.png)
SW과정 머신러닝 1026(15)
1. HumanActivity 추가본
import pandas as pd
import matplotlib.pyplot as plt
feature_name_df= pd.read_csv('./human_activity/features.txt',
sep='\s+',
header=None,
names=['column_index','column_name'])
feature_name_df.head(2)
feature_name = feature_name_df.iloc[:,1].values.tolist()
feature_name
feature_dup_df = feature_name_df.groupby('column_name').count()
feature_dup_df.head(2)
feature_dup_df[feature_dup_df['column_index']>1]
def get_new_feature_name_df(old_feature_name_df):
feature_dup_df = pd.DataFrame(data=old_feature_name_df.groupby('column_name').cumcount(),
columns=['dup_cnt'])
feature_dup_df = feature_dup_df.reset_index()
new_feature_name_df = pd.merge(old_feature_name_df.reset_index(),feature_dup_df,how='outer')
new_feature_name_df['column_name']=new_feature_name_df[['column_name','dup_cnt']].apply(lambda x:x[0]+'_'+str(x[1])
if x[1]>0 else x[0],axis=1)
new_feature_name_df = new_feature_name_df.drop(['index'],axis=1)
return new_feature_name_df
get_new_feature_name_df(feature_name_df)
def get_human_dataset( ):
# 각 데이터 파일들은 공백으로 분리되어 있으므로 read_csv에서 공백 문자를 sep으로 할당.
feature_name_df = pd.read_csv('./human_activity/features.txt',sep='\s+',
header=None,names=['column_index','column_name'])
new_feature_name_df = get_new_feature_name_df(feature_name_df)
# DataFrame에 피처명을 컬럼으로 부여하기 위해 리스트 객체로 다시 변환
feature_name = new_feature_name_df.iloc[:, 1].values.tolist()
# 학습 피처 데이터 셋과 테스트 피처 데이터을 DataFrame으로 로딩. 컬럼명은 feature_name 적용
X_train = pd.read_csv('./human_activity/train/X_train.txt',sep='\s+', names=feature_name)
X_test = pd.read_csv('./human_activity/test/X_test.txt',sep='\s+', names=feature_name)
# 학습 레이블과 테스트 레이블 데이터을 DataFrame으로 로딩하고 컬럼명은 action으로 부여
y_train = pd.read_csv('./human_activity/train/y_train.txt',sep='\s+',header=None,names=['action'])
y_test = pd.read_csv('./human_activity/test/y_test.txt',sep='\s+',header=None,names=['action'])
# 로드된 학습/테스트용 DataFrame을 모두 반환
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_human_dataset( )
X_train.info()
y_train.info()
X_train.head(1)
y_train['action'].value_counts()
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
dt_clf = DecisionTreeClassifier(random_state=156)
dt_clf.fit(X_train,y_train)
pred = dt_clf.predict(X_test)
accuracy = accuracy_score(y_test,pred)
accuracy
dt_clf.get_params()
from sklearn.model_selection import GridSearchCV
params = {'max_depth':[6,8,10,12,16,20,24]}
grid_cv = GridSearchCV(dt_clf,param_grid=params, scoring='accuracy',cv=5, verbose=1)
grid_cv.fit(X_train,y_train)
grid_cv.best_params_
grid_cv.best_score_
pd.DataFrame(grid_cv.cv_results_)[['param_max_depth','mean_test_score']]
params = {'max_depth':[6,8,12],
'min_samples_split':[12,14,16,24]}
grid_cv = GridSearchCV(dt_clf,param_grid=params, scoring='accuracy',cv=5, verbose=1)
grid_cv.fit(X_train,y_train)
grid_cv.best_params_
grid_cv.best_score_
pd.DataFrame(grid_cv.cv_results_).head(2)
pd.DataFrame(grid_cv.cv_results_)[['param_max_depth','mean_test_score']]
best_df_clf = grid_cv.best_estimator_
ascending=False 내림차순
pred = best_df_clf.predict(X_test)
accuracy = accuracy_score(y_test, pred)
accuracy
i_values = best_df_clf.feature_importances_
top20 = pd.Series(i_values, index=X_train.columns).sort_values(ascending=False)[:20]
import seaborn as sns
sns.barplot(x=top20, y=top20.index)
plt.show()2. 앙상블 학습방법
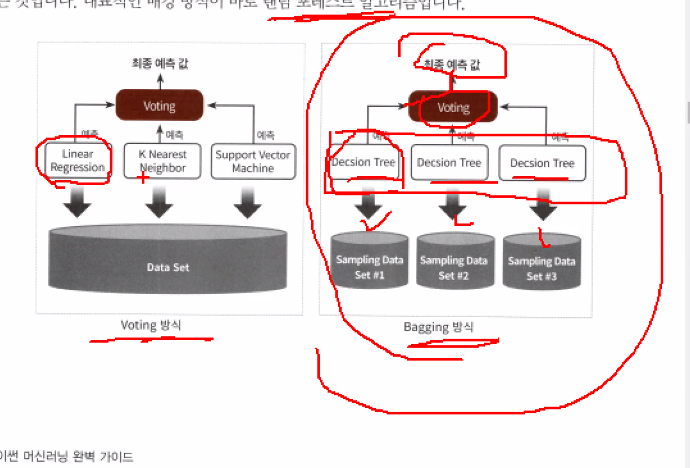
Voting vs Bagging 방식
보통은 하드보팅보다는 소프트보팅을 많이씀, 소프트보팅이 낫다.
import pandas as pd
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings('ignore')
load_breast_cancer()
cancer = load_breast_cancer()
type(cancer.data)
data_df = pd.DataFrame(cancer.data,columns=cancer.feature_names)
data_df.head(2)
lr_clf = LogisticRegression()
knn_clf = KNeighborsClassifier()
vo_clf = VotingClassifier(estimators=[('LR',lr_clf),('KNN',knn_clf)],voting='soft')
X_train,X_test,y_train,y_test = train_test_split(cancer.data,
cancer.target,
test_size=0.2,
random_state=156)#test에 20% 학습에 80%
vo_clf.fit(X_train,y_train)
pred = vo_clf.predict(X_test)
accuracy_score(y_test,pred)
items = [lr_clf,knn_clf]
for item in items:
item.fit(X_train, y_train)
pred = item.predict(X_test)
print(item.__class__.__name__)
print(accuracy_score(y_test,pred))
from sklearn.ensemble import RandomForestClassifier
def get_new_feature_name_df(old_feature_name_df):
feature_dup_df = pd.DataFrame(data=old_feature_name_df.groupby('column_name').cumcount(),
columns=['dup_cnt'])
feature_dup_df = feature_dup_df.reset_index()
new_feature_name_df = pd.merge(old_feature_name_df.reset_index(),feature_dup_df,how='outer')
new_feature_name_df['column_name']=new_feature_name_df[['column_name','dup_cnt']].apply(lambda x:x[0]+'_'+str(x[1])
if x[1]>0 else x[0],axis=1)
new_feature_name_df = new_feature_name_df.drop(['index'],axis=1)
return new_feature_name_df
def get_human_dataset( ):
# 각 데이터 파일들은 공백으로 분리되어 있으므로 read_csv에서 공백 문자를 sep으로 할당.
feature_name_df = pd.read_csv('./human_activity/features.txt',sep='\s+',
header=None,names=['column_index','column_name'])
new_feature_name_df = get_new_feature_name_df(feature_name_df)
# DataFrame에 피처명을 컬럼으로 부여하기 위해 리스트 객체로 다시 변환
feature_name = new_feature_name_df.iloc[:, 1].values.tolist()
# 학습 피처 데이터 셋과 테스트 피처 데이터을 DataFrame으로 로딩. 컬럼명은 feature_name 적용
X_train = pd.read_csv('./human_activity/train/X_train.txt',sep='\s+', names=feature_name)
X_test = pd.read_csv('./human_activity/test/X_test.txt',sep='\s+', names=feature_name)
# 학습 레이블과 테스트 레이블 데이터을 DataFrame으로 로딩하고 컬럼명은 action으로 부여
y_train = pd.read_csv('./human_activity/train/y_train.txt',sep='\s+',header=None,names=['action'])
y_test = pd.read_csv('./human_activity/test/y_test.txt',sep='\s+',header=None,names=['action'])
# 로드된 학습/테스트용 DataFrame을 모두 반환
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_human_dataset( )
#0.9263657957244655(90) 0.9253478113335596(100) 0.9280624363759755(200)
rf_clf = RandomForestClassifier(random_state=0,n_estimators=300)
rf_clf.fit(X_train,y_train)
pred = rf_clf.predict(X_test)
accuracy = accuracy_score(y_test,pred)
accuracy
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators':[100],
'max_depth':[6,8,10,12],
'min_samples_leaf':[8,12,18],
'min_samples_split':[8,16,20]
}
rf_clf = RandomForestClassifier(random_state=0,n_jobs=-1)
grid_cv = GridSearchCV(rf_clf,param_grid=params,cv=2,n_jobs=-1)
grid_cv.fit(X_train,y_train)
print(grid_cv.best_params_)
print(grid_cv.best_score_)
rf_clf1 = RandomForestClassifier(n_estimators=300,
max_depth=10,
min_samples_leaf=8,
min_samples_split=8,
random_state=0)
rf_clf1.fit(X_train,y_train)
pred = rf_clf1.predict(X_test)
accuracy_score(y_test,pred)3. lightbgm
아나콘다 프롬프트 설치코드
conda install -c conda-forge lightgbm
lightgbm code 정리
from lightgbm import LGBMClassifier
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
dataset = load_breast_cancer()
X_train,X_test,y_train,y_test=train_test_split(dataset.data,
dataset.target,
test_size=0.2,
random_state=156)
lgbm = LGBMClassifier(n_estimators=400)
evals=[(X_test,y_test)]
lgbm.fit(X_train,y_train,
early_stopping_rounds=100,
eval_metric='logloss',
eval_set=evals,verbose=True)
pred = lgbm.predict(X_test)
pred_proba = lgbm.predict_proba(X_test)[:,1]
from sklearn.linear_model import LogisticRegression #Ctrl + Shift + - 커서를 기준으로 작업열 분리시킴
from sklearn.metrics import confusion_matrix,accuracy_score, precision_score, recall_score, f1_score, precision_recall_curve,roc_auc_score
def get_clf_eval(y_test,pred):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test,pred)
precision = precision_score(y_test,pred)
recall = recall_score(y_test,pred)
f1 = f1_score(y_test,pred)
roc_auc = roc_auc_score(y_test,pred)
print('오차행렬')
print(confusion)
print(f'정확도:{accuracy:.4f} 정밀도:{precision:.4f} 재현율:{recall:.4f} F1:{f1:.4f} AUC{roc_auc:.4f}' )
get_clf_eval(y_test,pred)
from lightgbm import plot_importance
import matplotlib.pyplot as plt
fig,ax = plt.subplots()
plot_importance(lgbm,ax=ax)4. 회귀소개
분석자료

#LinearRegression 클래스는 예측값과 실제 값의 RSS를 최소화해
#OLS(Ordinary Least Squares)추정 방식으로 구현한 클래스이다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_boston
boston = load_boston()
df = pd.DataFrame(boston.data,columns=boston.feature_names)
df['price'] = boston.target
df.head(2)
df.shape
df.info()
df.columns
lm_features = ['ZN', 'INDUS', 'NOX', 'RM', 'AGE','RAD','PTRATIO','LSTAT']
fig, axs = plt.subplots(figsize=(16,8),ncols=4, nrows=2)
for i, feature in enumerate(lm_features):
row = int(i/4)
col = i % 4
sns.regplot(y='price', x=feature, data=df, ax=axs[row][col])
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error,r2_score
y_target = df['price']
X_data = df.drop(['price'],axis=1)
X_train, X_test, y_train, y_test = train_test_split(X_data,y_target,test_size=0.3, random_state=156)
lr = LinearRegression()
lr.fit(X_train,y_train)
pred = lr.predict(X_test)
mse = mean_squared_error(y_test,pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test,pred)
print(f'mse:{mse:.3f} rmse:{rmse:.3f} r2:{r2:0.3f}')
lr.intercept_
lr.coef_
np.round(lr.coef_,1)
df.columns
from sklearn.model_selection import cross_val_score
result = cross_val_score(lr,X_data,y_target,scoring='neg_mean_squared_error',cv=5)
-1*result
np.sqrt(-1*result)
np.mean(np.sqrt(-1*result))

DataEngineer Lee.