
 작성자 : 서울시립대 수학과 김상현
작성자 : 서울시립대 수학과 김상현
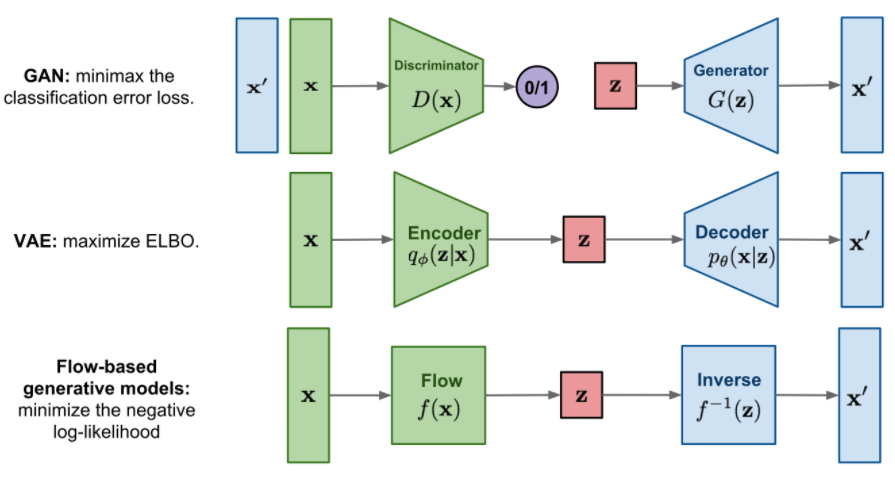
Evaluation of GANs
Evaluation
GAN model을 평가하기 어렵다.
why? Universal gold-standard discriminator가 존재하지 않는다.
생성된 이미지 평가의 중요한 두 가지 지표
1. Fidelity : quality of images
2. Diversity : variety of images
Comparing Images
-
Pixel distance

각 픽셀값의 차이를 절대값을 이용해서 구한다. 쉽게 값을 구할 수 있다는 장점이 있지만 위상변화에 매우 취약하다는 단점이 존재하므로 사용하지 않는다. -
Feature distance
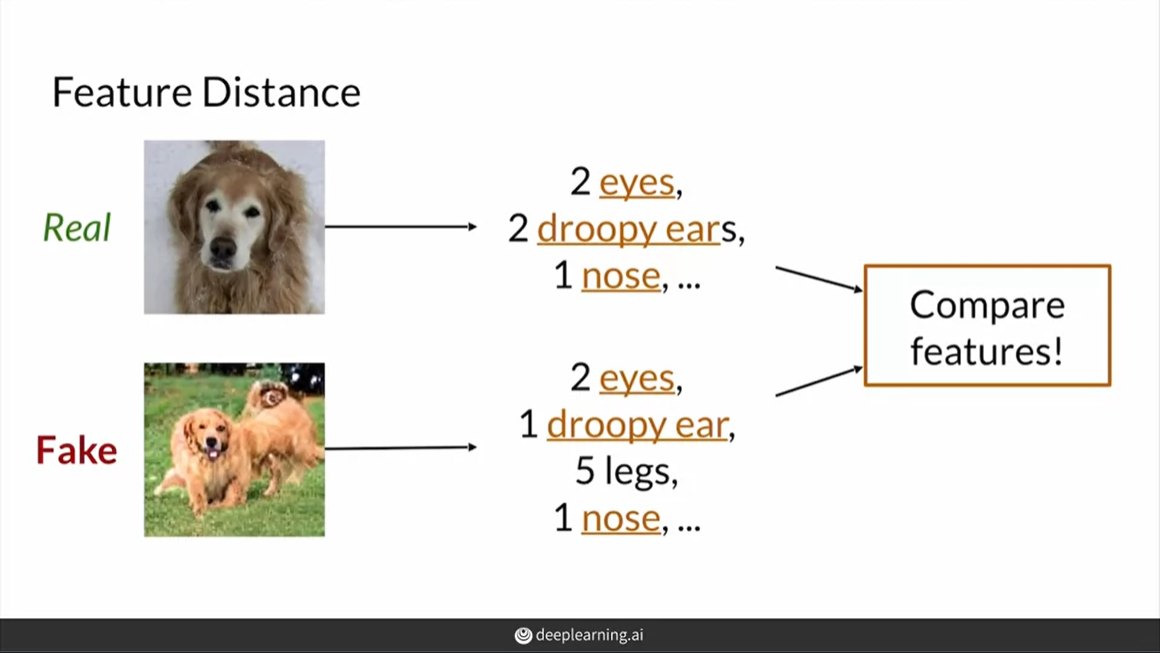
이미지들을 픽셀 단위로 비교하는 것이 아니라 특징들을 추출해서 비교한다. 따라서 pixel distance보다 위상변화에 대해 믿을만한 값을 얻을 수 있다.
Feature Extraction
위의 Feature distance를 구하기 위해서는 특징을 나타내는 벡터(연산을 위해)가 필요하다. 특징벡터를 구하기 위해 pre-trained CNN 모델을 이용한다
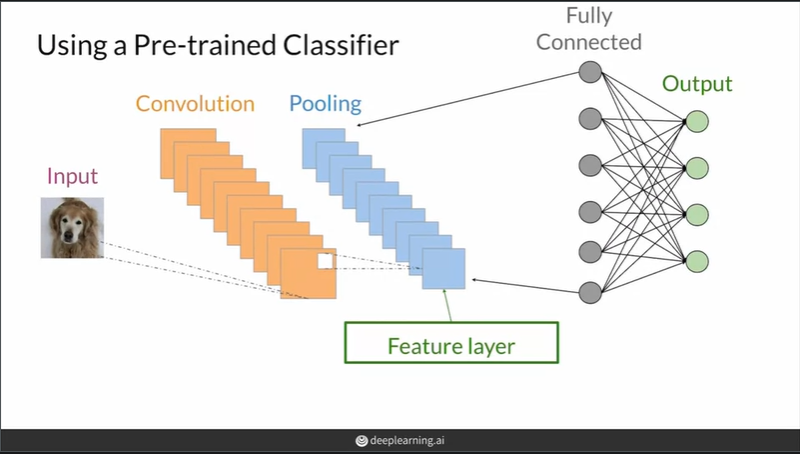
이미지 분류에서 CNN은 특징을 추출하는 convolutional layers와 분류를 하는 fully connected layers로 구성된다. 따라서 convolutional layers에 이미지의 특징을 표현하는 feature layer가 존재하고 이를 이용해서 이미지를 embedding할 수 있다.
대부분의 경우 fc층 전의 마지막 pooling layer를 feature layer로 사용하나 필요(primitive information)에 따라 앞 부분의 layer를 사용하는 경우도 있다.
ImageNet dataset을 이용해 pre-trained된 CNN을 사용한다.
Inception-v3 and Embeddings
Feature extraction을 수식으로 표현하면
: Embedding function, : input image
, : 어떠한 특징의 값
Embedding function을 ImageNet으로 학습된 Inception-v3모델의 convolutional layers를 이용한 함수로 정의한다.
이렇게 얻어진 벡터를 이용해서 Euclidean/Cosine distance등을 이용해서 feature distance를 구할 수 있다.
Inception-v3참고: https://static.googleusercontent.com/media/research.google.com/ko//pubs/archive/44903.pdf
Fréchet Inception Distance(FID)
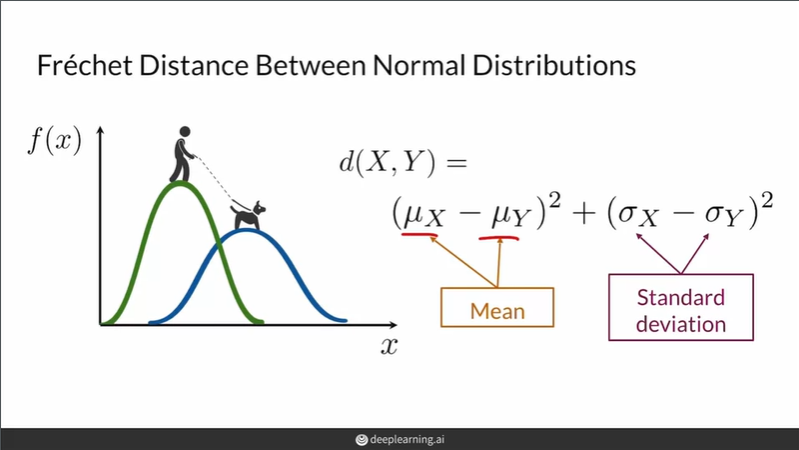
두 일변량 정규분포의 FID는 위와 같이 정의된다.

두 다변량 정규분포의 FID는 위와 같이 정의된다. (일변량의 확장버전)
FID의 기본 가정: embedding vector가 다변량 정규분포를 따른다.
정확하게 따른다기 보다는 계산의 편의를 위해서 가정한다.
낮은 FID -> 두 분포의 거리가 가깝다 -> 진짜와 가짜가 유사하다
FID의 단점
1. ImageNet data로 pre-trained된 경우 ImageNet data 이미지의 class와 다른 이미지를 다룰 경우 원하는 특징을 포착하지 못할 수 있다
2. pre-trained가 아닌 경우, 많은 수의 sample로 학습시키지 않으면 biased feature layer가 생겨서 좋지 못한 FID score를 얻게 된다
3. pre-trained가 아닌 경우, 학습을 시키기 위해 시간이 오래 걸린다
4. 표본의 분포가 정규분포가 아닐 경우 제한적인 통계량(평균,분산)만으로는 분포의 차이를 잘못 설명할 수 있다.
Inception Score(IS)
FID 이전 많이 사용되던 evaluation metric
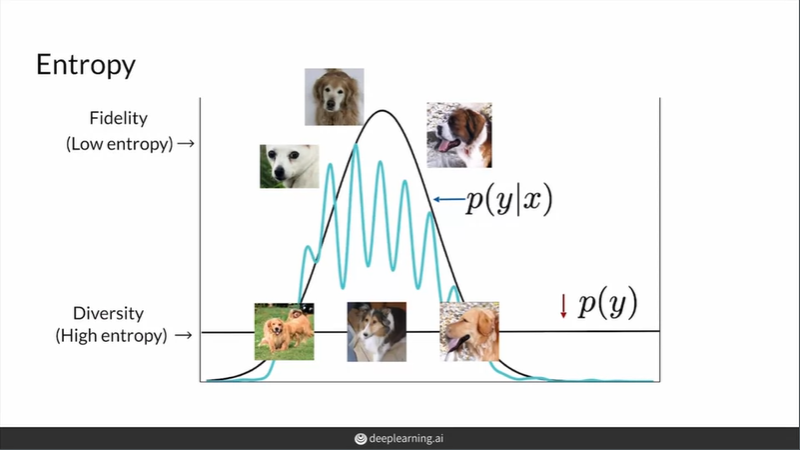
Entropy?
정보이론의 대표적인 개념으로 무작위성으로 볼 수 있다
랜덤 변수 X의 값이 예측가능하면 엔트로피가 낮음
예측하기 어렵다면 엔트로피는 높음
Inception Score 이해하기
수식을 보기 전 Inception-v3 model이 어떻게 사용되는지 확인하자
IS: classifier => fc층 사용
FID: feature extractor => fc층 사용 안함
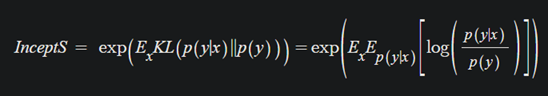
IS는 KL divergence의 expectation의 지수제곱(exp의 역할은 사람이 값을 이해하기 쉽게한다)
KL divergence 내의 두 분포
p(y|x): 주어진 input x에 대해 label y의 확률분포
p(y): label들의 확률분포
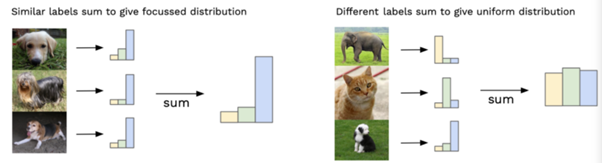
위 이미지의 왼쪽은 p(y|x)를 나타내고 한 곳에서 peak한 분포를 보이므로 entropy가 낮다 => Fidelity
위 이미지의 오른쪽은 p(y)를 나타내고 골고루 퍼진 분포(uniform)를 보이므로 entropy가 높다 => Diversity
Fidelity와 Diversity를 나타내는 분포들의 차이를 KL divergence의 기대값을 이용해서 구한 후 지수 제곱을 해주면 Inception Score가 된다.
예시)
fidelity와 diversity 모두 우수한 생성모델을 가정하자
해당 모델에서 생성한 이미지들은 fidelity가 높기 때문에 classifier가 잘 분류해낼 것이다. 따라서 p(y|x)가 한 곳에서 높은 값을 갖는 분포를 갖게 된다.
또한 diversity가 높기 때문에 다양한 label의 이미지를 생성할 것이다. 따라서 p(y)가 uniform distribution과 비슷한 형태의 분포를 갖게 된다.
두 분포의 차이가 크므로 KL divergence가 크다. KL divergence가 커지면 IS가 커진다. 따라서 IS가 큰 값을 갖으면 fidelity와 diversity가 우수한 생성모델이라 할 수 있다.
IS의 단점
1. 생성자가 각 label마다 하나의 이미지만 반복해서 생성하는 경우 IS가 높지만 이는 inner diversity를 고려하지 못한 좋지 못한 생성모델
2. fake image만을 이용한다 -> real image와 비교하지 못 한다.
3. FID와 마찬가지로 ImageNet data로 pre-trained된 경우 ImageNet data 이미지의 class와 다른 이미지를 다룰 경우 원하는 특징을 포착하지 못할 수 있다
Sampling and Truncation
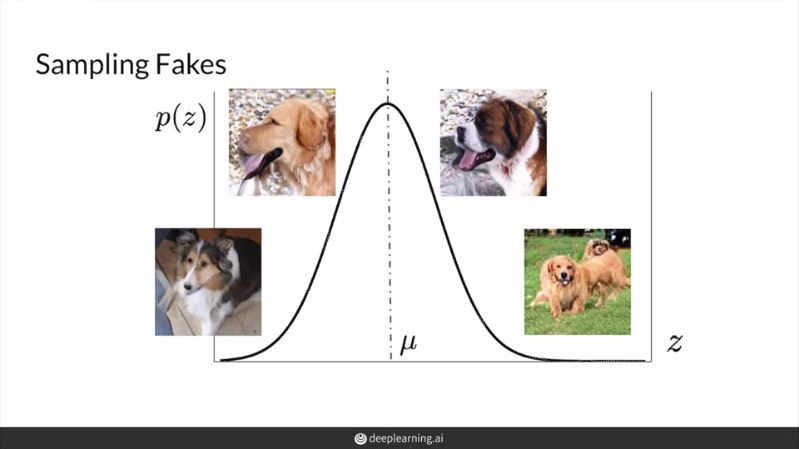
GAN을 평가할때 letent vector z의 사전 분포에 맞게 sampling 한다.
근처에서 sampling된 z들을 이용해서 fidelity에 집중해서 평가할 수 있다.
반대로 와 먼 곳까지 포함에서 sampling된 z들을 이용해서 diversity에 집중해서 평가할 수 있다.
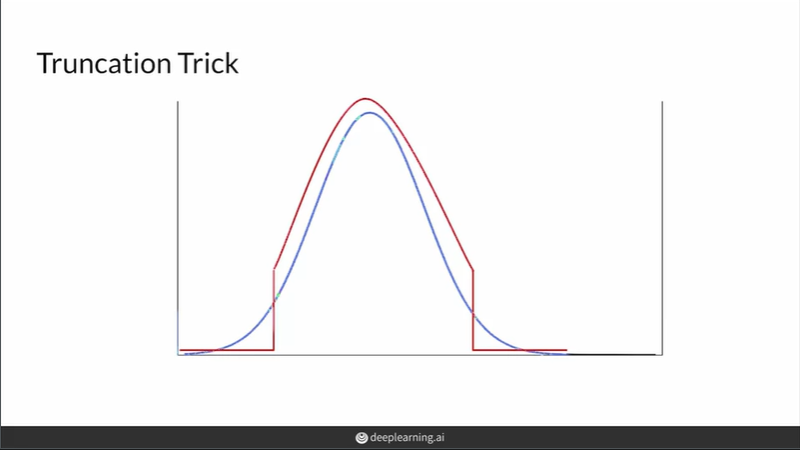
truncation trick을 이용해서 z 분포의 양 끝부분을 잘라낸 곳에서 sampling을 한 후 평가를 진행할 수 있다. 잘라내는 지점은 hyperparameter로 사람이 경험에 의해 직접 지정한다.
우수한 fidelity를 원하는 경우 양 끝부분을 많이 잘라내서 sampling을 하면 되고, 우수한 diversity를 원하는 경우 양 끝부분을 적게 잘라내서 sampling하면 된다.
fidelity와 diversity의 trade-off 관계에 맞게 잘라내는 지점을 지정하면 된다.
HYPE(Human eYe Perceptual Evaluation)

- 지각 심리학의 심리 물리학 방법에서 영감을 받은 근거가 있는 방법을 통해 생성 모델 출력의 지각 현실성을 측정
- 신뢰할 수 있고, 일관된 측정기
- 크라우드소싱 기술을 통해 비용과 시간 효율적인 방법을 보장
- Fidelity(realism)에 대해 평가할 수 있지만 다른 지표들(diversity, overfitting, train stability)은 평가하지 못 한다.
HYPE(time)
- 사람이 진짜로부터 가짜를 구별하는데 필요한 시간 제한적인 인지 임계값을 결정하기 위해 시간 제약을 조정하며 이미지들을 보여준다.
- HYPE(time) score는 최소의 시간으로 여겨진다. 여기서의 시간은 사람이 모델의 결과를 진짜인지 가짜인지 구분하는데 필요한 시간
HYPE(time)의 방법
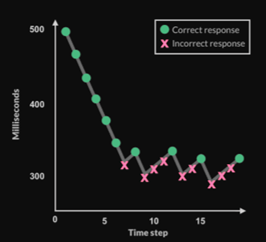
- 150개 이미지(5:5 real/fake)들을 노출시간을 500ms으로 시작해서 가짜 진짜를 판별시킨다. 맞추면 노출시간을 30ms 줄이고 틀리면 10ms 늘린다
- 각각의 평가자의 마지막 값을 계산해서 평균을 구하면 점수가 된다
- 높은 점수는 진짜와 가짜를 구분하는데 더 긴 시간이 필요하다는 것을 의미한다. 즉, 좋은 생성 모델
HYEP(inf)
- time 버전의 신뢰도를 유지하면서 첫번째 방법을 더욱 간단하고 빠르고 비용 저렴하게 이용한다.
- 무한한 시간(시간 제약이 없음)이 주어질 때, 사람들이 가짜와 진짜를 착각하는 비율로 해석
- 점수가 50%인 경우 사람들은 생성된 결과를 진짜와 가짜를 우연의 확률로 구별한다. 50% 이상인 경우 생성된 결과가 진짜보다 더욱 현실적이라는걸 나타낸다.
HYEP(inf)의 방법
- 100개의 이미지들을 (5:5 real/fake) 각각의 평가자에게 보여주고 잘못 평가한 이미지들의 비율을 계산하여 총 n명의 평가를 종합한다
- 높은 점수가 나올수록 좋은 생성모델
Precision and Recall
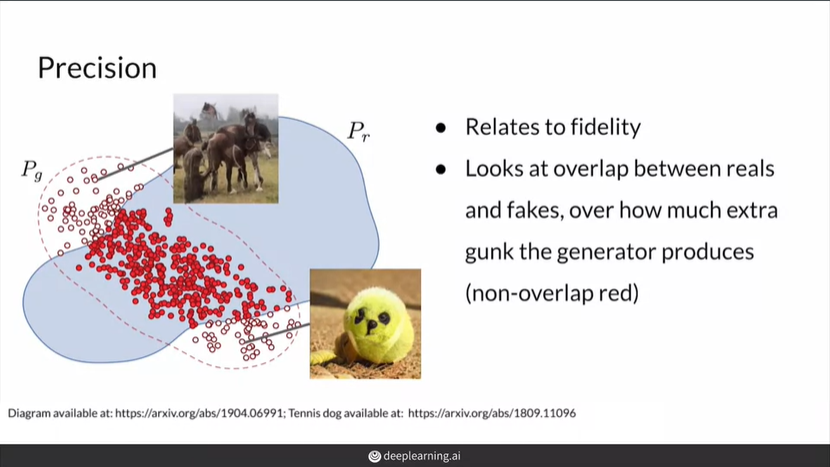
precision = 생성된 이미지 중 실제 이미지 분포에 들어가는 이미지들/생성된 이미지들
precision은 fidelity와 연관

recall = 실제 이미지 중 생성된 이미지 분포에 들어가는 이미지들/실제 이미지들
recall은 diversity와 연관
대부분의 경우 recall이 precision보다 높음. 따라서 truncation trick을 이용해서 precision을 높이다.
'Improved Precision and Recll Metric for Assessing Generative Models'논문에서 발전된 precision and recall을 정의했다

식(1): 함수 f에서 특정 벡터 가 해당 분포의 특정 cluster에 들어가는지 여부를 k-nearest neighbors를 이용해서 정의했다. 이를 통해서 특정 feature 벡터가 실제 이미지 분포에 포함되는지 혹은 생성된 이미지 분포에 포함되는지를 판단할 수 있다
식(2): 함수 f를 통해 얻은 값을 통해 recall과 precision을 정의한다. recall과 precision의 원래 정의와 같다.
정리
- GAN (생성 모델)을 평가하는 것은 어렵다
- 평가 방법으로 FID, IS, HYPE, precision and recall 등이 있다
- 해당 평가 방법들 모두 완벽한 방법은 아니고, 장단점이 존재한다
- 생성 모델의 evaluation metric에 대한 연구가 계속 진행되고 있다.
GAN Disadvantages and Bias
Disadvantages of GANs
Advantages of GANs
1. 높은 수준의 이미지 생성
2. 이미지 생성 시간이 빠르다.
Disadvantages
1. 본질적인 evaluation metrics 부족
2. 학습의 불안정성 -> 어느정도 해결됨
3. 명시적인 확률 밀도를 알 수 없다.
4. latent vector로 역변환이 어렵다.
Alternatives to GANs
Variational Autoencoder(VAE)
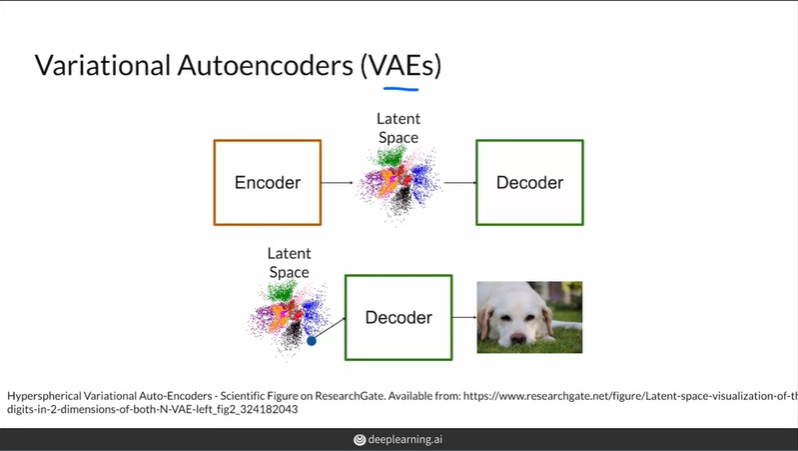
encoder와 decoder로 이루어진 생성 모델로 자세한 설명은 이전 강의
https://velog.io/@tobigs-gm1/Variational-Autoencoder 참조
장점
1. 확률 밀도를 알 수 있다
2. 역변환이 가능하다
3. 학습의 안정성
단점
1. blurry한 생성 결과물
Autoregressive Model
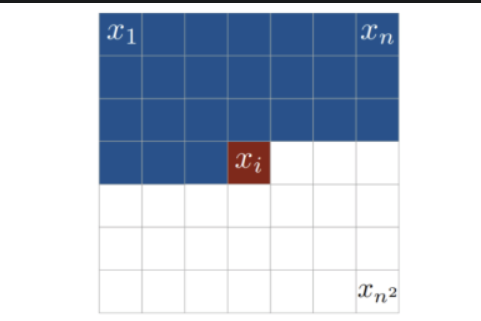
RNN처럼 sequence를 이용해서 이미지를 생성한다. 따라서 GAN이나 VAE와 다르게 latent vector가 존재하지 않는다.
pixelRNN, pixelCNN, GatedpixelCNN 등이 존재한다.
Flow based generative model
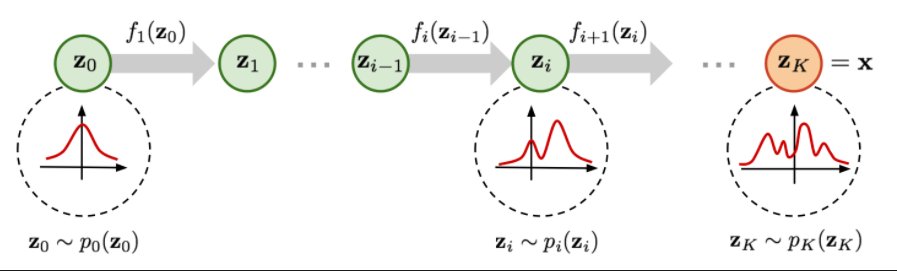
다른 모델과 다르게 letent vector z가 input vector x와 같은 차원을 갖는다. 같은 차원을 갖으므로 정보의 손실이 적다.
z의 분포를 표준정규분포로 시작하여 변수변환과 야코비안을 이용해 x의 분포처럼 복잡한 분포로 만든다. 이때 변환에 사용되는 함수는 역함수가 존재해야하고, 야코비안 행렬식 계산이 간단하게 이뤄져야 한다.
이러한 과정을 통해 구한 함수 f를 이용해 생성 결과물을 얻는다.
Intro to Machine Bias
COMPAS Algorithm
이 알고리즘은 미래에 범죄를 저지를 확률에 따라 점수를 주는 알고리즘이다. ProPublica는 기사에서 해당 알고리즘에 인종차별적 요소가 들어가 있다고 문제를 제기했다.

왼쪽의 백인 남성은 Home Depot에서 대략 $86 가치의 물건을 절도했다. 또한 그는 무장절도 경험과 수감 경험이 있다. 오른쪽의 흑인 여성은 $80 가치의 자전거와 스쿠터 절도를 시도했고, 현장에서 물건을 두고 도주했다. 다른 전과 기록은 없었다. 하지만 흑인 여성의 COMPAS점수가 더 높았다.
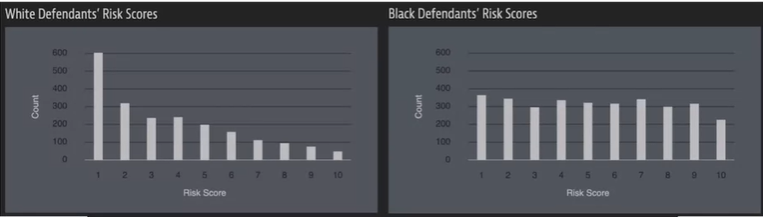
이 알고리즘의 사전 질문에 인종에 대한 질문은 존재하지 않지만 인종차별적인 결과가 발생하고 있다. 하지만 알고리즘의 계산과정은 공개되지 않아서 알고리즘 설계에서 인종차별적 결과를 의도했는지 확인하기 어렵다.
알고리즘의 점수는 판사의 판단에 영향을 미쳐 수감 기간에 영향을 준다. 또한 이 수감 기간으로 인해 수감 생활 이후의 삶에 안 좋은 영향을 미친다.
Fairness Definitions
'Fairness Definitions Explained'논문에서 예시를 통해 여러 fairness definitions를 설명하고 있다.
해당 논문에서 German Credit Dataset으로 학습된 로지스틱 회귀 분류기를 사용해 남성과 여성으로 그룹간의 신용 점수 분류 결과의 차이를 확인한다. 이 분류기를 이용해 여러 fairness definition을 각각 설명하고, 어떻게 적용되는지를 확인한다. 이 과정에서 fairness를 무엇으로 정의하냐에 따라 분류기의 fairness는 달라진다.
definitions of fairness
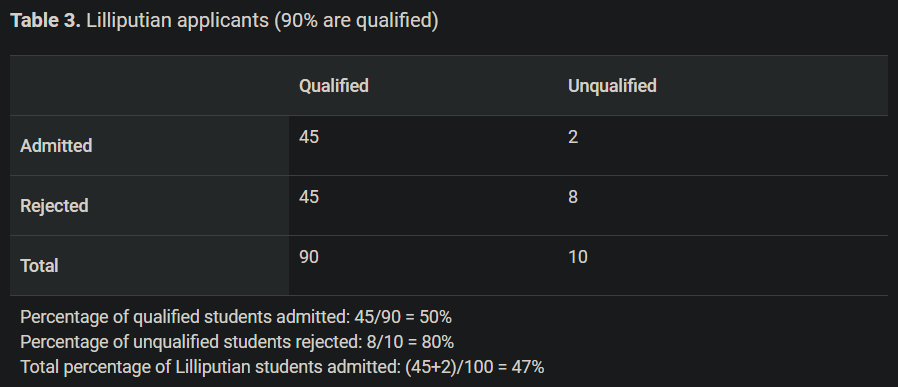
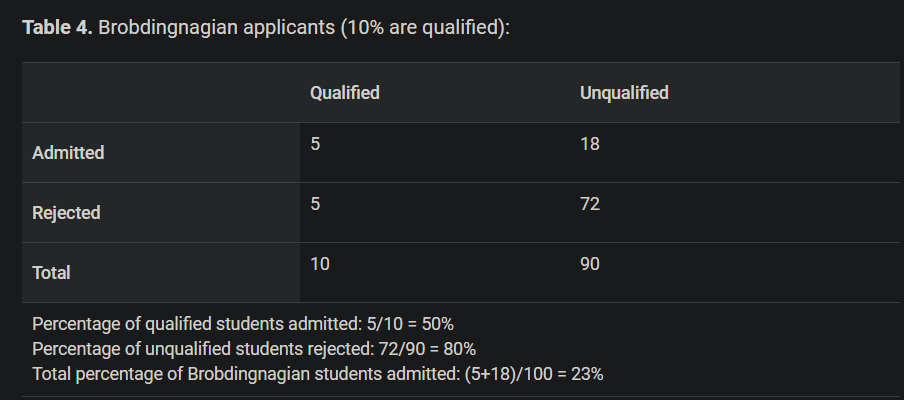
위 표에서 Lilliputian과 Brobdingnagian그룹으로 나뉜다.
Qualified/Unqualified는 ground-truth로 실제 자격인 있는 없는가에 대한 값이다
Admiited/Rejected는 분류의 결과로 예측값이다.
-
demographic parity: A fairness metric that is satisfied if the results of a model's classification are not dependent on a given sensitive attribute.
Ground-truth에 상관없이 그룹에 따른 분류결과(Admitted/Rejected)의 비율이 같으면 된다. 위의 예시에서 두 그룹의 total percentage of admitted가 다르므로 demographic parity을 만족하지 못 한다. -
equality of opportunity: equality of opportunity measures whether the people who should qualify for an opportunity are equally likely to do so regardless of their group membership.
그룹에 상관없이 실제 자격이 있는(qualified)한 학생은 선호되는 결과인 Admitted로 분류될 확률이 같아야 한다.위의 예시에서 두 그룹의 percentage of qulified students admitted가 같으므로 equality of opportuniy가 만족한다. -
equality of odds: if, for any particular label and attribute, a classifier predicts that label equally well for all values of that attribute.
그룹에 상관없이 자격이 있는(qualified)한 학생은 Admitted로 분류될 확률이 같고, 또한 자격이 없는(unqualified)한 학생은 rejected로 분류될 확률이 같아야 한다. 즉, equality of opportunity에서 부정적인 결과에 대한 확률도 같아햐 하는 제약조건이 추가된 fairness이다. 위의 예시에서 두 그룹 각각 percentage of qualified students admitted와 percentage of unqualified students가 같으므로 equality of odds를 만족한다. -
fairness through unawareness: A model is fair if the protected attribute differentiating Class A and Class B is not given to the model.
그룹 조건이 포함되지 않았을 때 분류 결과 비율이 같으면 만족한다.
Machine Learning Glossary: Fairness (2020):https://developers.google.com/machine-learning/glossary/fairness 에서 더 많은 정의 확인할 수 있다.
A Survey on Bias and Fairness in ML
'A Survey on Bias and Fairness in Machine Learning' 논문에서는 Bias와 Fairness의 정의에 대해 상세히 나와있다. 또한 Bias문제가 없는 fair machine learning methods에 대해서 소개하고 있다.
여기서는 fair한 생성모델을 하나 소개한다.
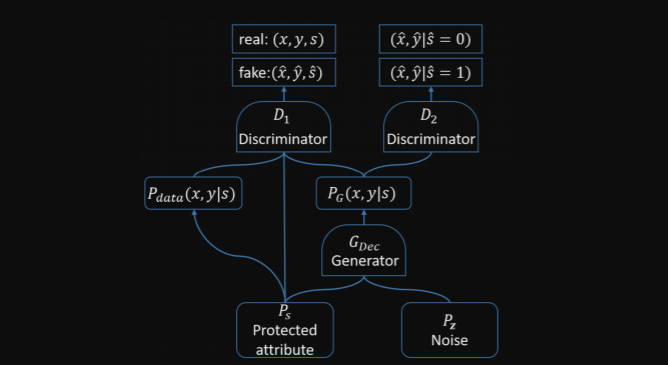
위 그림은 FairGAN의 구조이다. FairGAN은 한 개의 생성자와 두 개의 구별자로 이루어진다. 생성자는 이산적이고 연속적인 데이터 둘 다 생성하기 위해 medGAN의 생성자를 수정해서 사용한다. 구별자1과 생성자의 적대적 관계는 conditionalGAN과 유사한 형태를 갖고 있다. 또한 구별자2와 생성자의 적대적 관계는 생성된 샘플이 proteced속성(s)의 값을 예측하기 위해 지원하는 정보를 인코딩하지 않도록 하는 것이 목표로 한다.
FairGAN 논문: https://arxiv.org/pdf/1805.11202.pdf
Ways Bias in Introduced
Training Bias

- 데이터를 수집하는 과정에서 변동(분산)이 없는 데이터를 수집하는 경우가 있다.
- 데이터가 한 장소 또는 한 웹사이트에서 수집되는 경우가 있다.
- 데이터를 라벨링할때 다양한 라벨링하는 사람이 필요하다. 적은 수의 라벨러는 데이터에 편향을 줄 수 있다.
Evaluation Bias
- 모델이 평가될 때 주요 문화의 특성에서의 correctness가 반영되어 편향이 생길 수 있다.

- 'Does Object Recognition Work for Everyone?'논문에서는 household detection 모델에서 income에 따른 평향이 존재한다는 것을 밝혔다.
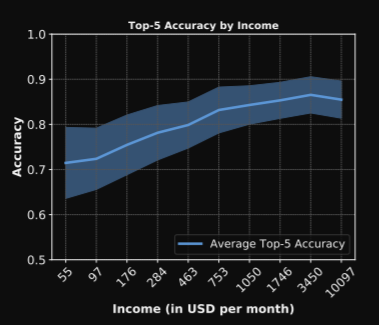 해당 모델에서 이와 같은 편향이 생긴 이유는 데이터의 대부분이 income이 높은 국가들에서 수집되었고, 데이터 수집시 기본 언어로 영어를 사용했다는 것이다.
해당 모델에서 이와 같은 편향이 생긴 이유는 데이터의 대부분이 income이 높은 국가들에서 수집되었고, 데이터 수집시 기본 언어로 영어를 사용했다는 것이다. - 생성 모델을 평가할 때 FID가 사용된다. FID의 Inception-v3는 ImageNet dataset을 이용해 pre-train된다. 밑의 그림과 같은 ImageNet dataset의 편향으로 인해 편향된 평가를 얻게 될 수 있다.
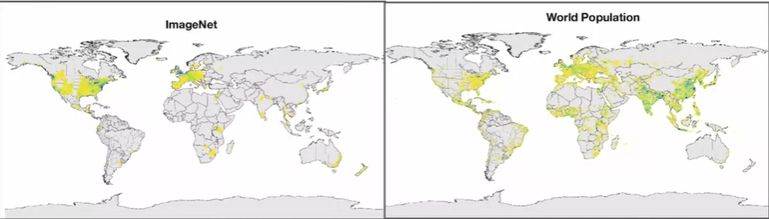
Model Architecture Bias
모델의 구조 만들거나 최적화 코드를 만드는 코딩하는 사람에게 영향을 받아 편향될 수 있다.
PULSE

styleGAN을 이용해서 pixelated blurry image에서 high resolution image을 생성한다.

왼쪽사람 부터 former president of U.S.A Barack Obama(African-American), politician Alexandria Ocasio Cortez(Hispanic), actress Lucy Liu(Asian-American)
이들은 모두 유색인종이다. 하지만 생성된 이미지를 보면 백인의 특성을 많이 갖는 이미지들이 생성되었다. 이를 통해서 해당 모델에 bias가 존재함을 알 수 있다. 해당 프로그램 개발자는 모델 적용시의 주의사항을 명시하였다.
머신러닝 알고리즘을 개발할 때 데이터 수집부터 평가 및 활용 등 개발 전과정에서 bias가 생길 수 있다. bias에 관한 문제는 현재 ML community에서 뜨거운 논쟁거리이다. 따라서 이를 극복하기 위한 연구도 진행되고 있다.
정리
- GAN은 장점과 단점이 존재한다.
- GAN이외에 VAE, AR, FLOW 등 생성 모델들이 존재한다.
- 머신러닝 모델에는 bias가 존재할 수 있다.
- bias를 평가하기 위한 여러가지 fairness가 정의된다.
- 머신러닝 개발자는 개발 및 적용 등 모델 전과정에서 bias가 일어날 수 있다는 점을 명심해야한다.
references
- Build Better GANs coursera강의 및 첨부된 논문들https://www.coursera.org/learn/build-better-generative-adversarial-networks-gans/home/welcome
- Inception-v3 논문: https://static.googleusercontent.com/media/research.google.com/ko//pubs/archive/44903.pdf
- Inception Score 관련: https://medium.com/octavian-ai/a-simple-explanation-of-the-inception-score-372dff6a8c7a
,https://m.blog.naver.com/chrhdhkd/222013835684 - 투빅스 12기 김태한님 VAE 수업자료: https://velog.io/@tobigs-gm1/Variational-Autoencoder
- Autoregressive model 관련: https://towardsdatascience.com/generating-high-resolution-images-using-autoregressive-models-3683f9af0db4
- Flow based generative model 관련: https://medium.com/@sunwoopark/slow-paper-glow-generative-flow-with-invertible-1x1-convolutions-837710116939
- FairGAN 논문: https://arxiv.org/pdf/1805.11202.pdf

12개의 댓글

투빅스 13기 이예지:
이번 강의는 'GAN의 평가와 편향'으로, 김상현님께서 진행하셨습니다.
GAN의 평가(Evaluation)
GAN은 Universal gold-standard discriminator가 존재하지 않습니다.
생성된 이미지가 얼마나 잘 "실제 이미지와 비슷하게" 만들어졌는가를 평가하는 것이 쉽지 않을 것 같습니다.
그러나 정확히 평가하는 것은 어렵지만 생성 모델에서 유의해야할 두가지 중요 지표가 있습니다.
(1) Fidelity: 이미지의 질
(2) Diversity: 이미지의 다양성
이를 중심으로 여러가지 평가 메트릭이 나오게 됩니다.
- pixel distance, feature distance, feature extraction, Inception-v3 and embeddings, FID, IS, samplng and truncation, HYPE, precision and recall
종류가 많아서 생략했지만, 각 방법 모두 장단이 있는 것 같습니다.
GAN의 단점(Disadvantage)
GAN은 분포에 대한 학습을 기존 방법보다 빠르고, 잘 학습한다는 장점이 있습니다.
그러나, 평가 메트릭의 부족과 명시적인 확률 밀도를 알 수 없는 등 다양한 단점이 있습니다.
물론 이 대안으로 다양한 모델들이 등장했고 GAN을 확장시키는 많은 연구가 나오고 있습니다.
GAN의 편향(Bias)
이번에 다룬 편향은, 주로 데이터셋의 부족으로 인해 발생할 수 있는 차별에 대한 내용이었습니다.
이는 실제로 모델을 서비스할 시 큰 문제를 불러일으킬 수 있기 때문에 신중해야합니다.
이를 모델링 과정에서 고려하기 위해 여러가지 fairness 정의가 등장하게 되었습니다.
모델에서 모델 설계 혹은 학습과정이 매우 중요합니다.
그러나 이런 부분에 너무 집중하다보면, 정작 가장 중요한 부분을 잊게 되는 것 같습니다.
이번 강의를 통해 미래에 마주하게 될 평가 단계와 편향에 대해 다시 한 번 생각할 수 있었던 것 같습니다.
좋은 강의 감사합니다 :)

투빅스 12기 김태한
- GAN이 가진 여러한 특징을 살펴볼 수 있는 시간이었습니다. GAN이 학습이 잘 되었는가를 판단하는 기준을 잡는 데는 fidelity와 diversity가 있으며 이러한 기준을 통해 여러 판단 지표 즉 evaluation metrics들을 구할 수 있었습니다. 이러한 GAN은 분포에대한 학습을 할 수 있는 장점이 있으나 본질적인 evaluation metrics 부족, 학습의 불안정성 -> 어느정도 해결됨, 명시적인 확률 밀도를 알 수 없다, latent vector로 역변환이 어렵다는 문제들이 존재하며 데이터셋에 따라 fairness를 반영하지 못하는 문제들도 반영하여 GAN에 대해 여러 방면에서 생각해 볼 수 있는 좋은 시간이었습니다.
좋은 강의 너무너무 감사합니다!

투빅스 14기 정재윤
이번 강의는 ‘GAN의 평가와 편향’으로, 김상현님께서 강의를 진행해주셨습니다.
- 우선 생성모델 분야가 굉장히 뜨고 있는 것은 맞습니다. 하지만 이런 발전 속도에 비해 이를 평가해주는 기준이 명확히 존재하지 않습니다. 이런 상황에서도 모델을 평가하는데 중요한 2가지 지표가 있는데요. Fidelity와 diversity입니다. Fidelity는 모델이 해당 이미지를 얼마나 정확하게 만들어 냈느냐를 평가하는 것이고, diversity는 모델이 이미지를 얼만큼 다양하게 만드느냐입니다. 특히 이 두 가지는 상호배반적인 성격이어서 그 중간을 잘 설정하여 이미지를 생성하는 것이 중요합니다.
- 모델을 잘 짜서 좋은 모델을 만드는 것도 중요하지만, 편향이 들어가면 안되는 것도 중요합니다. 이번 강의에서 다룬 편향은 주로 인종차별에 관한 편향이었습니다. 데이터셋에서 백인의 비중이 많다보니 다른 인종의 이미지를 input으로 넣어도 백인의 특징을 가진 이미지가 만들어질 뿐만 아니라 범죄 등도 다른 인종이 훨씬 많이 일어난다고 모델은 스스로 판단했습니다. 이런 편향은 사회적인 문제를 일으킬 뿐만 아니라 큰 논란을 일으킬 수 있습니다.
코세라 강의 영상이 너무 빠르게 말해서 이해가 힘들었는데, 덕분에 쉽게 이해할 수 있었던 것 같습니다. 감사합니다. 😊

투빅스 11기 이도연
앞서 배운 GAN을 평가하는 지표에 대해 배우고 편향에 대한 문제점을 다루는 강의였습니다. 정말 중요한 내용을 다룬 강의 잘 들었습니다!
- GAN의 생성된 이미지를 평가하기 위해 중요한 지표로는 Fidelity와 Diversity가 있다.
- 이미지를 비교한다고 할 때 가장 쉽게 떠오르는건 Pixel distance가 있지만 위상변화에 취약하다는 단점이 있다. 강의에서 소개한 Feature distance의 경우 특징들을 추출해서 비교하는 방법으로 pre-train된 classifier를 사용한다. (필요에 따라 사용하는 layer는 달라진다)
- 평가방법으로 FID(Fréchet Inception Distance), IS(Inception Score), HYPE, precison and recall을 설명하는데 모두 각각의 장단점이 있다.
- 그리고 GAN과 다른 generative model의 장단점도 살펴보았는데 GAN과 지난 시간에 배운 VAE의 장단점이 반대라는 것을 알 수 있었다.
- 딥러닝에서 데이터 셋의 부족, 편향으로 인해 발생할 수 있는 차별에 대해서는 생각해 왔는데 Bias와 Fairness의 정의에 대해 공부하며 조금 더 구체적으로 고민해볼 수 있었다. 그리고 데이터 뿐만 아니라 모델의 평가에 있어서 문화적 특성에 의해 생길 수 있는 편향이나 구조를 만들거나 코딩하는 사람에 의해 생기는 편향 등 머신러닝의 전 과정에서 bias가 일어날 수 있다는 점을 배웠다.

투빅스 14기 박준영
이번 강의는 Gan의 평가와 편향에 대한 강의로 투빅스 14기 김상현님이 발표하였습니다.
-Gan model은 universal gold-standard discriminator가 존재하지 않기때문에 Gan model을 평가하기 어렵다.
생성된 이미지 평가의 중요한 척도는 이미지의 quality인 Fidelity이고 이미지의 다양성인 Diversity 2개이다.
-
이미지를 비교할때 pixel distance와 feature distance 두가지 방법으로 비교하는데
pixel distance는 각 픽셀 값의 차이의 절대값으로 구한다.
이 방법은 쉽게 구할 수 잇지만 pixel의 위치가 바뀌면 제대로 평가할 수 없다는 문제가 있어서 사용하지 않는다. -
feature distance는 이미지의 특징을 추철해서 비교한다.
이는 pixel의 위치가 변하더라도 특징을 기준으로 하기때문에
제대로 평가 할 수있다. -
모델의 수집과정과 문화의 특성 모델러의 가치관으로 인해 모델의 bias가 일어날 수 있다는 점을
명심하면서 모델을 만들어야한다.
이번 강의에선 모델의 편향 부분이 인상 깊었습니다. 인공지능 기술이 너무나도 빨리 혁신적으로
발전함에 따라 AI가 하는 모든것이 맹목적으로 옳다고 생각에 빠져들고 있었는데
bias 부분을 보면서 모델의 편향에 대해 알게되었으며 모델을 만들때나 모델을 해석할 때
bias에 빠지지않게 더욱 조심해야 할것같습니다.
좋은 강의 감사합니다.
투빅스 14기 박지은:
- GAN은 fidelity(질)와 diversity(다양성)을 지표로 평가할 수 있습니다. 이를 위해 이미지를 비교하기 위해서는 pre-trained CNN으로 특징 벡터를 추출하여 비교함으로써 위상변화에 대해 믿을만한 값을 얻을 수 있습니다.
- GAN을 평가하기 위한 방법으로는 Frechet Inception Distance(FID), Inception Score(IS), HYPE, Precision and Recall 등이 있습니다.
- 머신러닝은 training bias, evaluation bias, model architecture bias 등의 이유로 편향적인 결과가 나올 수 있습니다. 이를 바로잡고자 한 개의 생성자와 두 개의 구별자를 사용하여 서로 간섭하지 않게 하는 등의 fairGAN에 대한 연구가 이루어지고 있습니다.
머신러닝을 기반으로 한 기술의 상용화에 있어서, 간과하기 쉽지만 중요한 부분인 공정성에 대해서 생각해 볼 계기가 되었고, 객관적인 데이터를 기반으로 한 학습에 실제 사회불평등적 요소가 드러나는 것이 정말 신기했습니다. 좋은 강의 감사드립니다.

투빅스 13기 신민정
이번 강의는 "GAN의 평가와 편향"으로, 김상현님께서 진행해주셨습니다.
- 생성된 이미지를 평가하는 두가지 지표 Fidelity(quality of image), Diversity(variety of image)와 FID,IS,HYPE,precision and recall과 같은 평가방법을 알아보았습니다. 평가 방법들의 장단점을 잘 파악하여 사용해야합니다.
- Flow based 생성모델은 latent vector z와 input vector가 같은 차원을 갖기 때문에 정보의 손실이 적고, z->x로 변환.역변환이 가능합니다.
- Machine bias에 대해 알아보았습니다. 성별, 인종이 모델에 영향을 주는 예시를 들어주셨습니다. 모델 평가와 데이터셋의 편향이 모델에 미치는 영향을 알아보았고, 모델을 설계할 때 이러한 편향이 생기지 않도록 주의해야한다는 점을 느낄 수 있었습니다. Style GAN을 이용해 픽셀이미지에서 해상도를 높여 실제 얼굴로 만드는 모델에서 편향이 일어난 예시가 인상깊었습니다.
수식적인 부분까지 꼼꼼하게 설명해주셔서 정말 이해가 잘되었습니다. 벨로그 글에 정리가 잘되어있어서 복습하기에 아주 유용하였습니다. 좋은 강의 감사합니다.@v<

투빅스 14기 김민경
- GAN은 정량적인 평가가 어렵지만 생성된 이미지를 평가하는 데 중요하게 고려할 점이 두 가지 있다. 얼마나 잘 모방했는지를 나타내는 Fidelity, class가 골고루 잘 나눠졌는지를 나타내는 Diversity이다.
- GAN의 평가 방법은 대표적으로 진짜 데이터와 생성된 데이터의 분포 차이를 비교한 지표인 "Fréchet Inception Distance (FID)", 생성된 데이터만을 사용한 지표인 "Inception Score (IS)"가 있다.
이외에도 사람이 평가를 하는 HYPE(time, inf) 방법, 기계가 평가하는 precision and recall 방법 등이 있다. - GAN은 높은 수준의 이미지를 빠르게 생성할 수 있다는 장점이 있는 반면 평가 기준이 모호하다는 것과 명시적인 확률 밀도를 알 수 없는 것, latent vector로 역변환이 어렵다는 등의 한계가 있다. 이러한 단점을 가진 GAN의 대안으로 VAE도 고려할 수 있다. 대신 흐릿한 이미지가 생성되는 등의 GAN의 장점을 반대로 단점으로 가진다.
- 기계는 데이터에 의존하기 때문에 편향이 있을 수 있고 공정성에 대한 의문도 가진다. 이러한 것을 보완하기 위해 공정성을 위한 FairGAN, medFAN 등이 대안으로 추천되고 편향을 보완하기 위한 방안으로는 1. 변동 없는 데이터를 수집하거나 2. 편향없는 데이터 수집, 3. 다양하고 많은 수의 라벨러 고용 등이 있다.
- GAN의 평가와 한계에 대해 알 수 있는 흥미로운 강의였습니다. 감사합니다:)
안녕하세요. FID Score 관련하여 질문이 있어서 댓글을 남기게 되었습니다. 본문에서 FID Score의 단점으로 " ImageNet data로 pre-trained된 경우 ImageNet data 이미지의 class와 다른 이미지를 다룰 경우 원하는 특징을 포착하지 못할 수 있다" 라고 언급하셨는데 혹시 이와 관련해서 참고하신 논문이나 자료가 있을지 궁금합니다. 감사합니다.
투빅스 14기 한유진 :
생소한 단어들이 꽤 있었는데 차근차근 설명해주셔서 듣기 좋았던 강의였습니다. 중간중간 정리를 해주신 점도 굉장히 도움이 많이 되었습니다. 감사합니다!