📌 AI
게임을 구성함에 있어 오브젝트들이 마치 살아있는 것처럼 움직여야 할 상황들이 있다.
이런 경우에 게임 개발자는 그 오브젝트가 행위해야할 방향에 대해 정의허고 이를 다양한 방법으로 시뮬레이션 한다.
➔ 게임의 간단한 자연물 등을 시물레이션 할 때
자연물을 시뮬레이션 할 때 최적화된 연산을 위해서 간단한 상태를 두고, 상태 간 전환이 이뤄지면서 시뮬레이션하는 상태머신기반으로 구현한다 (FSM을 구현하는 경우가 대부분)
유니티에서는 StateMachine을 직접 구현할 수도 있고, 유니티에서 애니메이터에 확장하여 사용할 수 있는 StateMachineBehaviour를 제공한다.
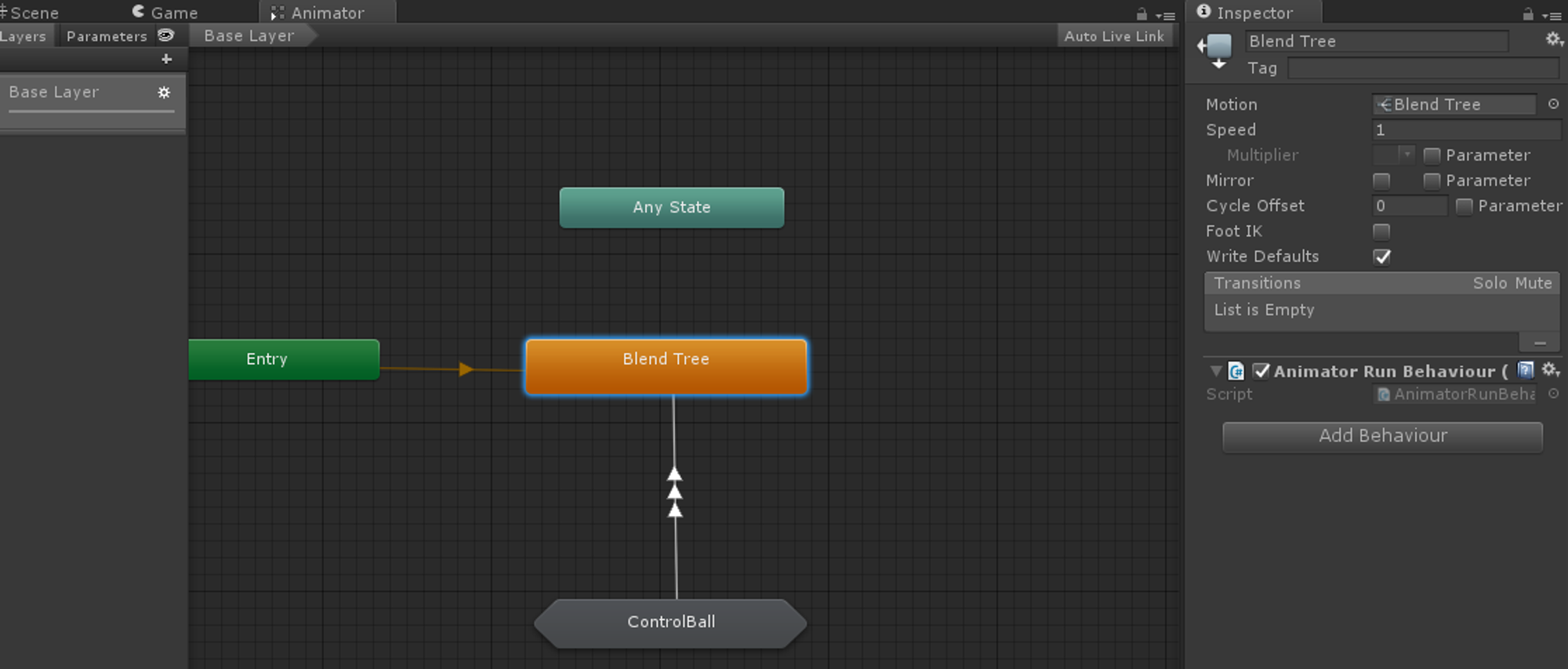
Unity StateMachineBehaviour
using UnityEngine;
public class AttackBehaviour : StateMachineBehaviour
{
public GameObject particle;
public float radius;
public float power;
protected GameObject clone;
override public void OnStateEnter(Animator animator, AnimatorStateInfo stateInfo, int layerIndex)
{
clone = Instantiate(particle, animator.rootPosition, Quaternion.identity) as GameObject;
Rigidbody rb = clone.GetComponent<Rigidbody>();
rb.AddExplosionForce(power, animator.rootPosition, radius, 3.0f);
}
override public void OnStateExit(Animator animator, AnimatorStateInfo stateInfo, int layerIndex)
{
Destroy(clone);
}
override public void OnStateUpdate(Animator animator, AnimatorStateInfo stateInfo, int layerIndex)
{
Debug.Log("On Attack Update ");
}
override public void OnStateMove(Animator animator, AnimatorStateInfo stateInfo, int layerIndex)
{
Debug.Log("On Attack Move ");
}
override public void OnStateIK(Animator animator, AnimatorStateInfo stateInfo, int layerIndex)
{
Debug.Log("On Attack IK ");
}
}➔ NPC등 복잡한 대상은 시뮬레이 할 때 (BehBehaviour Tree)
상태머신 기반으로 구현할 경우 명확한 상태로 구분을 해야하기 때문에 대상을 시뮬레이션하기가 어려울 수 있다. 이럴 때 활용할 수 있는게 Behaviour Tree 이며, 논리적인 순서도를 바로 활용하여 구현할 수 있다는 점이 장점인 방식이다.
BT에는 아래와 같은 요소들이 있다.
-
루트(root) 노드 : CS에서의 트리의 뿌리는 제일 아래에 있지 않고 제일 위에 있다.
-
흐름 제어 노드 (flow-control node) :
- Sequence node : AND 역할을 하는 노드
- Selector node : OR 역할을 하는 노드
-
리프(leaf) 노드 : 실제 행동이 들어가 있는 노드
Node 구현
public enum NodeState
{
Running,
Failure,
Success
}
public abstract class Node
{
protected NodeState state;
public Node parentNode;
protected List<Node> childrenNode = new List<Node>();
public Node()
{
parentNode = null;
}
public Node(List<Node> children)
{
foreach(var child in children)
{
AttatchChild(child);
}
}
public void AttatchChild(Node child)
{
childrenNode.Add(child);
child.parentNode = this;
}
public abstract NodeState Evaluate();
}
public class SequenceNode : Node
{
public SequenceNode() : base() {}
public SequenceNode(List<Node> children) : base(children) {}
public override NodeState Evaluate()
{
bool bNowRunning = false;
foreach (Node node in childrenNode)
{
switch (node.Evaluate())
{
case NodeState.Failure:
return state = NodeState.Failure;
case NodeState.Success:
continue;
case NodeState.Running:
bNowRunning = true;
continue;
default:
continue;
}
}
return state = bNowRunning ? NodeState.Running : NodeState.Success;
}
}
public class SelectorNode : Node
{
public SelectorNode() : base(){}
public SelectorNode(List<Node> children) : base(children){}
public override NodeState Evaluate()
{
foreach(Node node in childrenNode)
{
switch(node.Evaluate())
{
case NodeState.Failure:
continue;
case NodeState.Success:
return state = NodeState.Success;
case NodeState.Running:
return state = NodeState.Running;
default:
continue;
}
}
return state = NodeState.Failure;
}
}
예시
플레이어가 멀리 떨어지면 따라오는 펫에 대한 BT를 구현한다고 생각해보자. BT에서는, 해당 상황을 아래와 같이 나타낼 수 있다.
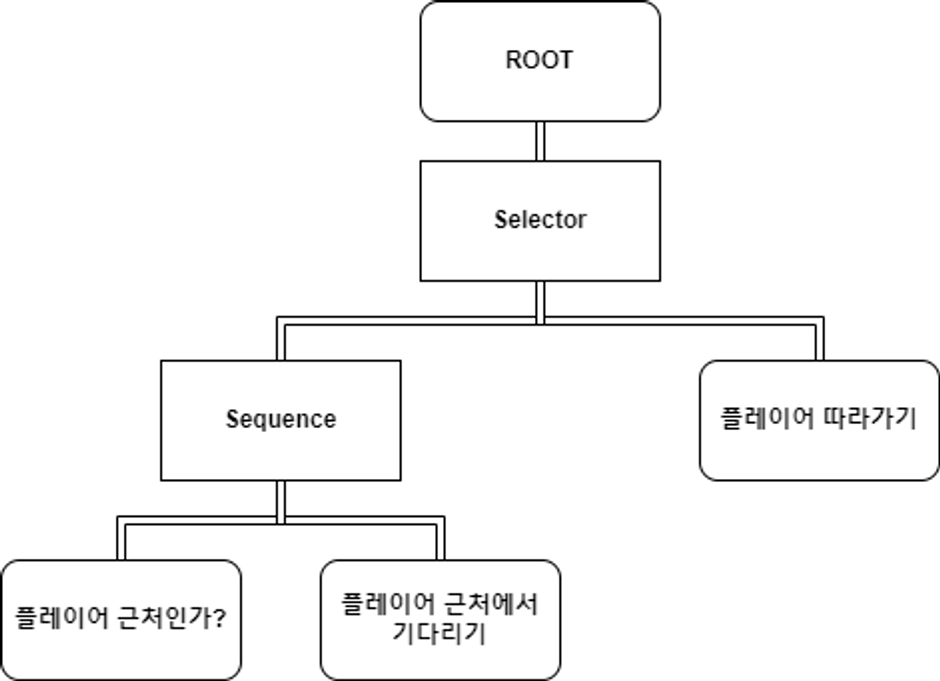
public class CheckPlayerIsNearNode : Node
{
private static int playerLayerMask = 1 << 6;
private Transform transform;
private Animator anim;
public CheckPlayerIsNear(Transform transform)
{
this.transform = transform;
anim = transform.GetComponent<Animator>();
}
public override NodeState Evaluate()
{
var collider = Physics.OverlapSphere(transform.position, 5.0f, playerLayerMask);
if(collider.Length <= 0) return state = NodeState.Failure;
anim.SetBool("Following", false);
return state = NodeState.Success;
}
}
public class StayNearPlayerNode : Node
{
private Animator anim;
public StayNearPlayerNode(Transform transform)
{
anim = transform.GetComponent<Animator>();
}
public override NodeState Evaluate()
{
anim.SetBool("Following", false);
return state = NodeState.Running;
}
}
public class GoToPlayerNode : Node
{
private Transform player;
private Transform transform;
private Animator anim;
public GoToPlayerNode(Transform player, Transform transform)
{
this.player = player;
this.transform = transform;
anim = transform.GetComponent<Animator>();
}
public override NodeState Evaluate()
{
transform.LookAt(player);
transform.position = Vector3.Lerp(transform.position, player.position, Time.deltaTime);
anim.SetBool("Following", true);
return state = NodeState.Running;
}
}
public class FollowingPlayerPetBT : AG.GameLogic.BehaviorTree.Tree //UnityEngine.Tree와 겹쳐서..
{
[SerializeField]
private Transform player;
[SerializeField]
private Transform pet;
protected override Node SetupBehaviorTree()
{
Node root = new SelectorNode(new List<Node>
{
new SequenceNode(new List<Node>
{
new CheckPlayerIsNear(pet),
new StayNearPlayerNode(pet)
}),
new GoToPlayerNode(player, pet)
});
return root;
}
}
Tree 구현
public abstract class Tree : MonoBehaviour
{
private Node rootNode;
protected void Start()
{
rootNode = SetupBehaviorTree();
}
protected void Update()
{
if(rootNode is null) return;
rootNode.Evaluate();
}
protected abstract Node SetupBehaviorTree();
}FSM과 BT는 서로 상호배타적이지 않고, 큰 상태는 FSM이 관리하고 그 안에서의 세부 행위를 BT가 관리하게 하는 등 하이브리드로 구현할 수도 있다.
➔ 룰을 내가 생각하고 싶지 않을 때
유니티에서는 머신 러닝(강화학습) 기반으로 AI 에이전트를 만들 수 있는 ML Agent를 제공한다.
ML Agent에서의 강화학습은 인공지능(AI) 에이전트가 환경과 상호작용하며 학습하는 과정을 말한다. 이 과정에서 에이전트는 환경으로부터 보상을 받으며, 어떤 행동이 좋은 결과를 가져오는지 학습한다. 강화학습은 주로 시행착오를 통해 학습하는 방식으로, 에이전트는 다양한 상황에서 다양한 행동을 시도하며 최적의 행동 방식을 찾아간다. 이러한 방식은 체스나 바둑과 같은 게임뿐만 아니라 자율 주핸 자동차, 로봇 공학 등 다양한 분야에서 응용된다.
ML Agent에서 강화학습을 구현할 때, 개발자는 에이전트에게 어떤 상황에서 어떤 보상을 줄 것인지 정의해야 한다. 예를 들어, 비디오 게임에서 적을 물리차면 보상을 주고, 장애물에 부딪히면 벌점을 주는 방식이다. 강화학습 알고리즘은 이러한 보상을 기반으로 에이전트가 최대한 많은 보상을 받을 수 있는 행동을 학습하도록 돕는다. 이 과정은 복잡한 문제를 해결하기 위해 점진적으로 학습하는 인공지능의 능력을 강화하는 데 크게 기여한다.
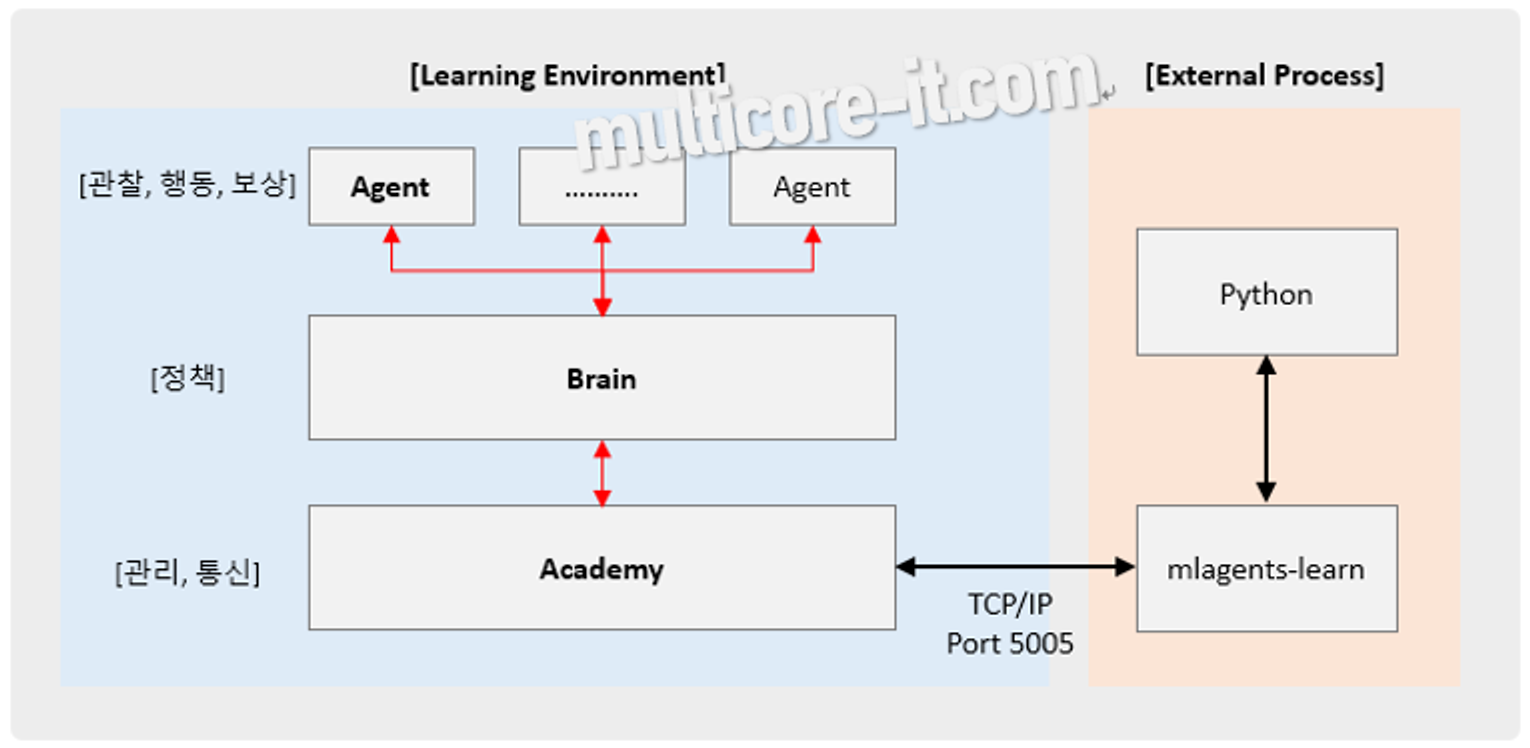
다만, 학습에 있어 C#으로만 할 수있었던 다른 방법들과는 달리 딥러닝 라이브러리인 Tensorflow 등에 익숙해야 하고, 라이브러리의 구조가 매우 변화무쌍하여 개발자들에게 어려움을 주는 라이브러리이니 참고하고 레퍼런스를 확인해야 한다.
📌 A* 알고리즘
A*는 그래프에서 최단거리를 찾는 알고리즘으로, 다익스트라와 함께 가장 많이 알려진 알고리즘이다. 다익스트라와의 가장 큰 차이는 방문할 노드를 선택할 때 휴리스틱을 활용한다는 것으로, 휴리스틱을 어떤 것울 활용하느냐에 따라 알고리즘의 성능이 무한정으로 좋아질 수도, 무한정으로 안좋아질 수도 있는 것이다.
📌 휴리스틱
휴리스틱은 문제 해결이나 의서 결정 과장에서 직관적이고 경험적인 방법을 의미한다. 이는 종종 복잡하고 어려운 문제를 더 빠르고 효율적으로 해결하기 위해 사용된다. 휴리스틱은 완벽한 해답을 찾는 것이 아니라, 실용적이고 합리적인 해답을 빠르게 찾는 데 중점을 둔다.
A 알고리즘에서 활용하는 휴리스틱은 경로 탐색 문제를 해결하는 데 사용되는 예측적인 방법이다. A 알고리즘은 시작 지점에서 목표 지점까지의 최단 경로를 찾기 위해 사용되며, 이 과정에서 휴리스틱 함수는 각 노드에서 목표 지점까지의 예상 최소 비용을 추정한다. 이 추정장치는 알고리즘이 탐색해야 할 경로를 결정하는 데 도움을 준다. 즉, 휴리스틱 함수는 알고리즘에게 어떤 경로가 '아마도' 최적에 가까울지 가이드를 제공한다.
g(n) → 이번 단계에서 다음 단계까지 가는 비용(예) 0→1 / 0→3)
h(n) → 휴리스틱을 통해 예측한 다음 단계에서 최종 목적지까지 가는 비용 (예) 1→6 / 3→6)
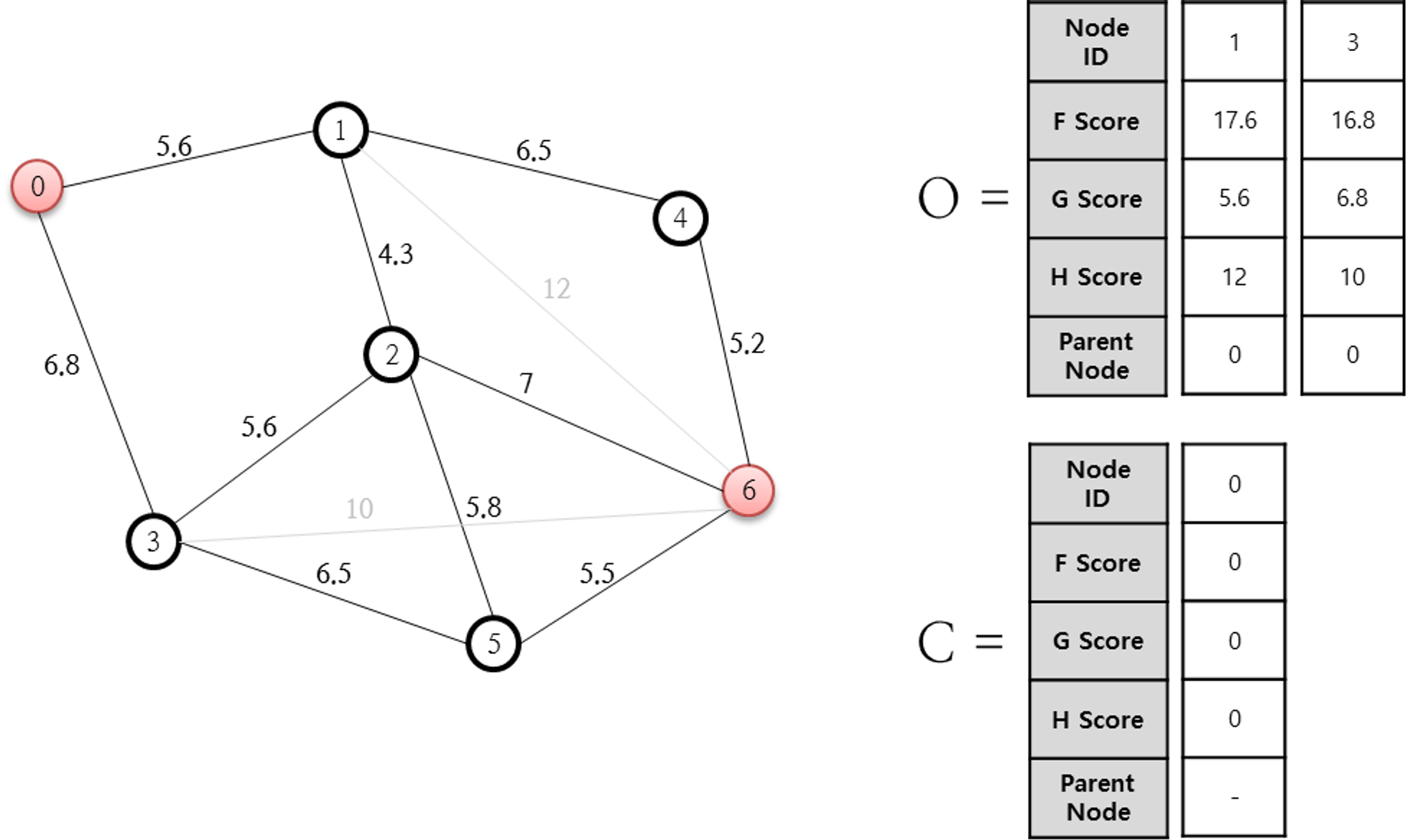
➔ 의사코드
function A*(start, goal)
// 이미 실행했던 노드들 '닫힌 목록'
closedSet := {}
// 아직 실행하지 않았지만 이제 탐색할 노드들 '열린 목록'
// 초기에는, 시작 노드만 들어있습니다.
openSet := {start}
// 각가장 효율적인 경로를(노드들을) 담습니다.
cameFrom := the empty map
// 각 노드별 시작 노드로부터의 거리를 담습니다. (기본 비용은 Infinity, 최소비용을 찾는 것이므로)
gScore := map with default value of Infinity
// 처음 노드는 시작 노드이므로 gScore는 0입니다.
gScore[start] := 0
// 시작 노드로부터의 비용, 목적 노드까지의 비용 두 가지가 합산된 비용입니다.
fScore := map with default value of Infinity
// 첫 번째 노드는 시작 노드로부터의 비용이 0이고, 목적 노드까지는 heuristic한 추정 비용입니다. // 그러므로, 첫 노드의 전체 비용은 추정값만 있을 뿐 입니다. fScore[start] := heuristic_cost_estimate(start, goal)
// '열린 목록'이 비어있을 때까지 반복합니다.
while openSet is not empty // '열린 목록'에서 가장 적은 f값을 가지는 노드 current := the node in openSet having the lowest fScore[] value // 목적 노드입니까?
if current = goal // 길 찾기를 완료하였으니 경로를 만듭니다.
return reconstruct_path(cameFrom, current)
// 목적노드가 아니라면 '열린 목록'에서 삭제하고 '닫힌 목록'에 넣습니다.
openSet.Remove(current)
closedSet.Add(current)
// 최소 비용으로 선택한 노드의 인접 노드들을 바라봅니다.
for each neighbor of current // 인접 노드가 이미 '닫힌 목록'에 들어있다면 무시하고 넘어갑니다. (이미 실행해 본것이므로)
if neighbor in closedSet
continue
// '열린 목록'에 들어있지 않다면 추가합니다.
if neighbor not in openSet
openSet.Add(neighbor)
// current 노드까지의 gScore + current 노드로부터 인접 노드까지 거리를 구합니다. // 시작 노드로부터 인접 노드까지 gScore가 current 노드를 거쳐 // 인접 노드까지 가는 비용보다 싸다면 이 경로는 무시합니다. tentative_gScore := gScore[current] + dist_between(current, neighbor) if tentative_gScore >= gScore[neighbor]
continue
// current 노드를 거쳐서 가는 것이 더 좋다고 생각되면 기록합니다.
cameFrom[neighbor] := current
gScore[neighbor] := tentative_gScore
fScore[neighbor] := gScore[neighbor] + heuristic_cost_estimate(neighbor, goal)
return failure
function reconstruct_path(cameFrom, current)
total_path := [current]
while current in cameFrom.Keys:
current := cameFrom[current]
total_path.append(current)
return total_path
출처: https://itmining.tistory.com/69 [IT 마이닝:티스토리]📌 NavMesh
게임엔진에서 활용되는 AI중 가장 많이 활용되는 분야가 길찾기이다. 길찾기는 경로를 정의하지 않아도 미리 혹은 실시간으로 길을 찾을 수 있도록하는 AI의 한 분야이다.

NavMesh(네비게이션 메시)는 Unity엔진의 기능 중 하나로, 게임 캐릭터나 AI에이전트거 이동할 수 있는 가상의 경로를 생성하고 관리하는 데 사용된다. NavMesh를 사용하면 캐릭터나 AI에이전트가 장애물을 피하거나 정해진 경로를 따라 이동할 수 있다.
아래 설명은 새롭게 변경된 NavMesh를 기준으로 작성된 내용들이다.
➔ NavMesh 개요
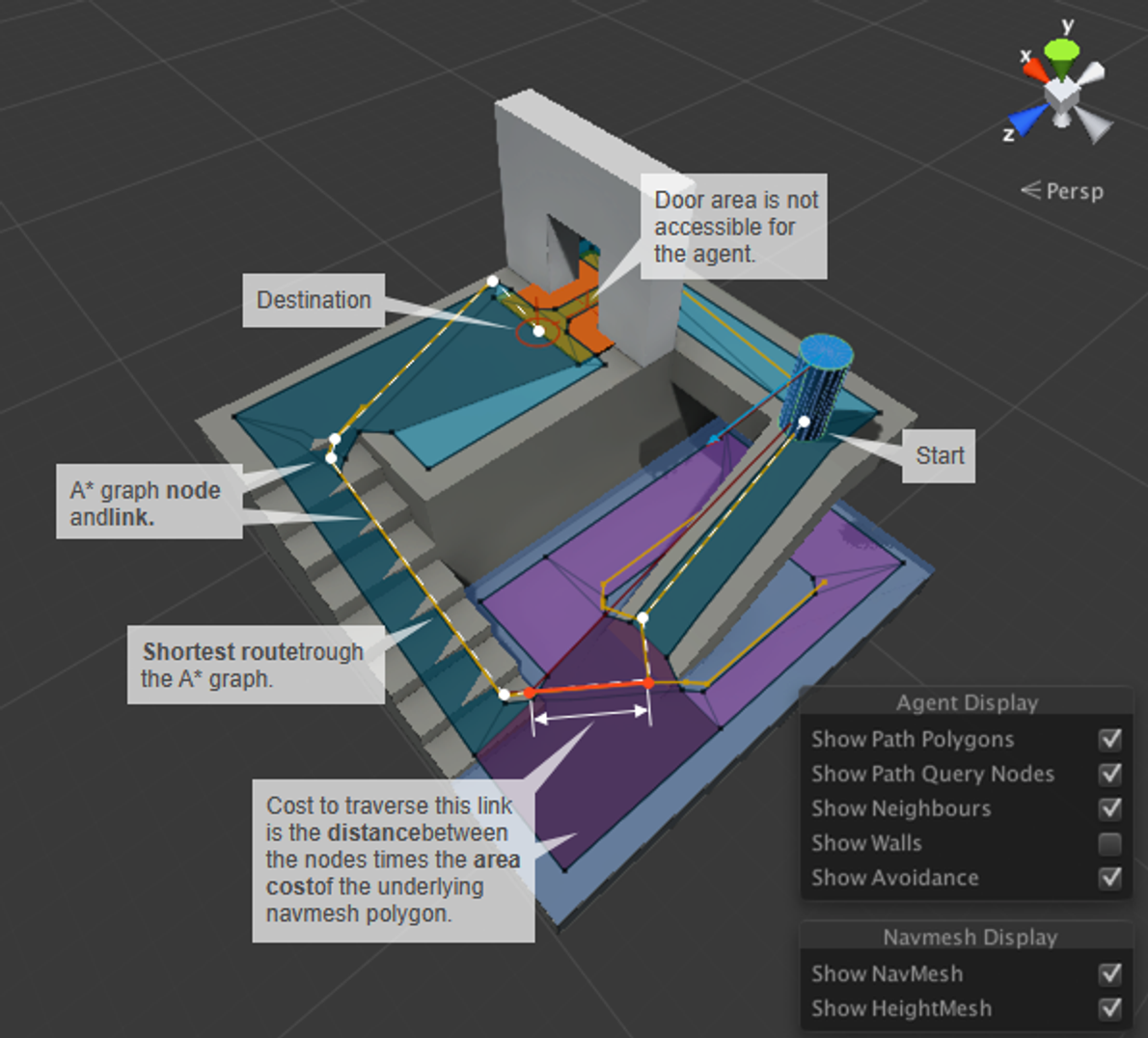
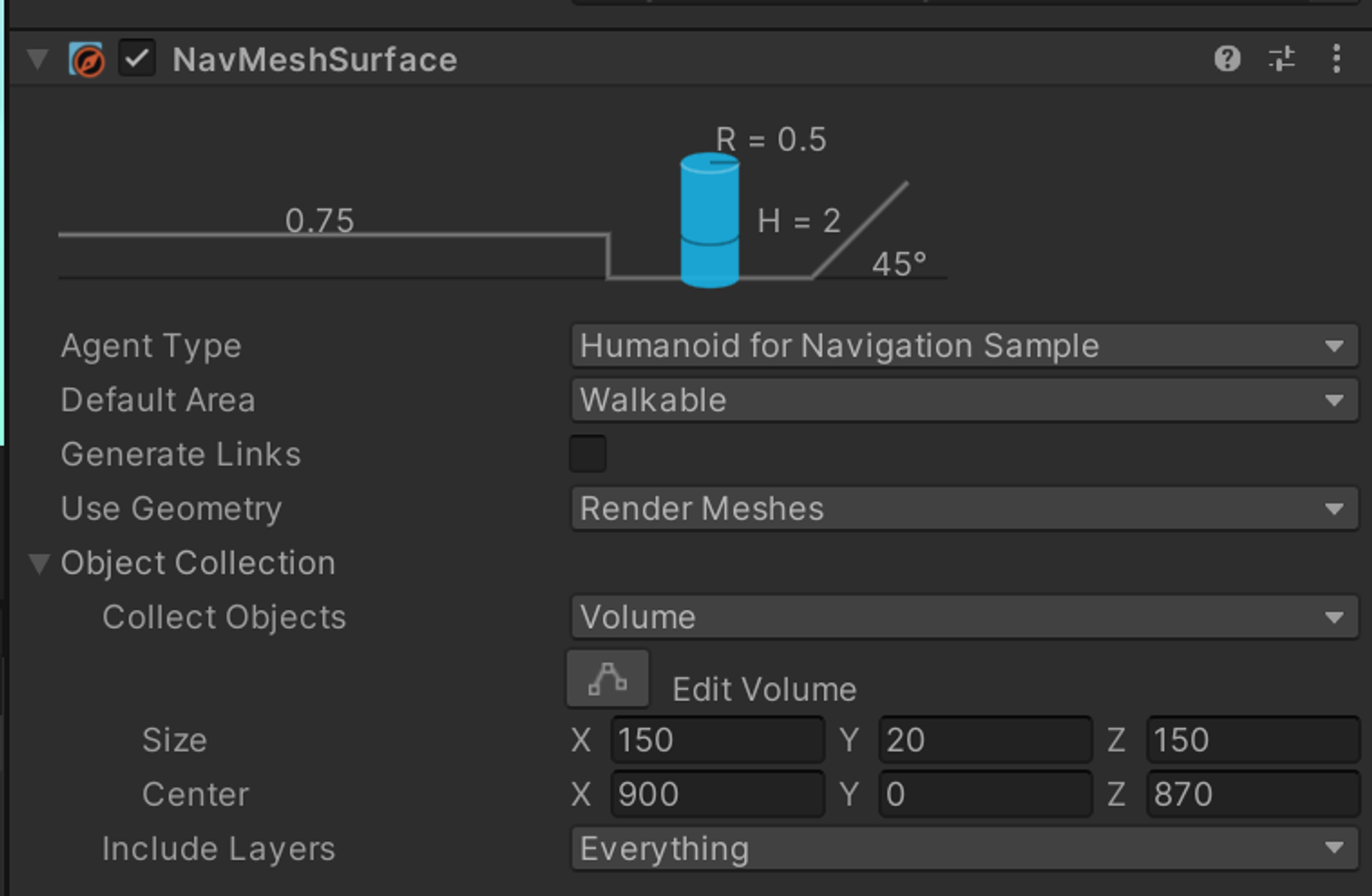
➔ NavMsh Surface
기존(구 Navmesh)에 있던 Bake 기능이 이쪽으로 넘어왔다. 신규 NavMeshSurface의 가장 큰 장점은 동적 베이킹으로, 실시간으로 변화되는 환경에서의 길찾기가 가능하다. 이에 대한 최적화를 위해 Volume 안에 있는 오브젝트만 길찾기에 포함하는 등의 작업이 가능하다.
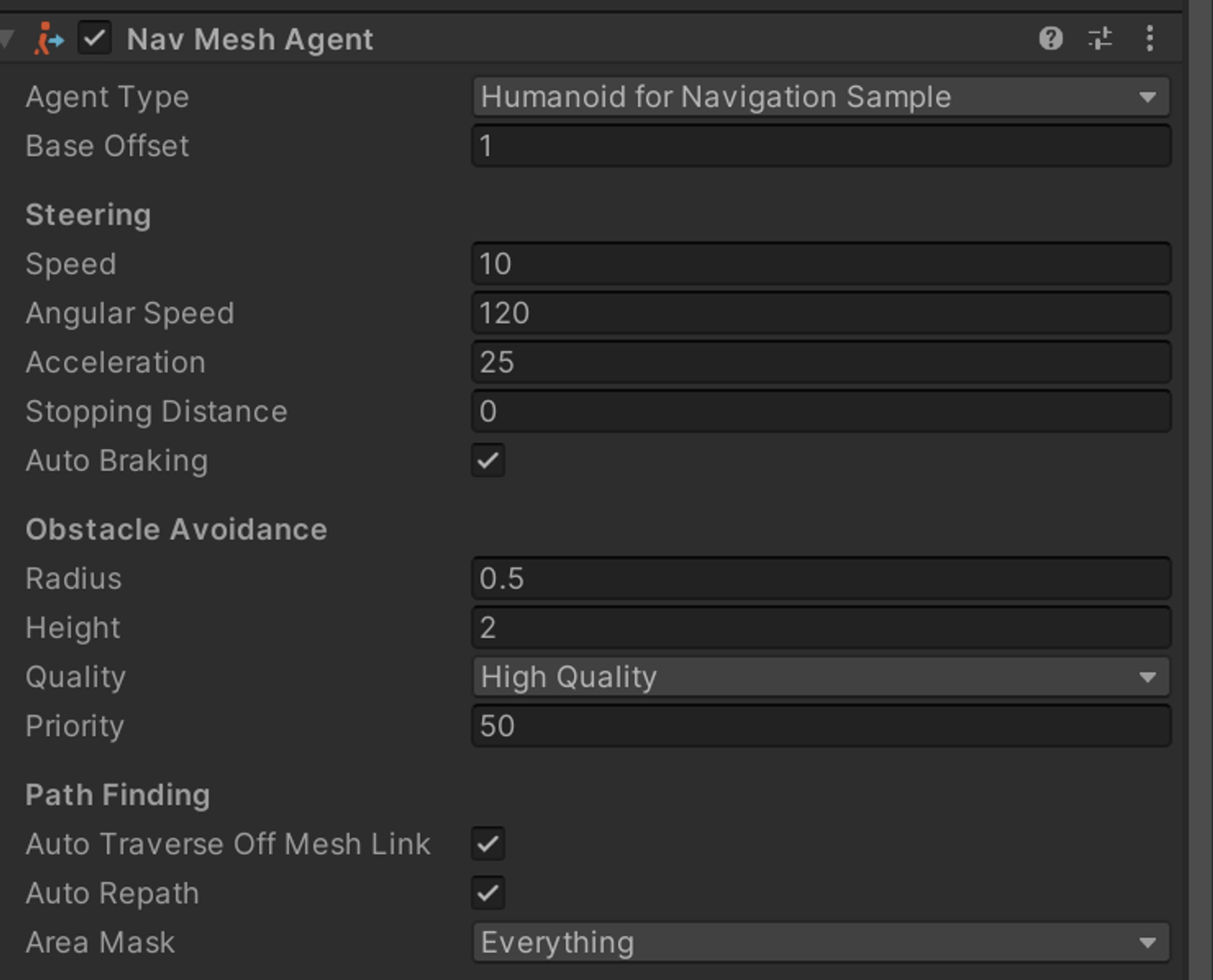
➔ NavMeshAgent
NavMeshAgent는 NavMesh위에서 이동하는 캐릭터나 AI에이전트를 제어하는 구성 요소이다.
NavMeshAgent는 속도, 회전, 도착 여부 등을 제어할 수 있는 다양한 기능을 제공한다.
➔ NavMeshObstacle
NavMeshObstacle은 움직이는 탱크처럼, 움직이면서 길을 막아버리는 동적 오브젝트를 말한다.
Carve를 선택하는 경우, 네비메시의 이동가능 경로를 파먹는 식으로 구현이 된다.
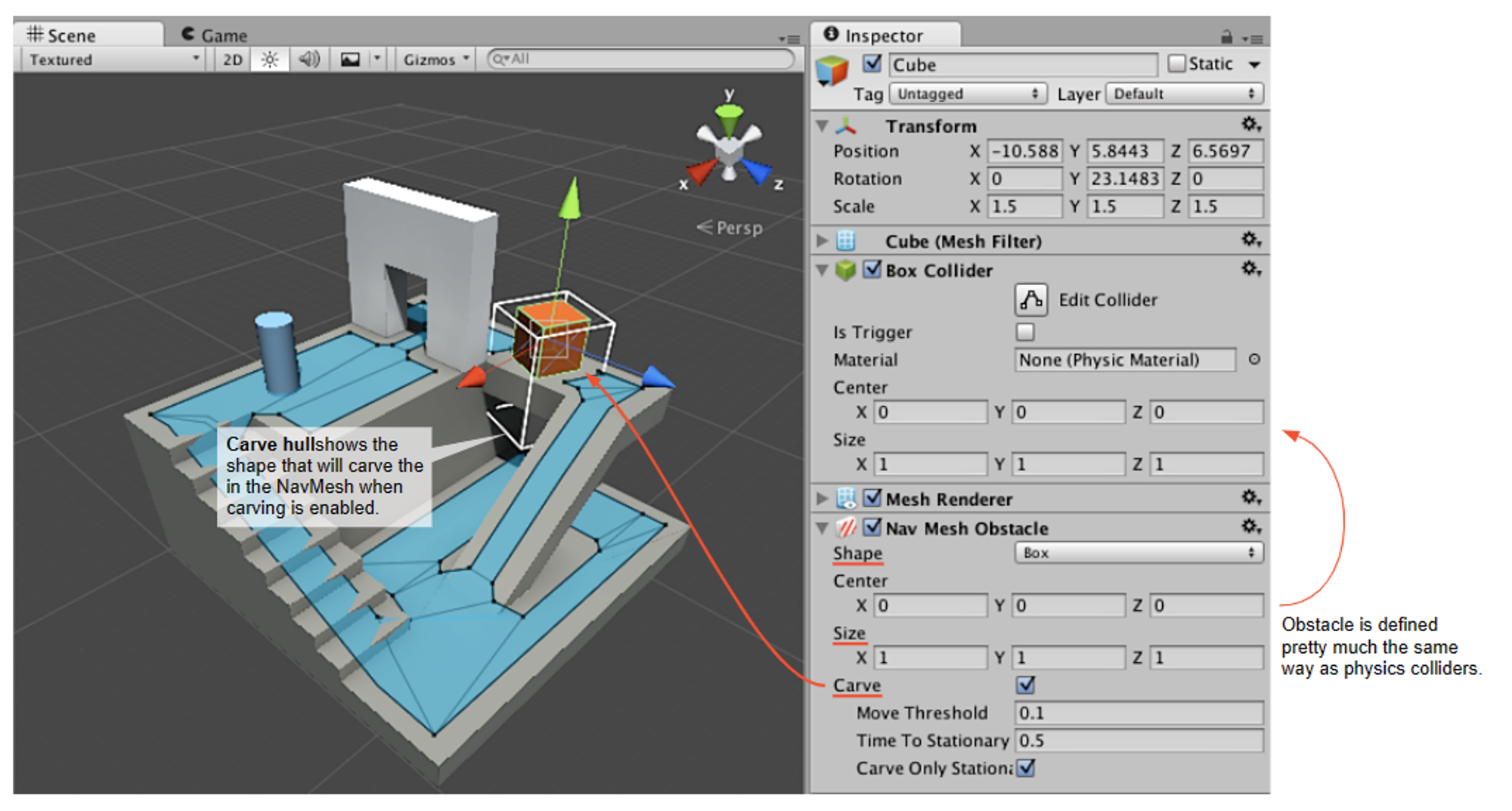
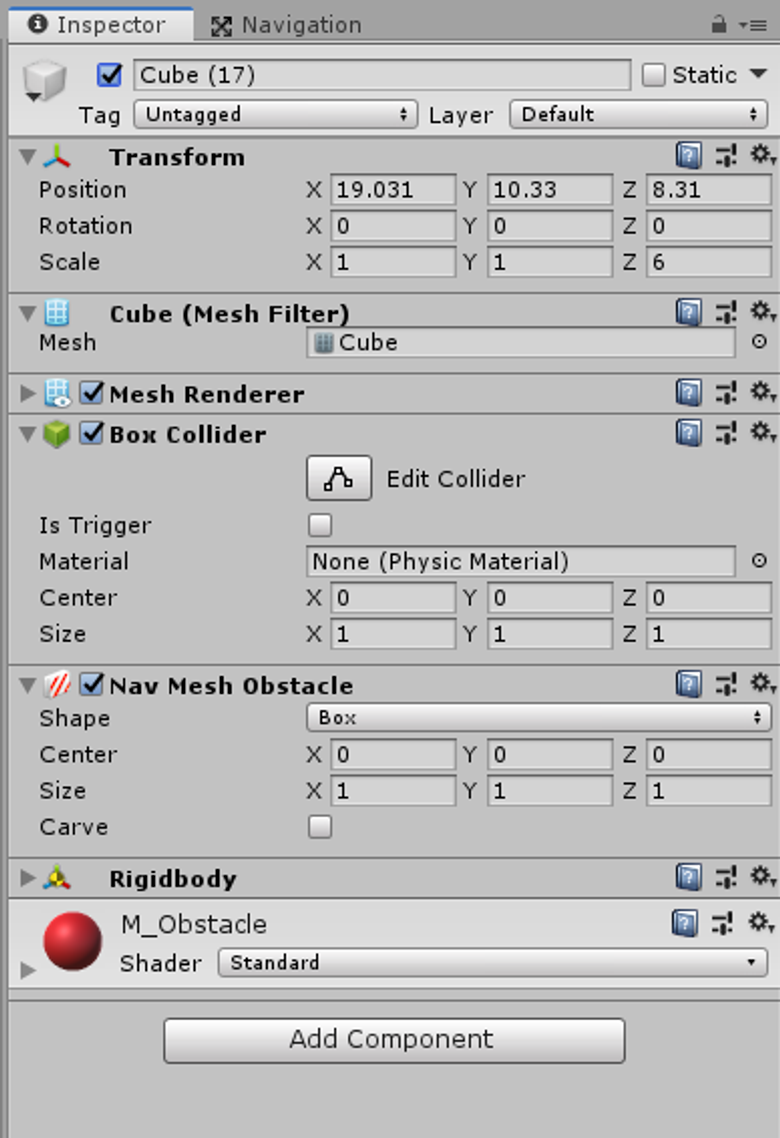
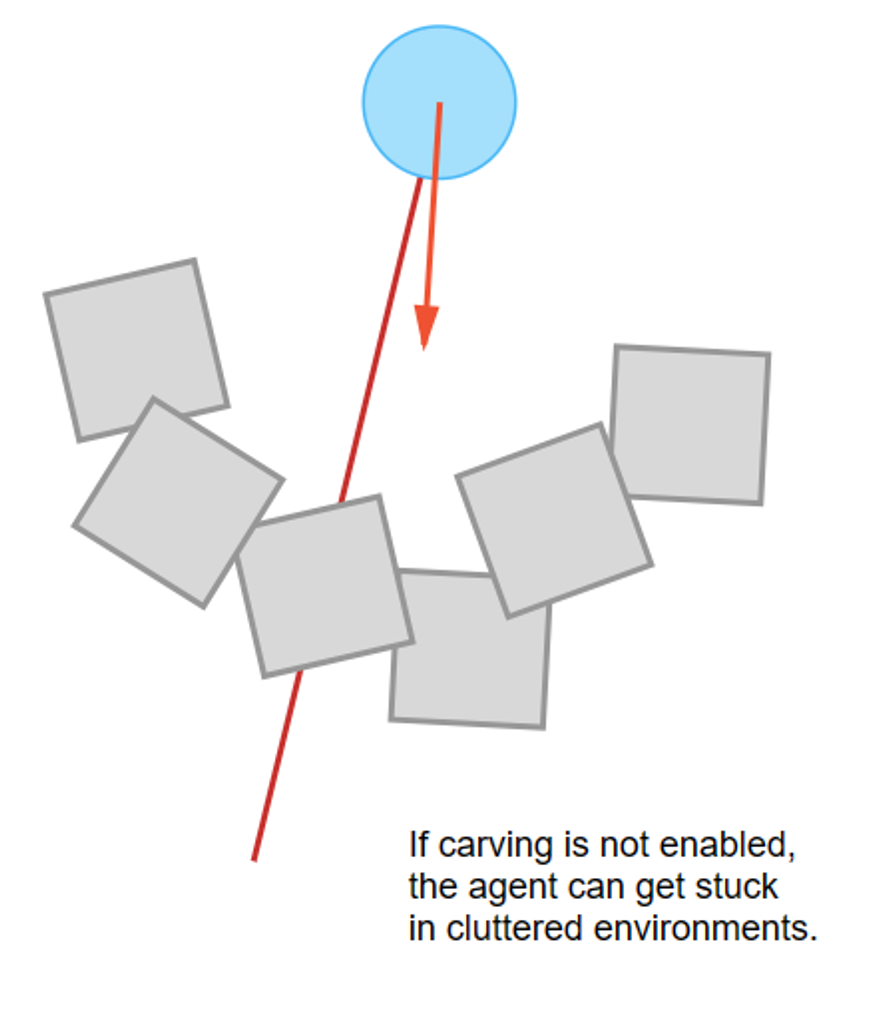
➔ Areas
특정한 경로의 이동 가중치를 부여하는 개념으로, 예를 들어 물이라는 경로가 있고, 그 물의 경로 가중치가 5라면, 아래와 같이 구현할 수 있다.
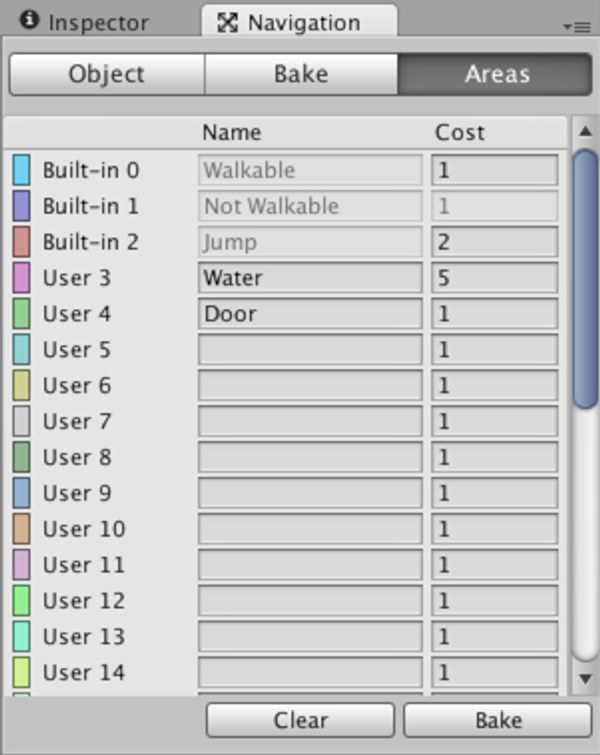
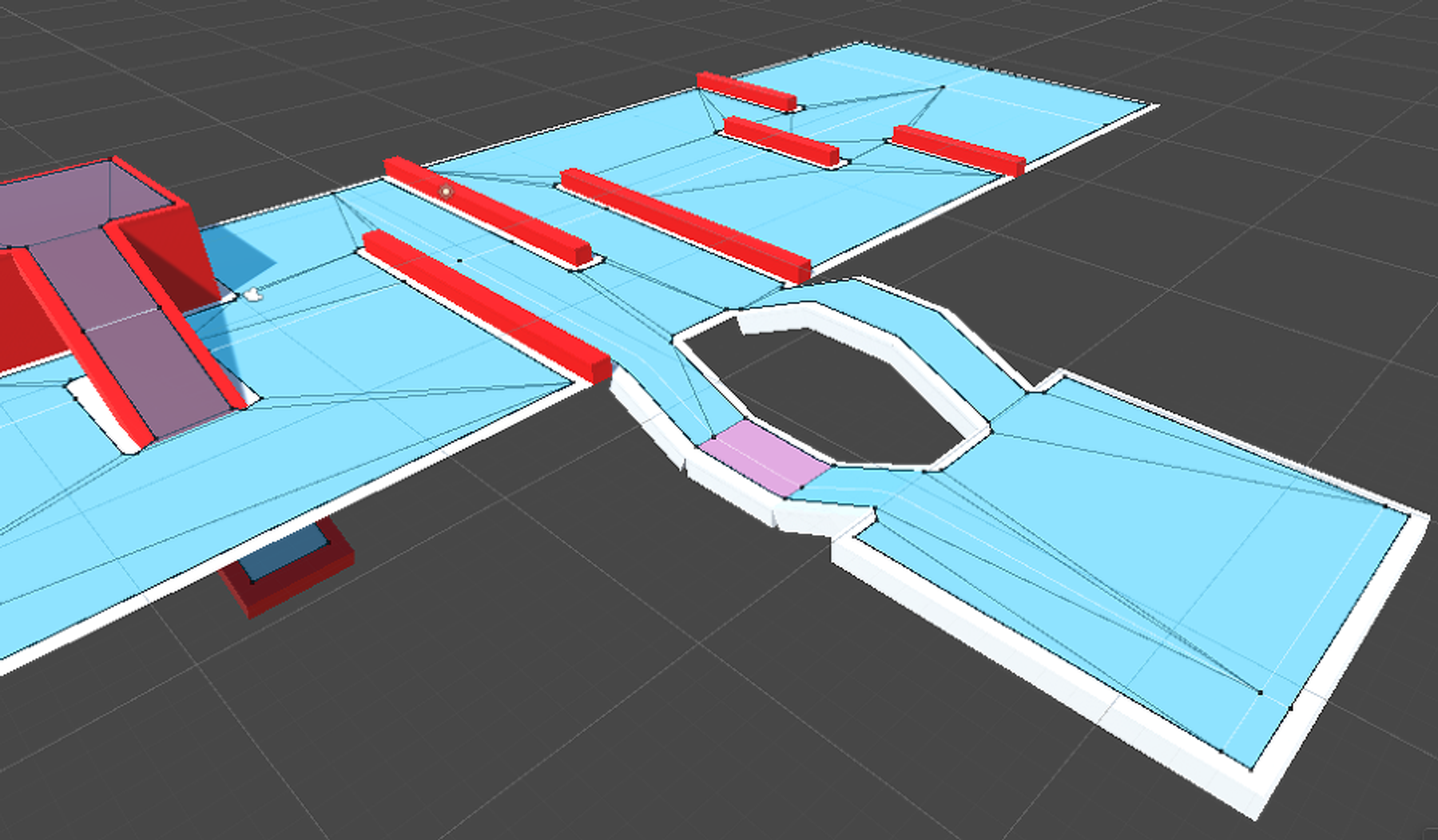
예시
NavMseh를 이용하여 패트롤을 구현할 수 있다.
아래 코드는 모듈러 연산을 활용해 특정한 구역을 반복적으로 들도록 구현한다.
// Patrol.cs
using UnityEngine;
using UnityEngine.AI;
using System.Collections;
public class Patrol : MonoBehaviour {
public Transform[] points;
private int destPoint = 0;
private NavMeshAgent agent;
void Start () {
agent = GetComponent<NavMeshAgent>();
// Disabling auto-braking allows for continuous movement
// between points (ie, the agent doesn't slow down as it
// approaches a destination point).
agent.autoBraking = false;
GotoNextPoint();
}
void GotoNextPoint() {
// Returns if no points have been set up
if (points.Length == 0)
return;
// Set the agent to go to the currently selected destination.
agent.destination = points[destPoint].position;
// Choose the next point in the array as the destination,
// cycling to the start if necessary.
destPoint = (destPoint + 1) % points.Length;
}
void Update () {
// Choose the next destination point when the agent gets
// close to the current one.
if (!agent.pathPending && agent.remainingDistance < 0.5f)
GotoNextPoint();
}
}