교차검증
우리는 학습과 검증을 위해서 train셋, validation셋, test셋으로 데이터를 나눈다. 하지만 이러한 방법은 역시 과적합(overfitting)에 취약한 약점을 가질 수 있다.
그리고 고정된 학습 데이터와 테스트 데이터로 평가를 하다 보면 테스트 데이터에만 최적의 성능을 발휘할 수 있도록 편향되기 때문에 해당 테스트 데이터에만 과적합이 되는 학습모델이 만들어지기 때문에 다른 테스트 데이터가 들어오게 되면 성능이 저하되는것을 볼 수 있다.
여기서 테스트 데이터에만 과적합 된다는 것은 일반화가 잘 되지않는다는 것을 뜻합니다.
일반화는 다른 새로운 데이터들이 들어왔을때도 test데이터의 성능과 비슷하게 나오는 정도로 말할 수 있을것 같다.
이 문제를 해결하기 위해 나온것이 교차검증 이다. 즉, 교차검정은 어느정도 성능을 확인해 본 후 일반화가 잘 될 것 같은지를 확인해 보기 위해 사용한다.
교차검증을 쉽게 설명을 하면 수능을 치루기 전에 모의고사를 여러 번 보는 것이다. 여기서 수능은 테스트 데이터 셋이며 모의고사는 검증셋입니다. 여러번의 모의고사를 통해 학습하여 수능을 치는 방식이라고 보면 됩니다.
이렇게 여러번의 모의고사를 통해서 과적합을 피해서 수능때 일반화를 잘 시키기 위해서 사용하는것이 교차검증입니다.
교차검증의 종류
k-fold 교차검증, Stratified K-fold교차검증, hang-out교차검증 이렇게 기본적으로 분류가 된다. 물론 베이지안이나, gridsearch cv 와 같은 교차검증 모델도 있지만 기본적으로 언급한 세가지가 베이스가 된다.
1. Hold-out
먼저 hang-out교차검증의 경우는 충분한 데이터가 있을때 사용하는 것으로 원시(Raw)데이터를 학습, 검증, 테스트 이렇게 세가지의 데이터 셋으로 나누어 train데이터로 학습후 검증데이터로 테스트해보고 좋은 성능으로 업그레이드 시킨후 테스트 데이터로 검증해 본다. 이는 학습과 테스트 데이터 두개의 데이터 셋이 있었을 경우 발생하는 오버피팅(Overfitting)을 방지할 수 있다.
2. k-fold, Stratified k-fold교차검증
원시(Raw)데이터가 충분하지 않은 양 일때 사용하는 방법이 k-fold교차검증이고 아래에서 언급할 것이다.
그리고 Stratified k-fold는 불균형(Imbalanced)한 분포도를 가진 클래스 데이터 집합을 위한 K폴드 방식이다. 예를 들면 대출 사기 데이터를 예측한다고 했을때(대출 사기 :1, 정상 대출 :0)인 경우 0이 훨씬많다. 이렇듯 레이블이 불균형한 데이터에 적합하다. 그 이유는 Stratified k-fold 의 경우에는 레이블 데이터 분포도에 따라 학습/검증 데이터를 나누기 때문이다.
K폴드 교차 검증
교차검증에는 여러가지 기법들이 있습니다. 그중에서
기본적인 k-Fold cross validation 이 있다.
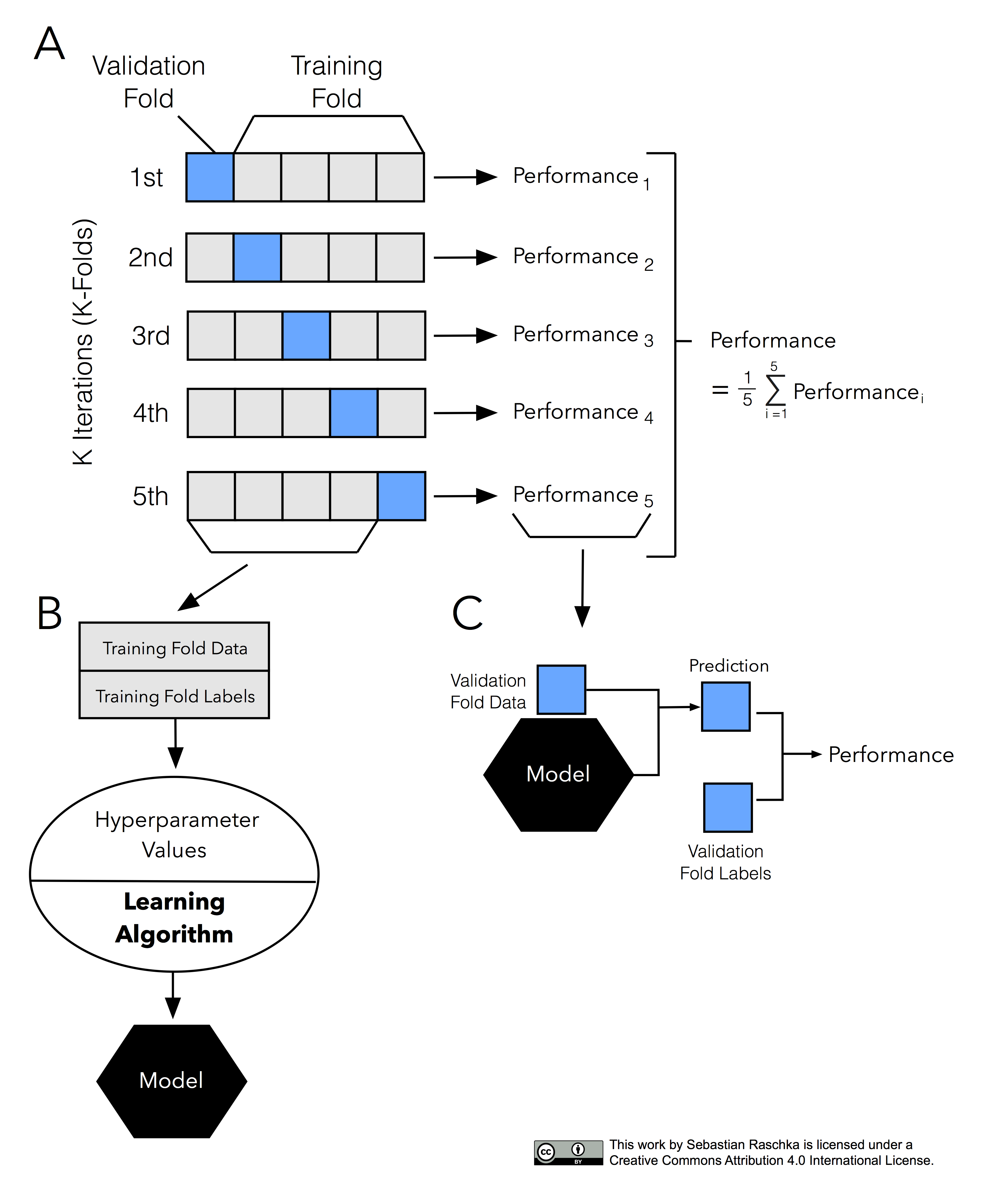
해당 모델은 가장 보편적으로 사용되는 교차 검증 기법이다. 먼저 K개의 데이터 폴드 세트를 만들어서 K번만큼 가 폴트 세트에 학습과 검증 평가를 반복적으로 수행하는 방법이다.
위에 있는 사진을 보면 파란색이 검증데이터이고 회색이 학습데이터이다. 저렇게 학습과 검증데이터를 점진적으로 변경하면서 5가지의 경우의 수를 다 활용하는 것이 바로 K폴드 교차검증이고,5개(K개)의 예측 평가를 구했으면 이를 평균해서 K폴드 평가 결과로 반영하면 된다.
기존에 pipe를 가지고 어떻게 k-fold를 활용할 수 있는지 코드로 알아보겠다.
from category_encoders import OneHotEncoder
from sklearn.feature_selection import f_regression, SelectKBest
from sklearn.impute import SimpleImputer
from sklearn.linear_model import Ridge
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
# (참고) warning 제거를 위한 코드
np.seterr(divide='ignore', invalid='ignore')
target = 'SalePrice'
features = train.columns.drop([target])
X_train = train[features]
y_train = train[target]
X_test = test[features]
y_test = test[target]
pipe = make_pipeline(
OneHotEncoder(use_cat_names=True),
SimpleImputer(strategy='mean'),
StandardScaler(),
SelectKBest(f_regression, k=20),
Ridge(alpha=1.0)
)
# 3-fold 교차검증을 수행합니다.
k = 3
scores = cross_val_score(pipe, X_train, y_train, cv=k,
scoring='neg_mean_absolute_error')
print(f'MAE ({k} folds):', -scores)
>>>MAE (3 folds): [19912.3716215 23214.74205495 18656.29713167]데이터는 집값 예측을 위한데이터를 사용하였으며, feature와 target을 지정해준뒤 pipe를 만든후 교차검증을 실시한 코드이다.
예시 데이터에서는 3개의 fold를 사용했으며 이로인해 3개의 폴드에 대한 결과값이 각각 다음과 같이 나온것이다.
이제는 이 각각의 폴드의 값을 평균해 줘야하기 때문에 최종 스코어는 다음과 같이 된다.
-scores.mean()
>>> 20594.4702693718이를 랜덤 포레스트에도 적용해 보겠다.
from category_encoders import TargetEncoder
from sklearn.ensemble import RandomForestRegressor
pipe = make_pipeline(
TargetEncoder(min_samples_leaf=1, smoothing=1),
SimpleImputer(strategy='median'),
RandomForestRegressor(max_depth = 10, n_jobs=-1, random_state=2)
)
k = 3
scores = cross_val_score(pipe, X_train, y_train, cv=k,
scoring='neg_mean_absolute_error')
-scores.mean()
>>> 17018.195737교차검증을 보다 간단하게 하는 방법
cross_val_score(estimator, X, y, scoring, cv, n_jobs = 1, verbose = 0, fit_params = None)
보통 estimator, x, y, scoring, cv를 주로쓰는데
순서대로 사이킷런의 분류알고리즘 스케일, X는 피쳐데이터세트, y 는 라벨데이터 세트, scoring은 예측성능평가지표, cv는 교차 검증 폴드 수 이다.
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score, cross_validate
from sklearn.datasets import load_iris
iris_data =load_iris()
dt_clf = DecisionTreeClassifier(random_state = 156)
data = iris_data.data
label = iris_data.target
# 성능 지표는 정확도(accuracy), 교차 검증세트는3개
scores = cross_val_score(dt_clf, data, label, scoring = 'accuracy', cv =3)
np.round(scores, 4) # 검증별 정확도
np.round(np.mean(scores),4) # 평균 검증 정확도
>>> 0.9804 0.9216 0.9792
0.9604Stratified k-fold
Stratified k-fold 의 경우 간단하게 이름만 StratifiedKFold(n_splits = 3)이렇게 변경하면 된다.
하이퍼파라미터 튜닝
-
하이퍼 파라미터는 머신러닝 알고리즘을 구성하는 주요 구성 요소이며, 이 값을 조정해 알고리즘의 예측 성능을 개선할 수 있다.
-
머신러닝 모델을 만들 때 중요한 이슈는 최적화(optimization)와 일반화(generalizatino)이다.
- 최적화는 훈련 데이터로 더 좋은 성능을 얻기 위해 모델을 조정하는 과정이며,
- 일반화는 학습된 모델이 처음 본 데이터에서 얼마나 좋은 성능을 내는지를 이야기 하는것이다.
GridSearchCV
- GridSearchCV는 하이퍼 파라미터의 집합을 만들어 이를 순차적으로 적용하면서 최적화를 수행할 수 있다.
- 지정해준 여러 하이퍼 파라미터를 순차적으로 변경하면서 최고 성능을 가지는 파라미터 조합을 찾을때 사용한다.
grid_parameters = {'max_depth' : [1, 2, 3],'min_samples_split' : [3, 4]}이런식으로 사전형태로 파라미터와 순차적으로 진행할 각 파라미터별 값을 지정해준다.
하지만, 이는 학습하고자하는 파라미터의 수에 따라 학습이 많이 늘어나므로 그에따른 시간은 비약적으로 늘어나게 된다.
GridSearchCV 파라미터 확인
- estimator : classifier, regressor, pipeline이 사용될 수 있다.
- param_grid : key + 리스트 값을 가지는 딕셔너리가 주어진다, estimator의 튜닝을 위해 파라미터명과 사용될 여러 파라미터 값을 지정한다.
- scoring : 예측 성능을 측정할 펴가 방법을 지정한다. 보통은 사이킷런의 성능평가지표를 지정하는 문자열(예)'accuracy')
- cv : 교차 검증을 위해 분할되는 학습/ 테스트 세트의 개수를 지정한다.
- refit : 디폴트가 Ture이며 생성 시 가장 최적의 하이퍼 파라미터를 찾은 뒤 입력된 estimator객체를 해당 하이퍼 파라미터로 재학습 시킨다.
예제를 살펴보자
iris_data = load_iris()
X_train, X_test, y_train ,y_test = train_test_split(iris_data.data, iris_data.target, test_size = 0, random_state = 121)
dtree = DecisionTreeClassifier()
# 파라미터를 딕셔니리 형태로 설정
parameters = {'max_depth' : [1,2, 3], 'min_samples_split':[2,5]}
import pandas as pd
grid_dtree = GridSearchCV(dtree, param_grid = parameters, cv =3 , refit = True)
# 학습
grid_dtree.fit(X_train, y_train)
#GridSearchCV 결과를 추출하기
grid_dtree.best_params_
grid_dtrr.best_score_
>>>
{'max_depth':3, 'min_samples_split' : 2}
0.9668GridSearchCV의 refit
그리드서치cv에는 refit이라는 하이퍼파라미터가 들어가 있다. 이는 최적의 성능을 나타내는 하이퍼 파라미터로 Estimator를 학습해 best_estimator로 저장하는 역할이면, 디폴트가 True로 내장되어 있다.
# GridSearchCV의 refit으로 이미 학습된 estimator반환
estimator = grid_dtree.best_estimator_
# GridSearchCV의 best_estimator_는 이미 최적 학습이 되었으므로 별도의 학습 필요하지 않음
pred = estimator.predict(X_test_
accuracy_score(y_test, pred)
>>> 0.9668