
본 내용은 한빛미디어의 [혼자 공부하는 머신러닝+딥러닝]을 참고하였습니다.
06. 비지도 학습(비슷한 과일끼리 모으자!)
06-1. 군집 알고리즘
- 비지도 학습 : 머신러닝의 한 종류, 지도 학습과 다르게 훈련 데이터에 타깃이 없음.
- 군집 : 비슷한 샘플끼리 하나의 그룹으로 모으는 비지도 학습 방법. 이렇게 모인 샘플 그룹을 클러스터(Cluster)라고 부름.
06-2. K-means
- 클러스터 중심(센트로이드) : k-means 알고리즘이 만든 클러스터에 속한 샘플의 특성 평균값.
- k-means 알고리즘의 작동 방식
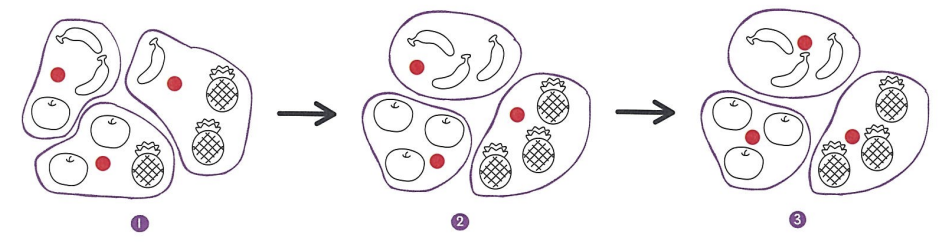
1. 무작위로 k개의 클러스터 중심을 정함
2. 각 샘플에서 가장 가까운 클러스터 중심을 찾아 해당 클러스터의 샘플로 지정.
3. 클러스터에 속한 샘플의 평균값으로 클러스터 중심을 변경
4. 클러스터 중심에 변화가 없을 때까지 2번으로 돌아가 반복.
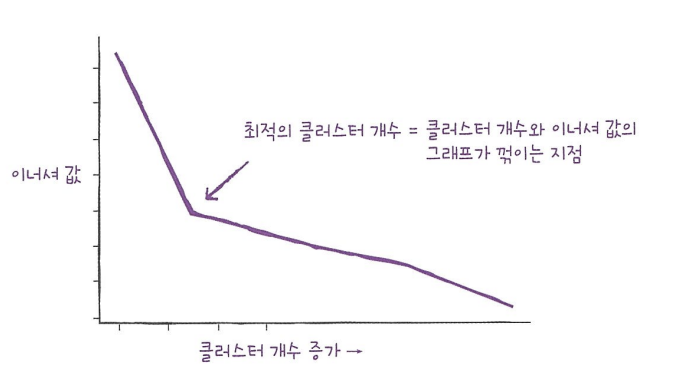
- 최적의 K를 찾는 방법?
-> 엘보우 방법 : 클러스터 개수에 따라 **이너셔 감소가 꺾이는 지점을 찾아 이 때의 클러스터 개수를 적절한 k로 지정.
이너셔 : 클러스터 중심과 클러스터에 속한 샘플사이의 거리 제곱 합
06-3. 주성분 분석
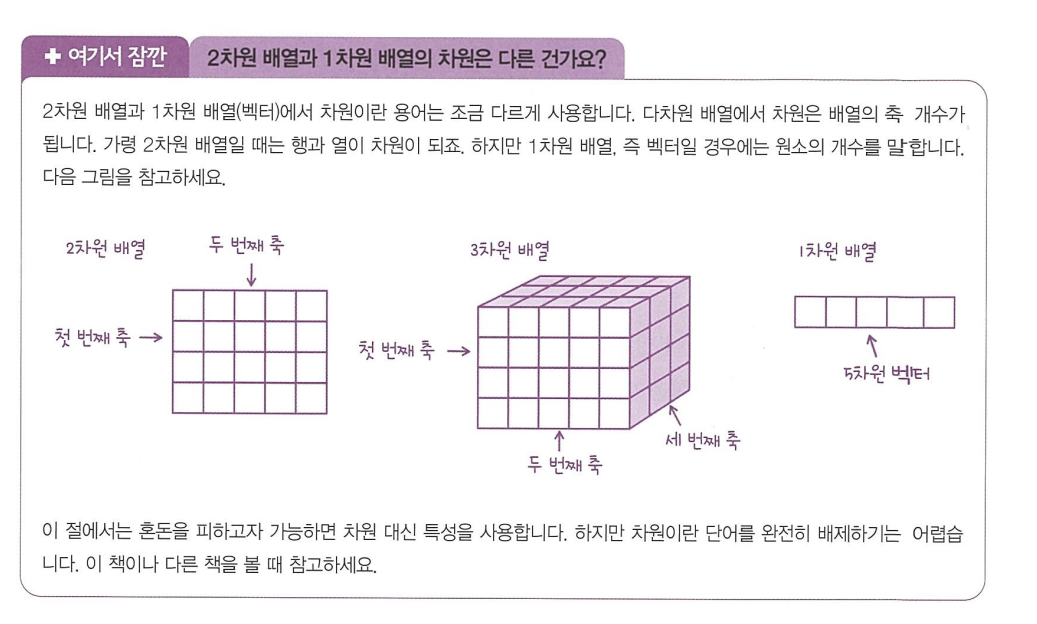
- 차원 : 머신러닝에서 특성이 10,000개며너 10,000차원을 가진다고 부름.
- 차원 축소 알고리즘 : 원본 데이터의 특성을 적은 수의 새로운 특성으로 변환시켜 다른 알고리즘의 성능을 높이고 저장 공간을 줄일 수 있는 비지도 학습 알고리즘
- PCA(주성분 분석) : 차원 축소 알고리즘의 하나. 데이터에서 가장 분산이 큰 방향(주성분)을 찾는 방법. 원본 데이터를 주성분에 투영하여 새로운 특성을 만듦.
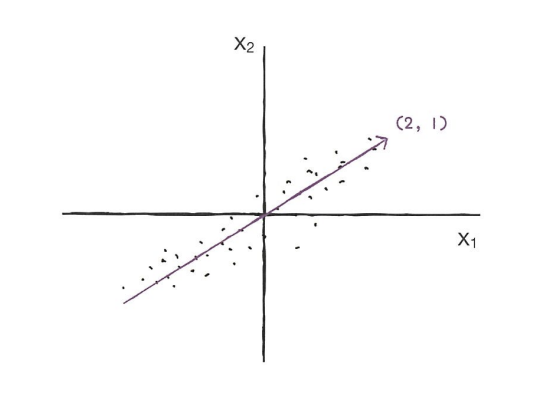 -> 화살표가 데이터의 분포를 가장 잘 표현하는 주성분
-> 화살표가 데이터의 분포를 가장 잘 표현하는 주성분
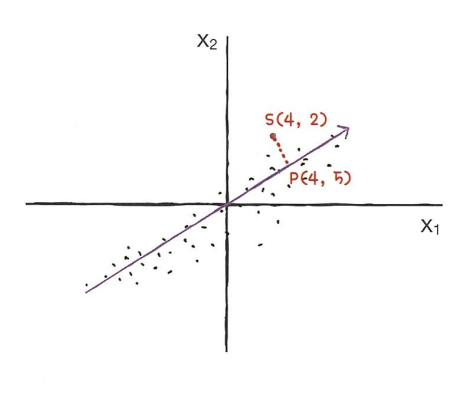 -> 샘플데이터 s(4,2)를 주성분에 직각으로 투영하여 1차원 데이터 p(4.5)를 만듦.
-> 샘플데이터 s(4,2)를 주성분에 직각으로 투영하여 1차원 데이터 p(4.5)를 만듦. - 설명된 분산 : 주성분이 원본 데이터의 분산을 얼마나 잘 나타내는지 기록한 값.

ai 개발자를 꿈꾸는 대학생