머신러닝
1.단순선형회귀, 다중선형회귀

회귀란?? 회귀는 여러 개의 독립 변수와 한 개의 종속 변수 간의 상관관계를 모델링 하는 기법을 말한다. 회귀의 종류 > 회귀모델은 위의 사진과 같이 구분을 할 수 있다. 독립변수가 1개이면 단순회귀(Simple Regression), 독립변수가 2개이상 이면 다
2.머신러닝 학습을 위한 데이터셋 분리(train,test,validation)
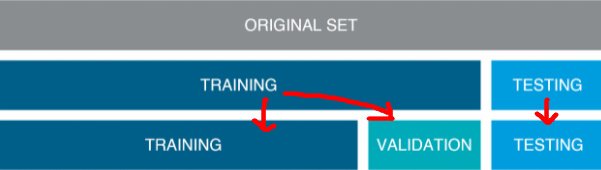
우리가 관심을 가지고 있는것은 모델 학습에 사용했던 훈련(train)데이터를 잘 맞추는 모델이 아니라, 학습에 사용하지 않은 테스트(test)데이터를 얼마나 잘 맞추는지 이다.train데이터는 우리가 학습을 할때 사용할 데이터 이며,test데이터는 우리가 학습한 모델의
3.회귀모델 평가지표(evaluation metrics)
회귀모델은 그 모델이 잘 학습되어졌는지 확인 하기 위한 회귀모델의 평가지표들이 4가지 있다.이를 하나씩 살펴보자. $\\frac{1}{n}\\sum{i=1}^{n}\\left | y{i} - \\hat{y\_{i}} \\right |$모델의 예측값과 실제값의 차이의 절
4.편향-분산 트레이드오프
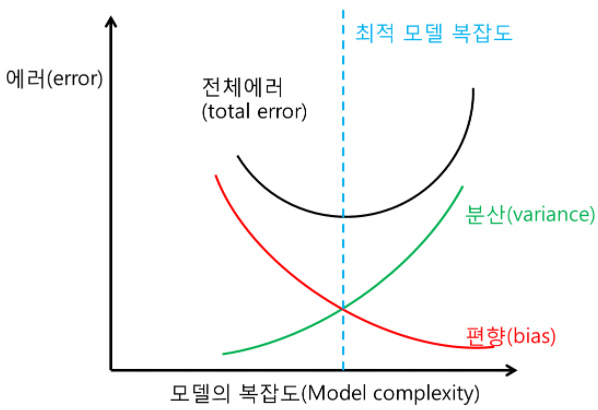
편향은 학습 알고리즘에서 잘못된 가정으로 인한 오류이다. 편향이 높으면 알고리즘이 feature(설명변수, 독립변수)와 target(종속변수)간의 관계를 놓칠 수 있다.(Underfitting)분산은 훈련 데이터셋의 작은 변동에 민감성으로 발생하는 오차다. 의도한 학습
5.릿지회귀(Ridge Regression)
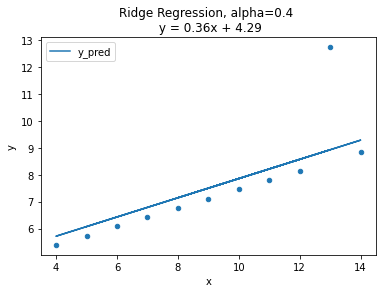
일반 선형회귀 모델을 사용하다 보면 과적합이 생길때가 빈번하게 있다. 이때, 과적합을 줄이기 위해서 사용하는것이 바로 릿지회귀이다.$\\beta{ridge}$: $argmin\[\\sum{i=1}^n(yi - \\beta_0 - \\beta_1x{i1}-\\dotsc
6.Nominal데이터 인코딩(One-hot-encoding, get_dummies)
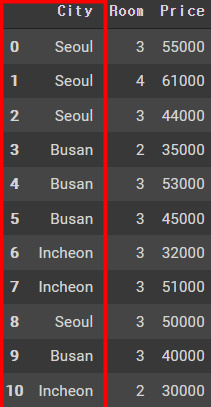
우리는 머신러닝의 모델을 만들때 데이터를 인코딩 하게된다.컴퓨터는 우리와 달리 텍스트를 인식하지못하여 이해를 할 수 있는 숫자의 형태로 만들어줘야한다.그래서 Categorical한 데이터를 숫자로 바꾸어 주는것을 우리는 인코딩이라고 부른다.OneHotEncoding은
7.사이킷런 파이프라인(Pipelines)
약 10일간 머신러닝을 공부 한것같다. 하면서 제일 손이 많이 가고 귀찮았던 부분이면서 해결 방법을 찾고있었던 스케일링과 다양한 학습들을 한번에 해주는 방법을 공부하게 되었다. 그것이 바로 사이킷런의 파이프라인이다.이런 흐름으로 일일이 모델을 학습시켜주었었다.정말 귀찮
8.특성중요도
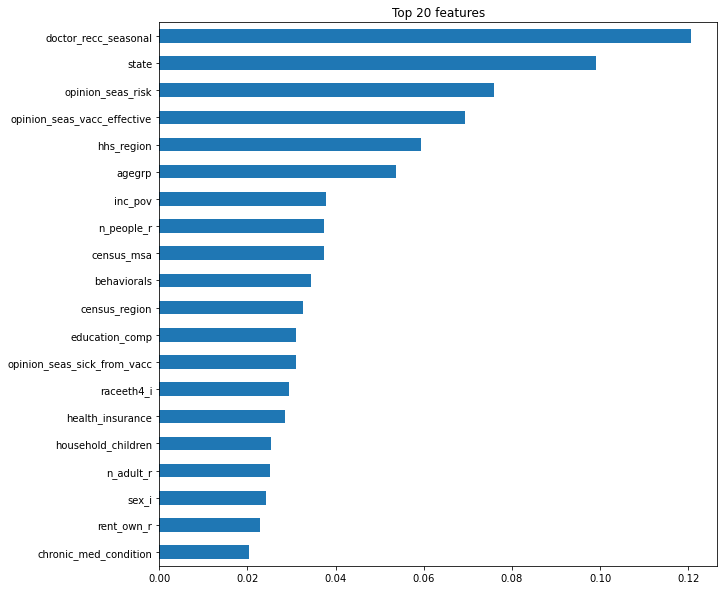
랜덤포레스트에서는 학습 후에 특성들의 중요도 정보(Gini importance)를 기본으로 제공한다.중요도는 노드들의 지니불순도(Gini impurity)를 가지고 계산하는데 노드가 중요할 수록 불순도가 크게 감소한다는 사실을 이용한다.노드는 한 특성의 값을 기준으로
9.클러스터링(군집화) 정리
INDEX >1. 목적 종류 similarity 종류 1 : 계층군집 종류 2 : PointAssignment(K-means) 계층군집과 PointAssignment(K-means)의 장단점 내가 클러스터링을 공부하면서 겪었던 개념적 착오 정리 군집분석 단계 최적의 군