내 코드가 그렇게 이상한가요?

1장. 잘못된 구조의 문제 깨닫기
1.1. 의미를 알 수 없는 이름
기술 중심 명명
class MemoryStateManager {
void changeIntValue0(int changeValue) {
...
}
}일련번호 명명
class Class001 {
void method001();
void method002();
}- 기술 중심 명명, 일련 번호 명명 은 어떠한 의도도 읽어낼 수 없음
1.2. 이해하기 어렵게 만드는 조건 분기 중첩
조건 분기 처리를 많이 하지 말아라
1.3. 수많은 악마를 만들어 내는 데이터 클래스
public class ContractAmount {
public int amountIncludingTax;
public BigDecimal salesTaxRate;
}- 데이터를 갖고 있기만 하는 클래스
- 세금이 포함된 금액을 계산하는 로직도 필요
- 이러한 계산 로직을 데이터 클래스가 아닌 다른 클래스에 구현하게 됨
- 설계를 따로 고려하지 않아 생기는 일
1.3.1. 사양을 변경할 때 송곳니를 드러내는 악마
- 로직이 여러 군데 번져 있으면, 응집도가 낮아져 여러 문제가 발생할 수 있음
1.3.2. 코드 중복
1.3.3. 수정 누락
1.3.4. 가독성 저하
1.3.5. 초기화되지 않은 상태 (쓰레기 객체)
- 초기화되지 않으면 잘못된 데이터가 들어가는 클래스
- 추가로 초기화해야 하는 클래스는 버그가 발생하기 쉬운 불완전한 클래스
즉
- 초기화하기 않으면 쓸모 없는 클래스
- 초기화하지 않은 상태가 발생할 수 있는 클래스
1.3.6. 잘못된 값 할당
- 잘못된 값이 들어가지 않게, 데이터 클래스를 사용하는 쪽의 로직을 살짝 변경해서 유효성을 검사하게 만들 수 있음
1.4. 악마 퇴치의 기본
- 나쁜 구조의 폐해를 인지해야 함
- 나쁜 폐해를 인지하면 어떻게든 대처해야겠다고 생각
- 이 생각이 바로 좋은 설계를 위한 첫걸음
2장. 설계 첫걸음
2.1. 의도를 분명히 전달할 수 있는 이름 설계하기
int d = 0;
d = p1 + p2;- 무언가를 계산하고 있지만 무엇을 하고 있는지 전혀 이해할 수 없음
int damageAmount = 0;
damageAmount = playerArmPower + playerWaponPower;- 자주 바뀔 가능서이 있는 코드를 구현할 때는 변수 이름을 쉽게 붙이는 것도 아주 훌륭한 기본 설계가 될 수 있음
2.2. 목적별로 변수를 따로 만들어 사용하기
- 계산의 중간 결과를 동일한 변수에 계속해서 대입하는 코드가 많이 사용
- 변수의 값을 다시 할당하는 것을
재할당이라고 함 - 재할당은 변수의 용도가 바뀌는 문제를 일으키기 쉬움
재할당으로 기존 변수를 다시 사용하지 말고, 목적별로 변수를 만들어서 사용
int totalPlayerAttackPower = playerArmPower + playerWeaponPower;
int totalEnemyDefence = enemyBodyDefence + enemyArmorDefence;- 어떤 값을 계산하는 데 어떤 값을 사용하는 지 관계를 파악하기 훨씬 쉬움
2.3. 단순 나열이 아니라, 의미 있는 것을 모아 메서드로 만들기
- 일련의 흐름이 그냥 작성되어 있으면, 계산 로직들이 단순하게 나열되어 있으면, 로직이 어디에서 시작해서 어디에서 끝나는지, 무슨 일을 하는 지 알기 어려움
- 이러한 상황을 막으려면, 의미 있는 로직을 모아서 메서드로 구현하는 것이 좋음
int sumUpPlayerAttackPower(int playerArmPower, int playerWeaponPower) {
return playerArmPower + playerWeaponPower;
}totalPlayerAttackPower = sumUpPlayerAttackPower(playerArmPower, playerWeaponPower)- 세부 계산 로직을 메서드로 감쌌으므로, 일련의 흐름이 훨씬 쉽게 읽힘
- 또한 서로 다른 계산 작업을 각각의 메서드로 분리했으므로 쉽게 구분 가능
설계= 유지보수와 변경이 쉽도록 변수의 이름과 로직을 신경써서 개발하는 것
2.4. 관련된 데이터와 로직을 클래스로 모으기
int hitPoint;hitPoint = hitPoint - damageAmount;
if (hitPoint < 0) {
hitPoint = 0;
}- 이런 로직들이 계속해서 이곳저곳 만들어짐 > 버그가 발생할 확률이 높음
- 이러한 문제를 해결해 주는 것이
클래스
class HitPoint {
private static final MIN = 0;
private static final MAX = 9999;
final int value;
HitPoint(final int value) {
if (value < MIN) throw new IllegalArgumentException();
if (value > MAX) throw new IllegalArgumentException();
this.value = value;
}
...
}- 서로 밀접한 데이터와 로직을 한 곳에 모아 두면, 이곳저곳 찾아 다니지 않아도 괜찮음
- 잘못된 값이 유입되지 않게 만들면, 조금이나마 버그로부터 안전한 클래스 구조가 됨
3장. 클래스 설계: 모든 것과 연결되는 설계 기반
3.1. 클래스 단위로 잘 동작하도록 설계하기
- 클래스 단위로도 잘 동작하게 설계해야 한다
3.1.1. 클래스의 구성 요소
- 인스턴스 변수
- 메서드
- 이러한 구성에서 버그를 일으키는 악마를 적게 불러오려면, 메서드의 역할을 명확하게 해야함
- 잘 만들어진 클래스는 다음 두가지로 구성
- 인스턴스 변수
- 인스턴스 변수에 잘못된 값이 할당되지 않게 막고, 정상적으로 조작하는 메서드

- 데이터 클래스는 일반적으로 인스턴스 변수를 조작하는 로직이 다른 클래스에 구현
- 연관성을 어려워서 부차적인 문제가 생길 수 있음
문제 1. 코드가 중복될 수 있고 중복 코드 중 일부를 그대로 둠
-> 가독성 저하
문제 2. 인스턴스를 생성하더라도 인스턴스 변수들은 아직 유효하지 않아 따로 초기화
-> 데이터 클래스는 초기화 작업을 하는 코드조차 다른 클래스에 구현
-> 데이터 클래스가 자기 자신을 보호할 수 있는 로직이 없음
3.1.2. 모든 클래스가 갖추어야 하는 자기 방어 임무
- 따로 초기화하지 않거나 사전 준비를 하지 않으면 사용할 수 없는 클래스와 메서드는 아무도 사용하고 싶지 않아함
- 기본적인 단위 (메서드, 클래스, 모듈 등)은 그 자체로 버그 없이, 언제나 안전하게 사용할 수 있는 품질을 갖춰야 함
- 클래스는 스스로
자기 방어 임무를 수행할 수 있어야 품질을 높일 수 있음
3.2. 성숙한 클래스로 성장시키는 설계 기법
class Mony {
int amount;
Currency currency;
}- 전형적인 데이터 클래스
3.2.1. 생성자로 확실하게 정상적인 값 설정하기
raw data object: default 생성자 (매개변수 없는 생성자) 를 사용해서 인스턴스를 생성한 후, 인스턴스 변수에 따로 값을 할당해서 초기화 = 초기화 하지 않은 상태
클래스 인스턴스를 생성하는 시점에 확실하게 인스턴스 변수가 정상적인 값을 갖게 만들어야 함
class Mony {
int amount;
Currency currency;
Money(int amount, Currency currency) {
if (amount < 0) {
throw new IllegalArgumentException();
}
if (currency == null) {
throw new IllegalArgumentException();
}
this.amount = amount;
this.currency = currency;
}
}3.2.2. 계산 로직도 데이터를 가진 쪽에 구현하기
- 응집도가 낮은 구조 : 데이터와 데이터를 조작하는 로직이 분리되어 있는 구조
3.2.3. 불변 변수로 만들어서 예상하지 못한 동작 막기
- 변수의 값이 계속해서 바뀌면, 값이 언제 변경되었는지, 지금 값은 무엇인지 계속 신경써야함
- 따라서 예상치 못한 부수 효과가 발생할 수 있음
class Mony {
final int amount;
final Currency currency;
Money(int amount, Currency currency) {
this.amount = amount;
this.currency = currency;
}
}final수식자를 붙이면 한 번만 할당 할 수 있음- 인스턴스 변수에 잘못된 값을 직접 할당할 수 없음
3.2.4. 변경하고 싶다면 새로운 인스턴스 만들기
class Mony {
...
Money add(int other) {
int added = amount + other;
return new Money(added, currency);
}
}3.2.5. 메서드 매개변수와 지역 변수도 불변으로 만들기
- 메서드 내부에서 매개 변수 변경
void doSomething(int value) {
value = 100;- 값이 중간에 바뀌면, 값의 변화를 추적하기 힘듬
void doSomething(final int value) {
value = 100; // compile error- method 의 재할당을 막음
3.2.6. 엉뚱한 값을 전달하지 않도록 하기
- 엉뚱한 값이 전달되지 않도록 하려면, Money 자료형만 매개변수로 받을 수 있게 메서드를 변경
class Mony {
...
Money add(final Money other) {
final int added = amount + other.amount;
return new Money(added, currency);
}
}- int 자료형이면 다른 값을 잘 못 전달해도 컴파일 오류가 발생하지 않음
- 프로그래밍 언어가 표준적으로 제공하는 자료형 :
primitive type - 따라서 실수로 의미가 다른 값을 전달하기 쉬움
3.2.7. 의미 없는 메서드 추가하지 않기
class Money {
...
Money multiple(Money other) {
if (!currency.equals(other.currency)) {
throw new IllegalArgumentException();
}
final int multiplied = amount * other.amount;
return new Money(multiplied, currency);
}
}- mutiple 을 하는 값은 필요 없음
- 따라서 필요 없는 method 는 추가하지 않는 것이 좋음
3.3. 악마 퇴치 효과 검토하기
class Money {
final int amount;
final Currency currency;
Money(final int amount, final Currency currency) {
if (amount < 0) {
throw new IllegalArgumentException();
}
if (currency == null) {
throw new IllegalArgumentException();
}
this.amount = amount;
this.currency = currency;
}
Money add(final Money other) {
if (!currency.equals(other.currency)) {
throw new IllegalArgumentException();
}
final int added = amount + other.amount;
return new Money(added, currency);
}
}클래스 설계= 인스턴스 변수가 잘못된 상태에 빠지지 않게 하기 위한 구조를 만드는 것응집도가 놓은 구조: 로직이 한 곳에 모여있는 구조캡슐화: 데이터를 조작하는 로직은 묶고, 필요한 절차만 외부에 공개하는 것
3.4. 프로그램 구조의 문제 해결에 도움을 주는 디자인 패턴
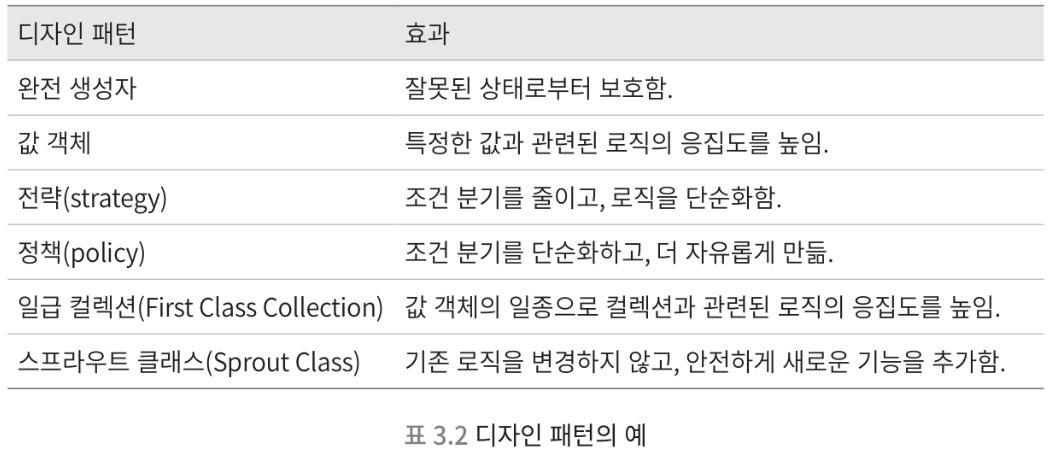
앞의 Money class 는 완전 생성자와 값 객체라는 두자기 디자인 패턴이 적용됨
3.4.1. 완전 생성자 (complete constructor)
- 잘못된 상태로부터 클래스를 보호하기 위한 디자인 패턴
- 인스턴스 변수를 초기화하지 않은 객체들이 생성 > 쓰레기 객체가 만들어지는 것을 방지
- final 수식자를 붙여서 불변으로 만들면, 생성 후에도 잘못된 상태로부터 방어 가능
3.4.2. 값 객체 (Value Object)
- 값을 class 로 나타내는 디자인 패턴
값 객체 + 완전 생성자객체 지향 설계에서 폭넓게 사용되는 기법
4장. 불변 활용하기: 안정적으로 동작하게 만들기
4.1. 재할당
- 변수에 값을 다시 할당하는 것 =
재할당,파괴적 할당
4.1.1. 불변 변수로 만들어서 재할당 막기
- 재할당을 기계적으로 막을 수 있는 방법 = 변수에 final 수식자 붙이기
void doSomething() {
final int vlaue = 100;
value = 200; // compile error4.1.2. 매개변수도 불변으로 만들기
- 재할당을 막으려면 매개변수에도 final 을 붙이면 됨
void addPrice(final int productPrice) {
final int increasedTotalPrice = totalPrice + productPrice;
}4.2. 가변으로 인해 발생하는 의도하지 않은 영향
- 인스턴스가 가변이면 다른 부분에 의도하지 않은 영향을 주기 쉬움
- 코드를 변경했을 때 생각하지도 못했던 위치에서 상태가 변화하여 예측하지 못한 동작을 하는 경우가 있음
4.2.1. 사례 1: 가변 인스턴스 재사용하기
AttackPower attackPower = new AttackPower(20);
Weapon weaponA = new Weapon(attackPower);
Weapon weaponB = new Weapon(attackPower);attackPower를 변경하면weaponA,weaponB에서 동시에 변경- 이러한 상황을 방지하려면 인스턴스를 재사용하지 못하게 만들면 됨
AttackPower attackPowerA = new AttackPower(20);
Weapon weaponA = new Weapon(attackPowerA);
AttackPower attackPowerB = new AttackPower(20);
Weapon weaponB = new Weapon(attackPowerB);4.2.2. 사례 2: 함수로 가변 인스턴스 조작하기
class AttackPower {
...
void reinforce(int increment) {
value += increment;
}
void disable() {
value = MIN;
}
}AttackPower attackPower = new AttackPower(20);
attackPower.reinforce(15);- 이렇게 코드를 변경했는데, 갑자기 값이 변경되는 일이 발생
- 다른 쓰레드에서 공격력을 변경시킴
- 이렇게 동작하면 안됨 > 구조적인 문제를 가지고 있음 > 부수 효과
4.2.3. 부수 효과의 단점
주요 작용
- 함수 (method) 가 매개변수를 전달 받고, 값을 리턴하는 것
부수 효과
- 주요 작용 이외의 상태 변경을 일으키는 것
- 함수가 매개변수를 전달 받고 값을 리턴하는 것 이외에 외부 상태를 변경하는 것
attackPower.value- instance 변수를 변경하기 때문에, 작업 실행 순서에 의존해야 함
- 따라서 항상 같은 결과가 나온다고 보장할 수 없음
4.2.4. 함수의 영향 범위 한정하기
- 부수 효과가 있는 함수는 영향 범위를 예측하기 힘듬
- 예상치 못한 동작을 막으려면, 함수가 영향을 주거나 받을 수 있는 범위를 한정하는 것
- 데이터 (상태) 는 매개변수로 받음
- 상태를 변경하지 않음
- 값은 함수의 리턴 값으로 돌려줌
- 따라서 매개변수로 상태를 받고, 상태를 변경하지 않고, 값을 리턴하기만 하는 함수가 이상적
4.2.5. 불변으로 만들어서 예기치 못한 동작 막기
- 인스턴스 변수 value 가 가변적이므로, 부수 효과가 발생할 여지를 남김
- 기능 변경 때에도 의도하지 않게 부수효과가 있는 함수가 만들어져서, 예상하지 못한 동작을 일으킬 가능성은 항상 존재
class AttackPower {
static final int MIN = 0;
final int value;
...
AttackPower reinforce(final AttackPower increment) {
return new AttackPower(this.value + increment.value);
}
AttackPower disable() {
return new AttackPower(MIN);
}
}final AttackPower attackPower = new AttackPower(20);
...
final AttackPower reinforced = attackPower.reinforce(new AttackPower(15));final AttackPower disabled = attackPower.disable();- 새로운 인스턴스를 만들었으므로 변경 전과 변경 후의 공격력은 서로 영향을 주지 않음
4.3. 불변과 가변은 어떻게 다루어야 할까
4.3.1. 기본적으로 불변으로
- 변수의 의미가 변하지 않으므로 혼란을 줄일 수 있음
- 동작이 안정적이게 되므로 결과를 예측하기 쉬움
- 코드의 영향 범위가 한정적으로 유지 보수가 편리해짐
4.3.2. 가변으로 설계해야 하는 경우
- 기본적으로 불변으로 설계하는 것이 좋지만, 가변이 필요한 경우가 있음
Performance 가 중요한 경우
ex) 대량의 데이터를 빠르게 처리해야 하는 경우 등
- 불변이라면 값을 변경할 때 인스턴스를 새로 생성해야 함
- 만약 크기가 큰 인스턴스를 새로 생성하면서 시간이 오려 걸려 문제가 된다면 불변 보다는 가변을 사용하는 것이 더 좋음
4.3.3. 상태를 변경하는 메서드 설계하기
mutater: 상태를 변화시키는 메서드- 조건에 맞는 올바른 상태로 변경하는 mutater 로 바꿔보자
class HitPoint {
private static final int MIN = 0;
int amount;
void damage(final int damageAmount) {
final int nextAmount = amount - damageAmount;
}
boolean isZero() {
return amount == MIN;
}
}
class Member {
final HitPoint hitPoint;
final States states;
void damage(final int damageAMount) {
hitPoint.damage(damageAmount);
if (hitPoint.isZero()) {
states.add(StateType.dead);
}
}
}4.3.4. 코드 외부와 데이터 교환은 국소화하기
- 불변을 활용해서 아무리 신중하게 설계하더라도, 코드 외부와의 데이터 교환은 주의해야 함
- 파일을 읽고 쓰는 I/O 조작은 코드 외부의 상태에 의존
- 특별한 이유 없이 외부 상태에 의존하는 코드를 작성하면, 동작 예측이 힘들어지므로 문제가 발생할 가능성이 높음
Repository Patter: Database 의 영속화를 캡슐화하는 디자인 패턴
5장. 응집도: 흩어져 있는 것들
5.1. static method 오용
- static method 오용으로 응집도가 낮아지는 경우가 있음
class OrderManager {
static int add (int moneyAmount1, int moneyAmount2) {
return moneyAmount1 + moneyAmount2;
}
}- static method 로 정의하면 클래스의 인스턴스를 생성하지 않고, add method 호출 가능
moneyData1.amount = OrderManager.add(moneyData1.amount, moneyData2.amount);- moneyData 와 moneyData 를 조작하는 로직이 따로 있는 것이 문제
- 악마를 불러들이는 코드 (김태리가 따로 없음)
5.1.1. static method 는 인스턴스 변수를 사용할 수 없음
- static method 는 인스턴스 변수를 사용할 수 없음
- 따라서 응집도가 낮아질 수 밖에 없음
5.1.2. 인스턴스 변수를 사용하는 구조로 변경하기
응집도를 높이는 것: 인스턴스 변수와 인스턴스 변수를 사용하는 로직을 같은 클래스에 만드는 것
5.1.3. 인스턴스 메서드인 척하는 static method 주의하기
- static keyword 만 없을 뿐 static method 와 같은 문제를 갖고 있는 인스턴스 메서드도 자주 볼 수 있음
class PaymentManager {
private int discountRate;
...
int add(int moneyAmount1, int moneyAmount2) {
return moneyAmount1 + moneyAmount2;
}
}add는 인스턴스 변수를 사용하지 않으므로 static 과 다름이 없음- 인스턴스 메서드인 척 하는 static method 도 응집도를 낮춤
5.1.4. 왜 static method 를 사용할까?
- 객체 지향 언어를 사용할 때 절차 지향 언어의 접근 방법을 사용하려 하기 때문
- 절차 지향 언어에서는 데이터와 로직이 따로 존재하도록 설계
- 이러한 접근 방법을 객체 지향 언어에 적용하여 설계하면, 데이터와 로직을 별도의 클래스에 배치하게 됨
- static method 를 남용하지 않는 것이 중요
5.1.5. 어떠한 상황에서 static method 를 사용해야 좋을까?
- 응집도의 영향을 받지 않는 경우, static method 를 사용해도 괜찮음
ex) log 출력 전용 메서드, format 변환 메서드 등
5.2. 초기화 로직 분산
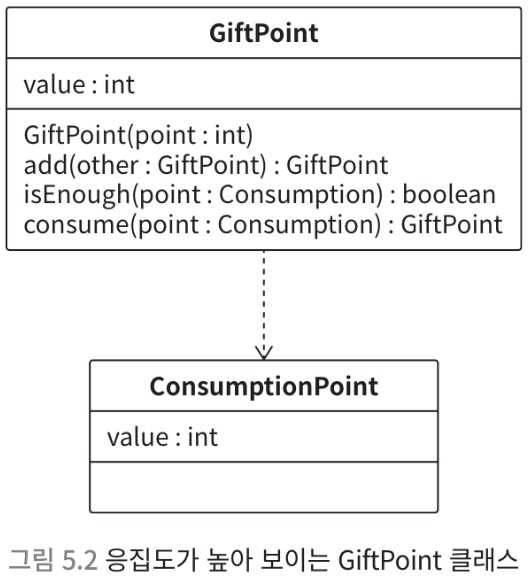
- 이 GiftPoint 클래스에 로직이 데이터와 응집되어 있는 것처럼 보임
GiftPoint standardMembershipPoint = new GiftPoint(3000);- 생성자를 public 으로 만들면 의도하지 않은 용도로 사용될 수 있음
- 관련 로직이 분산되기 때문에 유지 보수하기 힘들어짐
5.2.1. private 생성자 + 팩토리 메서드를 사용해 목적에 따라 초기화하기
class GiftPoint {
private static final int STANDARD_MEMBERSHIP_POINT = 3000;
private static final int PREMIUM_MEMBERSHIP_POINT = 10000;
...
static GiftPoint forStandardMembership() {
return new new GiftPoint(STANDARD_MEMBERSHIP_POINT);
}
static GiftPoint forPremiumMembership() {
return new new GiftPoint(PREMIUM_MEMBERSHIP_POINT);
}
...
}- Membership 이란 factory method 를 생성
5.2.2. 생성 로직이 너무 많아지면 팩토리 클래스를 고려해보자
- 생성 로직이 너무 많아지는 것 같다면, 생성 전용 팩토리 클래스를 분리하는 방법을 고려하는 것이 좋음
5.3. 범용 처리 클래스 (Common/Util)
- 범용 처리를 위한 클래스에는 Common, Util 이라는 이름이 붙음
- static method 와 마찬가지로 응집도가 낮은 구조가 만들어 질 수 있음
- 똑같은 일을 수행해야 하는 코드가 많아지면 코드를 재사용하기 위해 범용 클래스를 만듬
- 이때 static method 로 구현되는 경우가 많음
class Common {
static BigDecimal calcAmountIncludingTax(BigDecimal amountExcludingTax, BigDecimal taxRate) {
return amountExcludingTax.multiple(taxRate);
}
}- static method 는 응집도가 낮음
5.3.1. 너무 많은 로직이 한 클래스에 모이는 문제
- Common, Util 이라는 이름 자체가 범용이라는 뜻이기 때문에
- 사람들이 범용적으로 사용하고 싶은 로직은 Common class 에 만들면 되겠다고 생각
- 근본적인 원인은 범용의 의미와 재사용성을 잘못 이해하고 있기 때문
- 재사용성은 설계의 응집도를 높이면 저절로 높아짐
5.3.2. 객체 지향 설계의 기본으로 돌아가기
- 꼭 필요한 경우가 아니라면 범용 처리 클래스를 만들지 않는 것이 좋음
class AmountIncludingTax {
final BigDecimal value;
AmountIncludingTax(final AmountExcludingTax amountExcludingTax, final TaxRate taxRate) {
value = amountExcludingTax.value.mutiply(taxRate.value);
}
}5.3.3. 횡단 관심사
- 로그 출력과 오류 확인은 애플리케이션의 모든 동작에 필요한 기능
cross-cutting concern: 다양한 상황에서 넓게 활용되는 기능
try {
shoppingCart.add(product);
} catch (IllegalAmountException e) {
Logger.repot('');
}5.4. 결과를 리턴하는 데 매개변수 사용하지 않기
- 범용 처리 클래스 예에서 살펴보았던 것처럼 매개변수를 잘못 다루면, 응집도가 낮아지는 문제가 발생
- 출력 배개변수도 같음 문제를 일으킴
class ActorManager {
void shift(Location location, int shiftX, int shiftY) {
location.x += shiftX;
location.y += shiftY;
}
}- 이동 대상 인스턴스를 매개변수 location 으로 전달받고 이를 변경
- 이렇게 출력으로 사용되는 매개변수를
출력 매개변수라고 부름
- 데이터 조작 대상 = Location / 조작 로직 = ActorManager
- 데이터와 로직이 다른 클래스에 존재
class SpecialAttackManager {
void shift(Location location, int shiftX, int shiftY) {- 출력 매개변수는 응집도 문제 이외에도 여러 문제를 발생시킴
class DiscountManager {
void set(MoneyData money) {
money.amount -= 2000;
...
}
}- 전달한 매개변수 money 의 값을 변경
- 매개변수는 입력으로 전달하는 것이 일반적
- 이처럼 출력으로 사용해버리면, 매개변수가 입력인지 출력인지 메서드 내부의 로직을 확인해야함
- 출력 매개변수로 설계하지 말고
데이터,데이터를 조작하는 논리를 같은 클래스에 배치
class Location {
final int x;
final int y;
Location(final int x, final int y) {
this.x = x;
this.y = y;
}
Location shift(int shiftX, int shiftY) {
final int nextX = x + shiftX;
final int nextY = y + shiftY;
return new Location(nextX, nextY);
}5.5. 매개변수가 너무 많은 경우
- 매개변수가 너무 많은 메서드는 응집도가 낮아지기 쉬움
int recoverMagicPoint(int currentMagicPoint, it originalMaxMagicPoit, List<Integer> maxMagicPointIncrements, int recoveryAmount) {...}- 이 메서드는 정상적으로 기능하지만, 구조가 좋지 않음
- 너무 많은 매개변수를 받으면 실수로 잘못된 값을 대입할 가능성이 높음
- 매개변수가 많다는 것은 많은 기능을 처리하고 싶다는 의미
- 처리할 게 많아지면, 로직이 복잡해지거나, 중복 코드가 생길 가능성이 높아짐
5.5.1. 기본 자료형에 대한 집착
primitive type: 프로그래밍 언어가 표준적으로 제공하는 자료형- 메서드에 매개변수를 전달한다는 것은 해당 매개변수를 사용해서 어떤 기능을 수행하고 싶다는 의미
primitive obsession: 기본 자료형을 남용하는 현상- 줄곧 기본 자료형만을 써 온 개발자는 클래스 설계를 고려하지 않는 경우가 많음
class Util {
boolean isFairPrice(int regularPrice) {
if (regularPrice < 0) {
throw new IllegalArgumentException();
}
}
}- 이렇게 기본 자료형으로만 구현하면, 중복 코드가 많이 생김
- 계산 로직이 이곳 저곳 분산되기 쉬움
- 기본 자료형만으로 동작하는 코드를 구현하기는 쉬우나, 관련 있는 데이터와 로직을 집약하기는 힘듬
- 버그가 생기기 쉽고, 가독성이 떨어짐
- 데이터는 단순히 존재하기만 할 수는 없음
- 데이터를 사용해 계산하거나 데이터를 판단해서 제어 프름을 전환할 때 사용
- 기본 자료형으로만 구현하려고 하면 데이터를 사용한 계산과 제어 로직이 모두 분산됨
- 즉 응집도가 낮은 구조가 됨
class RegularPrice {
RegularPrice(final int amount) {
if (amount < 0) {
throw new IllegalArgumentException();
}
this.amount = amount;
}
}5.5.2. 의미 있는 단위는 모든 클래스로 만들기
- 매개변수가 너무 많아지는 문제를 피하려면, 개념적으로 의미 있는 클래스를 만들어야 함
- 매개변수가 많으면 데이터 하나하나를 매개변수로 다루지 말고, 그 데이터를 인스턴스 변수로 갖는 클래스를 만들면 됨
5.6. 메서드 체인
void equiparmor(int memberId, Armor newArmor) {
if(party.members[memberId].equipments.canChange) {
party.members[memberId].equipments.armor = newArmor;
}
}메서드 체인:.으로 여러 메서드를 연결해서 리턴 값으 요소에 차례차례 접근하는 방법- 이 방법은 응집도를 낮출 수 있는 좋지 않은 작성 방법
데메테르의 법칙: 사용하는 객체 내부를 알아서는 안된다- 메서드 체인으로 내부 구조를 돌아다닐 수 있는 설계는 데메테르의 법칙을 위반
5.6.1. Tell, Don't ask
- 다른 객체의 내부 상태를 기반으로 판단하거나 제어하려고 하지 말고
- 메서드로 명령해서 객체가 알아서 판단하고 제어하도록 설계하라는 의미
- 인스턴스 변수는 private 으로 변경해서 외부에서 접근할 수 없게 함
- 그리고 인스턴스 변수에 대한 제어는 외부에서 메서드로 명령하는 형태로 만듬
class Equipments {
private Equipment head;
void deactivateAll() {
this.head = Equipment.EMPTY;
}
}- 이렇게 하면 Equipment 에 방어구 탈착과 관련된 로직이 응집
6장. 조건 분기: 미궁처럼 복잡한 분기 처리를 무너뜨리는 방법
6.1. 조건 분기가 중첩되어 낮아지는 가독성
if (0 < member.hitPoint) {
if (member.canAct()) {
if (magic.costMagicPoint <= member.magicPoint) {
...
}
}
}- 위 조건을 모두 만족했을 때만 마법을 발동할 수 있음
6.1.1. 조기 리턴으로 중첩 제거하기
early return
if (0 > member.hitPoint) return;
if (!member.canAct()) return;
if (magic.costMagicPoint > member.magicPoint) return;
...- 중첩이 제거되어 가독성이 좋아짐
6.1.2. 가독성을 낮추는 else 구문도 조기 리턴으로 해결하기
- else 구문도 가독성을 나쁘게 만드는 원인 중 하나
6.2. switch 조건문 중복
- 값의 종류에 따라 다르게 처리하고 싶을 때는 switch 조건문을 사용
- switch 조건문은 악마의 저주에 걸릴 수 있음
6.2.1. switch 조건문을 사용해서 코드 작성하기
- 효과가 다른 마법을 여러개 구현해야 한다면
enum MagicType {
fire,
lighting
}switch (magicType) {
case fire:
pass
case ligtening:
pass
}6.2.2. 같은 형태의 switch 조건문이 여러 개 사용되기 시작
switch (magicType) {
case fire:
magicPoint = 10;
break;
case ligtening:
magicPoint = 20;
break;
}
switch (magicType) {
case fire:
attackPower = 10;
break;
case ligtening:
attackPower = 20;
break;
}- switch 조건문이 여러개 생성되어야 함
6.2.3. 요구 사항 변경 시 수정 누락 (case 구문 추가 누락)
6.2.4. 폭발적으로 늘어나는 switch 조건문 중복
- switch 조건문이 중복된 코드가 생김
- 주의 깊게 대응해도 실수가 발생할 수 밖에 없음
6.2.5. 조건 분기 모으기
- switch 조건문 중복을 해소하려면,
단일 책임 선택의 원칙을 생각해 봐야함
소프트웨어 시스템이 선택지를 제공해야 한다면, 그 시스템 내부의 어떠한 모듈만으로 모든 선택지를 파악할 수 있어야 함
switch (magicType) {
case fire:
magicPoint = 10;
attackPower = 10;
break;
case ligtening:
magicPoint = 20;
attackPower = 20;
break;
}- 이렇게 switch 문 한 곳에서 모든 것을 변경하도록 하면 실수를 줄일 수 있음
6.2.6. 인터페이스로 switch 조건문 중복 해소하기
- 단일 책임 원칙으로 switch 조건문을 하나만 사용
- 그런데 변경하고 싶은 부분이 많아지면, 로직이 점점 많아짐
- 이러한 문제를 해결할 때는 Interface 를 사용
interface Shape {
double area();
}class Retangular implements Shape {
private final double width;
private final double height;
public double area() {
return width * height;
}
}Shape shape = new Retangular(20, 25);- 각각의 코드를 간단하게 실행할 수 있게 하는 것 = 인터페이스의 큰 장점
6.2.7. 인터페이스를 switch 조건문 중복에 응용하기 (전략 패턴)
종류별로 다르게 처리해야 하는 기능을 인터페이스의 메서드로 정의하기
- 인터페이스의 가장 큰 장점 = 다른 로직을 같은 방식으로 처리할 수 있음
인터페이스의 이름을 결정하는 방법 : 어떤 부류에 속하는가?
- 가장 기본적인 방법은 인터페이스를 구현하는 클래스들이 어떤 부류인가를 생각해 보는 것
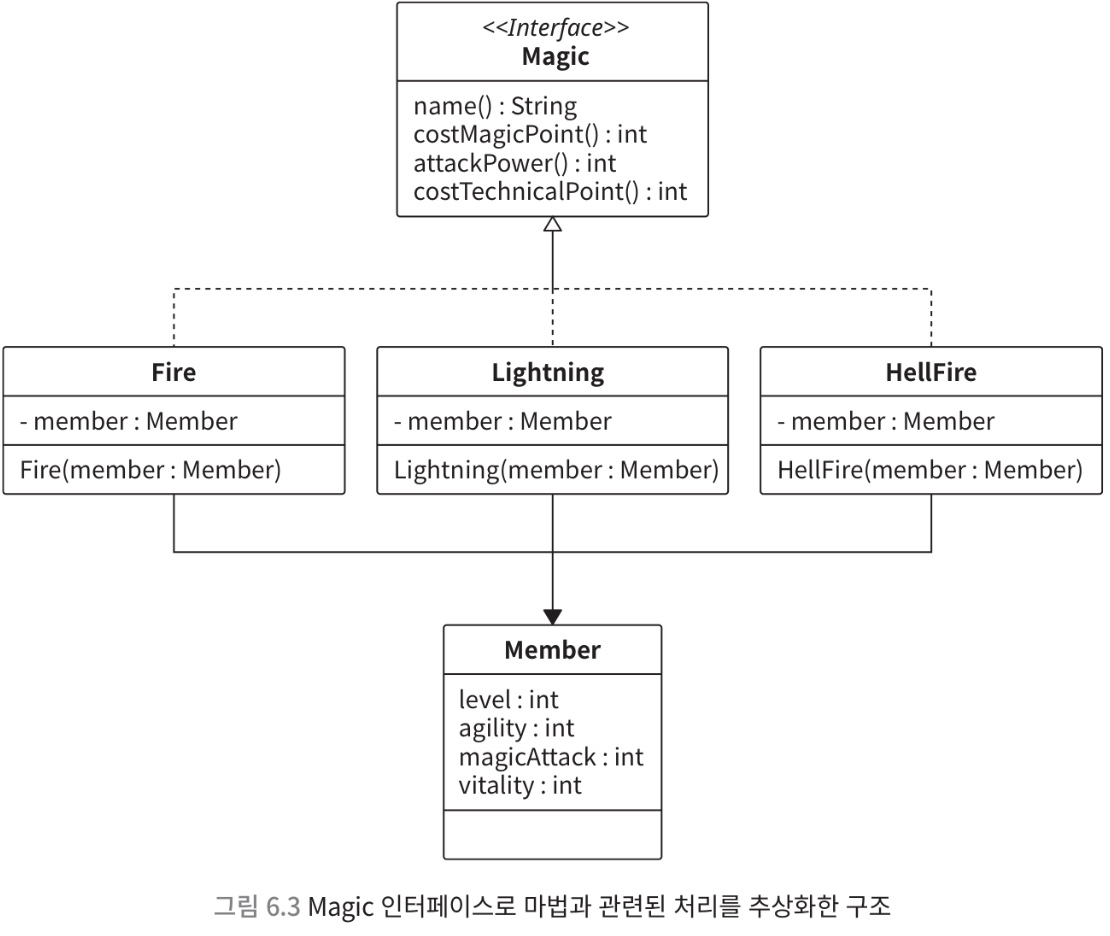
switch 조건문이 아니라, Map 으로 변경하기
- key 를 enum 으로 지정하고 값을 interface 구현 클래스의 인스턴스로 지정
final Map<MagicType, Magic> magics = new HashMap<>();
void magicAttack(final MagicType magicType) {
final Magic usingMagic = magics.get(magicType);
showMagicName(usingMagic);
}
void showMagicName(final Magic magic) {
final String name = magic.name();
}- switch 조건문을 전혀 사용하기 않고 HashMap 을 사용
메서드를 구현하지 않으면 오류로 인식하게 만들기
- 구현을 잊지 않도록 상위 클래스에 적용
값 객체화하기
class Magic {
String name();
}
class Fire implements Magic {
String name() {
return 'fire';
}
}6.3. 조건 분기 중복과 중첩
- 인터페이스는 switch 조건문의 중복을 제거할 수 있을 뿐만 아니라, 다중 중첩된 복잡한 분기를 제거하는 데 활용 가능
6.3.1. 정책 패턴으로 조건 집약하기
policy pattern: 조건을 부품처럼 만들고, 부품으로 만든 조건을 조합해서 사용하는 패턴
interface ExcellentCustomerRule {
boolean ok(finalPurchaseHistory history);
}class GoldCustomerPurchaseAmountRule implements ExcellentCustomerRule {
public boolean ok (final PurchaseHistory history) {
return 1000000 <= history.totalAmount;
}
}class ExcellentCustomerPolicy {
...
boolean complyWithAll(final PurchaseHistory history) {
for (ExcellentCustomerRule each : rules) {
...
}
}
}ExcellentCustomerPolicy goldCustomerPolicy = new ExcellentCustomerPolicy();
goldCustomerPolicy.add(new GoldCustomerPurchaseAmountRule());
goldCustomerPolicy.add(new PurchaseFrequencyRule());
goldCustomerPolicy.add(new ReturnRateRule());- 로직은 간단해졌으나, 이렇게 작성하면 골드 회원과 무관한 로직을 삽입할 수 있음
class GoldCustomerPolicy {
private final ExcellentCustomerPolicy policy;
GoldCustomerPolicy() {
policy = new ExcellentCustomerPolicy();
policy.add(new GoldCustomerPurchaseAmountRule());
policy.add(new PurchaseFrequencyRule());
policy.add(new ReturnRateRule());
}
boolean complyWithAll(final PurchaseHistory history) {
return policy.complyWithAll(history);
}
}6.4. 자료형 확인에 조건 분기 사용하지 않기
- interface 는 조건 분기를 제거할 때 활용할 수 있음
- interface 를 사용해도 조건 분기가 줄어들지 않는 경우가 있음
interface HotelRates {
Money fee();
}
class RegularRates implements HotelRates {
public Money fee() {...}
}- 이렇게 하면 전략 패턴으로 요금 확인 가능
if (hotelRates instanceof RegularRates) {
busySeasonFee = hotelRates.fee().add(new Money(5000))l
}
else if (hotelRates instanceof PremiumRates) {...}- 조건 분기 코드가 계속 중복됨
- 이와 같은 로직은
리스코프 치환 원칙 - 클래스의 기반 자료형과 하위 자료형 사이에 성립하는 규칙
- 기반 자료형을 하위 자료형으로 변경해도 코드는 문제없이 동작해야 함
- 인터페이스의 의미를 충분히 이해하지 못하고 사용하면 이와 같은 로직이 자주 만들어짐
interface HotelRates {
Money fee();
Money busySeasonFee();
}
class RegularRates implements HotelRates {
public Money fee() {
return new Money(3000);
}
public Money busySeasonFee() {
return fee().add(new Money(5000));
}
}Money busySeasonFee = hotelRates.busySeasonFee();6.5. 인터페이스 사용 능력이 중급으로 올라가는 첫걸음
- 인터페이스를 잘 사용하는 지가 곧 설계 능력의 전환점
- 조건 분기를 써야하는 상황에서는 일단 인터페이스 설계를 떠올리자!
6.6. flag 매개변수
damage(true, damageAmount);flag 매개변수: method 의 기능을 전환하는 boolean 자료형의 매개변수- flag 매개변수를 받는 메서드는 어떤 일을 하는 지 예측이 굉장히 힘듬
- 예측을 하기 위해서는 반드시 메서드 내부 로직을 확인해야 하므로 가독성이 낮아짐
6.6.1. method 분리하기
- flag 매개변수를 받는 method는 내부적으로 여러 기능을 수행하고 있으며, flag 를 사용해서 이를 전환하는 구조
- method 는 하나의 기능만 하도록 설계하는 것이 좋음
- 따라서 flag 매개변수를 받는 method 는 기능별로 분리하는 것이 좋음
6.6.2. 전환은 전략 패턴으로 구현하기
- flag 매개변수가 아니라 전략 패턴으로 구현해야 함
interface Damage {
void execute(final int damageAmount);
}class HitPointDamage implements Damage {
...
}
class MagicPointDamage implements Damage {
...
}- Map 과 enum 을 사용
enum DamageType {
hitPoint,
magicPoint,
}void applyDamage(final DamageType damageType, final int damageAmount) {
final Damage damage = damages.get(damageType);
damage.execute(damageAmount);
}- 조건을 분기하지 않고 가독성이 높아짐
7장. 컬렉션: 중첩을 제거하는 구조화 테크닉
7.1. 이미 존재하는 기능을 다시 구현하지 말기
boolean hasPrisonKey = false;
for (item each : items) {
if (each.name.equals('감옥 열쇠')) {
hasPrisonKey = true;
break;
}
}- if 조건문이 중첩되어 있어서 가독성이 좋지 않음
boolean hasPrisonKey = items.stream().anyMatch(
item -> item.name.equals('감옥 열쇠')
);anyMatchmethod 를 알고 있으면, 복잡한 로직을 직접 구현하지 않아도 됨- for 반복문을 사용해 collection 을 직접 조작하고 있다면, 잠시 멈추고 라이브러리에 같은 기능을 하는 method 가 있는지 확인
바퀴의 재발명 : 이미 널리 사용되고 있는 기술과 해결법이 존재하는데도, 이를 전혀 모르거나 의도적으로 무시하고 비슷한 것을 새로 만들어 내는 것
7.2. 반복 처리 내부의 조건 분기 중첩
for (Member member : members) {
if (0 < member.hitPoint) {
if (member.containsState(stateType.poison)) {
member.hitPoint -= 10;
if (member.hitPoint <= 0) {
member.hitPoint = 0;
}
}
}
}7.2.1. 조기 Continue 로 조건 분기 중첩 제거하기
- continue 로 실행하고 있는 처리를 건너 뛰고, 다음 반복으로 넘어가는 제어 구조
for (Member member : members) {
if (member.hitPoint == 0) continue;
if (!member.containsState(StateType.poison)) continue;
member.hitPoint -= 10;
if (0 < member.hitPoint) continue;
member.hitPoint = 0;
}7.2.2. 조기 break 로 중첩 제거하기
- 로직을 중단하고 반복문 전체를 벗어나는 제어 구문
int totalDamage = 0;
for (Member member : members) {
if (!member.hasTeamAttackSucceeded()) break;
...
}7.3. 응집도가 낮은 collection 처리
- collection 처리도 응집도가 낮아지기 쉬움
class FieldManager {
void addMember(List<Member> members, Member newMember) {
if (members.size() == MAX_MEMBER_COUNT) {...}
members.add(newMember); // 중복
}
}class SpecialEventManager {
void addMember(List<Member> members, Member newMember) {
members.add(newMember); // 중복
}
}- collection 과 관련된 작업을 처리하는 코드가 여기 저기 구현될 가능성이 높음
- 응집도가 낮아짐
7.3.1. collection 처리를 캡슐화하기
- collection 과 관련된 응집도가 낮아지는 문제는
First Class Collectionpattern 을 사용해 해결할 수 있음
[First Class Collection]
- collection 과 관련된 로직을 캡슐화하는 디자인 패턴
- collection 자료형의 인스턴스 변수
- collection 자료형의 인스턴스 변수에 잘못된 값이 할당되지 않게 막고, 정상적으로 조작하는 메서드
class Party {
// collection 자료형의 인스턴스 변수
private final List<Member> members;
Party() {
members = new ArrayList<Member>();
}
// collection 자료형의 인스턴스 변수에 잘못된 값이 할당되지 않게 막고
// 정상적으로 조작하는 메서드
Party add(final Member newMember) {
List<Member> adding = new ArrayList<>(members);
adding.add(newMember);
return new Party(adding);
}
}- 원래의 members 를 변화시키지 않아 부수 효과를 막을 수 있음
7.3.2. 외부로 전달할 때 컬렉션의 변경 막기
- First class collection 으로 설계한 Party class 에서 멤버 전원을 참조하려 할 때
class Party {
List<Mbmer> members() {
return members;
}
}- 인스턴스 변수를 그대로 외부에 전달하면 Party class 외부에서 마음대로 member 를 추가하고 제거할 수 있음
members = party.members();
members.add(newMember);- 외부로 전달할 때는 collection 의 요소를 변경하지 못하게 막아두는 것이 좋음
class Party {
List<Member> members() {
return members.unmodifiableList();
}
}- 따라서 Party class 외부에서 마음대로 collection 을 조작하는 상황 자체를 방지할 수 있음
8장. 강한 결합: 복잡하게 얽혀서 풀 수 없는 구조
coupling: 모듈 사이의 의존도를 나타내는 지표tightly coupling: 이해하고 변경하기 힘든 코드loose coupling: 코드 변경이 쉬워짐
8.1. 결합도와 책무
class DiscountManager {
boolean add(Product product, ProductDiscount productDiscount) {
int discountPrice = getDiscountPrice(product.price);
...
}
static int getDiscountPrice(int price) {
int discountPrice = price - 3000;
...
}
}class SummerDiscountManager {
...
boolean add(Product product) {
if (product.canDiscount) {
tmp = discountManager.totalPrice + discountManager.getDiscountPrice(product.price);
...
}
}
...
}8.1.1. 다양한 버그
- 일반 할인 가격을 3000원에서 4000원으로
class DiscountManager {
...
static int getDiscountPrice(int price) {
int discountPrice = price - 4000;
...
}
}- 그럼 해당 함수를 사용하는
SummerDiscountManager에서도 로직이 변경됨
8.1.2. 로직의 위치에 일관성이 없음
- DiscountManager 가 상품 정보 말고도 너무 많은 일을 함
- Product 가 직접 해야 하는 유효성 검사 로직이 DiscountManager, SummerDiscountManager 에 구현되어 있음
- ProductDiscount.canDiscount, Product.canDiscount 의 이름이 유사해서 어떤 것이 어떤 상품인지 구분이 어려움
- SummerDicsountManager 에서 DiscountManager 의 로직을 활용함
8.1.3. Single Responsibility Principle
- 책임 : 자신이 해야 하는 일로서, 하지 않으면 안되는 임무
- 소프트웨어에서의 책임 : 자신의 관심사와 관련해서, 정상적으로 동작하도록 제어하는 것
8.1.4. SRP 로 발생하는 악마
- 할인되는 가격이 같다는 이유만으로 메서드를 하나만 만들어서 사용하면
- 한쪽 사양이 변경될 대 다른쪽 사양도 함께 변경되어 버그가 발생
- 상품명과 가격이 타당한지 판단하는 책임은 이 데이터를 갖고 있는 Product Class 가 원래 가지고 있어야 함
- 그런데 아무 일도 하지 않음 =
미성숙한 클래스
8.1.5. 책임이 하나가 되게 클래스 설계하기
- 상품의 가격을 나타내는 RegularPrice class 를 생성
- Money class 와 같은
Value Object
class RegularPrice {
final int amount;
...
}class RegularDiscountPrice {
final int amount;
...
}class SummerDiscountPrice {
final int amount;
...
}- 가격이 분리되어 있어 서로 영향을 주지 않음
느슨한 결합: 관심사에 따라 분리해서 독립되어 있는 구조
8.1.6. DRY 원칙의 잘못된 적용
RegularPrice,RegularDiscountPrice,SummerDiscountPrice의 로직은 대부분 같음중복 코드가 작성된 것은 아닐까?라는 생각이 들지만- 책무를 생각하지 않고 로직의 중복을 제거하면 안됨
- 그렇게 되면 하나로 모인 로직이 여러 책무를 담당해야 함
모든 지식은 시스템 내에서 단 한 번만, 애매하지 않고, 권위 있게 표현되어야 한다 - <<실용주의 프로그래머 20주년 기념판>>
지식: 세분화된 정도, 기술 레이어 등 다양한 관점으로 생각 가능, 소프트웨어가 대상으로 하는 비즈니스 지식비즈니스 지식: 소프트웨어에서 다루는 비즈니스 개념
- 같은 로직 비슷한 로직이라도 개념이 다르면 중복을 허용해야 함
- 개념적으로 다른 것까지도 무리하게 중복을 제거하려면 강한 결합 상태가 됨
8.2. 다양한 강한 결합 사례와 대처 방법
8.2.1. 상속과 관련된 강한 결합
- 상속은 주의해서 다루지 않으면 곧바로 강한 결합 구조를 유발
- 이 책에서는 상속 자체를 권장하지 않음
Super class 의존
class PhysicalAttack {...}
class FighterPhysicalAttack extends PhysicalAttack {...}- 처음에는 이 로직이 문제 없이 동작
- 하지만 super class 에 변화가 있을 때, override 한 class 에도 변화가 생기면서 예측하지 못하는 버그가 발생
- Sub class 는 Super class 에 굉장히 크게 의존
- 따라서 sub class 는 super class의 구조를 하나하나 신경써야함
- 일반적으로는 super class 는 sub class 를 생각하지 않고 개발
상속보다 composition
- Super class 의존으로 인한 강한 결합을 피하려면 상속보다 composition 을 사용
class FighterPhysicalAttack {
private final PhysicalAttachk physicalAttack;
...
int singleAttackDamage() {
return physicalAttack.singleAttackDamage() + 20;
}
}상속을 사용하는 나쁜 일반화
- Sub class 가 Super class 의 로직을 그대로 사용
- Super class 가 공통 로직을 두는 장소로 사용
abstract class DiscountBase {
int getDiscountPrice() {
...
}
}class RegularDiscount extends DiscountBase {...}
class SummerDiscount extends DiscountBase {...}getDiscountPrice는 두 가지 책임을 지게 됨- SRP 를 구현하는 좋은 구현이라고 말할 수 업음
- 더 좋지 않은 코드는 Super class 에서 Sub class 를 아는 것
abstract class DiscountBase {
int getDiscountPrice() {
if (this instanceof RegularDiscount) {...}
else if (this instanceof SummerDiscount) {...}
}
}- 상속 받는 쪽에서 차이가 있는 로직만 구현하는 Template method 라는 디자인 패턴이 존재
- 하지만 상속은 강한 결합과 로직 분산 등 여러 악마들을 불러들임
- 신중하게 사용해야 함
8.2.2. 인스턴스 변수별로 클래스 분할이 가능한 로직
class Util {
void cancelReservation() {...}
void darkMode() {...}
void beginSendMail() {...}
}- method 모두 책임이 완전히 다름 하지만 모두 Util 이라는 클래스 안에 존재
- 따라서 Util class 를 각 3개의 class 로 분리해야함
class Reservation {...}
class ViewCustomizing {...}
class MailMagazineService {...}8.2.3. 특별한 이유 없이 public 사용하지 않기
- public 을 사용하면 강한 결합 구조가 됨
- 관곌ㄹ 맺지 않았으면 하는 클래스끼리도 결합되어, 영향 범위가 확대
- 결과적으로 유지 보수가 어려운 강한 결합 구조가 되고 맘
8.2.4. private 메서드가 너무 많다는 것은 책임이 너무 많다는 것
class OrderService {
private int calcDiscountPrice(int price) {...}
private List<Product> getProductBrowsingHistory(int userId) {...}
}- 최근 본 상품 리스트 확인은 주문과는 다름
- 따라서 책임이 다른 메서드는 다른 클래스로 분리하는 것이 좋음
8.2.5. 높은 응집도를 오해해서 생기는 강한 결합
- 기능이 늘면서 클래스의 규모가 커짐에 따라 발생하는 강한 결합
class SellingPrice {
int calcSellingCommission() {...}
int calcDeliveryCharge() {...}
int calcShoppingPoint() {...}
}- SellingPrice 에 모아서 놓음 > 응집도는 높으나, 필요 없는 method 가 포함 > 강한 결합
- 응집도가 높다는 개념을 염두해 두고, 관련이 깊다고 생각되는 로직을 한 곳에 모으려고 했지만,
- 결과적으로 강한 결합 구조를 만드는 상황은 매우 자주 일어남
결합이 느슨하고 응집도가 높은 설계
class SellingCommission {...}
class DeliveryCharge {...}
class ShoppingPoint {...}8.2.6. Smart UI
- 화면 표시와 직접적인 관련이 없는 책무가 구현되어 있는 클래스
- Smart UI 는 화면 표시에 관한 책무와 그렇지 않은 책무가 강하게 결합되어 있기 때문에, 변경하기가 아주 힘듬
8.2.7. 거대 데이터 클래스
- 수많은 인스턴스 변수가 존재
- 작은 데이터 클래스보다 훨씬 더 많은 악마를 불러들이므로 주의
- 다양한 데이터를 가지므로, 수많은 UseCase 에서 사용
- 결국 전역 변수와 같은 성질을 띄게 됨 (ex) 동기화하느라 성능이 저하되는 등)
8.2.8. Transaction Script Pattern
- 메서드 내부에 일련의 처리가 하나하나 길게 작성되어 있는 구조
데이터를 보유하고 있는 class와데이터를 처리하는 class를 나누어 구현할 때 자주 보임- 이를 남용하면 메서드 하나가 길게는 수백 줄의 거대한 로직을 갖게 됨
- 응집도는 낮아지고 결합은 강해짐
8.2.9. God Class
- 하나의 클래스 내부에 수천에서 수만 줄의 로직을 담고 잇음
- 수많은 책임을 담당하는 로직이 난잡하게 섞여 있는 클래스
- 어떤 로직과 관련 있는지, 책무를 파악하기가 굉장히 힘듬
- 기능을 수정하려면, 영향 범위를 파악하기 위해 수천 수만 줄의 로직을 읽어야 함
- 영향 범위 확인 시 놓치는 부분이 생기기 쉽고, 버그 발생이 쉬움
- 최악의 상황에는 아예 작성되어 있지 않은 경우도 있음
8.2.10. 강한 결합 클래스 대처 방법
- 객체 지향 설계와 단일 책임 원칙에 따라 제대로 설계하는 것
- 거대한 강한 결합 클래스는 책임별로 클래스를 분할해야 함
9장. 설계의 건전성을 해치는 여러 악마
9.1. Dead Code
Dead Code,Unreachable code: 절대로 실행되지 않는 조건 내부에 있는 코드
- 코드의 가독성을 떨어뜨림
- 언젠가 버그가 될 가능성이 높음
- 발견하는 즉시 제거하는 것이 좋음
9.2. YAGNI 원칙
You Aren't Gonna Need It
- 미래를 예측하고 미리 만들어두면 안됨
- 지금 필요 없는 기능은 만들지 말자
- 소프트웨어 대한 요구는 매일 매일 변함
- 사양으로 확정되지 않고 명확하게 언어화되지 않은 요구를 미리 에측하고 구현해도, 이러한 예측은 대부분 맞지 않음
- 예측에 들어맞지 않는 로직은 Dead Code 가 됨
9.3. Magic Number
Magic Number: 로직 내부에 직접 작성되어 있어서, 의미를 알기 힘든 숫자- 설명이 없는 숫자는 개발자를 혼란스럽게 만듬
- 따라서 상수로 변경하고 커밋
9.4. 문자열 자료형에 대한 집착
- 하나의 String 변수에 여러 값을 쉼표로 구분해서 저장
- 기본 자료형에 대한 집착처럼 클래스 뿐만 아니라 변수마저 추가하지 않으려는 경향
- 의미가 다른 값은 각각 다른 변수에 저장하는 것이 좋음
9.5. 전역 변수
- 모든 곳에서 접근할 수 있는 변수
- java 언어 사양에는 전역 변수가 없음
public static으로 선언하면 모든 곳에서 접근 가능
- 여러 로직에서 전역 변수를 참조하고 값을 변경하면, 어디에서 어떤 시점에서 값을 변경했는지 파악하기 힘듬
- 전역 변수를 참조하고 있는 로직을 변경해야 할 때, 해당 변수를 참조하는 다른 로직에서 버그가 발생하는지 검토 필요
- 동기화가 필요한 경우 DeadLock 에 빠질 수 있음
- 동기화를 하고 싶은 인스턴스 변수가 하나뿐이라고 해도, 해당 인스턴스의 다른 인스턴스 변수까지 모두 잠그므로, 성능상 문제가 큼
전역 변수를 직접적으로 사용하지 않더라도, 전역 변수와 같은 개념을 알게 모르게 사용
9.5.1. 영향 범위가 최소화되도록 설계하기
- 전역 변수는 영향 범위가 너무 넓음
- 영향 범위가 가능한 한 되도록 좁게 설계 하는 것이 필요
- 관계없는 로직에서는 접근할 수 없게 설계
- 그래도 전역변수를 사용하고 싶다면, 정말로 필요한지 검토 필요
9.6. null 문제
- null 이 들어갈 수 있다고 전제하고 로직을 만들면, 모든 곳에서 null 체크 필요
- 결국 null 체크 코드가 너무 많아져서, 가독성이 떨어짐
- 실수로 null 체크를 안하면 곧바로 버그가 됨
null 이 뭘까?
- 초기화하지 않은 메모리 영역에서 값을 읽으면 문제가 생김
- 이를 피하기 위해 null이 발명
- 메모리 접근과 관련된 문제를 방지하기 위한 최소한의 구조
- 즉 잘못된 처리 를 의미
9.6.1. null을 리턴/전달하지 말기
- 애초에 null 을 다루지 않게 만들어야 함
- null 을 리턴하지 않는 설계
- null 을 전달하지 않는 설계
9.6.2. null 안전
- null 에 의한 오류가 아예 발생하지 않게 만드는 구조
null 안전 자료형: null 을 아예 저장할 수 없게 만드는 자료형
val name: String = null // compile error9.7. 예외를 catch 하고서 무시하는 코드
try {
reservations.add(product);
} catch (Exception e) {
}- catch 해놓고 별다른 처리를 하고 있지 않음
9.7.1. 원인 분석을 어렵게 만듦
- 이러한 코드의 문제는 오류가 나도, 오류를 탐지할 방법이 없어진다는 것
- 예외를 catch 하고서도 무시하고 있으므로, 어느 시점에 어떤 코드에서 문제가 발생했는지 찾기 힘듬
9.7.2. 문제가 발생했다면 소리치기
- 잘못된 상태에서 어떠한 관용도 베풀어서는 안됨
- 잘못된 상태에서 계속해서 처리를 진행하는 것은 도화선에 불이 붙는 폭탄을 들고 돌아다니는 것과 같음
- 예외를 확인했다면 곧바로 통지, 기록하는 것이 좋음
9.8. 설계 질서를 파괴하는 Meta programming
Meta Programming: 프로그램 실행 중에 해당 프로그램 구조 자체를 제어하는 프로그래밍Reflaction Programming: 프로그램에서 임의의 클래스에 접근할 수 있는 기능
9.8.1. Reflaction 으로 인한 Class 구조와 값 변경 문제
class Level {
private static final int MIN = 1;
private static final int MAX = 99;
final int value;
private Level(final int value) {...}
static level initialize() {...}
Level increase() {...}
...
}Level level = Level.initialize();
Field field = Level.class.getDeclaredField('value');
field.setInt(999);- 잘못된 값이 들어갈 수 있음
- Reflaction 을 남용하면, 뒷문을 열어 놓은 것과 같음
9.8.2. 자료형의 장점을 살리지 못하는 Hard Coding
- statis type 언어는 정적 분석으로 정확한 코드 분석이 가능하다는 장점이 있음
- meta programming 은 이러한 장점 조차 무너뜨림
- class instance 를 만들 때 일반적으로 new keyword 를 사용
- reflaction 을 사용하면, Meta 정보를 기반으로 instance 생성 가능
static Object generateInstance(String packageName, String className) throw Exception {
Class klass = Class.forName(packageName + '.' + className);
Constructor constructor = klass.getDeclaredConstructor();
}- IDE 의 정적 분석을 사용하면, 어떤 클래스가 어디에서 참조되고 있는지 정확하게 분석할 수 있음
- 그런데 단순히 하드코딩 되어 있다면 알 수 없음
Employee user = (Employee)generateInstance("customer", "User");- IDE 정적 분석 기능은 이름 변경 이외에도 정의한 위치로 점프, 참조하고 있는 위치 전체 검색 등 개발의 효율성과 정확성 향상에 도움을 줌
9.8.3. 단점을 이해하고 용도를 한정해서 사용하기
- Meta Programming 을 사용하면, 뭔가 특별한 능력을 배운 것만 같지만, 단점을 무조건 잘 이해해야 함
9.9 기술 중심 Packaging
- Package 를 구분할 때도 폴더를 적절하게 나누지 않으면 악마를 부를 수 있음
기술 중심 패키징
- 구조에 따라 폴더와 패키지를 나누는 것
- 비즈니스 클래스를 기술 중심 패키징에 따라 폴더를 구분하면 관련성을 알기 매우 힘듬
ex) MVC 에 따라서 폴더 구조를 변경
- 비즈니스 개념을 중심으로 폴더를 구분하는 것이 좋음
- 관련된 개념끼리 모여 있음
9.10. Sample Code 복사해서 붙여넣기
- framework 마다 공식 사이트가 있음
- 각 사이트의 샘플 코드를 그대로 복사하고 붙여 넣으면, 좋지 않은 구조가 되기 쉬움
- 따라서 샘플 코드는 참고만!
9.11. Silver Bullet
- 새로운 기술과 방법을 익히면, 곧바로 써보고 싶어짐
- 새로운 기술은 개발 현장의 모든 문제를 해결해 줄 것처럼 보임
- 하지만 현실에서 발생하는 문제는 특정 기술 하나로 해결할 수 있을 정도로 단순하지 않음
- 어떤 문제가 있을 때, 어떤 방법이 해당 문제에 효과적인지, 비용이 더 들지는 않는지 평가하고 판단하는 자세
- 문제와 목적을 머릿속에 새겨두고 적절한 기술을 선택할 수 있도록 노력해야 함
Best 가 아니라 Better 를 목표로 해야함
10장. 이름 설계: 구조를 파악할 수 있는 이름
10.1. 악마를 불러들이는 이름
- 쇼핑몰에서 상품이라는 클래스를 만들면, 영향 범위가 너무 넓어 생산성이 저하될 수 있음
10.1.1. Seperation of concerns
- 강한 결합을 해소하고, 결합이 느슨하고, 응집도가 높은 구조
- 관심사에 따라서 각각 클래스로 분할해야 함
10.1.2. 관심사에 맞는 이름 붙이기
- 모든 상품을 그냥 상품이라고 하지 않고, 각각 종류에 따라 따로 클래스를 만듬
ex) 예약 상품, 주문 상품, 재고 상품, 발송 상품
10.1.3. 포괄적이고 의미가 불분명한 이름
목적 불명 객체: 이름이 너무 포괄적이라서 목적이 불분명한 클래스
10.2. 이름 설계하기 - 목적 중심 이름 설계
이름 설계: 클래스와 메서드에 이름을 붙이는 것설계: 어떤 문제를 해결하기 위한 구조를 생각하거나 만들어 내는 것
- 이름이란? 관심사 분리를 생각하고, 비즈니스 목적에 맞게 이름을 붙이는 것
- 결합이 느슨하고 응집도가 높은 구조를 만드는 데 굉장히 중요
[목적 중심 이름 설계 방법]
- 최대한 구체적이고, 의미 범위가 좁고, 특화된 이름 선택하기
- 존재가 아니라 목적을 기반으로 하는 이름 생각하기
- 어떤 관심사가 있는지 분석하기
- 소리 내어 이야기해보기
- 이용 약관 읽어 보기
- 다른 이름으로 대체할 수 없는지 검토하기
- 결합이 느슨하고 응집도가 높은 구조인지 검토하기
10.2.1. 최대한 구체적이고, 의미 범위가 좁고, 특화된 이름 선택하기
- 이름과 관계 없는 로직을 배제하기 쉬움
- 클래스가 작아짐
- 관계된 클래스 개수가 적으므로, 결합도가 낮아짐
- 관계된 클래스 개수가 적으므로, 사양 변경 시 생각해야 하는 영향 범위가 좁음
- 목적에 특화된 이름을 갖고 있으므로, 어떤 부분을 변경해야 할 때 쉽게 찾을 수 있음
- 개발 생산성이 향상됨
10.2.2. 존재가 아니라 목적을 기반으로 하는 이름 생각하기
- 주소이라고 클래스를 지으면 존재 기반 이름이 됨
- 그런데 발송지 인지 배송지 인지 법인 주소 인지 등을 구분하면 목적 기반 이름이 됨
10.2.3. 어떤 비즈니스 목적이 있는지 분석하기
- 비즈니스 목적에 특화된 이름을 만들려면, 어떤 비즈니스를 하는지 모두 파악해야 함
- 소프트웨어가 추구하는 목적과 내용을 분석해야 함
10.2.4. 소리 내어 이야기해 보기
- 어떤 목적을 달성하고 싶은지, 어떤 형태로 사용하고 싶은지, 서로 어떤 관련이 있는지 등
- 배경과 의도를 함께 정리하고 이를 팀과 소통해서 일치시키는 것이 중요
- 비즈니스 측면을 잘 이해하고 있는 사람과 이야기를 하면 바로 피드백을 받을 수 있음
고무 오리 디버깅: 프로그래밍에서 어떤 문제를 발견햇을 때, 문제를 누군가에게 설명하다보면 스스로 원인을 깨닫고 해결할 수 있음- 적극적으로 이야기하면서, 대화 속에서 사용되는 이름에 주의를 기울임
ubiquitous language: 팀 전체에서 의도를 공유하기 위한 언어- 같은 의도를 갖고 이름을 대화, 문서, 클래스 이름, 메서드 이름 등에 활용하면, 설계에서 발생하는 여러 문제들을 해결할 수 있음
10.2.5. 이용 약관 읽어보기
- 명확하고 구체적인 단어들이 나열되어 있어 판단하는 데 도움이 됨
10.2.6. 다른 이름으로 대체할 수 없는지 검토하기
- 사용자 > 관리인, 고객 > 투숙객, 결제자
- 사전에 유의어를 확인해 보는 것도 좋음
10.2.7. 결합이 느슨하고 응집도가 높은 구조인지 검토하기
- 목적에 특화된 이름을 선택하면, 목적 이외의 로직을 배제하기 쉬워짐
- 목적과 관련된 로직이 모여 있으므로, 응집도가 높아짐
- 다른 클래스 몇 개와 관련이 있는지 개수를 확인
- 너무 많은 클래스에 관련되어 있다면 좋지 않은 징조
강한 결합 상태일 수 있음
10.3. 이름 설계 시 주의사항
10.3.1. 이름에 관심 갖기
- 팀 개발에서는 이름이 중요
- 이름과 로직이 대응된다는 전제, 이름이 프로그램 구조를 크게 좌우 한다는 중요성을 공유해야 함
10.3.2. 사양 변경 시 '의미 범위 변경' 경계하기
- 여러 의미가 섞이면 이름이 의미하는 바를 다시 검토해야 함
- 이름을 변경하거나 클래스를 나누어야 함
10.3.3. 대화에는 등장하지만 코드에 등장하지 않는 이름 주의하기
- 대화에는 자주 등장하는 개념이 소스 코드에는 이름조차 붙어있지 않고, 잡다한 로직에 묻혀 있는 경우가 많음
- 만약 이를 코드에 반영하지 않는다면, 로직을 찾는 일이 굉장히 힘들어짐
- 대화에서 등장하는 이름을 신경써서 개발하는 것이 필요
10.3.4. 수식어를 붙여서 구별해야 하는 경우 클래스로 만들어보기
- 차이를 구분하기 어려운 코드를 단순하게 수식어를 붙여서 동료에게 설명하는 상황은 시스템 개발에서 매우 흔하게 볼 수 있음
int maxHitPoint = member.maxHitPoint + accessory;- 이 코드를 보면
maxHitPoint가 있다는 것은 알 수 있지만, 어떠한 최대 hit point 인지는 알 수 없음 - 따라서 장비를 착용했을 때의 최대 hit point 라는 것을 명확하게 명시해야 함
int corredtedMaxHitPoint = originalMaxHitPoint + accessory;- 하지만 int 로 계속 구현하면 의미 차이를 이름으로만 확인해야 함
- 또한 여러 관련 구현이 이곳 저곳에 퍼져 응집도가 낮은 구조가 됨
- 수식어를 붙이면서 차이를 나타내고 싶을 때 > 클래스로 설계 하는 것이 좋음
class OriginalMaxHitPoint {...}- 의미가 다른 개념들을 서로 다른 클래스로 설계해서 구조화하면, 개념 사이의 관계를 이해하기 쉬움
10.4. 의미를 알 수 없는 이름
int tmp3 = tmp1 - tmp2;
if (tmp3 < tmp4) {
tmp3 = tmp4;
}- 이 로직을 보고 목적인 무엇인지 파악하기 굉장히 어려움
- 목적 중심 이름 설계의 관점에서 보았을 때, 관심사 분리에 아무런 도움이 되지 않음
- 책무를 알 수 없으므로, 강한 결합 구조가 되기 쉬움
10.4.1. 기술 중심 명명
MemoryStateManager,changeIntValue01와 같은 이름을 사용하면, 이름의 의도를 알기 어려움- Embedded 처럼 HW 와 가까운 layer 의 middleware 에서는 memory 와 processor 에 직접 접근하는 로직이 많아, 어쩔 수 없이 기술 중심 명명을 해야 함
10.4.2. 로직 구조를 나타내는 이름
class Magic {
boolean isMemberHpMoreThanZeroAndIsMemberCanActAndIsMemberMpMoreThanMagicCostMp(Member member) {...}
}- method name 이 로직 구조를 그대로 드러내고 있음
- 무엇을 의도하는지 메서드 이름만 보고 알기 힘듬
- 의도와 목적을 이해하기 쉽게 이름을 붙이기
class Magic {
boolean canEnchant(final Member member) {...}
}10.4.3. Princople of least astonishment, Rule of least suprise
int count = order.itemCount();- 그냥 item count 만 조회한다고 생각했는데
class Order {
...
int itemCount() {
int count = items.count();
if (10 <= 10) {
giftpoint = giftPoint.add(new GiftPoint(100));
}
return count;
}
}- gift point 까지 추가하는 로직이 담겨 있었음
- 만약 실제로 이렇게 동작하고 있는 것을 알면 놀랄 수 있음
- 로직을 변경할 때는 항상 이 원칙을 신경써야 함
- 로직과 이름 사이에 괴리가 있다면 이름을 수정하거나, 메서드와 클래스를 의도에 맞게 따로 만들기
10.5. 구조에 악영향을 미치는 이름
10.5.1. 데이터 클래스처럼 보이는 이름
class ProductInfo {
...
}Info,Data같은 이름의 클래스는 읽는 사람에게 데이터만 갖는 클래스니까 로직을 구현하면 안되는 구나 라는 이미지를 심을 수 있음- 이렇게 되면 응집도가 낮은 구조가 되기 쉬움
ProductInfo>Product로 개선하는 것이 좋음
DTO (Data Transfer Object)
- 예외적으로 데이터 클래스를 사용하는 경우
- CQRS (Command and Query Repsonsibility Segregation) Architecture Pattern
- 참조 책무 : Database 에서 값을 추출하는 처리, 단순히 값을 추출
- 데이터 전송 용도로 사용되는 디자인 패턴
- 값을 변경하는 용도로 사용하면 안됨
- Data Class 를 절대 사용해서는 안된다는 것이 아니라, 의도를 이해하고 상황에 맞게 사용해야 한다는 것
10.5.2. 클래스를 거대하게 만드는 이름
- 대표적인 이름으로는
Manager(ex) MemberManager) - Manager 라는 이름이 붙은 클래스는 엄청나게 많은 책무를 가질 수 있음
- 즉 SRP (Single Reponsibility Principal) 을 위반
- 이러한 문제가 생겨난 원인은 Manager 라는 단어가 가진 의미가 너무 넓고 애매
- 따라서 좁은 개념을 찾는 것이 좋음
- 마찬가지로 Processor 와 Controller 같은 이름도 주의해야 함
- MVC 에서 Controller 는 전달 받는 요청 매개변수를 다른 클래스에 전달하는 책무만 가져야 함
- 금액을 계산하거나, 예약 여부를 판단하는 등의 분기 로직 구현 시 SRP 위반
- 책무가 다른 로직은 다른 클래스로 정의가 필요
10.5.3. 상황에 따라 의미가 달라질 수 있는 이름
ex)
- 배송 context : 자동차가 화물로 배송되는 context
- 판매 context : 딜러에 의해 고객에게 판매되는 context
- Context 의 차이를 생각하지 않고 Class 를 설계하면 두 개의 개념이 뒤섞임
- Context 가 다르다면 서로 다른 패키지로 선언
- 느슨하게 결합하면, 한 쪽을 변경해도 다른 쪽에는 영향을 주지 않음
10.5.4. 일련 번호 명명
- 클래스와 메서드의 이름에 번호를 붙여서 만드는 것
- 일련 번호라는 질서를 유지하기 위해 기능을 추가할 때 기존의 메서드에 로직을 추가하기 쉬움
10.6. 이름을 봤을 때, 위치가 부자연스러운 클래스
10.6.1. 동사 + 목적어 형태의 메서드 이름 주의하기
class Enemy {
...
void escape() {...}
// Magic Point 소비
void consmeMagicPoint(int costMagicPoint) {...}
// 주인공 파티에 아이템 추가
boolean addItemToParty(list<Item> items) {...}
}- Enemy class 의 관심사는 적인데,
addItemToParty은 주인공의 데이터를 다룸 - 관심사가 다른 메서드는
addItemParty처럼동사 + 목적어형태가 되는 경향이 있음 동사 + 목적어로 이루어진 이름은 관계없는 책무를 가진 메서드일 가능성이 있음
10.6.2. 가능하면 메서드의 이름은 동사 하나로 구성되게 하기
- 관심사가 다른 메서드가 섞이지 못하게 막으려면 되도록 메서드 이름이 동사 하나로 구성되도록 설계하는 것이 좋음
class PartyItems {
...
PartyItems add(final Item newItem) {...}
}10.6.3. 부적절한 위치에 있는 boolena method
- boolean 을 리턴하는 method 도 적절하지 않은 class 에 정의되어 있는 경우가 많음
class Common {
static boolean isMemberInConfusion(Member member) {...}
}- method 가 정의된 위치가 적절한지 관심사 단위로 생각해보면 좋음
isMemberInConfusionmethod 가 Common 에 있는 것이 아니라 Member class 에 정의되는 것이 자연스러움
- method 가 정의되어 있는 class 위치가 적절한지 쉽게 확인할 수 있는 방법
- boolean 자료형의 method 는
is,has,can형태의 이름이 붙는 경우가 ㅏㅁㄴㅎ음 - 다음 형태로 바꾸었을 때 위화감이 없으면 좋은 것
클래스 is 상태예를 들어
- Common is member in confusion
- Member is in confusion (자연스러움)class Member {
...
boolean isInConfusion() {...}
}10.7. name abbreviation
10.7.1. 의도를 알수 없는 축약
- 긴 이름이 싫어서 이름을 축약하는 경우가 있음
- 이름이 축약되면 의도를 이해하기 힘듬
int trFee = brFree + LRF * dod;- Rental Total Fee 를 계산하는 계산식
- 하지만 주석과 문서가 없다면 주변의 로직을 읽어서 무엇을 계산하는지 유추 해야 함
10.7.2. 기본적으로 이름은 축약하지 말기
- 조금 귀찮더라도 이름은 축약하지 말고 모두 쓰기를 바람
- 하지만 관습적으로 축약하는 경우에는 사용해도 괜찮음
10.7.3. 이름을 축약할 수 있는 경우
- 축약을 어느 정도 허용할 것인가 에 관해서는 굉장히 다양한 관점이 있음
- 최대한 축약하지 말고 의도를 명확하게 전달하는 것이 중요
11장. 주석: 유지 보수와 변경의 정확성을 높이는 주석 작성 방법
11.1. 내용이 낡은 주석
class Memter {
...
// 힘든 상태일 때 or 중독, 마비 상태 일때 : true
boolean isPainful() {
if (states.contains(StateType.poison) ||
states.contains(StateType.paralyzed) ||
states.contains(StateType.fear)) {
return true;
}
return false;
}
}- 주석과 로직이 다름
- 코드에 비해 주석을 유지 보수 하는 것이 어렵기 때문
- 주석이 낡아버리지 않게 구현을 변경할 때 주석도 함께 변경하는 것이 좋음
11.1.1. 주석은 실제 코드가 아님을 이해하기
- 주석의 설명도 실제 코드가 아니므로, 실제 내용을 100% 전달 할 수 없음
- 최대한 의도가 제대로 전달될 수 있게 class 와 method 의 이름을 짓고 주석을 달아야 함
11.1.2. 로직의 동작을 설명하는 주석은 낡기가 쉬움
- 코드의 동작을 그대로 설명하는 주석은 코드를 변경할 때마다 주석도 변경해야 함
- 로직을 그대로 설명하는 주석은 코드를 이해하는 데 별다른 도움이 되지 않음
11.2. 주석 때문에 이름을 대충 짓는 예
class Member {
...
boolean isNotSleepingAndIsNotParalyzedAndIsNotConfusedANdIsNotStoneAndIsNotDead() {...}
}- 메서드의 이름만으로는 이러한 의도를 전달하기 힘듬
- 의도를 전달하기 힘든 메서드에는 의미를 다시 설명하는 주석을 달기 쉬움
- 따라서 메서드 자체의 이름을 수정하면 좋음
class Member {
...
boolean canAct() {...}
}- method 의 가독성을 높이면 주석으로 설명을 추가하지 않아도 됨
11.3. 의도와 사양 변경 시 주의 사항을 읽는 이에게 전달하기
- 코드는 언제 읽힐까? 기본적으로 유지보수 할 때와 사양을 변겨알 때 읽힘
- 코드를 유지 보수 시 읽는 사람이 주의를 기울여야 하는 부분은
이 로직은 어떤 의도를 갖고 움직이는가 - 사양을 변경할 때 읽는 사람이 주의를 기울여야 하는 부분은
안전하게 변경하려면 무엇을 주의해야 하는가 - 따라서 주석이 이러한 내용이 담기면 좋음
11.4. 주석 규칙 정리
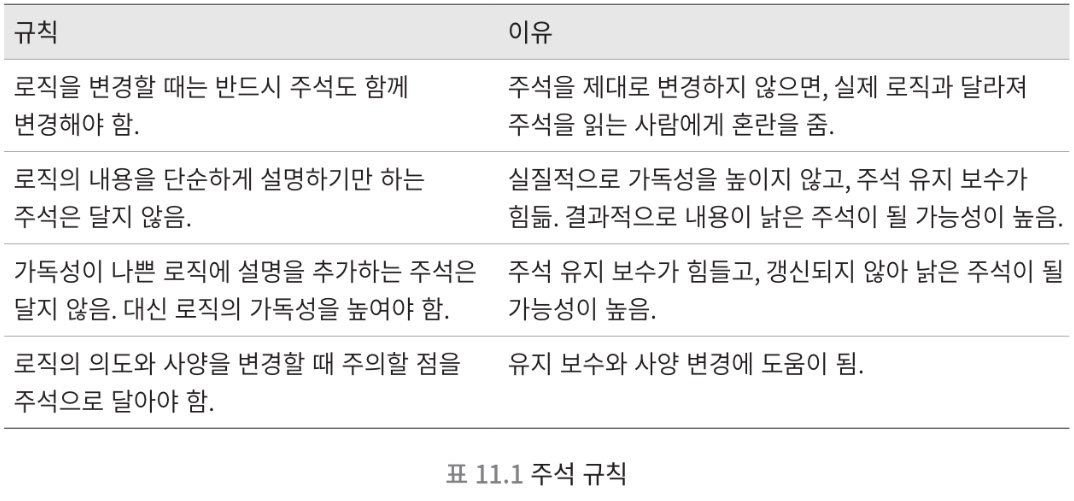
11.5. 문서 주석
문서 주석: 특정 형식에 맞춰 주석을 작성하면, API 문서를 생성해주거나 코드 에디터에서 주석의 내용을 팝업으로 표시해주는 기능
12장. method(함수): 좋은 class 에는 좋은 method 가 있다
12.1. 반드시 현재 class 의 instance 변수 사용하기
- 인스턴스 변수를 안전하게 조작하도록 메서드를 설계하면, 클래스 내부가 정상적인 상태인지 보장 가능
- 메서드는 반드시 현재 클래스의 인스턴스 변수를 사용하도록 설계
- 인스턴스는 생성해야지 변경하려고 하면 좋지 않음
12.2. 불변을 활용해서 예상할 수 있는 method 만들기
- 가변 인스턴스 변수 등을 변경하는 메서드는 의도하지 않게 다른 부분에 영향을 줄 수 있음
- 이렇게 되면 예상하지 못한 동작이 발생할 수 있으며, 유지보수가 어려워짐
- 불변을 활용해서 예상치 못한 동작 자체를 막을 수 있게 설계하면 좋음
12.3. 묻지 말고 명령하라
- 어떤 class 가 다른 class 의 상태를 판단하거나, 상태에 따라 값을 변경하는 등
- 다른 class 를 확인하고 조작하는 method 구조는 응집도가 낮은 구조
ex) instance 변수 값을 추출하는 메서드 getter, 값을 설정하는 메서드 setter
- getter, setter 는 다른 클래스를 확인하고 조작하는 메서드 구조가 되지 쉬움
- 개발 생산성이 좋지 않은 소프트웨어의 소스 코드에서 자주 볼 수 있음
12.4. CQS (Command/Query Seperation)
int gainAndGetPoint() {
point += 10;
return point;
}- 상태와 변경과 추출을 동시에 하는 method 는 여러 문제의 원인이 됨
- 사용자도 쓰기 힘든 method 가 됨

- modifier 는 최대한 피하는 거이 좋음
void gainPoint() {
point += 10;
}
int getPoint() {
return point;
}12.5. parameter
12.5.1. immutable parameter 로 만들기
- 매개 변수를 변경하면 값의 의미가 바뀌어서 어떤 의미를 나타내는지 유추하기 어려움
- 또한 어디서 변경되었는지 찾기도 힘듬
- 매개변수에
final수식자를 붙여서 불변으로 만드는 것이 좋음
12.5.2. Flag parameter 사용하지 않기
- 코드를 읽는 사람이 method가 무슨 일을 하는지 알기 어렵게 만듬
- 무슨 일을 하는지 이해하려면, method 의 내부 로직을 확인해야 하므로 가독성이 낮아짐
12.5.3. null 전달하지 않기
- null 을 활용하는 로직은 NullPointException 이 발생할 수 있으므로, 매개변수로 null 을 전달하지 않게 설계하는 것이 필요
- null 을 전달하지 않게 설계하려면, null 에 의미를 부여해서는 안됨
12.5.4. 출력 parameter 사용하지 않기
- 출력 매개변수를 사용하면 응집도가 낮은 구조가 만들어짐
- 매개변수는 입력 값으로 사용하는 것이 기분
- 매개변수를 출력값으로 사용하면, 코드를 읽는 사람에게 혼란을 줄 수 있음
12.5.5. Parameter 는 최대한 적게 사용하기
- method 에 parameter 가 많다는 것은 method 가 여러 가지 기능을 처리한다는 의미
- method 가 처리할 게 많아지면, 그만큼 로직이 복잡해져 이는 다양한 악마를 불러들임
12.6. Return Value
12.6.1. 자료형을 사용해서 Return value 의 의도 나타내기
class Price {
...
int add(final Price other) {
return amount + other.amount;
}
}- int 형 처럼 단순한 기본 자료형으로는 Return Value 의 의미를 호출하는 쪽에 전달할 수 없음
- 따라서 기본 자료형을 사용하지 말고, 독자적인 자료형을 사용해서 의도를 명확하게 나타내는 것이 좋음
class Price {
Price add(final Price other) {
final int added = amount + other.amount;
return new Price(added);
}
}12.6.2. null Return 하지 않기
12.6.3. 오류는 Return Value 로 Return 하지말고 Exception 을 일으키기
class Location {
...
Location shift(final int shiftX, final int shiftY) {
...
return new Location(-1, -1); // error case
}
}- 오류 값으로 Location(-1, -1) 을 리턴한다는 사실을 호출자가 알고 있어야 함
- 아니라면 후속 로직에서 정상 값처럼 사용되어 버그가 생길 수 있음
- double meaning : 어떤 값으로 여러 의미를 나타내는 것
- Location(-1, -1) 은 오류로 다루는 중의적인 의미
- Return Value 로 오류 값을 리턴하지 말고 곧바로 예외를 발생시켜야 함
class Location {
...
Locaion(final int x, final int y) {
if (!valid(x, y)) {
throw new IllegalArgumentException();
}
}
}13장. 모델링: 클래스 설계의 토대
13.1. 악마를 불러들이기 쉬운 User Class
- User Class 는 사양 변경이 굉장히 잦아서 여러 가지 문제를 일으키기 쉬움
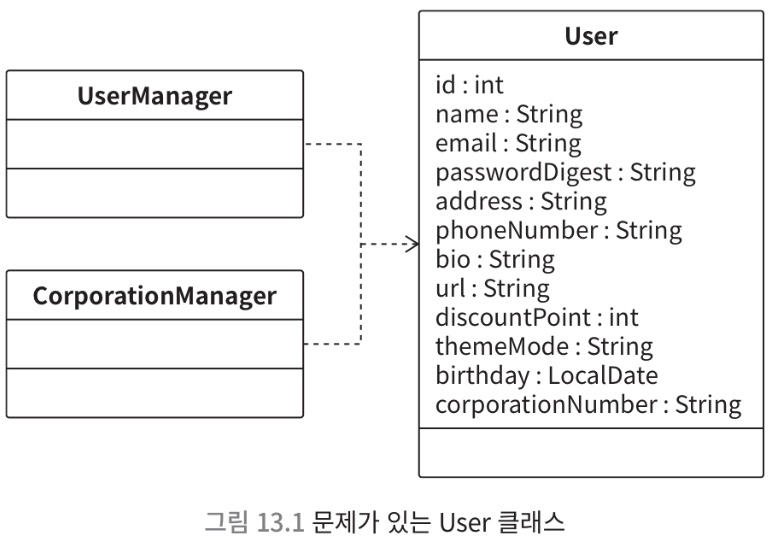
- User 는 하나인데 여러 목적을 가지기 때문에, 많은 오류가 날 수 잇음
13.2. Modeling 으로 접근해야 하는 구조
13.2.1. System 이란?
- 수많은 구성 요소로 이루어진 집합체로서 각가의 부분이 유기적으로 연결되어, 전체적으로 하나의 목적을 갖고 움직이는 것
ex) 사람은 이족 보행 시스템, 음파를 통한 회화 시스템을 따름
정보 시스템: 시스템 중에서 컴퓨터를 활용하는 시스템
13.2.2. System structure & Modeling
Model
- 이러한 시스템의 구조를 설명하기 위해 사용
- 시스템 구조를 설명하기 위해 단순한 상자로 도식화한 것
Modeling
- Model 의 의도를 정의하고 구조를 설계하는 것
- System 은 목적을 달성하기 위한 수단
- Model 은 System 의 구성요소 / 목적을 달성하기 위한 수단의 일부를 개념화 한 것
Model? 특정 목적을 달성하기 위해 최소한으로 필요한 요소를 갖춘 것
13.2.3. Software 설계와 Modeling
ex) Online Shopping mall : 상품 매매를 시스템화 한 것
- 온라인 쇼핑몰은 매매가 효율적으로 이루어지게 도와줌
- 온라인 쇼핑몰 덕분에 집에서도 상품을 구매할 수 있음
- 그럼 상품을 모델로 나타내면 어떻게 될까?
- 정보를 모두 포함하면, 모델의 목적을 알 수 없음
Model: 특정 목적 달성을 위해서 최소한으로 필요한 요소를 갖춘 것- 주문과 배송은 달성해야 하는 목적이 다름
- 즉 목적에 따라 상품의 모델이 달라짐
13.3. 안 좋은 모델의 문제점과 해결 방법
- User 의 목적은 무엇일까요? 개인 프로필과 관련된 요소
- 법인 등록 번호는 개인 프로필과 관련되지 않음
일관성이 없는 모델: User Class 는 여러 목적에 무리하게 사용되고 있으며, Modeling 된 것처럼 보이지만 Modeling 되어 있지 않음
- 설계 품질 문제가 될 때 이유를 확인해 보면 Modeling 이 제대로 되어 있지 않아 그저 작동만 하는 코드로 작성되어 있는 경우가 많음
13.3.1. User 와 System 의 관계
- User 가 무엇인가? = 사용자는 무엇인가? = 사용자는 무엇을 사용하는가?
- 사용자는 System 을 사용 =
System User
[UML > System Usecase Diagram]
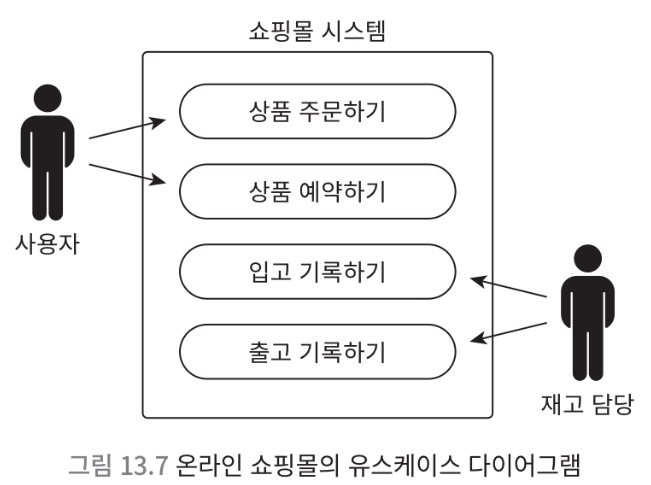
actor: System 사용자, System 의 바깥에 있음사각형: System
- 시스템 내부에 User 가 포함되는 것은 조금 부자연스러움
- 정보가 안과 밖에 얽혀 있는 관계를 해소하려면, 정보 시스템만이 갖는 특징을 활용해야 함
13.3.2. 가상 세계를 표현하는 정보 시스템
- 정보 시스템의 기반 = 컴퓨터 = 0과 1 bit 로 구성되는 세계
- 물리적인 것이 아니라 개념적인 사항
정보 시스템이란? 현실 세계에 있는 개념만을 컴퓨터 세계에 투영하는 가상 현실
13.3.3. 목적별로 모델링하기
- 각각의 매체는 목적에 따라 표현 방법과 이름이 다름
- 따라서 User 또한 목적에 따라 표현이 다를 수 밖에 없음
Remind! Model? 특정 목적 달성을 위해, 최소한으로 필요한 요소를 갖춘 것
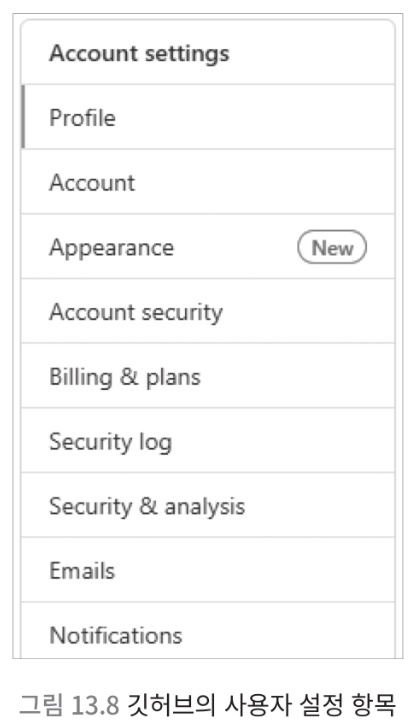
- Github 사용자의 목록을 보면 목적 별로 나누어져 있음
- 정보 시스템에서는 현실 세계에서 있는 물리적인 존재와 정보 시스템에 있는 모델이 무조건 일대일 대응이 되지 않음
- 설계 품질을 생각할 때 이 부분을 특히 주의해야 함
13.3.4. Model 은 대상이 아니라 목적 달성의 수단
- Model 을 단순한 대상으로 해석하면 안됨
Model? System 전체가 아니라 특정한 목적 달성과 관련된 부분만을 추려 표현한 시스템 일부
- 목적 달성 수단 으로 해석해야 제대로 모델링 가능
- 목적 중심으로 이름을 잘 설계하면, 목적을 달성하기에 적절한 모델을 설계 가능
13.3.5. 단일 책임이란 단일 목적
- User Class 를 너무 많은 목적으로 사용해서 문제가 발생
Class 가 이루어야 하는 목적은 반드시 하나여야 한다
- 특정 목적에 특화되게 설계해야, 변경하기 쉬운 고품질 구조를 갖게 됨
"책무를 잘 생각해서 설계하자"
13.3.6. Model 을 다시 확인하는 방법
- 해당 모델이 달성하려는 목적을 모두 찾아냄
- 목적별로 모델링을 다시 수정
- 목적 중심 이름 설계를 기반으로 모델에 이름을 붙임
- 모델에 목적 이외의 요소가 들어가 있다면 다시 수정
13.3.7. Model과 구현은 반드시 서로 피드백하기
- Model 은 구조를 단순화한 것에 불과하므로 세부적인 내용은 따로 묘하사지 않음
- Model 을 기반으로 클래스를 설계하고 코드를 구현하면서 세부적인 내용을 수정해야 함
- Model != Class
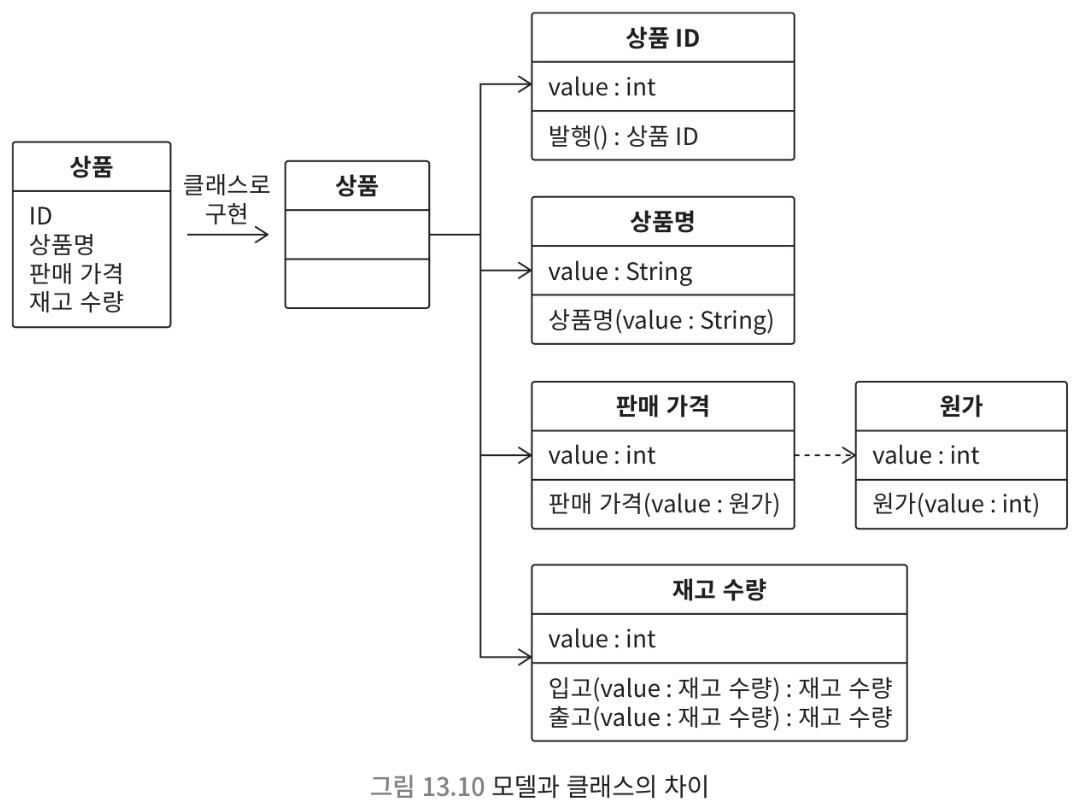
- Class 설계와 구현에서 무언가를 깨닫는다면, 이를 Model에 피드백해야 함
- Feedback 을 하면 Model 이 더 정확해짐
- 그러면 Model structure를 개선할 수 있고, 이는 코드 품질 향상에 기여
- Feedback 을 하지 않으면,
Model Structure와Source Code사이에 괴리가 생김 - Feedback Cycle 을 계속 돌리는 것이 설계 품질을 높이는 것이 비결
13.4. 기능을 좌우하는 Modeling
기능성: 소프트웨어 품질 특성 중 하나, 고객의 니즈를 만족하는 정도
13.4.1. 숨어 있는 목적 파악하기
- 온라인 쇼핑몰에서 상품 구매 모델링을 생각해보면 아래와 같음
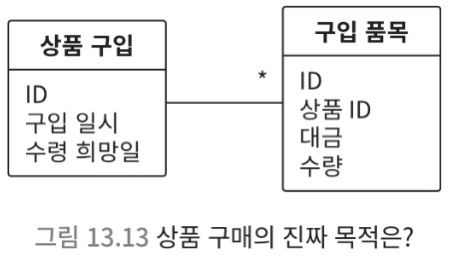
- 이러한 모델은 기능을 발휘하기 힘듬
- 상품 구매 뒤에 숨어 있는 진짜 모습 때문
상품 등의 매매 계약은 구매 회원의 구매 신청에 대하여 회사 또는 판매 회원이
승낙의 의사를 표시함으로써 체결됨- 매매 계약 = 지불 시기와 결ㄹ제 방법 등 지불 조건을 지정해야 함
- 위의 모델에는 지불 조건에 해당하는 요소가 없음
- 법적인 내용이 시스템에 반영되어 있지 않다면, 문제가 일어남
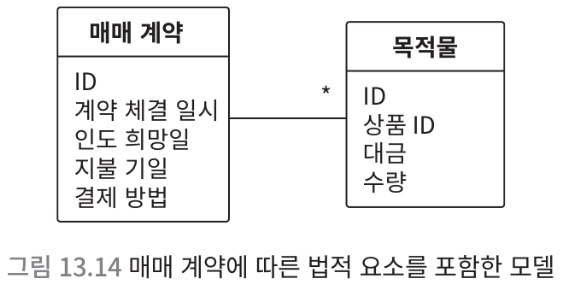
개념의 정체와뒤에 숨어 있는 중요한 목적을 잘 파악하는 것이 중요
13.4.2. 기능성을 혁신하는 깊은 모델
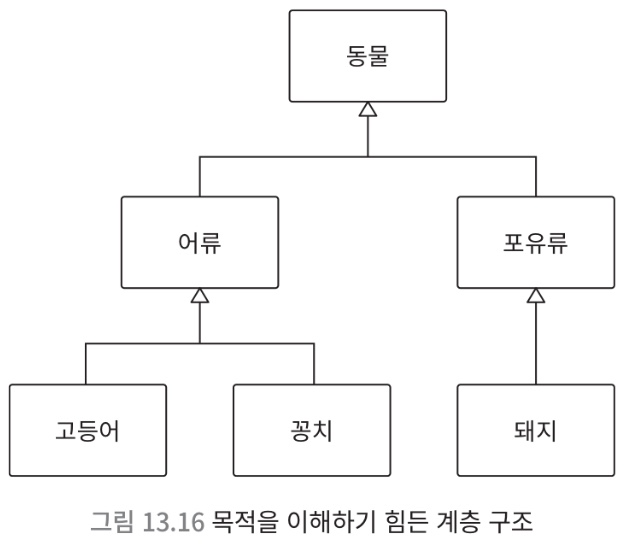
- 이와 같은 추상화에는 다소 문제가 있음
- 각 모델이 어떤 역할을 하고 있는지 전혀 알 수 없음
- 모델 = 목적 달성 수단
- 위의 모델이 어떤 목적을 달성하기 위한 수단인지 확인이 필요
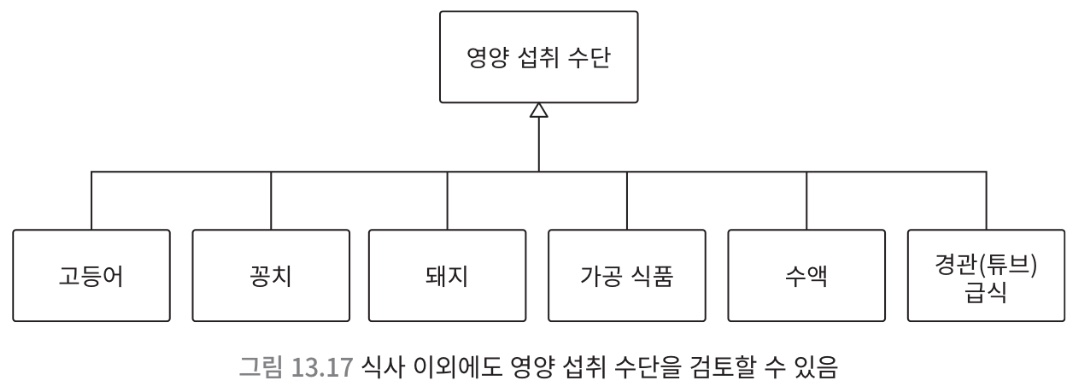
- 영양 섭취 수단으로써의 모델로 재정의
- 컴퓨터의 본질은 0과 1이라는 신호를 변환하고, 신호 변환을 응용해서 연산하는 것
- 뛰어난 변환 능력을 갖춘 모델을 설계하는 것이 곧 기능성의 혁신으로 이어짐
deep model? 본질적인 과제를 해결하고 기능성 현식에 공현하는 모델
- deep model 은 수많은 시행착오를 거듭하고 모델을 계속해서 개량하는 과정에서 발상이 전환됨
- 설계는 매일 매일 반복해서 개선하는 것이 중요
14장. Refactoring: 기존의 코드를 성장시키는 기술
14.1. Refactoring 흐름
Refactoring: 실질적인 동작은 유지하면서, 구조만 정리하는 작업
class PurchasePointPayment {
...
PurchasePointPayment(final Customer customer, final Comic comic) {
if (customer.isEnable()) {
if(comic.isEnable()) {
if(comic.currentPurchasePoint.amount < customer.possessionPoint.amount) {...}
}
}
}
}14.1.1. 중첩을 제거하여 보기 좋게 만들기
class PurchasePointPayment {
...
PurchasePointPayment(final Customer customer, final Comic comic) {
if (!customer.isEnable()) {...}
if(!comic.isEnable()) {...}
if(comic.currentPurchasePoint.amount < customer.possessionPoint.amount) {...}
}
}14.1.2. 의미 단위로 로직 정리하기
- 조건 확인과 값 대입 로직을 각각 분리해서 정리
class PurchasePointPayment {
...
PurchasePointPayment(final Customer customer, final Comic comic) {
if (!customer.isEnable()) {...}
customerId = customer.id;
if(!comic.isEnable()) {...}
comidIc = comic.id;
if(comic.currentPurchasePoint.amount < customer.possessionPoint.amount) {...}
comsumptionPoint = comic.currentPurchasePoint;
}
}class PurchasePointPayment {
...
PurchasePointPayment(final Customer customer, final Comic comic) {
if (!customer.isEnable()) {...}
if(!comic.isEnable()) {...}
if(comic.currentPurchasePoint.amount < customer.possessionPoint.amount) {...}
customerId = customer.id;
comidIc = comic.id;
comsumptionPoint = comic.currentPurchasePoint;
}
}14.1.3. 조건을 읽기 쉽게 하기
customer.isEnable()이라고 하면 보기 편하지만!customer.isEnable()이라고 하면 보기가 어려움- 코드를 읽을 때 한 번 더 생각해서 유효하지 않다라고 변경해서 읽어야 함
class PurchasePointPayment {
...
PurchasePointPayment(final Customer customer, final Comic comic) {
if (customer.isDisable()) {...}
if(comic.isDisable()) {...}
...
}
}14.1.4. 무턱대고 작성한 로직을 목적을 나타내는 method 로 바꾸기
if(comic.currentPurchasePoint.amount < customer.possessionPoint.amount) {...}- 이렇게 작성한 로직은 목적을 알기 힘듬
- 무턱대고 로직을 작성하지 말고 목적을 나타내는 메서드로 만들어서 사용하는 것이 좋음
class Customer {
...
boolean isShortOfPoint(Comic comic) {
return comic.currentPurchasePoint.amount < customer.possessionPoint.amount
}
}class PurchasePointPayment {
...
PurchasePointPayment(final Customer customer, final Comic comic) {
if (customer.isDisable()) {...}
if(comic.isDisable()) {...}
if(customer.isShortOfPoint(comic)) {...}
...
}
} 14.2. Unit Test로 Refactoring 중 실수 방지하기
- Unit Test : 작은 기능 단위로 동작을 검증하는 테스트
- Refactoring 을 할 때는 Unit Test 는 필수
14.2.1. 코드 과제 정리하기
14.2.2. TestCode 를 사용한 Refactoring 흐름
- 이상적인 구조의 클래스 기본 형태를 어느 정도 잡음
- 이 기본 형태를 기반으로 테스트 코드 작성
- 테스트를 실패 시킴
- 테스트를 성공시키기 위한 최소한의 코드 작성
- 기본 형태의 클래스 내부에서 Refactoring 대상 코드 호출
- 테스트가 성공할 수 있도록, 조금씩 로직을 이상적인 구조로 Refactoring
14.3. 불확실한 사양을 이해하기 위한 분석 방법
- Unit Test 를 사용한 Refactoring 은 처음부터 사양을 알고 있다는 전제가 있기에 테스트를 작성할 수 있었음
- 실제 개발을 하다보면 사양을 모르는 경우도 많음
- 사양을 제대로 모른다면 Refactoring 을 위한 Unit Test 를 작성할 수 없음
14.3.1. 사양 분석 방법 1: 문서화 테스트
public class MoneyManager {
public static int calc(int v, boolean flag) {...}
}- calc method 가 무슨 기능을 하는지 알 수 없음
- 따라서 안전하게 Refactoring 할 수 없음
- 이때 활용하는 기법 =
문서화 테스트
- 문서화 테스트 : 메서드의 사양을 분석하는 방법
- 테스트를 변경해가면서 메서드가 어떻게 동작하는지 확인
@Test
void characterizationTest() {
int actual = MoneyManager.calc(1000, false);
assertEqual(1000, actual);
}- 매개변수를 변경해가면서 method 가 어떻게 동작하는지 파악
문서화 테스트 : 분석하고 싶은 메서드의 테스트를 작성해서, 해당 method 가 어던 동작을 하는지 확인하는 방법
14.3.2. 사양 분석 방법2: Scratch Refactoring
- 정식 Refactoring 이 아니라 로직의 의미와 구조를 분석하기 위해 시험 삼아 Refactoring
- TestCode 를 따로 작성하지 않고 코드를 Refactoring
[장점]
- 코드의 가독성이 좋아져 로직의 사양을 이해할 수 있음
- 이상적인 구조가 보여 어느 범위를 메서드 또는 클래스로 끊어야 좋을지 보임
- Dead code 가 보임
- TestCode 를 어떻게 작성해야 할지 보임
14.4. IDE의 Refactoring 기능
14.4.1. Rename
- 한 번에 class, method, 변수 이름을 전부 변경하는 Refactoring
14.4.2. method 추출
14.5. Refactoring 주의 사항
14.5.1. 기능 추가와 Refactoring 동시에 하지 않기
- 기능 추가와 Refactoring 을 따로 구분하지 않으면 기능을 구분하기 힘듬
14.5.2. Small Step 으로 실시하기
- commit 은 어떻게 Refactoring 했는지 차이를 알 수 있는 단위로 구분
- 여러 번 commit 했다면 PR 을 작성하는 것이 좋음
14.5.3. 불필요한 사양은 제거 고려하기
- 불필요한 사양이 있으면 Refactoring 이 힘들어짐
- 이처럼 이익에 거의 기여하지 않는 사양에 해당하는 코드는 Refactoring 해도 이익이 없음
- 따라서 사양을 다시 활용해 불필요하다면 없애는 것이 좋음
15장. 설계의 의의와 설계를 대하는 방법
15.1. 이 책은 어떤 설계를 주제로 집필한 것인가?
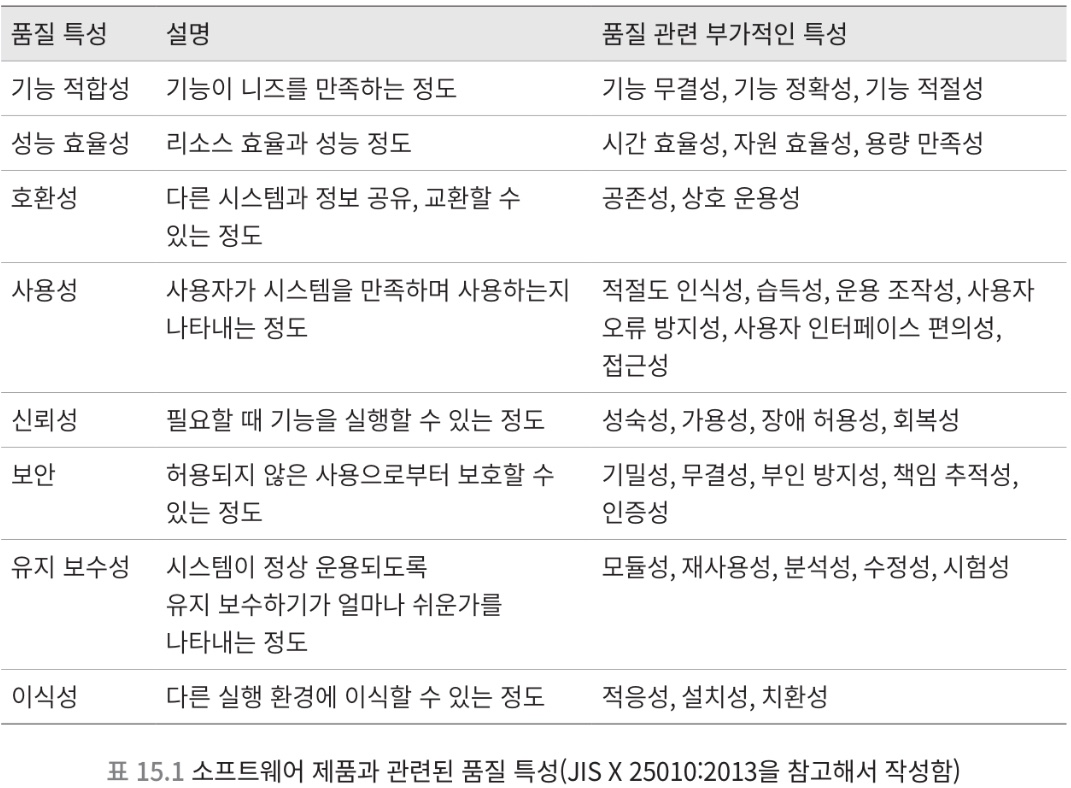
- 설계 : 어떠한 문제를 효율적으로 해결하는 구조를 만드는 것
- 소프트웨어 설계 : 어떤 소프트웨어의 품질 특성을 향상시키기 위한 구조를 만드는 것
- 악마의 성질과 가장 관련 있는 품질 특성은
유지 보수성 - 유지 보수성 : 시스템이 정상 운용되도록 유지 보수하기가 얼마나 쉬운가를 나타내는 정도
- 수정성 : 변경 용이성이라고도 부르며, 얼마나 쉽고 정확하게 코드를 변경할 수 있는지 나타내는 지표
15.2. 설계하지 않으면 개발 생산성이 저하된다
- Legacy Code : 변경하기 어렵고, 버그가 생기기 쉬운 코드
- technical debt : Legacy code 가 축적되어 있는 상태
15.2.1. 요인 1: 버그가 발생하기 쉬운 구조
- 응집도가 낮은 구조로 인해 사양 변경 시 수정 누락이 발생하기 쉬워지고 결국 버그가 발생
- 코드를 이해하기 어려우므로 구현할 때 실수를 저지르기 쉬워지고, 결국 버그가 발생
- 잘못된 값이 들어오기 쉬워지고, 결국 버그가 발생
15.2.2. 요인 2: 가독성이 낮은 구조
- 로직의 가독성이 낮아, 읽고 이해하는 데 시간이 오래 걸림
- 관련된 로직이 이곳저곳에 흩어져 있어, 사양을 변경할 때 관련된 로직을 찾아서 돌아다니는 데 시간이 오래 걸림
- 잘못된 값이 들어와서 버그가 발생했을 때, 잘못된 값의 출처를 추적하기 어려워 짐
15.2.3. 나무꾼의 딜레마
나무꾼의 도끼의 날이 너무 무딘 것 같아요
도끼를 갈고 나무를 베는 것이 좋지 않을까요
알고 있지만, 나무를 베는 것이 바빠서 도끼를 갈 시간이 없었어요- 제대로 설계하지 않으면, 로직 변경과 디버그에 많은 시간을 소비하게 됨
- 결국 설계할 시간 여유조차 없어지는 딜레마에 빠짐
15.2.4. 열심히 일했지만 생산성이 나쁨
- 어쨋거나 열심히 일했다! 가 아니라 성과를 내기 위해 쉬운 구조를 설계하는 데 노력을 쏟지 않았다면, 열심히 했다라고 이야기하기 어려움
15.2.5. 국가 규모의 경제 손실
- Legacy Code 의 양에 단순 비례하지 않음
- 복잡하고 이해하기 힘든 로직이 있으면, 이로 인해 더 복잡하고 이해하기 힘든 로직이 만들어짐
- 소스 코드가 점점 거대해지면, 이러한 문제가 점점 가속화됨
- 결국 기능 추가가 너무 힘들어져, 릴리스가 어려워질 정도로 악화됨
15.3. Software 와 Engineer 의 성장 가능성
- 소프트웨어의 가치와 매력을 높이기 위해 사양을 추가하고 변경하면서, 코드를 변경
- 코드의 변경 용이성이 높을수록 소프트웨어의 가치를 빠르게 높일 수 있음
- 소프트웨어가 빠르게 성장하는 것
변경 용이성이 높다=소프트웨어의 성장 가능성이 높다
15.3.1. Engineer 에게 Asset 이란?
- 기술력!
- 기술력은 엔지니어가 부를 창출하는 원천
- Legacy Code 는 이러한 자산의 축적, 기술력의 성장을 방해하는 무서운 존재
15.3.2. Legacy Code 는 발전을 막음
- Legacy Code 는 다음 사람으로 하여금 Legacy Code 를 작성하게 함
- 즉 낮은 수준의 기술만 사용하게 만듬
15.3.3. Legacy Code 는 고품질 설계 경험을 막음
- Legacy code 는 균형이 이미 깨져 있어, 설계를 개선하기가 매우 힘듬
15.3.4. Legacy Code 는 시간을 낭비하게 만듬
- 이해하는 데 오랜 시간이 걸림 하지만 시간은 유한함
- 따라서 원래 더 가치있는 일에 사용되었어야 하는 시간이 줄어듬
- 기술 향상을 막고, 엔지니어에게 정말 중요한 자신이라 할 수 있는 기술력의 축적을 막음
15.4. 문제 해결하기
15.4.1. 문제를 인식하지 못하면 설계에 대한 생각 자체가 떠오르지 않음
15.4.2. 인지하기 쉬운 문제와 인지하기 어려운 문제가 존재
- Software System 에 대해 정의한 metric
- 악마가 어떤 문제를 일으키는지 모른다면, 기술 부채의 존재를 인식하기 힘듬
- 소스 코드를 독해하는 스킬과 기술 부채를 인식하는 스킬은 전혀 다름
15.4.3. 이상적인 형태를 알아야 문제를 인식할 수 있음
- 이상적인 형태가 어떤 것인지 스스로 자세하게 정의할 수 있어야 함
- 이상이 무엇인지 알고 있다면, 현실과 비교하며 차근 차근 문제 해결 가능
15.4.4. 변경 용이성을 비교 수 없는 딜레마
- 기술 부채를 줄이는 변경 용이성 설계의 효과는 어떻게 측정하면 될까?
- 변경 용이성은 곧바로 비교할 수 없음
- 미래의 변경 비용이 얼마나 낮은지 나타내는 것으로 시간이 경과해야 알 수 있음
- 따라서 거의 불가능 함
15.5. 코드의 좋고 나쁨을 판단하는 지표
Code metric,Software metric: 코드 복잡성과 가독성 등의 품질 지표
15.5.1. 실행되는 코드의 줄 수
- 주석을 제외하고, 실행되는 로직을 포함하는 코드의 줄 수
- 많으면 많을수록 너무 많은 일을 하고 있을 가능성이 높음
- 줄 수가 너무 많으면 method 와 class 분할을 검토
15.5.2. Cyclomatic complexity
- 코드의 구조적인 복잡함을 나타내는 지표
15.5.3. 응집도
- 모듈 내부에서 데이터와 로직이 관련되어 있는 정도
- 응집도가 높을수록 변경 용이성이 높고 좋은 구조
- 응집도 메트릭 LCOM (Lack of Conhension in Methods) 가 있음
15.5.4. 결합도
- 모듈간의 의존도
- 어떤 클래스가 호출하는 다른 클래스의 수
- 의존하고 있는 클래스가 많으면 많을수록, 결합도가 높을 수록 더 넓은 범위를 고려해야 함
- Class Diagram 으로 확인할 수 있음
15.5.5. Chunk
Magical Number 4: 인간의 단기 기억은 한번에 4 ± 1 의 개념 정도만 파악할 수 있음Chunk: 기억할 수 있는 정보 덩어리의 단위
- 프로그래밍은 굉장히 많은 종류의 데이터/로직을 보는 직업
- 데이터와 사양 변경이 어디에 영향을 주는지, 버그가 발생하지 않는지 등 다양한 요소를 보고 검증해야 함
- 하지만 클래스가 너무 거대하면 제대로 파악할 수 없음
- class 를 설계할 때도 Magical Number 4 를 염두해두고 뇌가 쉽게 받아들일 수 있는 구조인지 생각
- 이보다 큰 Class 는 작은 Class 로 분할하는 것이 좋음
15.6. 코드 분석을 지원하는 다양한 도구
15.6.1. Code Climate Quality
- Code Climate 사에서 만든 코드 품질 분석 도구
- Github 와 연동하면 저장된 코드의 품질 점수를 자동으로 계산
15.6.2. Understand
- 코드 줄 수, 복잡도, 응집도 (LCOM), 결합도 이외의 다양한 관점의 메트릭 계측 가능
15.6.3. Visual Studio
- Community Version 을 통해 모든 license 형태에서 Code metric 계산 가능
15.7. 설계 대상과 비용 대비 효과
- 회사의 예산은 유한하고, 유한한 예산 안에서 개발 비용이 산축
- 투자한 비용과 제한된 기간 내에 어떻게든 이익을 내야 함
- 설계와 리팩터링은 무한히 할 수 없음
- 따라서 비용 대비 효과가 높은 부분을 노려야 함
15.7.1. 파레토의 법칙 (80:20의 법칙)
- 전체 결과가 80% 가 전체 원인의 20% 에서 일어남
ex) 매출의 80% 는 전체 상품 중 20% 의 상품이 만들어냄
- 소프트웨어의 처리 시간 중 80% 는 소스 코드 전체의 20%가 차지
- 소프트웨어의 기능 전체 중에서 중점적으로 사용되는 기능은 1/3 정도 밖에 안됨
- 사양이 자주 바뀌는 곳도 일부에 한정되어 있음
- 중요한 기능에는 고객들이 주목하므로 개선 요구도 당연히 많음 따라서 사양도 자주 변경됨
- 중요하고 사양 변경이 빈번한 곳의 설계를 개선하면 비용 대비 효과가 높음
15.7.2. Core Domain: Service 중심 영역
- 모든 상품과 서비스 = 우리가 판매하는 것 = 중심 가치
- 시스템에서 가장 큰 가치를 창출하는 곳
- 가치 있고 중요하고 비용 대비 효과가 가장 큰 곳
- 경쟁 우위에 있고 차별점을 만들며, 비즈니스 우위를 만들 수 있는 곳
15.7.3. 중점 설계 대상 선정에는 비즈니스 지식이 필요함
- Service 가 거대해지면 무엇이 서비스의 중심 가치인지 알기 힘들어짐
- Domain 주도 설계 = Core Domain 의 가치를 지속적으로 높이고, 서비스를 장기적으로 성장시키는 설계 방법
- 설계 비용 대비 효과를 높이려면 중점적인 설계 대상을 선정할 수 있어야 함
- 대상을 잘 선정하려면, 서비스가 해결하고 싶은 고객 과제가 무엇인지, 서비스의 본질이 무엇인지 볼 수 있는 능력이 필요
- 서비스와 관련된 비즈니스 지식이 필요
15.8. 시간을 다스리는 능력자 되기
- 변경 용이성 설계 = 개발 생산성 향상 = 미래의 시간을 다룰 수 있음
- Legacy Code 를 안고 계속해서 기술 부채를 쌓아갈지 소프트웨어를 빠르게 성장시킬지는 모두 설계자의 능력에 달림
- 엔지니어가 아니면 표면적인 기능만 봄
- 엔지니어는 내부 구조를 머릿속에 그릴 수 있음
- 머릿속에 그리는 능력과 설계 능력을 활용하면 미래의 시간을 조종할 수 있음
16장. 설계를 방해하는 개발 프로세스와의 싸움
16.1. Communication
16.1.1. Communication 이 부족하면 설계 품질에 문제가 발생
- Team Communication 이 부족하면 서로가 무엇을 하고 있는지 잘 모름
- 팀원간 의사소통에 문제가 있으면 버그가 많아짐
16.1.2. Conway's law
- 시스템의 구조는 그것을 설계하는 조직의 구조를 닮아간다
- 개발 부문이 3개의 팀으로 구분되어 있다면, 모듈의 수도 3개로 구성되는 시스템
- 왜냐하면 여러 개의 팀을 편성하면, 커뮤니케이션은 각각의 팀 내에서만 활발하게 이루어짐
- 따라서 시스템의 구조가 Release 단위, 즉 팀 단위의 구조처럼 구성
- Conway's law = Communication 비용 구조의 법칙
- 팀 내부에서 이뤄지는 커뮤니케이션 비용은 낮고
- 외부와 이뤄지는 커뮤니케이션 비용은 높음
Inverse conway's law: 소프트웨어 구조를 먼저 설계하고 소프트웨어 구조에 맞게 조직을 편성- 하지만 표면적으로 내세우는 것만으로 효과가 크지 않음
- 팀간의 관계, 팀 내부와의 관계를 잘 파악해야 함
16.1.3. 심리적 안정성
- 어떤 발언을 했을 때 부끄럽거나, 거절 당하지 않을 것이라는 확신
- 안심하고 자유롭게 발언 또는 행동할 수 있는 상태
- 성공적인 팀을 구축할 때 매우 중요한 개념
- 커뮤니케이션에 문제가 있을 때는 일단 심리적 안정성 향상에 힘쓰는 것이 좋음
16.2. 설계
16.2.1. 빨리 끝내고 싶다는 심리가 품질 저하의 함정
- 품질이 나쁜 시스템을 만드는 팀은 클래스 설계와 관련된 습관이 애초에 없음
- 빨리 끝내고 싶은 마음이 앞서고 그냥 동작하면 구현
- 품질을 무시하고 구현하는 과정이 반복되면 조악한 코드는 점점 조악해짐
16.2.2. 나쁜 코드를 작성하는 것이 좋은 코드를 작성하는 것보다 오래 걸린다
- TDD 를 사용하는 편이 전체적으로 보았을 때 더 빠르다는 결론
16.2.3. Class 설계와 구현 Feedback Cycle 돌리기
- 사양을 변경할 때는 최소한 메모로라도 클래스 다이어그램을 그림
- 이를 기반으로 책무와 응집도 등의 관점에서 문제가 없는지 간단하게 리뷰
16.2.4. 한 번에 완벽하게 설계하려고 들지 말고, 사이클을 돌리며 완성하기
- 대규모로 변경할 때는 그만큼 확실한 클래스 설계가 필요
- 완벽하게 설계하려는 욕심을 버리고 피드백 사이클을 돌리면서 조금씩 향상 시킴
16.2.5. 성능이 떨어질 수 있으니 클래스를 작게 나누지 말자는 맞는 말일까?
- 클래스가 많아지면 비용이 발생하는 것은 맞음 하지만 대부분은 무시할 수 있는 정도
- 실제로 성능과 관련 없는 부분인데, 이렇게 하면 빠를 것이다 라고 생각하고 작성하는 코드는 대부분 변경 용이성이 낮음
16.2.6. 설계 규칙을 다수결로 결정하면 코드 품질은 떨어진다
- 아무래도 수준이 낮은 쪽에 맞춰서 하향평준화되기 쉬움
- 조악한 규칙이 채택될 수 있고, 규칙 자체가 만들어지지 않을 수 있음
16.2.7. 설계 규칙을 정할 때 중요한 점
- 시니어 엔지니어처럼 설계 역량이 뛰어난 팀원이 중심이 되어 규칙을 만드는 것이 좋음
- 각각의 설계 규칙에는 이유와 의도를 함께 적는 것이 좋음
- 설계 규칙은 성능이나 프레임워크의 제약 등 다양한 요건과 트레이드 오프 될 가능성이 있음
- 규칙을 무조건 지켜야 하는 것은 아니며, 타협점을 찾아야 하는 상황도 분명 존재
- 팀의 설계 역량이 성숙하지 않으면, 개인에게만 맡기지 말고, 설계를 어느 정도 아는 팀원이 설계 리뷰와 코드 리뷰를 하도록 해서 설계 품질을 관리
- 팀원들과 스터디를 진행해보면서, 팀 전반의 설계 역량을 조금씩 높이는 것도 중요
16.3. 구현
16.3.1. 깨진 유리창 이론과 보이스카우트 규칙
16.3.2. 기존 코드를 믿지 말고, 냉정하게 판단하기
- 의심 없이 코드를 받아들이지 말고, 계속해서 확인해라
- 정체를 파악하는 행위
- 구조적으로 이상한 것
- 클래스 이름과 메서드 이름이 이성한 것
- 사양과 다른 이름을 갖고 있거나
- 사양이 비슷하면서 다른 의미의 이름이 붙어 있는지 않은지 확인
[장애물]
- Anchoring Effect
- 처음 제시한 수치와 정보가 기준이 되어, 이후의 판단을 왜곡하는 인지 편향
- 기존의 클래스 이름과 메서드 이름이 기준이 되어, 개발자의 판단을 왜곡시키는 경우가 많음
- 이름이 없거나 이름을 모르는 것은 인지하기 어려움
- 해결하고 싶은 내용과 달성하고 싶은 목적을 배우는 것이 중요
- 관계자를 찾아 대화하거나 관련된 글을 읽고 그곳에서 쓰이는 용어를 파악하려고 이해해야 함
16.3.3. Code Convention 사용하기
16.3.4. Naming Rule
- 팀 전체에 통일된 규칙을 정하고 이를 활용
16.4. Review
16.4.1. Code Review 구조화하기
- PR code 는 code 의 history 와 경위를 알고 있는 사람 또는 설계를 자세하게 알고 있는 사람이 리뷰하는 것이 좋음
16.4.2. Code 를 설계 시점에 리뷰하기
16.4.3. 존중과 예의
- 기술적 올바름을 두고 공격적인 코멘트를 다는 사람들을 방지해야 함
- 기술적 올바름과 유용성보다도 함께 일하는 동료를 존중하는 것이 먼저
- 존중과 예의를 갖추고 지적하는 것이 코드 품질을 높이는 가장 빠른 길
16.4.4. 정기적으로 개선 작업 진행하기
- 좋은 않은 코드가 스케쥴 문제로 반영되기도 함
- 따라서 최대한 빠른 시일 내에 수정하는 것이 중요
- Github 의 Issue 로 관리하면 좋음
16.5. 팀의 설계 능력 높이기
16.5.1. 영향력을 갖는 규모까지 동료 모으기
- 혼자 힘으로는 품질을 높이려고 해도 효과가 거의 나타나지 않음
- 설계 뿐만 아니라 일의 방식을 상향식으로 개선하려면, 주위의 협력이 반드시 필요
- 협력은 일하는 방식을 바꿀 만큼 큰 영향력이 생김
- Lanchester's laws : 전투력에 따라 적에게 미치는 피해 규모를 계산하는 이론
- Koopman Goal : 시장 점유율의 목표를 정의
- Lanchester's laws 를 시장 점유율에 적용한 경쟁 이론
- 시장 인지권 : 시장 내에서 영향력을 무시할 수 없고, 점유율 경쟁에 본격적으로 참가를 시작하는 위치
- 보통 목표치는 10.9%
- 방향성이 어느 정도 같은 동료에게 말을 걸고 고민을 나누고 협력을 해 줄 동료를 만듬
16.5.2. 천리길도 한 걸음 부터
- 조급하게 굴지 말고 매일 조금씩 설계 지식을 공유
16.5.3. 백문이 불여일견
- 어느 정도 공유했다면, 함께 클래스를 설계하고 구현한 뒤 리뷰
16.5.4. Follow up Study
- 동료를 더 모으면 설계 스터디를 진행해 보는 것도 좋음
- 책에 적혀 있는 노하우 1-2개 정도 읽음
- Production code 에서 노하우를 적용해 볼 수 있는 부분을 찾음
- 노하우를 사용해 코드 개선
- 어떻게 개선했는지 발표
- 발표 내용에 대한 질의 응답
16.5.5. Study Group 에서 발생할 수 있는 문제 해결 노하우
- 단순하게 책을 읽는 것이 아니라 코드를 개선햇을 때 실제로 좋아졌음을 느끼는 것이 중요
- 올바른 설계 방법을 강요하는 것도 좋지 않음
- 다른 사람의 관점에 맞춰 생각하는 일은 힘들지만, 공감대 없이 무리하게 이야기한다면 모두가 불행해짐
- 설계 이야기를 빨리 꺼내고 싶어서 불안하겠지만, 인내가 필요
16.5.6. Leader 와 Manager 에게 설계의 중요성과 비용 대비 효과 설명하기
16.5.7. 설계 책임자 세우기
- 설계 품질과 관련된 규칙이나 개발 프로세스 수립
- 규칙을 반복적으로 알리고 교육
- 리더와 매니저에게 효과 공유
- 품질 시각화
- 설계 품질 유지
17장. 설계 기술을 계속해서 공부하려면
17.1. 책 추천
- 현장에서 유용한 시스템 설계 원칙
- 읽기 좋은 코드가 좋은 코드다
- Refactoring 2판
- Clean Code
- Legacy Code 활용 전략
- Re-Engineering Legacy Software
- Beyond Legacy Code
- Engineering 조직으로의 초대
- Principal of Programming
- Clean Architecture
- Domain Drive Design
- Secure by Design
- 도메인 주도 설계 철저 입문
- 도메인 주도 설계 모델링/구현 가이드
- 도메인 주도 설계 샘플 코드와 FAQ
- Test Driven Development
17.2. 설계 스킬을 높이는 학습 방법
- input : output = 2:8
- 설계 효과를 반드시 머릿속에 새기기
- 악마의 구조를 파악하는 연습
- Refactoring 으로 설계 기수력 높이기
- 동작하는 코드를 작성했다면, 다시 설계하고 커밋하기
- 설계 기술서를 읽으며 더 높은 목표 찾기
