AI/ML/K-Nearest Neighbor Algorithm
KNN
분류 모델의 일종(회귀모델도 있긴 있다). Gradient Boosting이나 C-SVM보다 성능이 뛰어나진 않지만 원리가 단순하다.
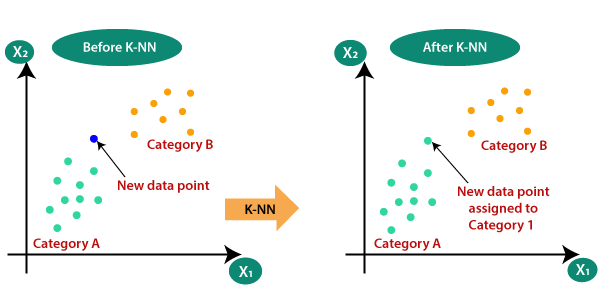
제일 가까운 k개의 원소에 대해 가장 비율이 높은 범주로 예측하는 것이다.
k값이 작을수록 오버피팅된다.
실습
import numpy as np
import matplotlib
import matploblib.pyplot as plt
from sklearn import neighbors, datasets
iris = datasets.load_iris()
iris_x = iris.data
iris_y = iris.target
model = neighbors.KNeighborsClassifier(n_neighbors=7) # k = 7
model.fit(iris_x, iris_y)