
표본은 더 큰 데이터 집합으로부터 얻은 데이터의 부분집합이다. 통계학자들은 이 큰 데이터 집합을 모집단 이라고 부른다. 다양한 데이터를 효과적으로 다루고 데이터 편향을 최소화하기 위한 방법으로 표본추출하는 것이 중요하다.
예를 들어 "대한민국 남성의 평균키는 173이다" 라고 했을때, 모집단은 대한민국 남자 전체를 말한다.
하지만, 대한민국 모든 남성의 키 데이터를 얻을 수 없기때문에 표본 즉, 각 지역별로 랜덤하게 뽑는다고 했을때 여기서 뽑은 데이터를 표본이라고 하며, 이 표본을 통해서 모집단을 예측하게 된다.
즉, 샘플 기반의 추정이나 모델링에서는 데이터의 품질은 양보다 더 중요하다!!
📈 용어 정리
- N(n) : 모집단(표본)의 크기
- 임의표본추출(random sampling) : 무작위로 표본을 추출하는 것
- 층화표본추출(stratified sampling) : 모집단을 층으로 나눈 뒤, 각 층에서 무작위로 표본을 추출하는것(중복되지 않은 층, 예를 들어 대한민국의 ~~한 평균을 구한다고 했을때 지역별로 층을 나누는것)
- 계층 : 공통된 특징을 가진 모집단의 동종 하위 그룹
- 단순임의표본 : 모집단의 층화 없이 임의표본추출로 얻은 표본
- 편향 : 계통상의 오류
- 표본편향 : 모집단을 잘못 대표하는 표본
자기선택 표본편향 : 카페나 레스토랑의 리뷰데이터는 무작위로 선정된 것이 아니기 때문에 편향이 되기 쉽다. 예를들어 호텔같은 경우 리뷰를 남긴 사람의 경우 아닌사람들과 달리 특별한 좋은 혹은 나쁜 경험을 했거나, 리뷰어 혹은 체험단의 성격을 지닐 수 있기 때문이다. 이는 표본자체가 편향이 있으며 해당 호텔을 파악하기 위한 지표로서 사용하기에는 어려울 수 있따. 하지만 단순히 시설간의 비교를 할때에는 오히려 신뢰할 만한 자료가 될 수 있다.
📈 편향
- 통계적 편향은 측정 과정 혹은 표본추출 과정에서 발생하는 계통적인 오차를 의미한다.
- 통계적 추정결과가 체계적으로 한 쪽으로 치우치는 경향을 보임으로서 발생하는 오차.
- 추정결과가 크거나 작아짐에 따라 발생하는 변동오차와는 달리, 추정결과가 한 쪽 방향으로 치우침에 따라 나타나는 오차이다.
- 임의표본추출로 인한 오류와 편향에 따른 오류는 신중하게 구분해야한다.
📈 표본평균과 모평균
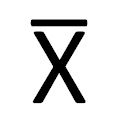
- 위에 있는 기호를 모집단의 표본평균의 기호이며 모집단의 평균은 U로 표현한다.
- 이 둘을 구분하는 이유는 표본에 대한 정보는 관찰을 통해 얻어지고, 모집단에 대한 정보는 주로 작은 표본들로부터 추론을 하기때문에 통계학자들은 구분하는것을 선호한다.
📈 선택편향(select bias)
- 선택편향은 데이터를 의식적이든 무의식적이든 선택적으로 고르는 관행을 뜻한다.(관측 데이터를 선택하는 방식 때문에 생기는 편향)
- 이는 오해의 소지가 있거나 단편적인 결론으로 향한다.
- 비무작위 표본을 마치 무작위 표본인 것처럼 생각하고 사용할 때 발생하는 오류를 뜻한다.
- 쉽게 생각해보면 모아둔 자료들이 랜덤하다고 착각하는것이다.
- 다른 예를들어 보면 시장에 바나나를 사러갔는데 수 많은 바나나중 대충 두, 세개를 골랐더니 신선해 보여서 구매를 했더니 세개 모두 신선했을때는 다른것들도 신선할 것이라고 예측한다.
- 하지만, 본인이 선택해서 확인한 것이 아닌 과일가게 주인이 두,세개를 보여주는 경우 장사를 하는 입장에서 일부로 좋은상품을 표본으로서 보여줬을 가능성이 있다.
- 이러한 경우 가게 주인의 작위성이 들어가고 신뢰가 떨어지게 된다.
- 선택편항에는 등장하는 두가지 개념이 있다. "데이터 스누핑"과 "방대한 검색 효과" 이다.
📈 방대한 검색효과 (Vast search effects)
- 데이터 과학자들이 걱정하는 선택편향의 한 형태는 존 엘더가 부르는 방대한 검색효과이다.
- 큰 데이터 집합을 가지고 반복적으로 다른 모델을 만들고 다른 질문을 하다 보면, 언젠가 흥미로운 것을 발견하기 마련이다. 그 결과는 정말로 의미가 있는 것인가? 아니면 우연히 얻은 예외 인가?
- 많은 예측 변수를 포함하는 모델링은 일반화가 될 수 있을까??
- 예를 들어 내가 복권에 당첨 될 확률은 희박할것이다. 하지만 백만명이 복권을 샀을때 그 중 한명이 복권에 당첨 될 확률은?? 매우 높을것이다
- 즉, 데이터를 고문하다보면 어떤 형태로든 자백하게 되는데 과연 이것이 의미있는것일까? 아니면 우연일까??
- 따라서 성능을 검증하기 위해서 홀드아웃(holdout)데이터 세트를 사용하거나, 목표값섞기(순열검정)을 추천했다(존 엘더John Elder < 데이터 마이닝 컨설턴트이자 엘더 리서치의 설립자이다. > )
- 통계에서 일반적으로 나타나는 선택편향으로는 위에서 언급한 방대한 검색효과 뿐만 아니라, 비임의표본추출(non-random-sampling), 데이터 체리피킹(선택), 특정한 통계적 효과를 강조하는 시간 구간 선택, 흥미로운 결과가 나올때 실험을 중단하는 것 등이 포함된다.
📈 데이터 스누핑
- 어떠한 가설을 세우고 그것을 시험하기 위해서 잘 설계된 실험을 수행한다면, 그 결과에 대해 강하게 확신할 수 있다. 하지만 이런 경우는 드물다.
- 보통 가지고 있는 데이터를 먼저 확인한 후 그 안에서 패턴을 찾고자 한다. 하지만, 이것이 참된 패턴인지 그냥 데이터 스누핑을 통해 나온 결과인지 알 수없다.
- 즉, 데이터 스누핑이란 흥미로운것이 나올때까지 계속해서 데이터를 뒤지는것이다.
- 모델에 환벽히 들어 맞는 패턴이나 규칙을 계속해서 찾는것, 우리는 데이터를 계속해서 고문하다보면 모델에 들어맞는 패턴을 찾는경우가 있지만 이것이 유의미한 패턴인지는 의문이다.
📈 평균으로의 회귀
- 주어진 어떤 변수를 연속적으로 측정했을 때 나타는 현상으로서
- 예외적인 경우가 관찰되면 그 다음에는 중간 정도의 경우가 관찰되는 경향이 있다는 것이다. 따라서 예외 경우를 너무 특별히 생각하고 의미를 부여하면 선택편향으로 이어질 수 있다.
- 예를 들어, 야구 선수가 새로운 팀으로 이적을 했다고 가정하자.
- 해당 시즌에 성적은 간단하게 다음과 같은 공식이 적용할것이다.
- 성적 = 실력 + 운
- 물론 실제로 다양한 복합적인 요소가 있겠지만 예시를 위해 이렇게 예를 들어보았다.
- 실력이 10중에 5인 선수이지만 그 해 운이 좋아서 10의 성적을 보여줬다고 하면 이것은 평소 5점의 실력과 다르게 예외값으로 계산이 된다. 그렇다고 해서 이 경우에 너무 의미 부여를 하다가는 선택편향이 발생할 수 있다.
- 예외가 발생하였다고 성급하게 어떠한 판단을 하기보다는 데이터를 전체적으로 바라보자!!
📈 정리
- 가설을 구체적으로 명시하고 임의표본추출 원칙에 따라 데이터를 수집하면 편향을 피할 수 있다.
- 모든 형태의 데이터 분석은 데이터수집/분석 프로세스에서 생기는 편향의 위험성을 늘 가지고 있다.

문제를해결하는도구로서의"데이터"