정의
편향은 학습 알고리즘에서 잘못된 가정으로 인한 오류이다. 편향이 높으면 알고리즘이 feature(설명변수, 독립변수)와 target(종속변수)간의 관계를 놓칠 수 있다.(Underfitting)
분산은 훈련 데이터셋의 작은 변동에 민감성으로 발생하는 오차다. 의도한 학습결과를 내기보다는 훈련 데이터 내의 무작위 소음을 모델링함에 따라 overfitting의 원인이 된다.
좀 더 쉽게 설명을 하자면 편향은 예측값들과 정답이(실제값)대체로 멀리떨어져 있으면 결과의 편향(bias)가 높다라고 말하며, 예측값들이 자기들 끼리 대체로 멀리 흩어져 있으면 결과의 분산(variance)가 높다라고 한다.
편향이 높다는것은 또한 train데이터의 오차가 크다는 것이다. 이는 과소적합으로 연결될 수 있으며 분산이 높다는 것은 train데이터에만 학습이되어 test데이터에서는 맞지않아 과적합으로 연결된다. 다음의 그림을 참고하면 좋을것 같다.
[Python Data Science Handbook,_ Chapter 5.3]
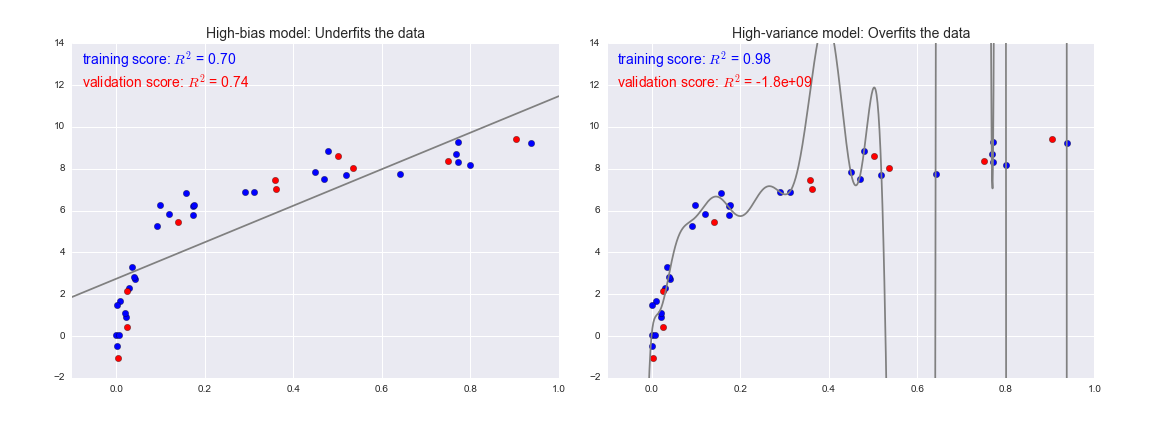
 - [The Dangers of Under-fitting and Over-fitting](https://medium.com/analytics-vidhya/the-dangers-of-under-fitting-and-over-fitting-495f9efa1847)
- [The Dangers of Under-fitting and Over-fitting](https://medium.com/analytics-vidhya/the-dangers-of-under-fitting-and-over-fitting-495f9efa1847)
(사진출처: The Dangers of Under-fitting and Over-fitting)
위의 그림은 좀 더 이해를 돕고자 사진을 가지고 왔다.
즉, 편향은 목표값(target)과 평균이 얼마나 떨어져 있는지를 나타내는 것이며, 분산은 표준편차의 제곱이다.
우리가 모델을 만들때는 편향과 분산을 최소로 만들어주어 에러를 줄이는것이 이상적이다.
편향-분산 트레이드 오프

(사진출처 : https://steemit.com/kr/@doctorbme/doctorbme-essay-bias-variance)
위의 그림은 모델복잡도와 에러를 편향과 분산의 관점에서 바라본 형태이다.
분산이 낮을 수록 편향이 높아지며(Underfitting), 분산이 높을수록 편향이 낮아지는(Overfitting)을 볼 수 있다.
그리고 전체에러는 복잡도가 높아질때 다시 상승하는 모습을 볼 수 있다. 따라서 우리는 에러를 가장 낮게하는(편향과 분산이 낮은지점에서 교차가되는)곳까지만 학습을 시켜야 한다.
요약하면 우리는 편향과 분산을 완벽하게 제거하지 못한다. 그렇다고 한가지만 집중적으로 제거하다가 다른 하나가 커져 모델을 망치게 된다. 따라서 우리는 편향과 분산사이에서 균형을찾아야한다. 이것이 편향과 분산의 트레이드 오프이다.
