통계
1.데이터의 종류

이산데이터와 달리 Group을 지어서 Table을 만들어야한다.179(cm) - 1명179.1 - 3명179.2 - 2명179.3 - 1명....180.1 - 1명위와 같은 데이터가 있을때 한 데이터 마다 따로 계산을 하는것이 아닌그룹화 시킨다. 179
2.독립표본T 검정, 대응표본 검정
T검정이란 가설검정의 한 종류로서 모집단의 분산이나 표준편차를 알지 못할때, 표본으로부터 추정된 분산이나 표준편차를 이용하여, 두 모집단의 평균의 차이를 통해 집단이 같은지, 다른지 알아보는 검정 방법이다.집단의 수가 3개 이상인 경우 ANOVA(아노바)검정을 사용한다
3.1종 오류와 2종오류, Type of Error
||불이나지 않음(귀무가설이 참이다)|화재발생(귀무가설이 거짓)| |------------------|---------|-----------------------| |화재경보가 울리지않음(귀무가설기각)|옳은결정|2종오류(귀무가설이 거짓인데 기각하지않음)| |화재경보가
4.카이제곱 검정
주어진 데이터 간의 동일한 분포 혹은 빈도를 나타내는지 검정하는 방법1) 적합도 검정(Goodness of Fit test)관찰된 비율 값이(실제값, observed)기대값(exp, expected)와 같은지 조사하는 검정(1sample 카이제곱 검정)2) 동질성 검정
5.변수의 종류와 의미
Reference : https://www.youtube.com/watch?v=9O13pGpVSrE인과관계에서 원인이 되는 변수가 독립변수이다.결과를 예측하기 때문에 예측변수라고 부르기도 한다.결과를 설명하기 때문에 설명변수라고 부르기도 한다.예를 들어 고객의
6.기초통계 (1)위치추정
💡 위치 추정 데이터를 살펴보는 기초 단계중 하나는 각 feature(변수)의 대푯값을 구하는 것이다. 이는 곧 값이 어디쯤 위치하는지(중심경향성)를 나타내는 추정값이다. 평균 : 모든 값들의 합을 개수로 나눈 값 가중평균 : 가중치를 곱한 값의 총합을 가중치의 총
7.기초통계 (2)변이추정

💡 변이 추정 변이 추정은 데이터 값이 얼마나 밀집해 있는지 혹은 퍼져 있는지를 나타내는 산포도를 나타낸다. 📈 편차(deviation) 관측값과 위치 추정값 사이의 차이 쉽게 말하면 회귀식에서 실제 관측값과 우리가 추정하는 값의 차이를 뜻한다. 📈 분산 평균
8.기초통계 (3) 분포탐색하기
Boxplot(상자그림) : 데이터 분포를 시각화하기 위한 그림도수분포표 : 어떤 구간에 해당하는 수치 데이터 값들의 빈도를 나타내는 기록히스토그램(histogram) : x축은 구간들을, y축은 빈도수를 나타내는 도수 테이블의 그림(막대그래프와 시각적으로 비슷하지만
9.기초통계 (5) 상관관계
데이터 분석에 있어서 상관관계를 조사하는것은 빼놓을 수 없는 절차중 하나이다.X가 큰값을 가질 수록 Y도 큰값을 가지거나, X가 작은값을 가질때 Y도 점점 작은값을 가진다면 이를(X와Y는) 양의 상관관계를 가진다고 할 수 있다.반대로 X가 큰값을 가질 수록 Y가 작은값
10.기초통계 (6) 분산과 공분산 그리고 상관계수
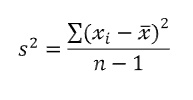
💼 분산 분산이란 내가 가진 자료(데이터)가 평균값을 중심으로 퍼져있는 평균적인 거리
11.기초통계 (4) 이진 데이터와 범주 데이터 탐색

통계를 배우다 보면, 혹은 데이터 직군을 위해 공부를 하다보면 기대값(expected value)라는 말이 종종 나온다. 이 기댓값은 무엇을 의미하는것일까??먼저 우리는 카지노에 입장했다고 가정해본다.A라는 게임(두개의 컵속에 파란색, 빨간색 칩이 하나씩 들어있는데 파
12.기초통계 (7) 표본추출과 편향

표본은 더 큰 데이터 집합으로부터 얻은 데이터의 부분집합이다. 통계학자들은 이 큰 데이터 집합을 모집단 이라고 부른다. 예를 들어 "대한민국 남성의 평균키는 173이다" 라고 했을때, 모집단은 대한민국 남자 전체를 말한다. 하지만, 대한민국 모든 남성의 키 데이터를
13.기초통계 (8) 통계학에서의 표본분포(와 표준오차 표준편차 구분)

표준편차는 각 데이터가 평균과 얼마나 차이를 가지느냐를 알려주는 것이다.즉, 추출된 표본들이 표본의 평균에서 얼마나 떨어져 있는가를 나타낸다.표준오차는 추정량의 정도를 나타내는 측도로서 샘플링을 여러 번 했을 때 각 샘플들의 평균이 전체 평균과 얼마나 차이를 보내는지에
14.기초통계 (9) 복원추출과 비복원추출

먼저 다음에 질문해보는것이 잘 알고있는지 아닌지 확인해볼 수 있을것 같다.다음 3개의 경우의 수 를 보았을때 어떤것이 복원추출이고 어떤것이 비복원추출에 해당하는 것일까??1번이 복원추출 2번이 비복원추출이라고 생각하시는 분들이 분명히 있을것이다.하지만 복원추출은 3번이
15.기초통계 (11) 통계 기호 정리
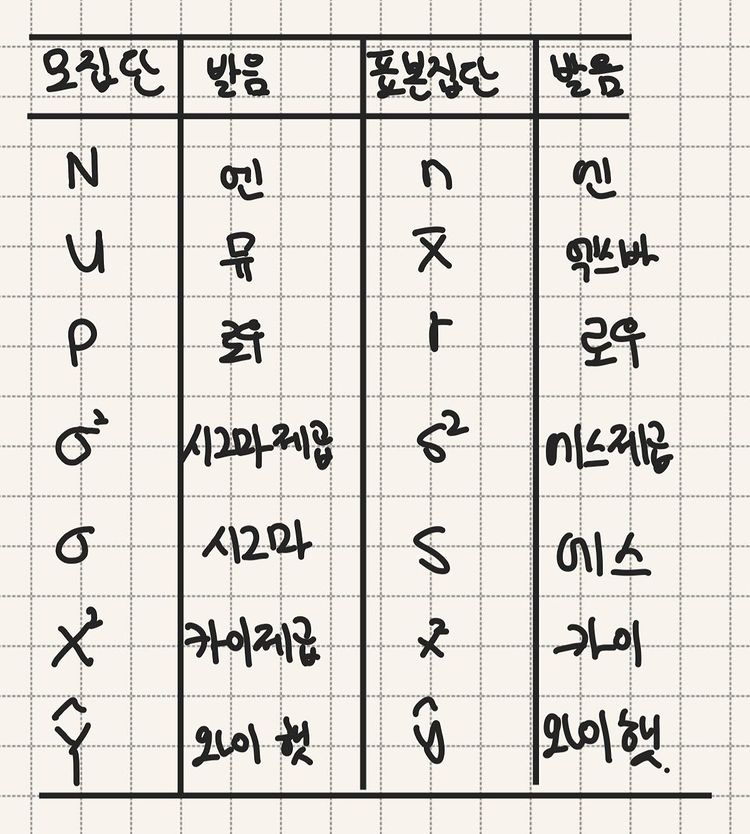
위에서부터 순서대로 적용 예시1\. 크기2\. 평균3\. 피어슨 상관계수4\. 분산5\. 표준편차6\. 교차분석7\. y의 추정값
16.기초통계 (10) 중심극한정리 와 재표본추출(순열검정, 부트스트랩)

💡 용어 정리 표본통계량 : 더 큰 모집단에서 추출된 표본 데이터들로부터 얻은 측정 지표 데이터 분포 : 어떤 데이터 집합에서의 각 개별 값의 도수분포 표본분포 : 여러 포본들 혹은 재표본들로부터 얻은 표본통계량의 도수분포 중심극한정리 : 표본크기가 커질수록 표본분
17.기초통계 (12) 신뢰구간(Confidence interval)

들어가기 앞서 사람들은 불확실성에 대해 자연스러운 반감을 가지고 있는경우가 많다. 특히 전문가들은 '잘 모른다'와 같은 표현을 사용하는 것을 꺼려한다. 사람들은 불확실성을 인정하면서도, 그것이 어떤 단일 수치(점추정)로 제시될때, 추정치에 대한 과도한 믿을을 가진다.
18.기초통계 (5-2) 두 개 이상의 변수 탐색하기
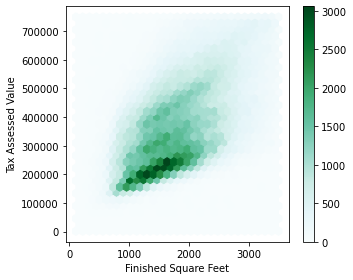
평균과 분산과 같이 익숙한 추정값들은 한 번에 하나의 변수를 다룬다(일변량 분석). 상관분석은 두 변수(이변량 분석)를 비교할 때 중요한 방법이다. 이번에는 이에 관한 추정법과 도표를 살펴보고 셋 이상의 변수(다변량분석)을 다루는 방법을 살펴볼 것이다.분할표(conti
19.기초통계 (13) 대표값의 함정
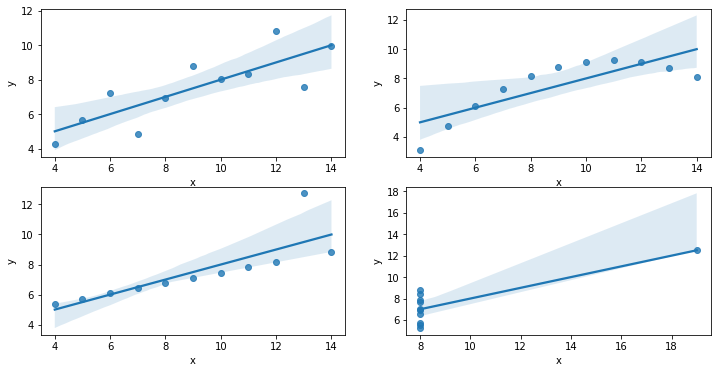
기술통계에서는 많은 대표값들이 존재한다. 하지만, 이 대표값으로만 의미를 뽑아내려다 보면 전체적인 그림을 보지 못할 수 있습니다. 이를 설명하는데 대표적인 것이 앤스컴 콰르텟 입니다.앤스컴 콰르텟이란 통계학자가 발견한 네 개의 데이터셋을 뜻한다. 실제로 코렙으로 만들어
20.기초통계 (14) 정규분포(정규화,표준화)
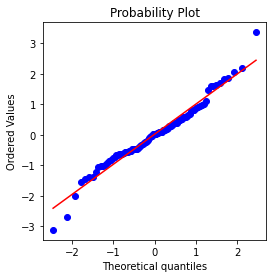
오차 : 데이터 포인트와 예측값 혹은 평균 사이의 차이표준화(정규화)하다 : 평균을 빼고 표준편차로 나눈다.z 점수(z-score) : 개별 데이터 포인트를 정규화한 결과표준정규분포(standard normal distribution) : 평균 = 0, 표준편차 =1
21.기초통계 (15) 스튜던트의 t분포
n : 표본크기자유도 : 다른 표본크기, 통계량, 그룹의 수에 따라 t분포를 조절하는 변수t분포는 정규분포와 생김새가 비슷하지만, 꼬리 부분이 약간 더 두껍고 길다. t분포는 표본통계량의 분포를 설명하는 데 광범위하게 사용된다. 표본 평균의 분포는 일반적으로 t분포와
22.기초통계 (16) 이항분포
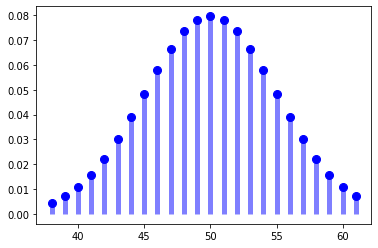
시행(trial) : 독립된 결과를 가져오는 하나의 사건(예 : 동전던지기)이항식(binomial) : 두 가지 결과를 갖는다.이항시행(binomial trial) : 두 가지 결과를 가져오는 시행이항분포(binomial distribution) : n번 시행에서 성공
23.기초통계 (17) 카이제곱분포, F분포, 푸아송 분포 및 기타 다른분포들
각 분포에대한 검정까지 학습후 다시정리해서 출간할 예정 📈 카이제곱분포 카이제곱통계량은 검정결과가 독립성에 대한 귀무 기대값에서 벗어난 정도를 측정하는 통계량이다. 카이제곱통계량은 관측 데이터가 특정 분포에 '적합'한 정도를 나타낸다(적합도검정). 여러 처리('A/
24.기초통계 (18) A/B 검정
A/B검정은 두 가지의 처리방법, 제품, 절차 중 어느 쪽이 다른 쪽보다 더 우월하다는 것을 입증하기 위해 실험군을 두개로 나누어 진행하는 실험으로 하나는 기존의 방법 혹은 어떠한 처리도 하지않은 대조군 그룹이고 하나는 새로운 처리방법을 채택한 처리군 그룹이라고 부른다
25.기초통계 (19) 가설검정
가설검정 혹은 유의성검정의 목적은 관찰된 효과가 우연에 의한것인지 여부를 알아내는 것이다. 귀무가설 : 우연 때문이라는 가설대립가설 : 귀무가설과 대조(증명하고자 하는 가설)일원검정(one-way test) : 한 방향으로만 우연히 일어날 확률을 계산하는 가설검정이원검
26.기초통계 (20) 재표본추출2(순열검정)
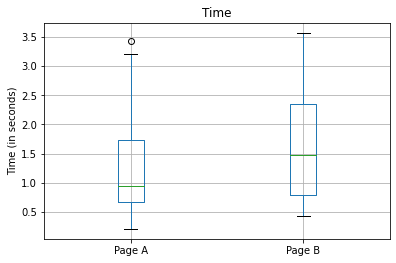
통계학에서 재표본추출이란 랜덤한 변동성을 알아보기위함. 이라는 일반적인 목표를 가지고 관찰된 데이터를 반복추출하는것을 의미하며, 일부 머신러닝(ML)모델의 정확성을 평가하고 향상시키는데 사용할 수 있다.(의사결정트리, 배깅) 📈 재표본추출 재표본추출에는 부트스트랩과
27.기초통계 (21) 통계적 유의성과 p값
통계적 유의성이란 통계학자가 자신의 실험(또는 기존 데이터에 대한 연구) 결과가 우연히 일어난 것인지 아니면 우연히 일어날 수 없는 극단적인 것인지를 판단하는 방법이다. 결과가 우연히 벌어질 수 있는 변동성 바깥에 존재한다면 우리는 이것을 통계적으로 유의하다고 말한다.
28.기초통계 (23) 다중검정 과 자유도
예를 들어 20개의 예측변수와 1개의 결과변수가 모두 임의로 생성되었다고 하자.유의수준 0.05에서 20번의 유의성검정을 수행하면 적어도 하나의 예측변수에서 통계적으로 유의미한 결과를 초래할 가능성이 꽤 높아진다. 이것을 1종오류라고 한다. 숫자로 살펴보면 20번 모두
29.기초통계 (24) 분산분석(아노바검정)
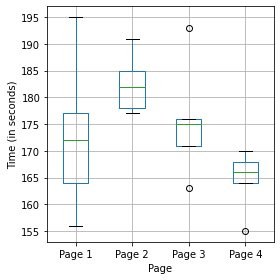
쌍별 비교 : 여러 그룹 중 두 그룹 간의 가설검정총괄검정 : 여러 그룹 평균들의 전체 분산에 관한 단일 가설검정분산분해 : 구성요소 분리. 예를 들면 전체 평균, 처리평균, 잔차 오차로부터 개별 값들에 대한 기여를 뜻한다.F 통계량 : 그룹 평균 간의 차이가 랜덤모델
30.기초통계 (25) 카이제곱검정과 피셔의 정확성검정
카이제곱검정(chi-square test)은 주로 횟수 관련 데이터 사용되며 예상되는 분포에 얼마나 잘 맞는지를 검정한다. 변수간에 독립성에 대한 귀무가설이 타당한지를 평가하기 위해 r x c 분할표를 함께 사용한다카이제곱통계량 : 기댓값으로부터 어떤 관찰값까지의 거리
31.기초통계 (26) 멀티암드 밴딧 알고리즘
멀팀암드 밴딧(MAB, multi-armed bandit) : 고객이 선택할 수 있는 손잡이가 여러 개일 가상의 슬롯 머신을 말하며, 각 손잡이는 각기 다른 수익을 가져다 준다. 다중 처리 실험에 비유라고 생각할 수 있다.손잡이 : 실험에서 어떤 하나의 처리를 말한다(
32.기초통계 (27) 검정력과 표본크기
📈 용어 정리 효과크기(effect size) : '클릭률의 20% 향상'과 같이 통계 검정을 통해 판단할 수 있는 효과의 최소 크기 검정력(power) : 주어진 표본크기로 주어진 효과크기를 알아낼 확률 유의수준 : 검증시 사용할 통계 유의수준 📈 검정력 표본
33.가설검정 로드맵
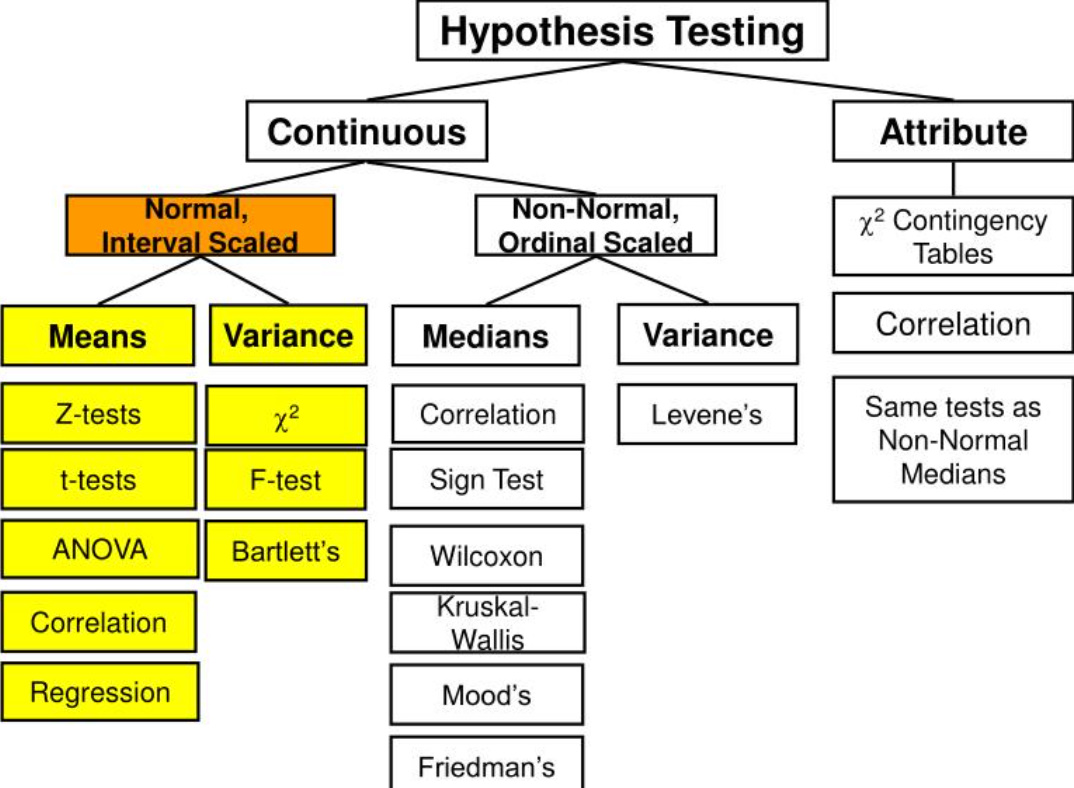
(출처 : SliderServe(Samuru Ishida))
34.기초통계 (28) 단순선형회귀
응답변수(반응변수, 종속변수) : 예측하고자 하는 변수독립변수(예측변수, 독립변수) : 응답치를 예측하기 위해 사용되는 변수레코드(record) : 한 특정 경우에 대한 입력과 출력을 담고 있는 벡터(행, 사건)절편 : 회귀직선의 절편, X = 0일때 예측값회귀계수(r
35.기초통계 (29) 다중선형회귀
📈 용어정리 제곱근평균제곱오차(RMSE) : 회귀 시 평균제곱오차의 제곱근. 회귀모형을 평가 하는 데 가장 널리 사용되는 측정 지표다. 잔차 표준오차(RSE) : 평균제곱오차와 동일하지만 자유도에 따라 보정된 값 R제곱(R-squared) : 0에서 1까지 모델에 의
36.다중검정(Multiple Comparison)
다중검정은 더 이상 서로간의 1대1 대응으로 검정하는 것이 아닌 더 많은 대상들간의 유의성검정을 하는것을 말한다. 예를 들어, T검정의 경우 각각 A, B 웹페이지를 랜덤하게 보여준다고 가정했을때, A를 보였을때 머문시간, B를 보였을때 머문시간의 차이가 유의미한 차
37.회귀 분석할때 중요한점
우리는 회귀 분석을 할 때 다양한 독립변수 혹은 단일의 독립변수 X 를 통해서 목표하는 종속변수 Y를 구해야 하는데 이때 우리가 종속변수를 예측할때 어떠한 요인을 통해서 예측을 할 것인가를 정하는 것은 매우 중요하다. 하지만 많은 초보자분들(본인포함)이 신경을 덜 쓰는
38.부트스트랩 순열검정 리마인드
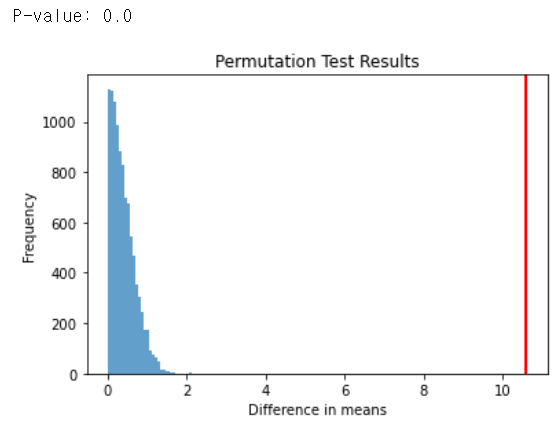
우리는 서비스를 개선시키기위해 혹은 유저경험을 개선시키기 위해서 A/B테스트를 많이 진행하게 된다. 이때 우리는 실험의 결과가 우연에 의한 차이는 아닌지 의심하게 된다. 많은 경우에 t검정을 통해서 결과에대한 최종 결정을 하게 될텐데, t검정의 경우 몇가지 가정이
39.인과추론 A/B테스트 이해하기

1\. 인과추론이 필요한 이유(2. A/B테스트 이해하기(3. A/B Test 실습(Python)(지표가 왜 올라가는지(or 내려가는지)원인을 명확히 모르면 기능 개선건 마다 직감으로 선택하게 된다. 물론 도메인에 있는 사람들의 직감 그자체가 빅데이터가 될수 있다. 하
40.A/B테스트 실험설계(MDE, 실험기간 설정, 검증력, 효과크기) 수정중

이전 게시글에서 A/B테스트 가 무엇이고 간단하게 결과해석 하는 부분에 대해서 살펴보았다. 이번에는 A/B 테스트에서 실험을 어떻게 설계를 하는지 여러자료들을 바탕으로 학습해 보았고, 이해한 내용과 중요하다고 생가하는 내용을 정리해보려고 한다. A/B 테스트 진행
41.인과추론 잠재적 결과 프레임워크 이해하기

인과추론을 바라보는 프레임워크 중에서 잠재적 결과 프레임워크(Potential Outcomes Framework)에 대해서 알아보자.먼저 해당 프레임 워크의 컨셉은 " Treatment가 적용되지 않았다면 어땠을까? " 에서 시작된다.(Treatment는 직역하면 "처