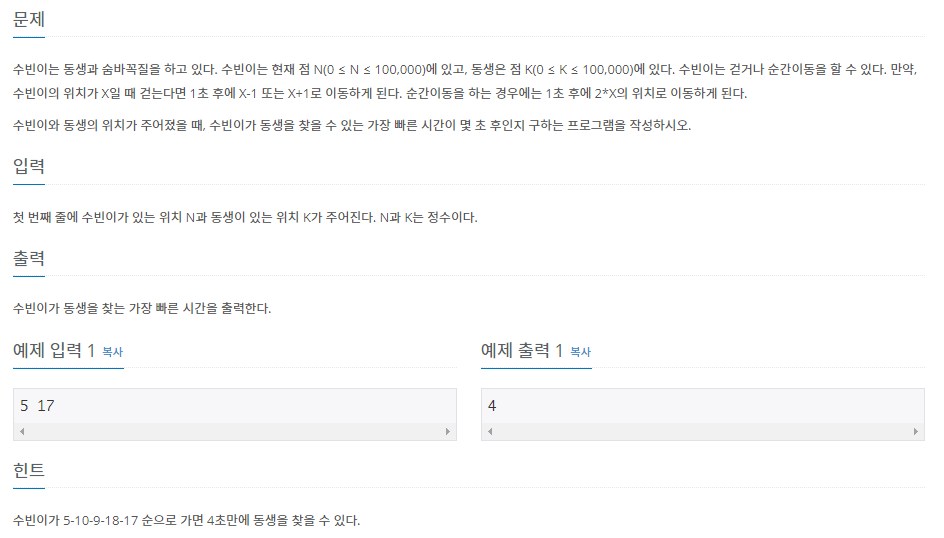
문제를 해결했던 과정
- 술래의 위치(N)에서 찾아야 하는 위치(K)까지 도달하기 위해 술래가 이동할 수 있는 범위만큼 BFS(넓이우선탐색)를 활용해야겠다고 판단했다.
- 술래의 위치(N)와 찾아야 하는 위치(K)가 같으면 움직이지 않아도 되기 때문에 조건을 걸어 0을 출력하도록 했다.
- 술래가 이동할 수 있는 범위는 -1, +1 ,*2이기 때문에 자신의 위치보다 작은 숫자에 위치해 있을 경우 뒤로 한 칸씩(-1) 이동하여 N-K가 출력되도록 했다.
- 술래의 현재 위치에서 이동할 수 있는 범위만큼 산출 후 같은 depth(깊이)에 저장했고, 현재 depth의 모든 위치를 확인 후 재귀 함수를 통해 다음 depth를 확인하도록 했다.
- 이런 방법으로 진행하면 이동할 수 있는 범위에서 찾아야 하는 위치와 같아지는 depth가 있는데, 바로 정답이 되게 된다.
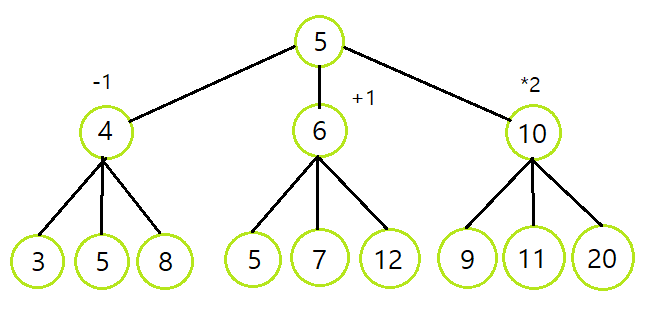
아래의 그림은 해결했던 과정을 그래프로 나타내었다.
❗해결하면서 발생한 문제점 및 해결방법 (Collection contains() method 성능 비교)
ArrayList방문처리를 ArrayList에 현재 위치를 저장하여 contains로 포함 여부를 판단하려고 하니 시간 초과가 발생했다.
결론부터 말하면 ArrayList대신 HashSet을 사용했다.
ArrayList의 contains메서드는 내부 메서드인 indexOf를 활용하여 list의 수만큼 반복적으로 탐색하여 그만큼 부하가 발생하지만, HashSet의 contains메서드는 HashMap.containsKey를 활용하여 해시 코드가 일치하는 값과 비교 후 호출한다.
Collection 인터페이스를 상속받는 ArrayList와 HashSet은 contains메서드의 성능 차이는 여기서 확인한다.
[Java] Collection Interface란?
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.Queue;
import java.util.StringTokenizer;
import java.util.HashSet;
public class Main {
static int N, K;
static int depth = 0; //술래가 찾는 시점
static Queue<Integer> que = new LinkedList<>();
static HashSet<Integer> hashSet = new HashSet<>();
static void bfs(int N, int queSize){
if(que.contains(K)){
return;
}
//현재 위치(노드)의 레벨에 있는 노드 수 만큼
for(int i=0; i<queSize; i++){
int curr = que.poll();
//현재 위치에서 이동할 수 있는 범위만큼 노드를 추가
int[] formula = new int[] {curr-1, curr+1, curr*2};
for(int j=0; j<formula.length; j++){
if(formula[j] >= 0 && formula[j] <= 100000 && !hashSet.contains(formula[j])){
que.add(formula[j]);
hashSet.add(formula[j]);
}
}
}
//이동할 수 있는 범위의 노드를 추가후 depth추가
depth++;
bfs(N, que.size());
}
public static void main(String[] args){
try{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
N = Integer.parseInt(st.nextToken());
K = Integer.parseInt(st.nextToken());
} catch (IOException e){
e.printStackTrace();
}
if(N == K){
System.out.println(0);
}else if(N > K){
System.out.println(N-K);
}else{
que.add(N);
hashSet.add(N);
bfs(N,1);
System.out.println(depth);
}
}
}
백엔드 개발자