몇 년 전까지만 해도, LLM이 등장하고 모델의 용량을 키우며 성능을 높이는 연구가 많이 나왔다. 하지만 요즘은 이러한 Language Model을 mobile과 같은 device에 담기 위해 sLM(Small Language Model)에 대한 연구가 많이 진행되고 있다. 그 중 최근에 Microsoft에서 공개한 Phi-3에 관한 논문에 대해 리뷰해보고자 한다.
논문 원본 링크: https://arxiv.org/abs/2404.14219
1. Phi-3 소개
- Phi-3-Mini는 3.8억 개의 파라미터를 가지며, 3.3조개의 토큰으로 훈련되었다.
- 모델의 용량이 작아 모바일에서도 작동하며, GPT-3.5와 같은 LLM들과 비교하여 준수한 성능을 보였다.
2. 사양과 모델 아키텍처
- Phi-3 Mini는 Transformer의 Decoder 아키텍처를 기반으로 구성되어있으며, 4K의 context 길이를 가지고 있다.
- 3072의 hidden dimension, 32개의 head, 그리고 32개의 layer로 구성되어 있다.
- 4-bits로 양자화되어 1.8GB밖에 메모리를 사용하지 않아서 iPhone 14와 같은 스마트폰에서 실행될 수 있다.
- 초당 12개 이상의 토큰을 처리할 수 있다.
3. 학습 기술
3-1. 더욱 quality 있는 training set
Phi-3-Mini의 훈련은 high-quality의 데이터를 사용하는 것에서 시작한다.
이 데이터는 웹에서 추출한 정보 + 인공적으로 생성된 데이터를 포함한다. 'education level'에 따라 철저히 필터링된다.
- 일반적인 지식과 언어 이해를 위한 웹 데이터를 사용
- 논리적 사고, 추론 능력과 특정 기술을 가르치기 위한 더욱 엄격하게 필터링된 데이터를 사용
'사실적 지식' 보다는 '추론 능력'을 잠재적으로 향상시키는 데이터를 높은 비율로 사용한다. 단 여기서, 지나치게 사실적인 내용은 모델의 용량만 늘리므로 훈련 세트에서 제외한다.
> 지나치게 사실적인 내용에 대해 논문에서는 특정 날짜의 프리미어리그 경기 결과를 예시로 들고 있다.
3-2. 후처리 과정
후처리는 SFT,DPO 두 단계로 구성된다.
-
SFT: 수학, 코딩, 추론, 대화, 모델 정체성 및 안전성과 같은 다양한 도메인에 걸쳐 filtering 된 데이터를 활용한다.
-
DPO: 챗봇에서 나온 데이터, 추론 작업을 포함하며 모델이 생성한 응답이 부적적절 하면 이를 거부하여 모델이 더욱 적절하고 윤리적인 대답을 하도록 유도한다.
Phi-3-Mini 모델은 기본적으로 4K의 콘텍스트 길이를 지원했지만, 위와 같은 후처리 과정에서 이를 128K로 확장하였다.
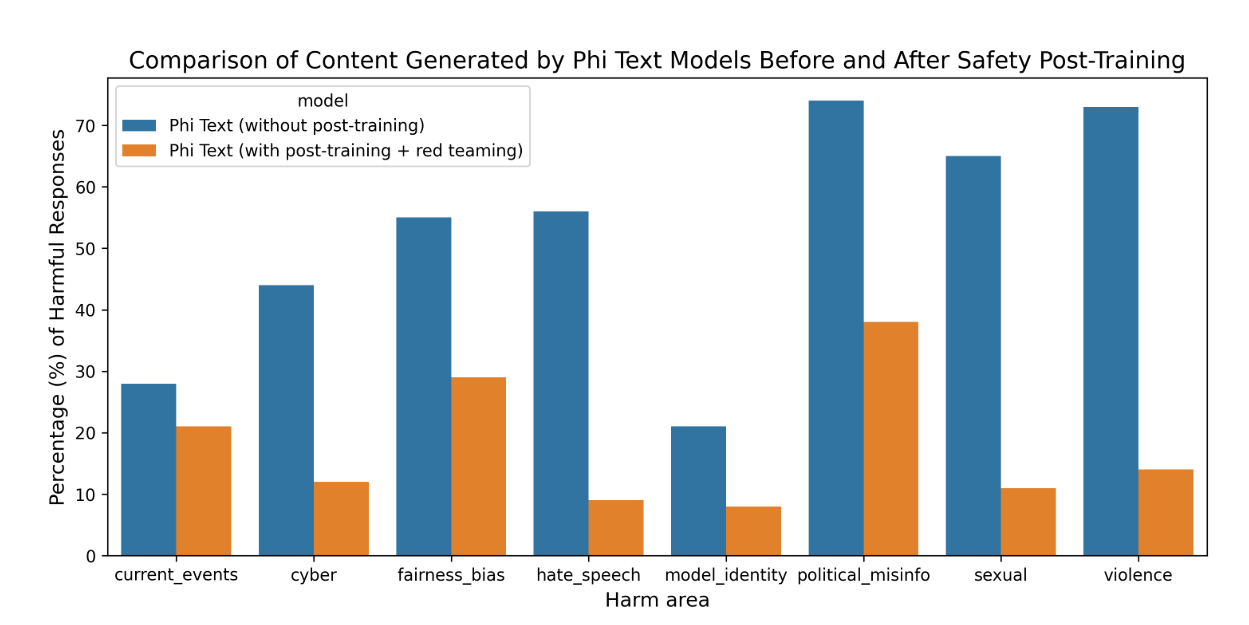
4. 안전성
- Phi-3 Mini는 Microsoft의 RAI(Responsible Artificial Intelligence) 원칙에 따라 개발되었다.
- post-training : AI(RAI)의 원칙에 걸쳐 안전성을 조정한다. 과거에 학습하여 생긴 문제들을 해결하기 위해 데이터셋을 수정하여 다시 training했다.
- Red-teaming: Microsoft 내의 Red team이 Phi-3-mini 모델을 반복적으로 검토하여 post-traning 과정 중 개선점을 확인하고 피드백을 제공했다.
위와 같은 방법으로 학습시켰을 때 아래와 같이 해가되는 대답의 비율이 확연하게 줄었음을 확인할 수 있다.
5. 약점과 해결 방안
- 영어로만 학습하여 다국어 성능이 약함
- factual knowledge를 충분히 학습하지 못함.
-> 검색 엔진을 통해 보안했으며, 앞으로 다국어를 지원하도록 더 연구가 필요함
