AI/ML/Clusturing, K-Means Algorithm
Unsupervised
이전까지는 모델에 정답이 포함된 데이터를 넣어줬다면 여기부터는 정답이 없는 데이터를 학습시키는 비지도 학습을 한다.
K-Means Algorithm
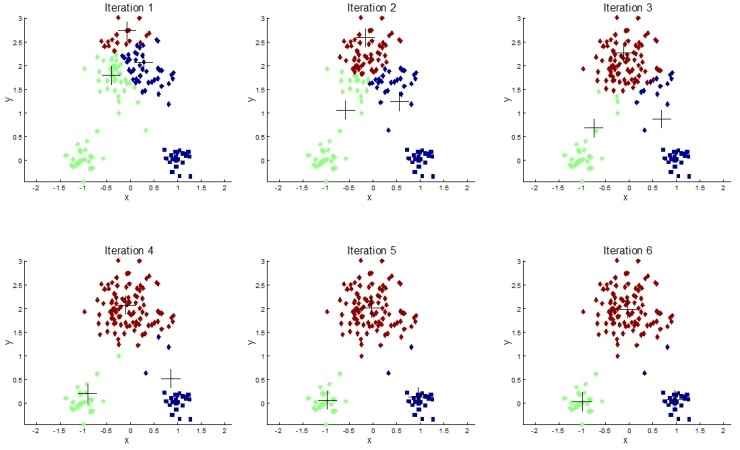
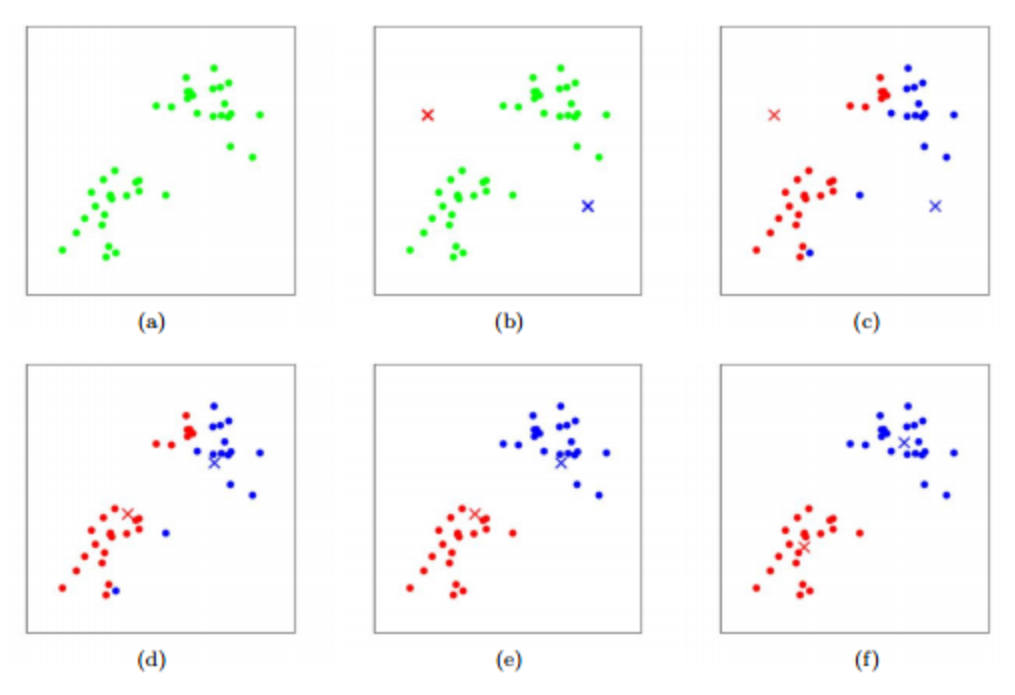
- 임의로 K개의 중심점을 정한다.
- 각 데이터마다 가까운 점의 클러스터에 할당한다.
- 클러스터의 평균값으로 중심점을 옮긴다.
- 변화가 없을 때 까지 2~3 과정을 반복한다.
약점: 2, 3번 과정에서 계산량이 많아 속도가 느림
개선방법
1. 차원축소를 한다.
2. 데이터를 선별해서 개수를 줄인다.
3. 대체 모델로 t-SNE(gpu가속을 사용함), GMM 등이 있다.(https://3months.tistory.com/154)
실습
from sklearn import cluster
import numpy as np
X = np.array([[1, 4], [5, 1], [6, 4], [5, 3], [5, 1], [7, 3]])
kmeans = cluster.KMeans(n_clusters=2, random_state=0).fit(X)
print(kmeans.labels_)
kmeans.predict([[0, 1], [14, 5]])n_clusters는 K값, random_state는 최초로 중심점을 찍는 랜덤시드이다.
kmeans.clusters_centers_를 보면 중심점을 뽑아낼 수 있다.
kmeans.labels_는 각 데이터들의 클러스터 번호를 출력한다.
근데 중심점을 처음에 잘못찍으면 군집화자체가 이상해지는 경우가 있는데
cluster.KMeans() 안에 init='k-means++'라는 속성이 숨어있어서 그렇게 안된다. init='random'이라고 넣어보면 한번 확인해볼 수 있다.
근데 데이터를 분류할 때 k를 어떻게 설정해야할까?
