지난 포스팅에서는 시계열 데이터의 구성에 대해서 확인 해 보았고, 이번에는 시계열 데이터를 분해하는것을 직접 다루어 보려고 한다.
먼저 분해 방법에는 두가지가 있다.
첫번째, 덧셈 분해(additive decomposition)
두번째, 곱셈 분해(multiplicative decomposition)덧셈 분해(additive decomposition)
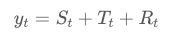
각각의 변수를 먼저 설명하면, y는 데이터, S는 계절성분, T는 추세, R은 불규칙 요소를 나타나면 각각의 t는 시점을 나타낸다.
곱셈 분해(multiplicative decomposition)
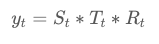
앞에서 본 것과 달리 곱셈을 사용하여 분해를 하는 방법으로 선제 조건으로는 데이터에 0 값이 존재해서는 안된다.
덧셈과 곱셈 분해의 차이점
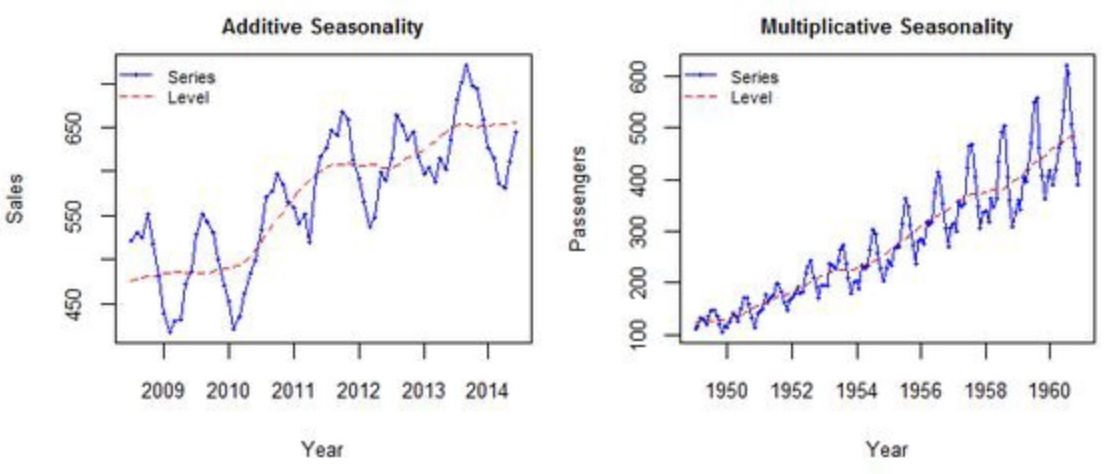
위에 두개의 시계열 데이터가 있습니다. 차이점이 무엇일까요??
왼쪽의 그래프 경우 시간이 지나감에 따라서, 변동폭이 일정하지만, 두번째 그래프의 경우 trend가 상승함에따라서 변동폭이 역시 상승하는것을보여주고 있다.
따라서 데이터의 특성에 따라 아래 실습 코드에서 model 파라미터에 addative OR multiplicative를 사용 해주면 된다.
분해실습
지난시간에 다룬데이터를 이어서 사용해 보겠습니다.
이렇게 다시 데이터를 불러오고 시작해 보겠습니다.result = seasonal_decompose(df, model = 'additive', two_sided = False)
result.plot()
plt.show()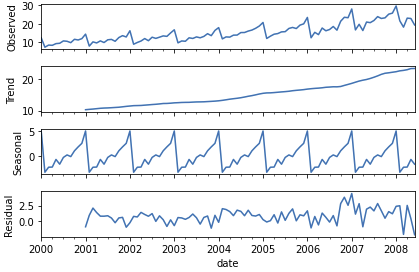
seasonal_decompose 메서드를 사용하면 이렇게 간단하게 데이터들이 분리가 됩니다.
위에서부터 데이터(observed), 추세(trend), 계절성(seasonal), 불규칙 요소(residual)
4가지로 분리되어 나오는것을 볼 수 있습니다.seasonal_decompose의 파라미터를 짧게 설명하고 넘어가겠습니다.
- model은 덧셈분해를 할것이냐 혹은 곱셈분해를 할것이냐에 따라서 데이터에 맞게 진행하면됩니다.
- two_sided 의 경우 추세의 경우 앞의 데이터를 통해서 만들어지는데 맨앞의 데이터만 보지 않으려면 False, 맨앞의 데이터와 가장 최근데이터를 보지않으려면 True를 사용해서 할 수 있습니다.
또한 출력을 따로 보고싶으면 아래 처럼 각각을 입력하면 됩니다.
result.observed.plot()
result.seasonal.plot()
result.trend.plot()
result.resid.plot()
문제를해결하는도구로서의"데이터"