"AN IMAGE IS WORTH 16X16 WORDS:
TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE" 논문을 리뷰한 글입니다.
논문 원본 : https://arxiv.org/abs/2010.11929
1. Abstract
- Transformer 구조는 NLP분야에서 "사실상 표준"이 됨. 하지만 vision 분야에서의 적용은 아직 제한됨.
- vision 분야에서 attention 구조는 CNN과 함께 CNN의 특정 구성 요소를 유지하면서 CNN을 대체하는 데 사용됨.
- 기존 attention구조에 의존하지 않고, Transformer구조를 image classfication task를 수행하는 데 사용했더니 좋은 성능을 낼 수 있다는 것을 확인하였음.
- 이런 구조를 Vision Transformer라고 부르며 대용량 dataset에서 더 좋은 성능을 냄.
2. Introduction
- Transformer구조는 1000억개의 파라미터를 학습할 수 있음.
- NLP의 성공에서 영감을 받아서 vision 분야에서도 attention구조가 CNN구조를 대체하는 연구가 진행되고 있음.
- 구체화된 attention구조는 현재 최신의 hardware에서 아직 구조화되지 못하여 ResNet 구조가 아직까지 제일 좋은 성능을 내고 있음.
- NLP분야에서 Transformer구조의 성공에서 영감을 받아 본 연구에서는 vision분야에서 Transformer구조를 쓰는 것을 연구함.
- 위와 같이 하기 위해 image를 여러개의 patch로 나누고 linear embedding을 통해 Transformer 구조에 input으로 넣음.
- 데이터가 적으면 ResNet보단 성능이 좋지 못했지만, 1400만~3억개의 image dataset을 학습시킬 땐 눈에 띄게 성능이 좋아짐을 확인함.
3. Related Work
- Transformer구조는 BERT와 GPT같은 NLP 모델에서 많이 사용되고 있음.
- vision 분야에서 attention 아키텍처가 쓰일 수 있음을 많은 연구들이 보였지만 하드웨어 자원을 효과적으로 써서 학습시키려면 복잡한 engineering을 필요로 함.
- 본 연구와 관련있는 모델로 image GPT(iGPT)가 있음. 이는 image의 해상도와 color space를 낮춰서 이미지 픽셀을 Transformer에 넣는 방식 이지만 ImageNet 데이터애서 accuracy가 72%밖에 되지 않음.
4. Method
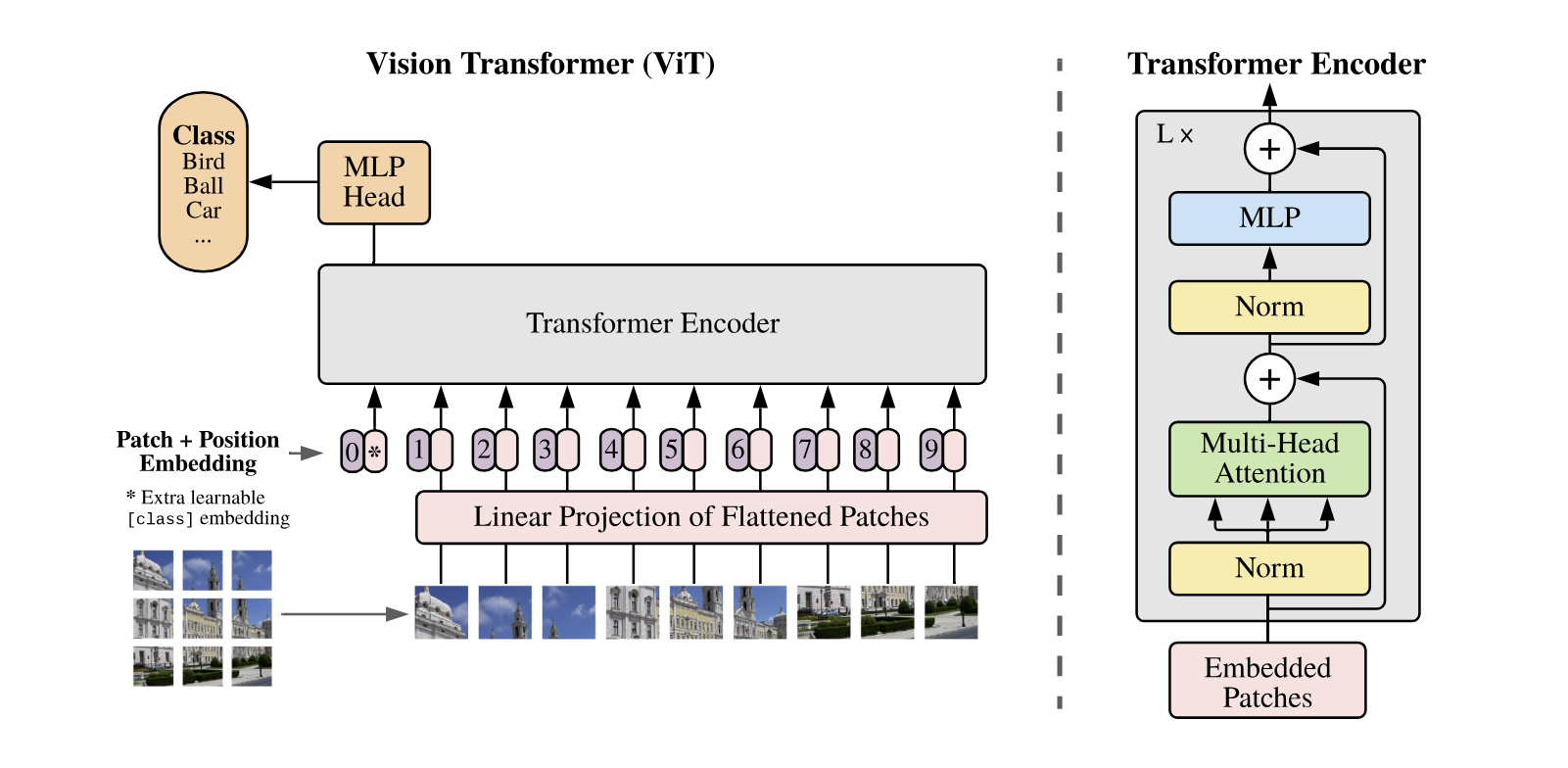
- NLP에서 쓰이는 Transformer구조와 최대한 비슷하게 Model을 디자인함. Encoder는 MSA(Multi-Self-Attention, MLP로 이루어져있음.
4-1. VIT
- 모델의 overview는 위의 사진과 같음.
- 사진을 patch로 나누어서 flatten한 뒤 D차원으로 linear projection을 진행
- 이후 1D Position embedding을 통해 위치 정보를 나타내도록 함.
- 이렇게 나온 값을 Encoder에 집어 넣음.
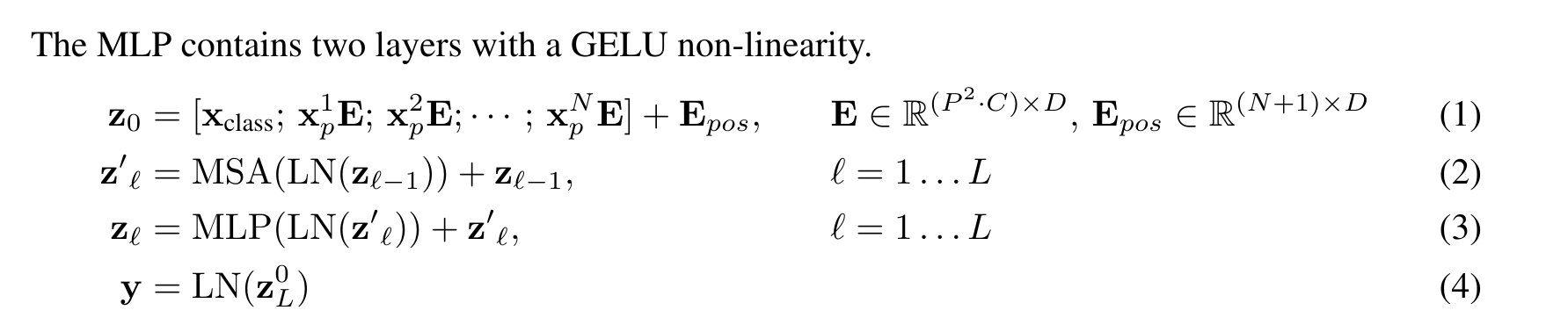
-> Encoder 모델

ai 개발자를 꿈꾸는 대학생