https://velog.io/@hjongc/Pandas-Profiling-%ED%95%9C%EA%B8%80-%EA%B9%A8%EC%A7%90-%ED%95%B4%EA%B2%B0
위 자료를 참고했다.
옆자리 동기분이 ydata-profiling 패키지를 소개(?)해주셨다!
EDA를 할 때 하나하나 확인하고 있었는데,
이 패키지를 쓰니 데이터 전체적 개요를 파악하기 너무 편했다.
ydata-profiling 패키지 사용 팁
- 결과는 꼭 노트북파일에서 보지 말고, html파일로 따로 저장해서 보도록 하자
- 노트북 파일에서 보려고 아무 생각 없이 셀 실행시켰다가 결과 용량이 너무 커서인지 그동안의 모든 출력들이 날아갔었다(...)
- 분석 대상 변수에서 "꼭!" 범주형 데이터를 모두 제거해주자. 범주형 데이터가 들어가면 결과 용량이 너무 커지더라.
- 결과 용량이 커질 경우, html파일이 제대로 열리지 않는다. 나같은 경우 수치형 데이터만 넣었음에도 불구하고 결과 html 파일이 70mb정도 나왔는데, 결국은 분석 대상 변수를 축소시켜 용량을 줄였다.
- 웬만하면 heatmap은 seaborn사용해서 따로 추출하고, ydata-profiling의 결과를 html로 저장할 때 simple옵션을 주어 간단한 정보만 저장되도록 하자.
(이건 사실 과정이 잘 기억이 안남.)
profile report 추출 시 연속형 데이터 -> 범주형 데이터 자동 변환 방지
profile = df.profile_report(vars={"num": {"low_categorical_threshold": 0}})나같은 경우, 기존에 연속형 데이터임에도 불구하고 자꾸 범주형 데이터로 인식되는 문제가 발생했다.
여기서 또 한 시간 날렸다 ㅋㅋ
위 코드처럼 low_categorical_threshold 변수 지정을 해주면 된다.
이름에서 유추할 수 있다시피, 수치형임에도 불구하고 unique한 값이 threshold(default: 5) 이하인 경우 범주형 데이터로 인식한다.
즉, 저렇게 변수 지정을 해줌으로써 threshold를 0으로 하고, 모든 수치형 데이터는 unique 한 값이 몇 개든 상관없이 수치형으로 보겠다는 것이다.
ydata-profiling 결과 파일에서 한글 출력 오류 해결 방안
- matplotlib 기반 시각화 시 한글 깨짐 오류가 있는 것과 같이, 비슷한 오류가 발생한다.
좀 복잡하지만, 이것도 패키지 파일을 수정해줌으로써 오류를 해결해주면 된다.
pip show <패키지 명>위 커맨드 실행 시 패키지 설치 경로가 출력된다. (패키지 관련 정보 출력)
- (패키지설치경로)/visualisation/context.py
위 파일을 수정해주면 된다.
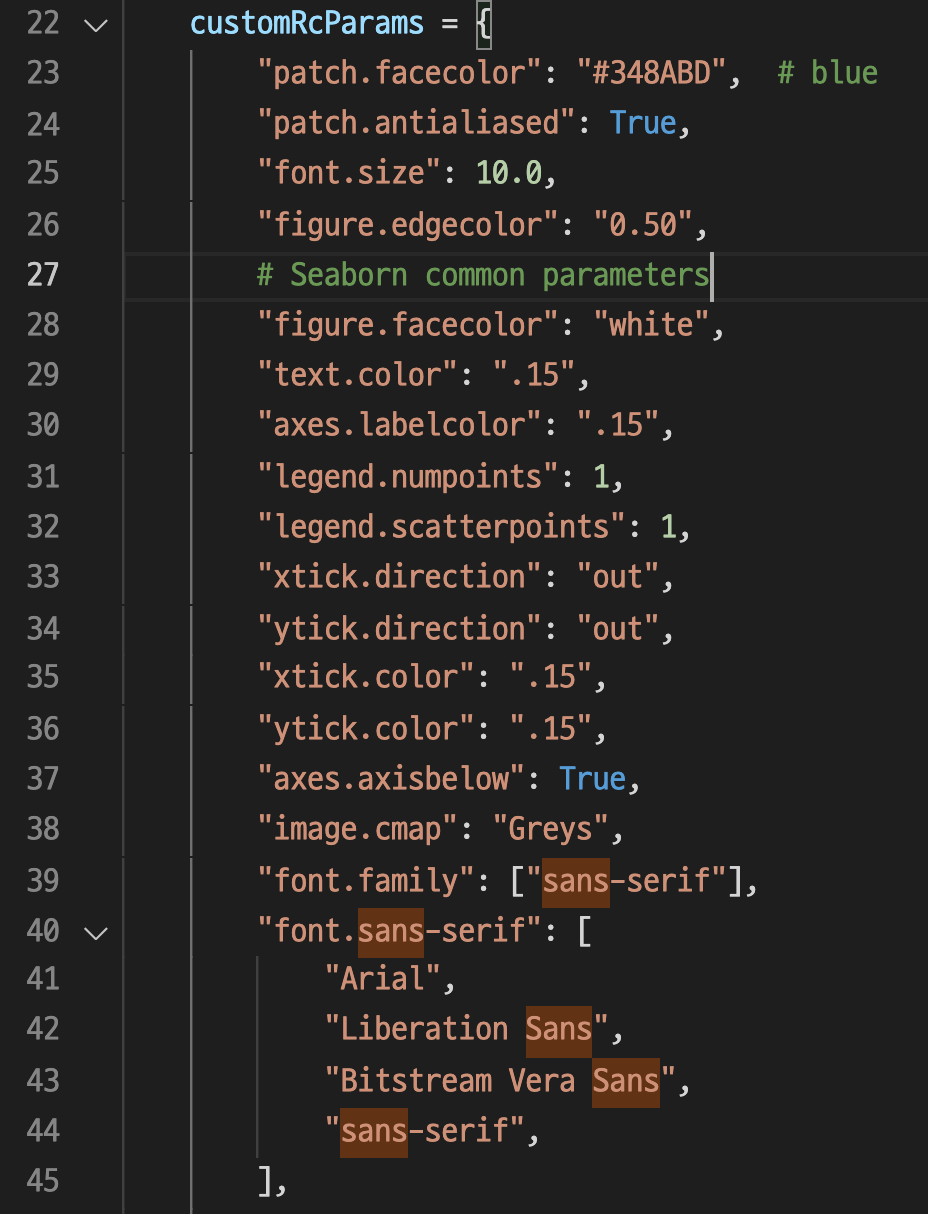
여기에서 "font.family":["sans-serif"]
부분을 Windows 환경이라면 "Malgun Gothic"으로, Mac 환경이라면 "AppleGothic"으로 변경해준다.
그리고 중요한 부분!!!
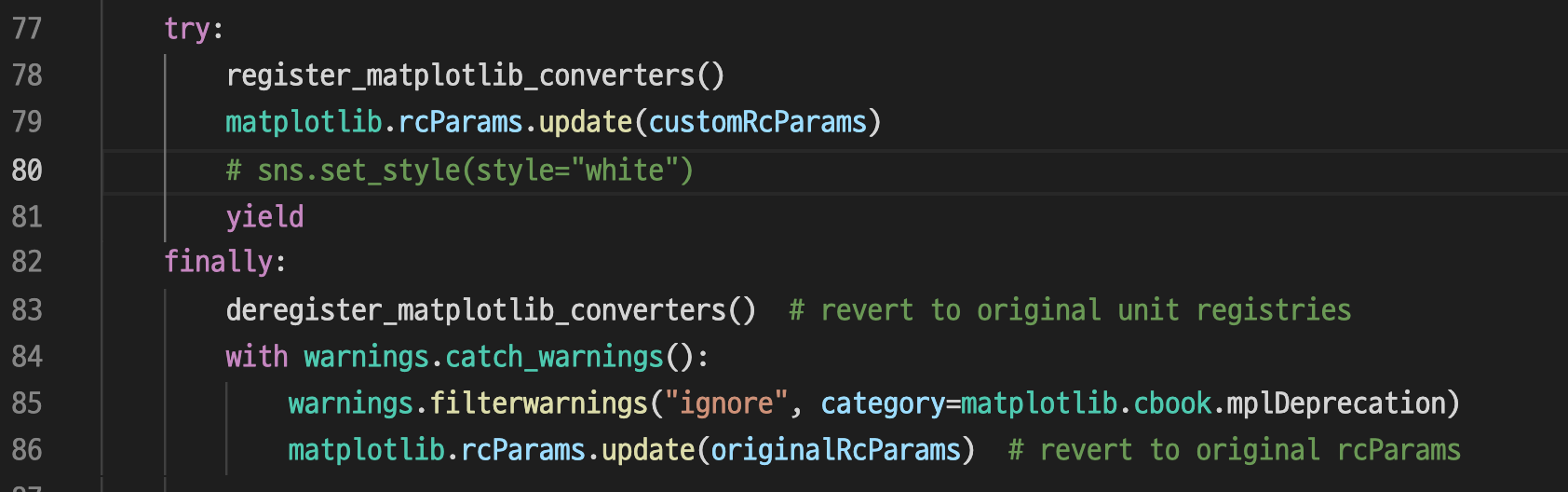
이렇게 seaborn 관련 부분도 주석처리해줘야된다.
내 경우, 이걸 안해줬더니 계속 오류나더라.
만약 이래도 적용이 잘 안 된다면, vsc를 껐다 켜는 등 설정이 재적용될 수 있도록 해주면 된다.
