파이썬머신러닝완벽가이드
1.결정트리(Decision Tree)모델(Model)
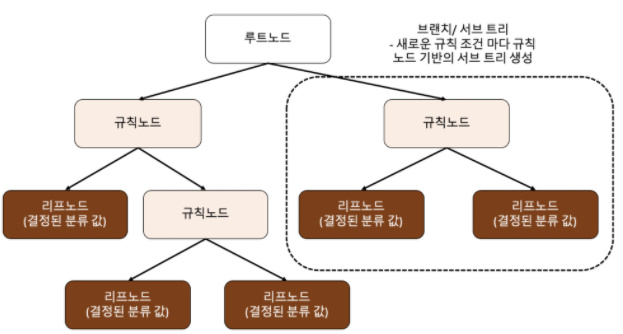
결정트리 모델이란 데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 (Tree)기반의 분류 규칙을 만드는것으로 이 모양이 나무를 닮아 Tree모델이다.구조 구조 설명루트노드(root) : 트리가 시작된 곳(뿌리)규칙노드 : 규칙조건이 되는 곳리프노드 : 결정된 클
2.앙상블 학습
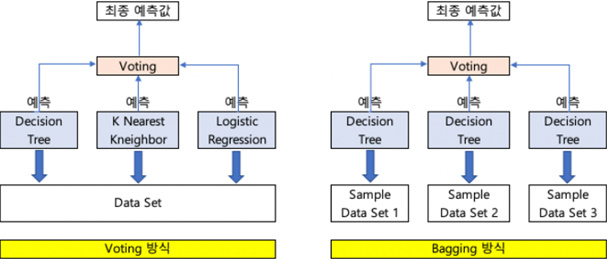
앙상블(Ensembl)이란 한 종류의 데이터로 여러 머신러닝 학습모델(week base learner,기본모델)을 만들어 그 모델들의 예측결과를 다수결이나 평균을 내어 예측하는 방법을 말한다.이론적으로 기본모델 몇가지 조건을 충족하는 여러 종류의 모델을 사용할 수 있다
3.랜덤 포레스트(RandomForest)모델
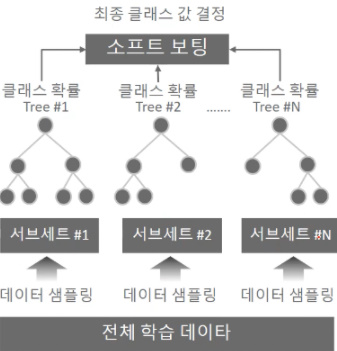
랜덤 포레스트는 결정 트리 기반의 알고리즘으로, 결정트리의 장점인 쉽고 직관적인 것을 그대로 가지고 왔습니다. 랜덤 포레스트는 여러 개의 결정 트리 분류기(classifier)가 전체 데이터에서 배깅(bagging)방식으로 각자의 데이터를 샘플링(sampling)해
4.머신러닝 분류모델 평가(정밀도,재현율,f1-score등)
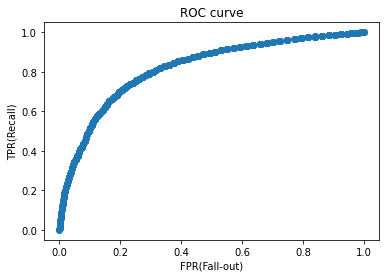
평가란...?? 머신러닝의 프로세스를 간단하게 살펴 보면 데이터 가공/변환, 모델 학습/예측, 그리고 평가(Evaluation)으로 구성이된다. 어떻게 데이터를 가공하고 변환시켜서 이것을 모델에 넣어 학습을 하고 예측을 하는것 모두 중요하다 하지만 이러한 과정들이 잘
5.교차검증과 하이퍼파라미터 튜닝

교차검증 우리는 학습과 검증을 위해서 train셋, validation셋, test셋으로 데이터를 나눈다. 하지만 이러한 방법은 역시 과적합(overfitting)에 취약한 약점을 가질 수 있다. 그리고 고정된 학습 데이터와 테스트 데이터로 평가를 하다 보면 테스트
6.인코딩 방법
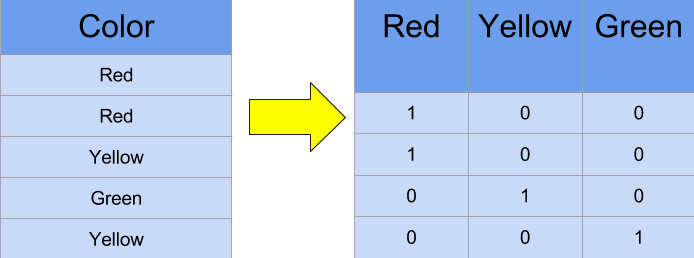
인코딩은 컴퓨터가 아는 언어로 변환 해 주는 작업을 말한다.컴퓨터는 0과1의 이진법만 이해를 할 수 있다. 따라서, 우리가 한글로 주고 머신러닝을 학습시키면 학습이 되지 않는다. 따라서 우리는 이러한 것들을 컴퓨터가 알아들을 수 있게 인코딩 하는 작업이 필수적이다.No
7.피처 스케일링(StandardScaler,MinMaxScaler)
피처 스케일링(표준화, 정규화) 서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 작업을 피처 스케일(feature scaling)이라고 한다. 대표적인 방법으로 표준화(Standardization)와 정규화(Normalization)가 있다. 표준화는 데이터의 피