Evaluation of GANs & GAN Disadvantages and Bias
** 본 포스팅은 cousera GANs 5,6강을 보고 작성되었습니다.
Why is evaluating GANs hard?
- 예를 들어 classifier의 경우, 답이 정해져 있으므로 모델이 무언가 결과를 내뱉었을 때 옳은지 틀린지 바로 평가할 수 있다.
- 하지만, GAN의 경우 noise를 넣어 진짜인 것 같은 가짜 이미지를 생성하게 되는데, 이 때 각 픽셀이 구체적으로 어떤 값을 가져야하는지 알 수 없다.
생성된 이미지를 평가할 때 중요한 2가지 지표
- Fidelity : quality of images
- Diversity : variety of images - 조금 질은 떨어지지만 다양한 강아지들이 다양한 자세를 하고 있는 것을 볼 수 있다.
==> Fiedlity뿐만 아니라 Diversity(데이터셋 내에서 얼마나 다양한 이미지를 생성할 수 있는지)도 고려해야할 중요한 지표

summary
- No ground-truth = challening to evaluate
- Fidelity measures image quality and diversity measures variety
- Evaluation metrics try to quantify fidelity & diversity
Comparing Images
Pixel distance

각 픽셀값의 차이의 절댓값을 이용해서 구한다. 쉽게 값을 구할 수 있지만, 1픽셀만 움직여도 크게 달라진다. 현실적으로 사용 불가!
Feature Distance
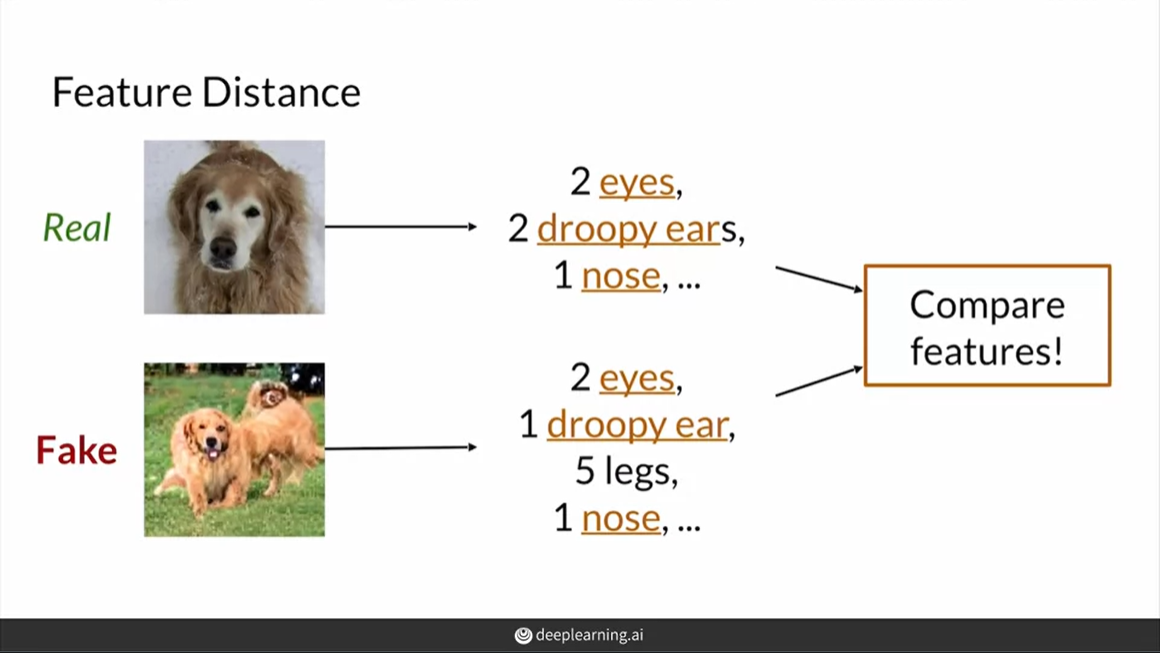
다른 방식은 더 higher level feature를 사용하는 것! 특징들을 추출해서 비교하기 때문에, 위상변화에 대해 pixel distance보다 덜 민감하다.
ex) 개는 눈 2개 귀 2개 귀여운 코!
summary
- pixel distance는 간단하지만 실현 가능하지 않다
- feature distance는 이미지에서 higher level의 특징을 사용하기 때문에, 위상변화에 덜 민감하고 더 현실적이다!
Feature Extraction
Feature distance를 구하기 위해선 feature를 나타내는 벡터가 필요! feature vector를 구하기 위해 pre-trained CNN모델을 이용한다.
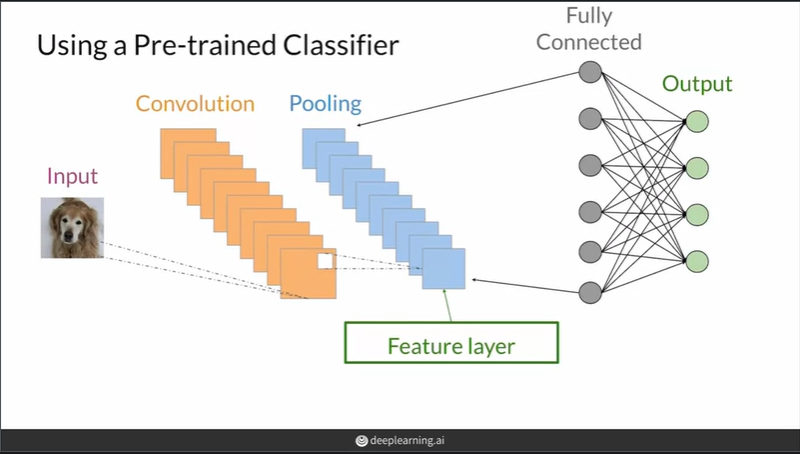
이미지 분류에서 특징을 추출하는 convolutiaonal layer와 분류를 하는 fully connected layers로 구성됨. fc layer에서 나오는 weight의 경우 dataset이나 task(분류하려는 클래스)에 따라 overfitting될 수 있으므로 중간 단계 layer의 pooling단을 feature vector로 사용한다. 즉, conv단계에서 특징을 추출한 feature layer(이미지를 농축시킨)를 구할 수 있고, 이를 사용해 이미지를 embedding할 수 있다. 대부분 CNN부분의 마지막 pooling layer를 feature layer로 사용하나 필요에 따라 앞 부분의 layer를 사용하는 경우도 있다. ImageNet dataset를 이용해 pre-trained된 CNN을 사용한다.
summary
- classifier can be used as feature extractors by cutting the network at earlier layers
- The last pooling layer is most commonly used for feature extraction
- Best to use classifiers that have been trained on large dataset-ImageNet
Inception-v3 and Embedding
여러 pretrained classifier를 쓸 수 있지만, 가장 대표적인 것은 inception-v3
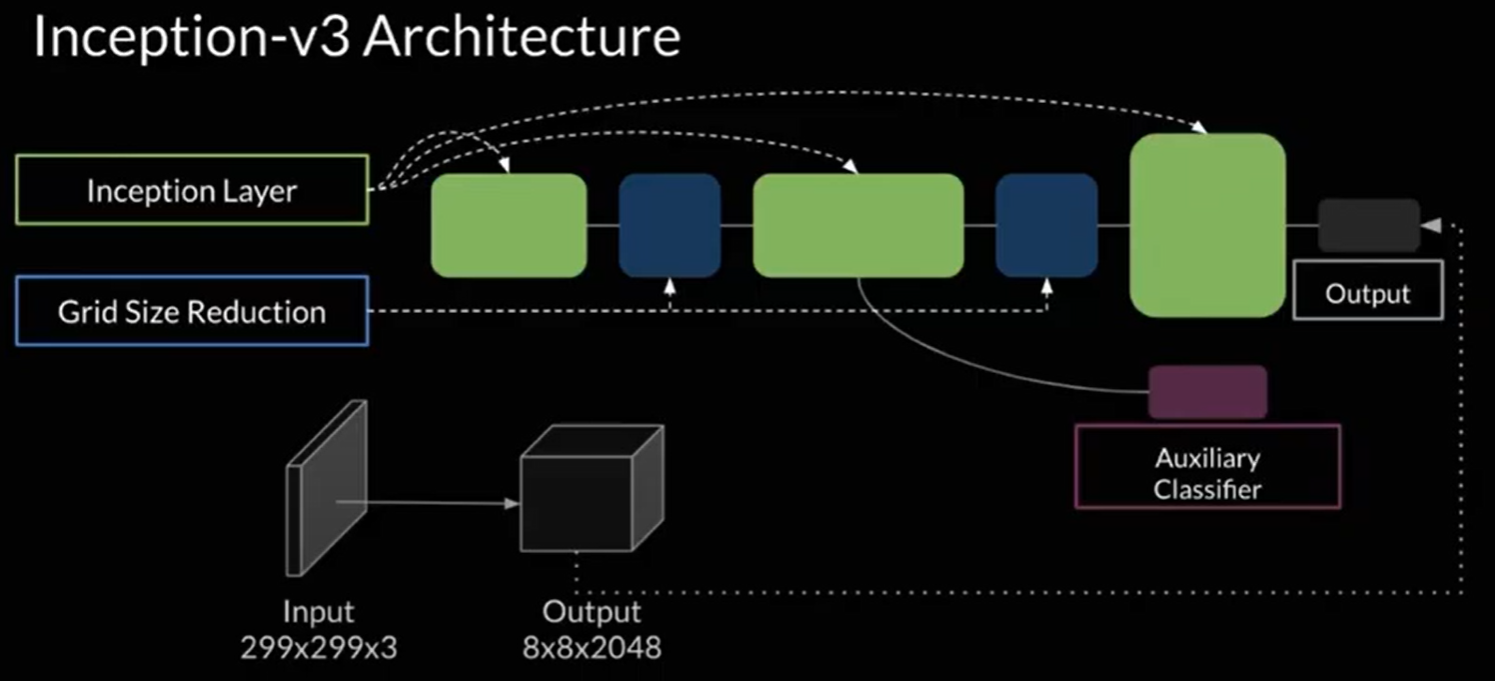
Inception은 42layer로 구성되었지만 굉장히 효율적인 연산량을 보여준다. 이 그림에서 보면, output으로 얻게 되는 에 pooling을 하게 되면, 2048차원의 feature를 산출해낼 수 있다. 즉, 이미지가 주어지면 이미지의 픽셀을 농축시켜서 salient feature를 나타내는 2048차원의 벡터로 만들게 된다!
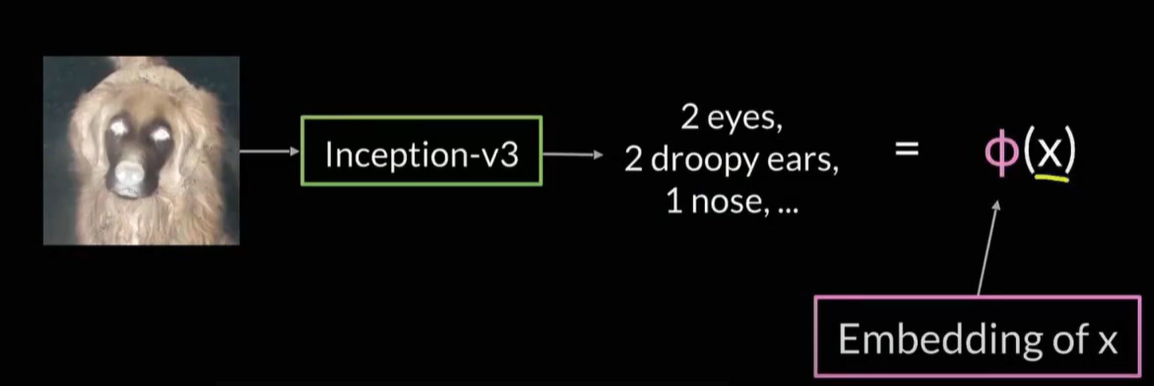
feature extration 모델을 위와 같은 함수로 표현할 수 있다. input을 넣었을 때 feature로 mapping시켜주는 함수이다. 는 fc layer가 없는 inception network를 의미한다.
: Embedding function, : input image
, : 어떠한 특징의 값
이렇게 얻어진 벡터 를 이용해서 진짜 이미지와 가짜 이미지의 feature distance를 구할 수 있다.
Summary
- Commonly used feature extractor : Inception-v3 classifier, which is pre-trained on Image Net, with the output layer cut off
- These features are called embeddings
- Compare embedding to get the feature distance
Frechet Inception Distance(FID)
진짜 이미지와 가짜 이미지 사이의 feature distance를 측정하는 가장 유명한 지표
Frechet Distance는 곡선을 따르는 점들의 위치와 순서를 고려한 곡선간의 유사성을 측정하는데 사용하는 방법. 두 분포 사이의 거리를 측정하는 데에도 사용됨!
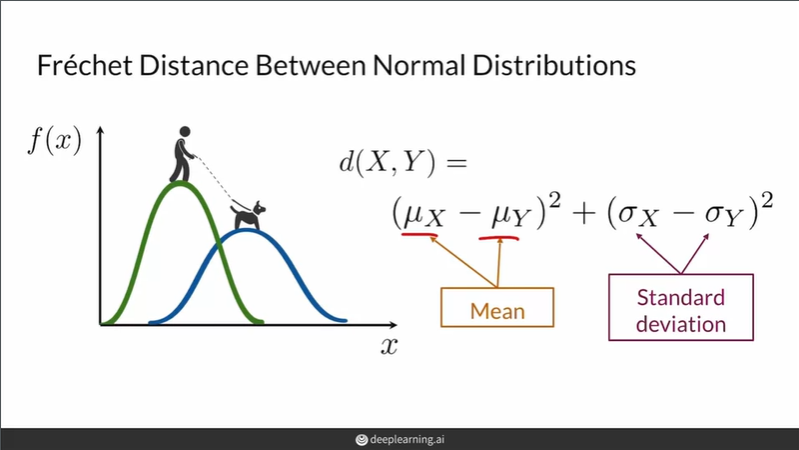
수학적으로, 프레쳇 거리는 두 "다변량" 정규분포 사이의 거리를 계산하는데 사용된다. 위의 그림은 "일변량" 정규분포의 경우, 프레쳇 거리를 계산하는 방법이 나타나 있다. 프레쳇 거리에 따르면 두 분포의 차이는 평균의 거리의 제곱과 표준편차의 거리의 제곱의 합으로 나타낼 수 있다.
GAN 평가의 맥락에서 위의 방법을 사용해 feature distance를 계산해보자. 각 이미지를 embedding하기 위한 Inception V3모델에서 activation을 사용하면 score에 Frechet Inception Distance라는 이름이 부여된다.
penultimate pooling layer(끝에서 두번째 풀링 레이어)에서 이 activation을 가져오는데, shape (2048,)의 출력 벡터가 "다변량"정규분포에 가깝다고 가정한다.
"다변량" 정규분포에 따른 프레쳇 인셉션 거리는 다음과 같이 주어진다.
여기서 와 는 두 개의 다변량정규분포로 가정된 실제와 가짜 임베딩(Inception모델에서 활성화)이다. 와 는 와 의 크기이다. 은 행렬의 대각합(trace)이고, 와 는 벡터의 공분산 행렬이다.
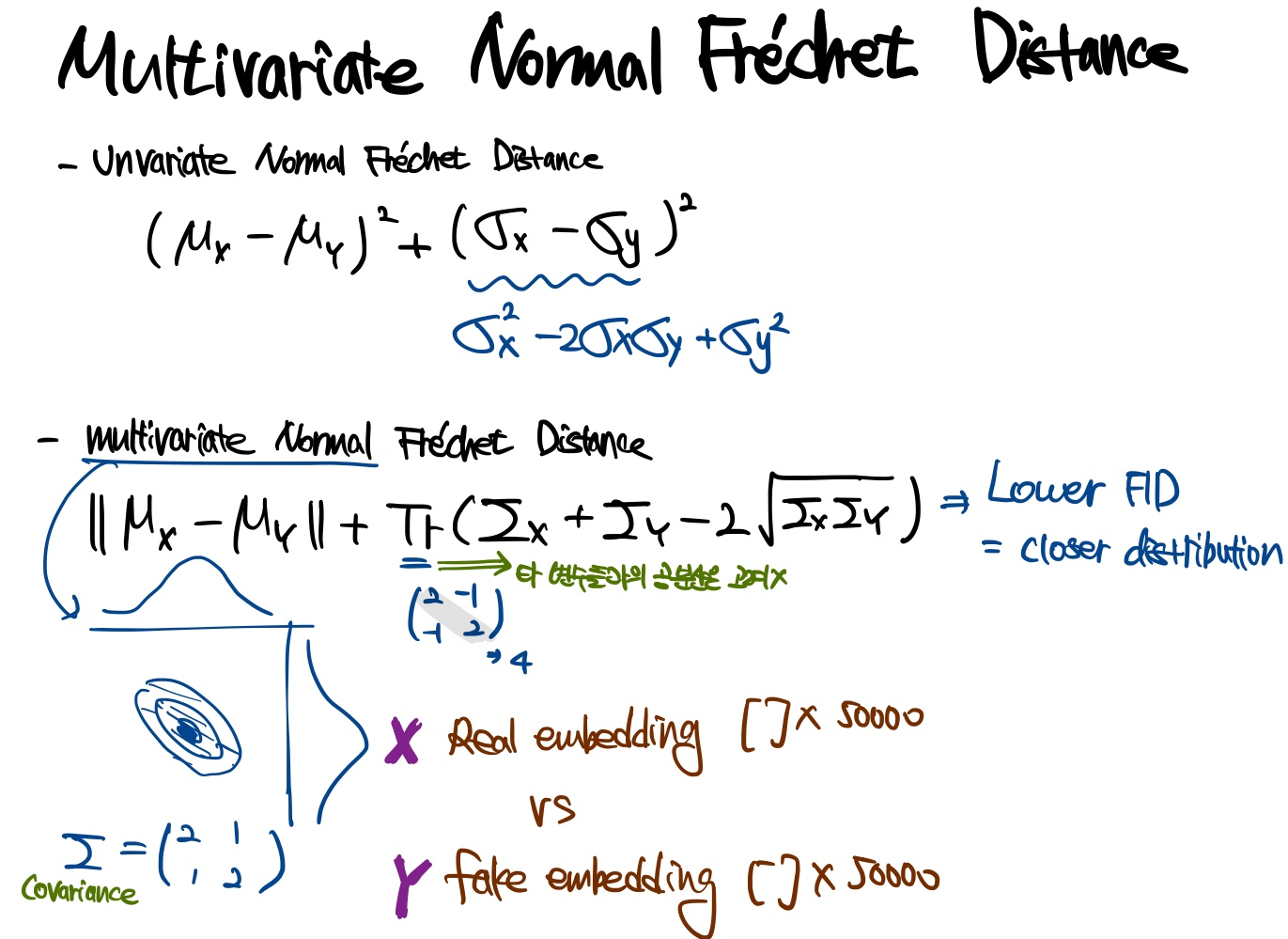
코드로 나타내면 다음과 같다(reference에서 참조).
-
사전 학습된 Inception V3모델을 사용하기 위해 다음과 같이 불러온다.

-
실제 이미지와 생성된 이미지에 대한 임베딩을 계산한다.
- GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium의 저자는 최소 샘플 사이즈 10,000을 사용하여 FID를 계산할 것을 권장하고 있다(그래서 10000개씩 모아서 한번에 FID점수를 계산하도록 코드가 짜여져 있음). 그렇지 않은 경우 생성기(generator)의 실제 FID(true FID)가 과소평가된다.

- inception_model.predict를 embedding으로 사용하는 것을 볼 수 있다.
- 실제 생성된 이미지 임베딩을 사용해 FID score를 계산한다.
def calculate_fid(real_embeddings, generated_embeddings):
# calculate mean and covariance statistics
mu1, sigma1 = real_embeddings.mean(axis=0), np.cov(real_embeddings, rowvar=False)
mu2, sigma2 = generated_embeddings.mean(axis=0), np.cov(generated_embeddings, rowvar=False)
# calculate sum squared difference between means
ssdiff = np.sum((mu1 - mu2)**2.0)
# calculate sqrt of product between cov
covmean = linalg.sqrtm(sigma1.dot(sigma2))
# check and correct imaginary numbers from sqrt
if np.iscomplexobj(covmean):
covmean = covmean.real
# calculate score
fid = ssdiff + np.trace(sigma1 + sigma2 - 2.0 * covmean)
return fid
fid = calculate_fid(real_image_embeddings, generated_image_embeddings)위의 수식 그대로 embedding의 평균과 공분산을 구해서 거리의 합을 구하는 것을 알 수 있다.
FID의 단점
- ImageNet data로 pre-trained된 경우 ImageNet data 이미지의 class와 다른 이미지를 다룰 경우 원하는 특징을 포착하지 못할 수 있다.
- pre-trained가 아닌 경우, 많은 수의 sample로 학습시키지 않으면 biased feature layer가 생겨서 좋지 못한 FID score를 얻게 된다.(권장되는 최소 샘플 사이즈는 10000)
- pre-trained가 아닌 경우, 학습을 시키기 위해 시간이 오래 걸린다.
- 표본의 분포가 정규분포가 아닐 경우 제한적인 통계량(평균,분산)만으로는 분포의 차이를 잘못 설명할 수 있다.
summary
- FID calculates the difference between reals and fakes
- FID uses the Inception model and multivariate normal Frechet distance
- Sample size need to be large for FID to work well
Inception Score(IS)
- IS : classifier => fc layer 사용
- PID : feature extractor => fc layer 사용 안함
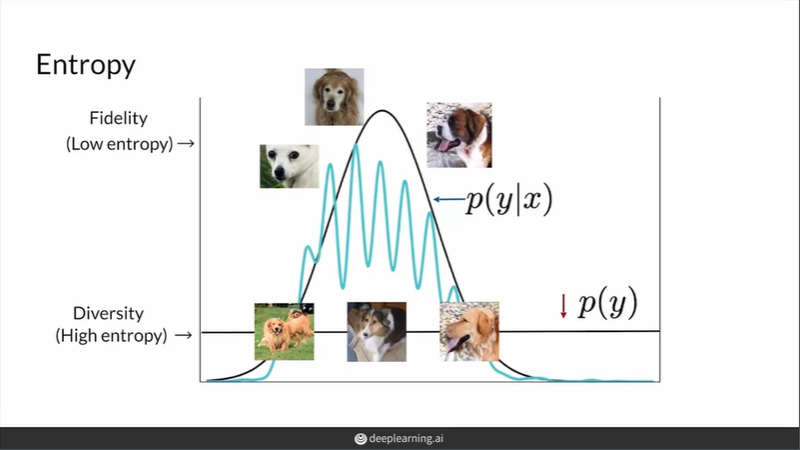
fidelity가 높다면, 몇몇 지점만 확률이 높고 나머지는 전반적으로 확률이 낮아(low entropy) 특정 클래스로 분류될 확률이 높다. diversity를 높이고 싶다면 data들이 특정 클래스로 집중되지 않아야 한다(high entropy).
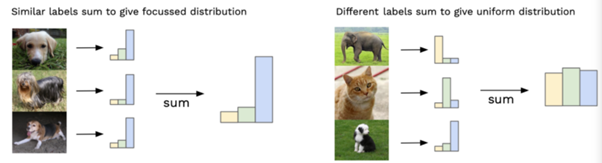
위 사진의 왼쪽은 를 나타내고 한 지점에서 peaky하므로 entropy가 낮다(Fidelity). 오른쪽은 를 나타내고 골고루 퍼진 분포를 보이므로 entropy가 높다(Diversity).
그렇다면, 이러한 fidelity와 diversity는 어떻게 식으로 나타낼 수 있을까? KL Divergence를 통해 두 가지를 하나의 식으로 표현할 수 있다.
KL Divergence는 fidelity를 나타내는 의 분포와 diversity를 나타내는 가 얼마나 다른지를 대략적으로 측정할 수 있다.

Fidelity와 Diversity를 나타내는 분포들의 차이를 KL divergence의 기대값을 이용해서 구한 후 지수 제곱을 해주면 Inception Score가 된다.
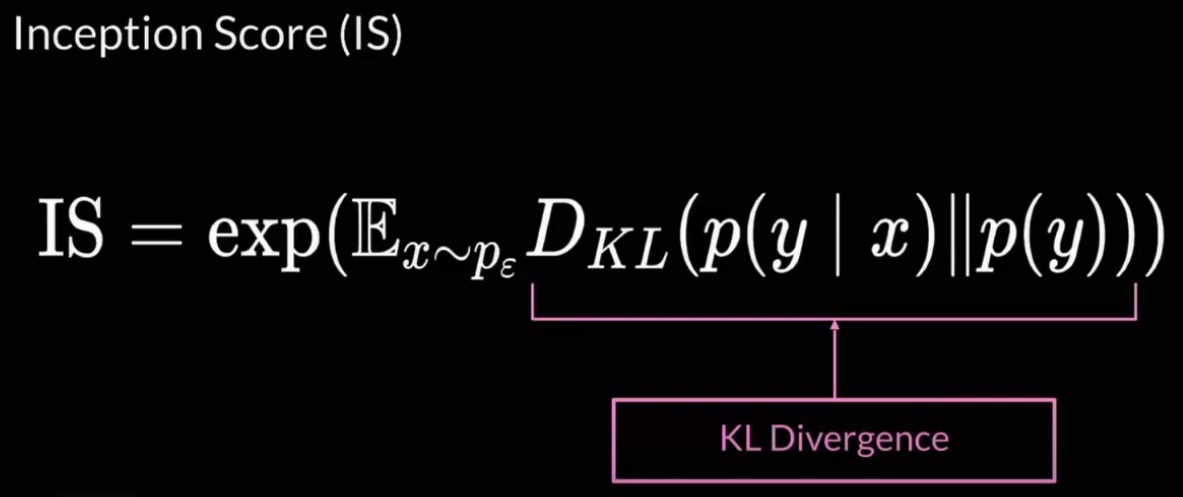
- : , generator로 생성한 샘플
이론상으로 가장 작은 값은 0, 가장 큰 값은 infinity지만, 실제로 사용할 땐 가능한 가장 작은 값은 1, 가장 큰 값은 존재하는 클래스의 수이다(Imagenet에선 1000).
IS는 높을수록 좋다. 우리가 생각하는 우수한 생성모델은, 다양한 클래스의 이미지를 생성하면서도 고화질의 이미지를 생성하는 것이다. 즉, fidelity가 높기 때문에, classifier가 잘 분류해낼 것 == 가 한 곳에서 높은 값을 갖는 분포가 되고, diversity가 높기 때문에 다양한 클래스의 이미지를 생성해낼 것 == 가 uniform distribution가 비슷한 형태의 분포를 갖게 된다. 두 분포의 차이가 크므로 KL divergence가 크고, KL divergence가 커지면 IS도 커지므로, IS가 큰 값을 가지면 fidelity와 diversity가 우수한 생성모델이라고 할 수 있다.
반면에 IS가 낮다면, 두 분포 모두 entropy가 높아서 다양성이 낮거나 두 분포 모두 entropy가 낮아서 선명한 이미지가 만들어지지 않는 두 가지 경우 중 하나이다.
IS의 단점
- 생성자가 label마다 하나의 이미지만 반복해서 생성하는 경우 IS가 높지만 이는 inner diversity를 고려하지 못한 좋지 못한 생성모델(8에 관한 사진이 100장이 있는데 1장이랑만 똑같은 이미지를 반복해서 생성)
- fake image만을 이용한다. -> real image와 비교하지 못한다.
- FID와 마찬가지로 ImageNet date로 pre-trained된 경우 ImageNet data 이미지의 class와 다른 이미지를 다룰 경우 원하는 특징을 포착하지 못할 수 있다.
Summary
- Inception Score tries to capture fiedlity & diversity
- Inception Score has many shortcomings
- Can be gamed too easily
- Only looks at fake images, not reals
- ImageNet doesn't teach a model all features
- Worse than Frechet Inception Distance
Sampling and Trucation
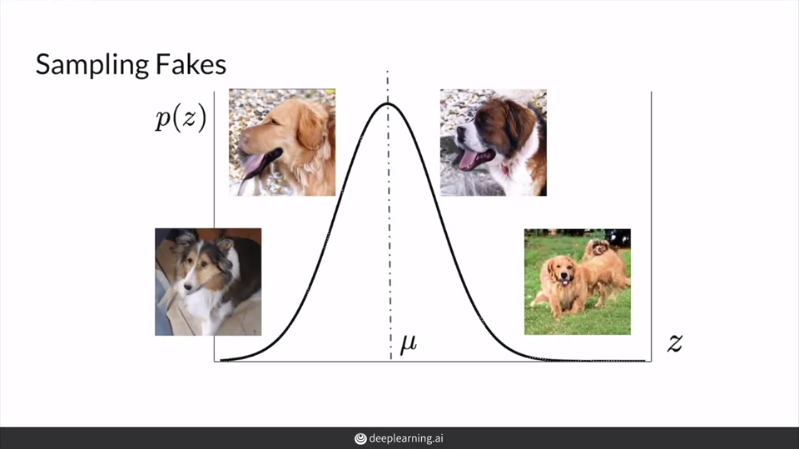
GAN을 평가할 때 latent vector z의 사전 분포에 맞게 sampling한다. 근처에서 sampling된 z들은 이용해 fidelity에 집중해 평가할 수 있고, 반대로 와 먼 곳까지 포함해서 samping된 z들을 이용해 diversity에 집중해서 평가할 수 있다. 다시 말하면, FID나 inception score와 같은 평가는 sample에 매우 큰 영향을 받으므로 sample이 중요하다.
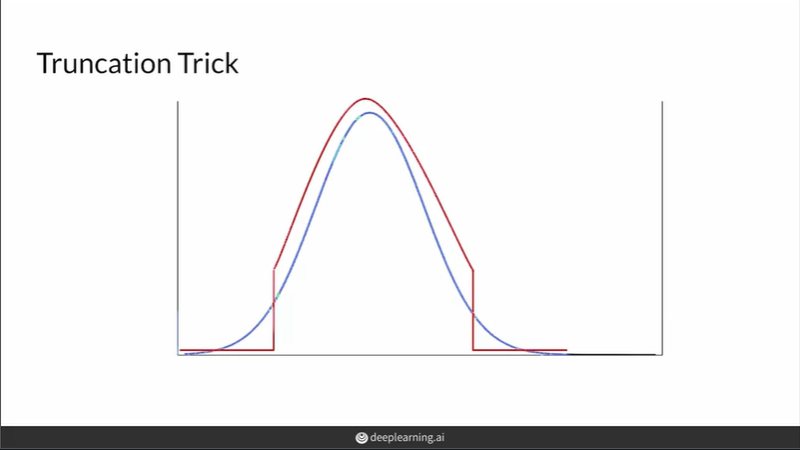
truncation trick을 이용해서 z분포의 양 극단을 잘라낸 곳에서 sampling을 한 후 평가를 할 수 있다. 파란색이 기존 normal distribution(sampe noise vector from during training)이고 빨간색이 양 극단을 잘라낸 모양인데, 양 극단의 확률은 0이므로 양 끝에선 샘플링을 하지 않는다.
우수한 fidelity를 원하는 경우 양 끝 부분을 많이 잘라내서 sampling하면 되고, 우수한 diversity를 원하는 경우 양 끝분을 적게 잘라내서 sampling하면 된다. 이처럼 잘라내는 지점은 hyperparameter로 사람이 경험에 의해 직접 지정한다.
HYPE(Human eYe Perceptual Evaluation)

- 지각 심리학의 심리 물리학 방법에서 영감을 받은 근거가 있는 방법을 통해 생성 모델 출력의 지각 현실성을 측정
- 신뢰할 수 있고, 일관된 측정기
- 크라우드소싱 기술을 통해 비용과 시간 효율적인 방법을 보장
- Fidelity(realism)에 대해 평가할 수 있지만, 다른 지표들(diversity, overfitting, train stability)는 평가하지 못함
HYPE(time)
- 사람이 진짜로부터 가짜를 구별하는데 필요한 시간 제한적인 인지 임계값을 결정하기 위해 시간 제약을 조정하며 이미지들을 보여줌
- HYPE(time) score는 사람이 모델의 결과를 진짜인지 가짜인지 구분하는데 걸리는 최소의 시간
HYPE(time)의 방법
- 150개의 이미지(5:5 real/fake)들을 노출시간을 500ms로 시작해서 가짜 진짜를 판별시킴. 맞추면 노출시간을 30ms줄이고, 틀리면 10ms 눌림
- 각 평가자의 마지막 값을 계산해 평균을 구해 점수로 산출
- 높은 점수 == 진짜와 가짜를 구분하는데 더 긴 시간이 필요. 즉 좋은 생성 모델!
HYPE(inf)
- time 버전의 신뢰도를 유지하면서 첫번째 방법을 더 간단하고 빠르고 저렴하게 이용
- 시간 제한 없이, 사람들이 가짜와 진짜를 착각하는 비율로 해석
- 점수가 50%보다 높으면 생성된 결과가 진짜보다 더욱 현실적이라는걸 보여줌
HYPE(inf)의 방법
- 100개 이미지를 (5:5 real/fake) 각 평가자에게 보여주고 잘못 평가한 이미지들의 비율을 계산해 n명의 평가를 종합
- 높은 점수가 나올수록 좋은 생성모델
Summary
- fakes are sampled using the training or prior distribution of z
- Truncate more for higher fidelity, lower diversity
- Human evaluation is still necessary for sampling
Precision and Recall
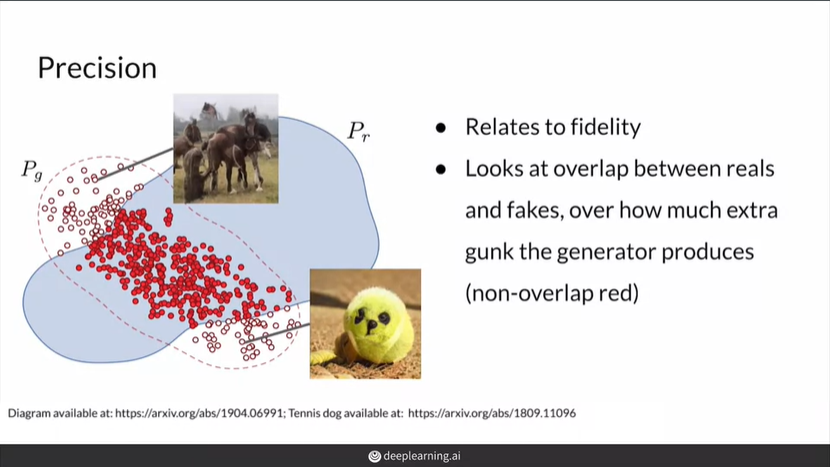
precision = 생성된 이미지 중 실제 이미지 분포에 들어가는 이미지들 / 생성된 이미지들
(원래는 모델이 True라고 분류한 것 중 실제 True인 것의 비율)
precision은 fidelity와 연관 - precision이 높으면 생성한 이미지들이 모두 진짜인것 같은 이미지이므로 fidelity와 연관되지만, 이것이 generator가 모든 실제 이미지 분포를 커버한다는 것은 아님

recall = 실제 이미지 중 생성된 이미지 분포에 들어가는 이미지들 / 실제 이미지들
(원래는 실제 True인 것 중 모델이 True라고 분류한 것의 비율)
recall은 diversity와 연관 - 생성 모델이 가능한 모든 실제 이미지를 생성할 수 있는가
모델이 커지면 의 범위가 커지니까 recall 점수는 높아짐. 그래서 대부분의 경우 recall이 precision보다 높다 . 따라서 truncation trick을 이용해 precision을 높인다.
Summary
- Precision is to fidelity as to recall is to diversity
- Models tend to be better at recall
- Use truncation trick to imporve precision
Disadvantages of GANs
Advantages of GANs
- 놀라운 실험적 결과 - 특히 fidelity 측면에서!

- 이미지 생성 시간이 빠름
Disadvantages of GANs
- 본질적인 평가 지표의 부족 ex) 정말 진짜 이미지 같은가?
- 학습의 불안정성(ex. mode collapes)
- 명시적인 확률 밀도를 알 수 없음 ex) 강아지 사진을 생성한다고 할 때, 골든 리트리버가 얼마나 나오는지
- latent vector로 역변환이 어려움
Alternatives to GANs
Variational Autoencoder(VAE)
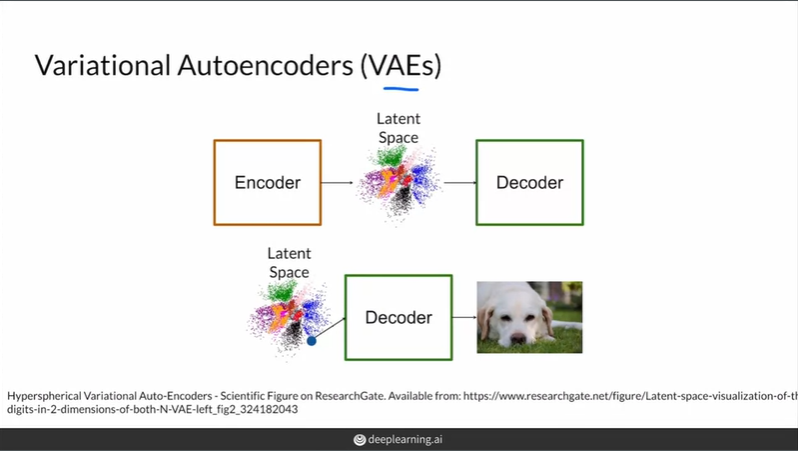
진짜 사진 -> Encoder -> latent Space -> decoder 의 구성
장점
- 확률 밀도를 알 수 있다
- 역변환이 가능하다
- 학습의 안정성
단점
- blurry한 생성 결과(fidelity가 낮음)
Autoregressive Model

RNN처럼 이전 픽셀을 바탕으로 다음 픽셀을 생성, GAN이나 VAE와 달리 latent vector가 존재하지 않음
pixelRNN, pixelCNN, GatedpixelCNN 등..
Flow based generative model
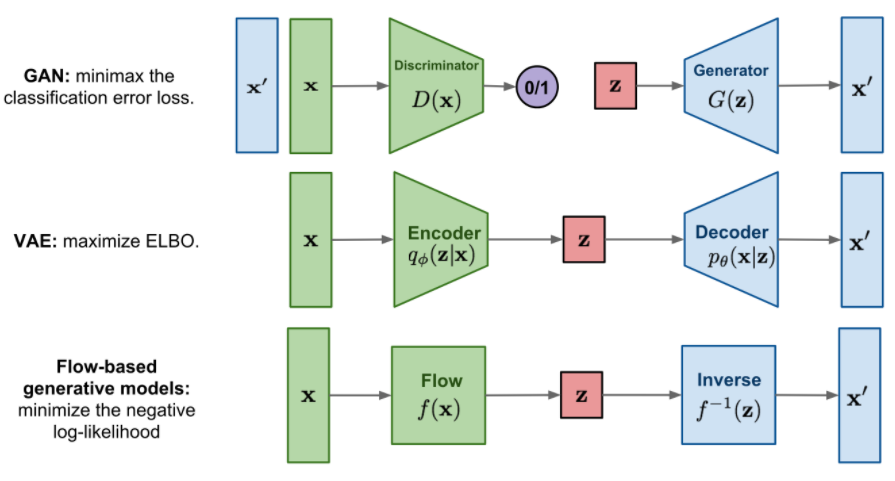
다른 모델과 다르게 latent vector z가 input vector x와 같은 차원을 가짐. 같은 차원을 가지므로 정보의 손실이 적다.
z의 분포를 표준정규분포로 시작해 변수변환과 야코비안을 이용해 x의 분포처럼 복잡한 분포로 만든다. 이 때, 변환에 사용되는 함수는 역함수가 존재해야하고, 야코비안 행렬식 계산이 간단하게 이루어져야 한다.
즉, 를 학습하되, 를 통해 다시 x를 계산하는 것을 목표로 함. 이러한 과정을 통해 구한 함수 f를 이용해 생성 결과물을 얻는다.
Intro to Machine Bias
COMPAS Algorithm
: 미래에 범죄를 저지를 확률에 따라 점수를 주는 알고리즘. ProPublica는 기사에서 해당 알고리즘에 인종차별적 요소가 들어가 있다고 문제 제기

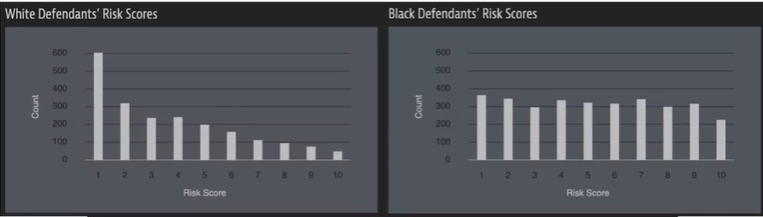
왼쪽의 백인 남성은 Home Depot에서 $86가치의 물건을 절도했고, 무장 절도 및 수감 경험이 있다. 오른쪽의 여성은 $80가치의 자전거와 스쿠터 절도를 시도했고, 현장에서 물건을 두고 도주했다. 다른 전과 기록은 없다. 하지만 흑인 여성의 COMPAS점수가 더 높았다.
이 알고리즘의 사전 질문에 인종에 관한 질문은 없지만, 인종차별적인 결과를 유발하고 있다. 알고리즘의 계산과정은 공개되지 않아 알고리즘 설계에서 인종차별적 결과를 의도했는지 확인하기 어렵다.
알고리즘의 점수는 판사의 판단에 영향을 미쳐 수감 기간에 영향을 준다.

흑인은 백인에 비해 2배정도 더 위험한 사람으로 분류되었지만, 실제로는 다시 범죄를 저지르지 않았다.
즉, 이러한 Machine bias는 역사적으로 소외된 인구에 대해 불균형적으로 부정적인 영향을 끼친다 .
Defining Fairness
fair한지 평가할 수 있는 여러가지 기준들
ex) Ground-truth에 상관없이 분류 결과의 비율이 같으면 된다 / 그룹에 상관없이 실제 자격이 있는 사람은 선호되는 결과인 Admitted로 분류될 확률이 같아야 한다 / 그룹에 상관없이 자격이 있는 학생은 Admitted로, 자격이 없는 학생은 rejected로 분류될 확률이 같아야 한다 / 그룹 조건이 포함되지 않았을 때 분류 결과 비율이 같으면 된다 등..
결론
- Fairness is difficult to define
- There is no single definition of fairness
- Important to explore these before releasing a system into production
Ways Bias is Introduced
Training Bias

- 데이터를 수집하는 경우에서 variation이 없는 데이터를 수집하는 경우(사람 얼굴 사진을 수집하는데 백인만, 흑인만 등..)
- 데이터가 한 장소 또는 한 웹사이트에서 수집되는 경우 (특정 지역의 demographic정보만 반영될 수 있다)
- 데이터를 라벨링할 때 라벨링하는 다양한 사람이 필요하다. 소수의 라벨러는 데이터에 편향을 줄 수 있다.
Evaluation Bias
모델이 평가될 때 주요 문화 특성에서의 correctness가 반영되어 편향이 생길 수 있다
- 운전시 운전자 방향 위치

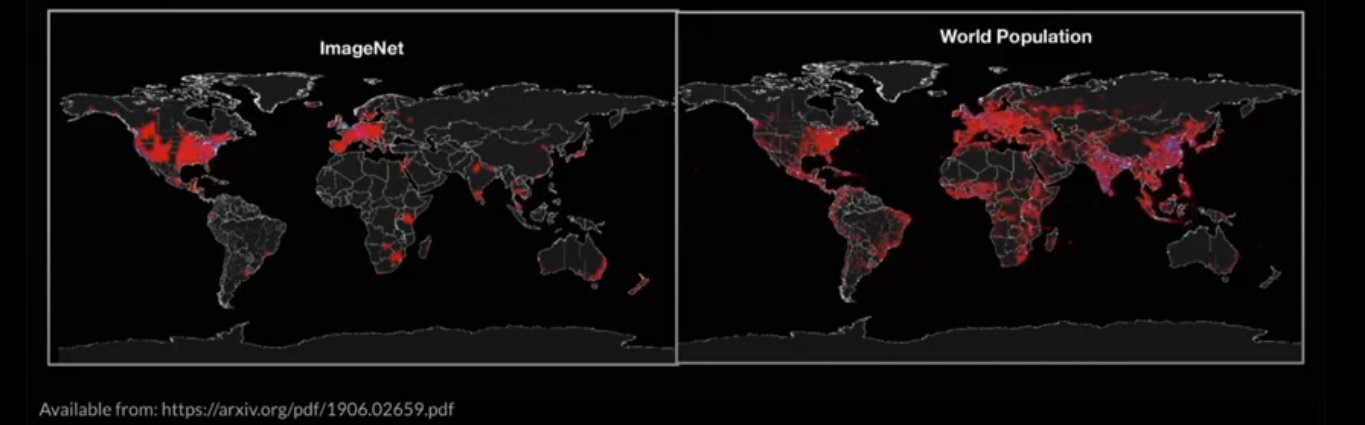
- ImageNet분포와 world population분포 차이
: 생성 모델을 평가할 때 FID가 사용되는데, FID의 Inception-v3은 ImageNet dataset을 이용해 사전학습되므로 ImageNet dataset의 편향에 영향을 받아 편향된 결과를 얻게 될 수 있다.
Model Architecture Bias
구조를 설계하거나 코드를 최적화하는 프로그래머에 의해 영향을 받을 수 있다.
==> Bias는 어느 단계에서든 발생할 수 있다.
PULSE

원본 사진을 픽셀화하고, 다시 upsampling했을 때의 결과이다. 3명 다 유색 인종이지만 upsampling한 결과를 보면 백인의 특성을 많이 갖는 이미지들이 생성되었다. 즉, 해당 모델이 bias가 존재함을 알 수 있다.
머신러닝 알고리즘을 개발할 때 데이터 수집으로부터 평가 및 활용 등 전 과정에서 bias가 생길 수 있다. bias는 ML community에서 논쟁거리이며 이를 극복하기 위한 연구도 진행되고 있다.
**reference
https://www.youtube.com/watch?v=sZkHO4rPqJg&list=PLsLwz2eoSYLWW09NAhDIq-i8ObCGElMRk&index=6
https://velog.io/@tobigs-gm1/evaluationandbias
https://wandb.ai/wandb_fc/korean/reports/-Frechet-Inception-distance-FID-GANs---Vmlldzo0MzQ3Mzc
https://devkihyun.github.io/study/Flow-based-Generative-Models-1-Normalizing-Flow/
