이 논문은 2022년 9월 26일에 올라온, 2022 NeurIPS에 accept된 논문입니다!
논문 리뷰에 너무 많은 시간이 걸리는거 같아서, 이번엔 motivation, proposed methods, experiment, conclusion형식으로 리뷰해보려고 합니다!
Motivation
-
beam search와 같은 maximization-based decoding methods들이 질이 저하된 글을 생성하는 경향이 있음
- 여기서 질이 저하되었다 == 자연스럽지 않으면서 바람직하지 못한 반복을 포함하고 있는 글!
ex) 나는 밥을 먹었다 먹었다 먹었다 . . . 이런 것!
- 여기서 질이 저하되었다 == 자연스럽지 않으면서 바람직하지 못한 반복을 포함하고 있는 글!
-
본 논문에서는 이러한 현상이 anisotropic distribution of token representations때문이라고 봄
- 즉, 우리가 보통 사용하는 사전 학습된 언어 모델들이 내뱉는 token representation이 의미와 관계 없이 전반적으로 모두 유사하기 때문에, 이러한 현상이 발생한다고 봄
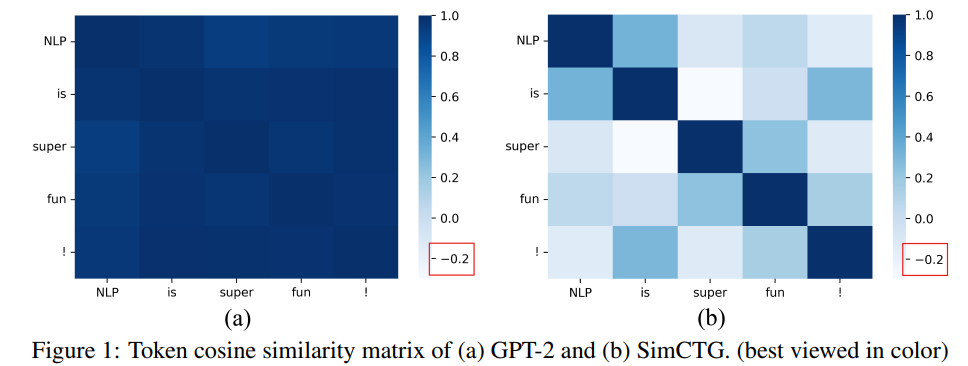
- 위의 그림을 보면, 확실히 GPT-2를 거쳐서 나온 모델의 경우 토큰끼리의 유사도가 매우 높은 것을 볼 수 있음(토큰들이 밀집하게 representation됨 == anisotropy), 반면에 SimCTG로 추가 학습한 모델을 보면 토큰끼리의 유사도가 낮아진 것을 볼 수 있음
- 이렇게 토큰 유사도가 서로 높으면, 모델이 매 스텝마다 반복적으로 같은 토큰을 생성할 수 있어서 바람직하지 않음
- 반복되는 현상을 줄이기 위해선 생성된 글의 token similarity matrix의 sparseness가 보존되어야 함!
(+) 근데 이걸 입증하진 않음.. CL로 학습해서 개선되었다고 이러한 문제가 있어서 그런거라고 볼 수 있나?
- 즉, 우리가 보통 사용하는 사전 학습된 언어 모델들이 내뱉는 token representation이 의미와 관계 없이 전반적으로 모두 유사하기 때문에, 이러한 현상이 발생한다고 봄
Proposed methods
-
기존 연구 방향
- decoding strategy를 less like vocabualries에서 샘플링하는 것으로 수정
=> 하지만 이 방식은 생성된 글이 원문(human written prefix)과 다르거나 모순되는 등의 sematic inconsistency문제가 발생
==> 즉, 비교적 등장 확률이 낮은 토큰을 디코딩하기 때문에, 원문과 관련 없는 말을 할 확률이 높아짐 - 모델의 output vocabulary distribution을 unlikelihood training으로 수정

(NEURAL TEXT DEGENERATION WITH UNLIKELIHOOD TRAINING 논문에서 발췌)- 위의 수식을 보면 을 줄이기 위해선 결국 를 줄여야한다.
- 여기서 은 이전의 context tokens이므로, 직관적으로 위와 같은 이미 나왔던 토큰이 반복해서 나올 확률을 낮춰주는 역할!
- decoding strategy를 less like vocabualries에서 샘플링하는 것으로 수정
-
제안한 방법
: 모델이 discriminative and isotropic token representations를 학습하도록 하는 SimCTG(a simple contrstive framework for neural text generation)을 제안- loss function
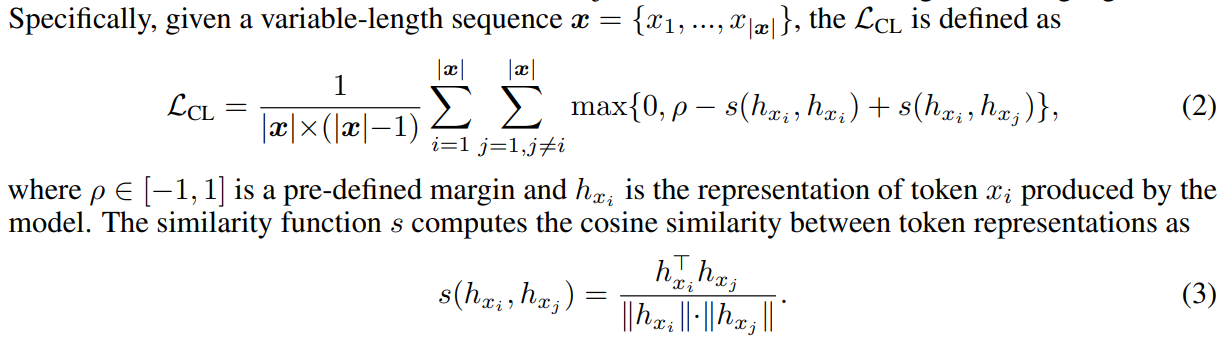
- loss function에 contrastive learning항을 추가
- 식을 살펴보면, 같은 토큰과의 유사성은 높도록, 다른 토큰과의 유사성을 낮추도록 학습을 함
- 특히, 가 뜻하는 바는, 같은 토큰의 유사도와 다른 토큰의 유사도의 차이가 만큼은 나야한다는 것
- 토큰 유사도는 코사인 유사도를 사용해서 계산
- 식을 유심히 보면 라고 나와있는데, 같은 토큰과의 유사도이므로 정의에 의해 1이 됨
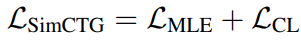
- 전체 loss는 위와 같음. 기존의 언어모델에서 사용하던, 다음 토큰의 나올 확률에 대한 loss인 MLE loss와 새로 제안한 CL loss를 더하여 최종 loss로 사용
- SimCTG를 보완하는 decodig strategy, contrastive search를 제안
- 각 decoding step에서 확률이 높은 후보 토큰들 중 생성된 글과 사람이 쓴 prefix사이의 의미적 일관성을 잘 유지하는 토큰을 선택
- 생성된 글의 sparseness of the token similarity matrix가 보존되도록 함
- 이 두 가지를 충족시켜서 생성된 글이 1) 더 의미적으로 prefix와 일관되도록 2) model degeneration을 피할 수 있음
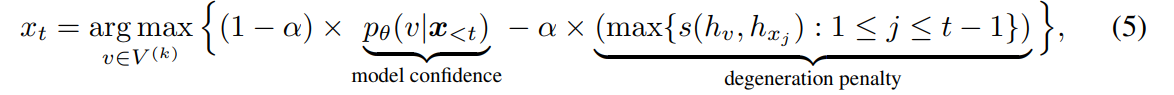
- V가 k번째 스텝에서의 후보 토큰 집합을 의미하는데, 이 식을 살펴보면 기존에 사용하던 이전 context가 주어졌을 때, 다음에 나올 토큰의 확률을 나타내는 model confidence항과 이번에 나올 토큰과 이전 step까지 나온 토큰의 유사도 중 최대값을 계산하는 degeneration penalty항이 존재
- 이전에 나온 토큰과 유사한 토큰이 나올 경우 패널티를 부여하는 것, 즉, 이전과 다른 discriminative한 v를 고르도록 유도
- 가 0일 경우 greedy search와 완전히 동일
- loss function
Experiment
-
Experiment setup
- Model and Baselines
- GPT-2를 제안된 objective function()를 사용해 fine-tuned
- baseline의 경우 12개의 head를 가진 12개의 transformer layer를 가진 모델을 사용
- 다양한 decoding methods를 사용해서 글을 생성
- MLE, SimCTG의 경우 학습시 Wikitext-103에 대해 40k training step만큼 학습시킴
- unlikelihood base line의 경우 학습시 Wikitext-103에 대해 token-level unlikelihood objective에 대해 38.5k, sequence-level unlikelihood objective에 대해 1.5k training step만큼 학습시킴
- decoding할 때, prefix의 길이를 32로, 생성하는 글의 max_len은 128로 제한
- beam search의 경우 beam size 10으로 설정
- Evaluation Benchmark
- Wikitext-103 dataset에 대해 실험을 진행
- Wikitext-103은 문서 단위의 데이터셋으로, large-scale language modeling의 평가에 널리 사용됨
- Model and Baselines
-
Evaluation Metrics
-
Perplexity : Wikitest-103에 대한 model perplexity(ppl)
-
Prediction Accuracy : 이전 토큰이 주어졌을 때, 다음에 나올 토큰을 맞추는지
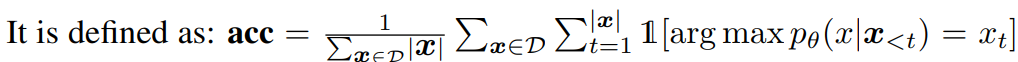
-
Prediction Repetition : 다음 토큰으로 이미 이전 step에 나온 말을 하는 정도를 측정

-
Generation Repetition : 생성된 문장에서 중복된 n-grams를 seqeuce-level repetition로 측정
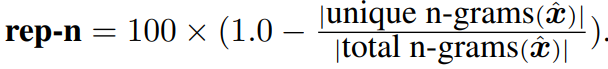
-
Diversity : 다양한 n-gram level에서 generation repetition을 측정
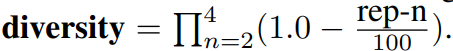
-
MAUVE : 생성된 글과 사람이 쓴 글 사이의 token distribution closeness를 측정
-
Semantic Coherence : 자동으로 SimCSE를 문장 임베딩 방법으로 사용하여, prefix와 generated text사이의 semantic coherence를 측정
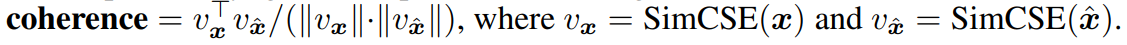
-
Perplexity of Generated Text : prefix가 주어졌을 때, 생성된 글의 perplexity를 측정. 높은 gen-ppl을 가진다면, prefix가 주어졌을 때 생성된 text가 매우 unlikely하다는 것이므로 낮은 품질의 글일 확률이 높음. 반대로 낮은 gen-ppl를 가진다면, 생성된 글이 low diversity를 가져 repetitive loops에 갇힐 확률이 높음.
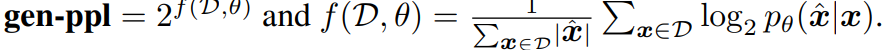
-
human evaluation
- Coherence : 생성된 글이 의미적으로 prefix와 일관되는지
- Fluency : 생성된 글이 유창하고 이해하기 용이한지
- Informativeness : 생성된 글이 다양하고 흥미로운 내용을 가지고 있는지
-
-
Experiment result
-
autometric을 사용해 각 모델, decoding method를 평가
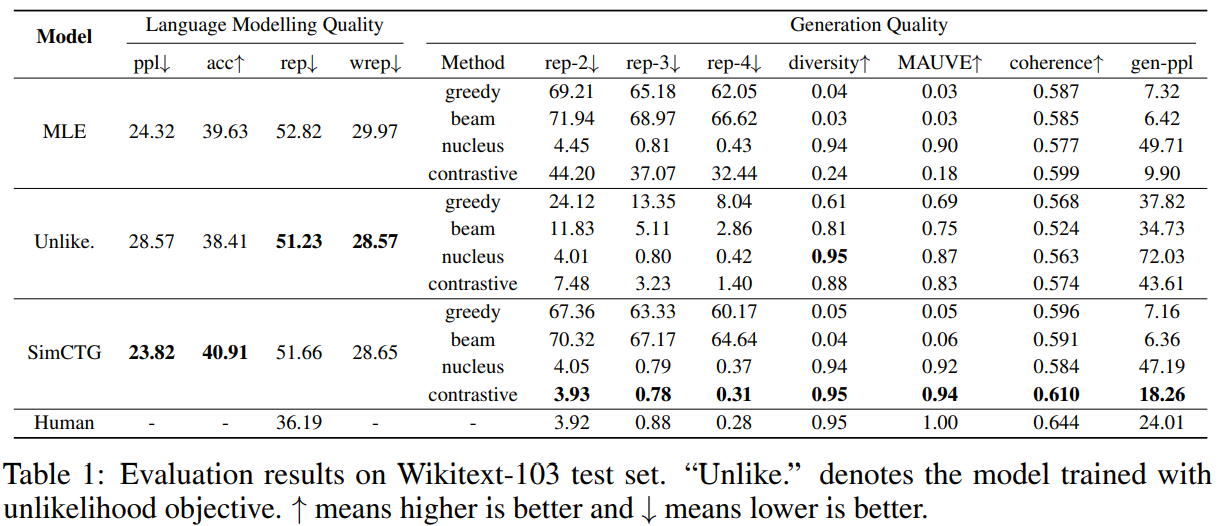
- 실험 결과를 보면, 전반적으로 SimCTG + contrastive 방식이 높은 성능을 보인다는 것을 알 수 있다.
-
human evaluation
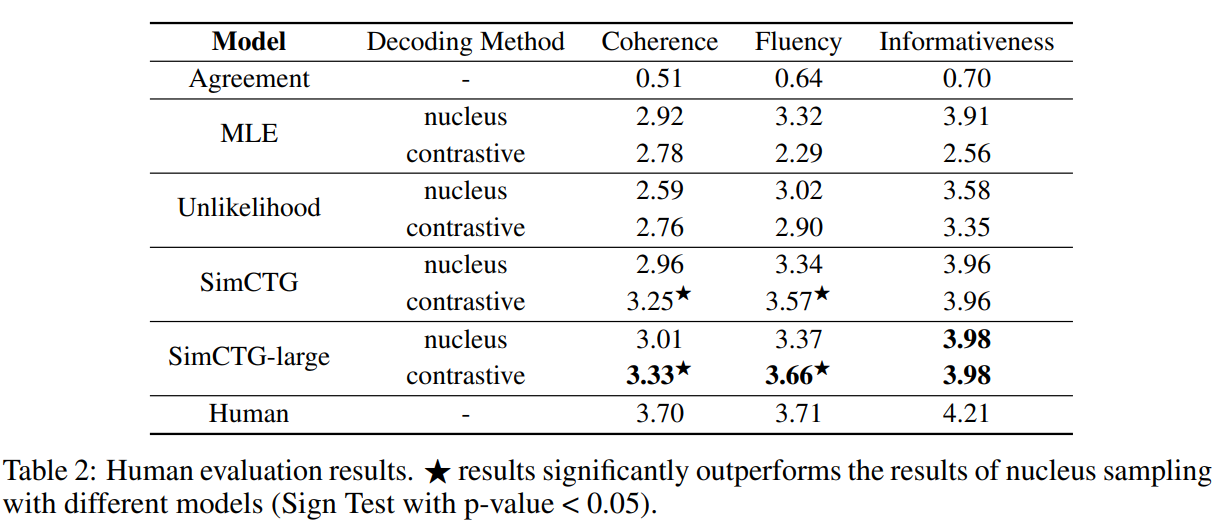
- human evaluation 역시 SimCTG-large모델이 통계적으로 유의하게 뛰어난 성능을 보인다
-
-
Open-domain Dialogue Generation
- 본 논문에서 제안하는 방식이 다른 task와 언어에도 적용되는지를 살펴보기 위해, open-domain dialogue generation에 적용해 봄
- 중국어 벤치마크인 LCCC dataset과 영어 벤치마크인 DailyDialog dataset에 대해서도 적용
- SimCTG와 MLE로 fine-tuned한 GPT-2모델을 비교, 중국어 데이터에는 공개된 Chinese GPT-2를 사용
- batch size 128, input max_len으로 256사용, LCC에서는 40k step학습, DailDialog는 5k step만큼 학습(fine-tune)
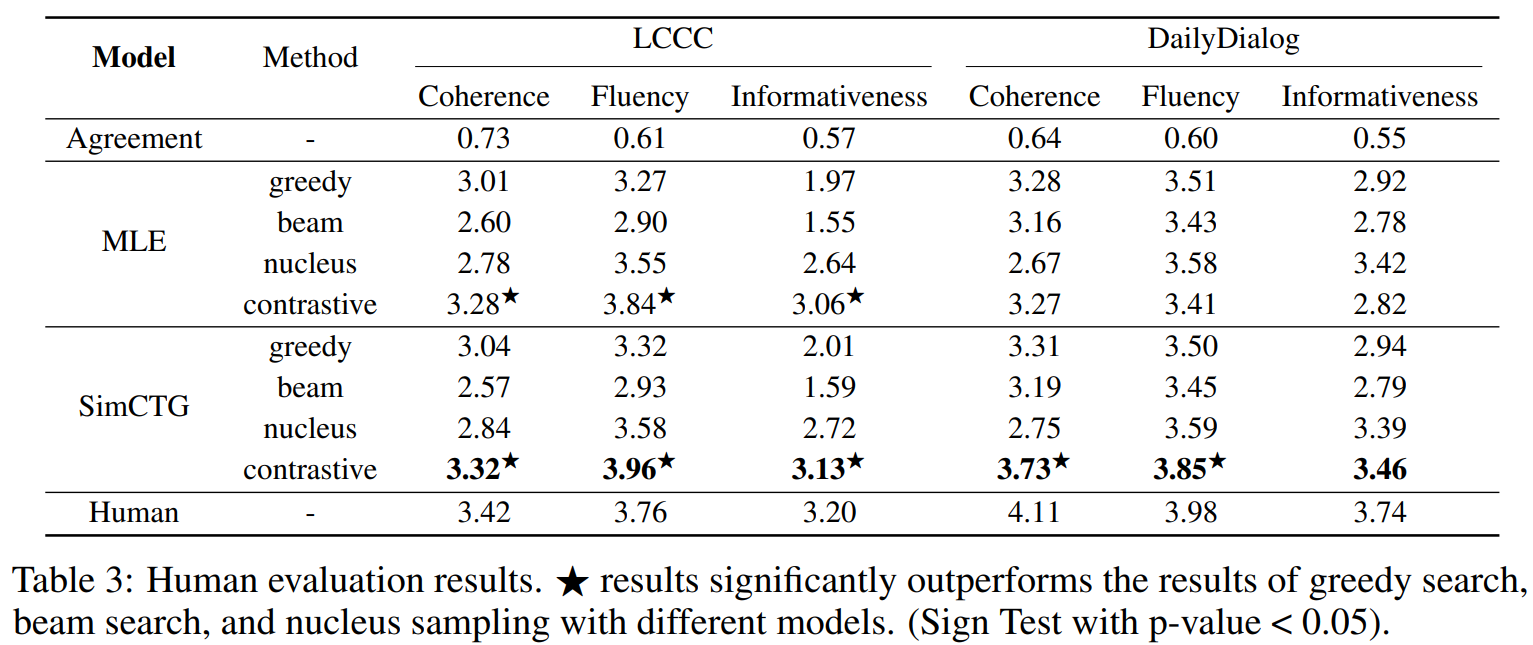
- 두 데이터셋 모두에서, SimCTG+contrastive search방법이 다양한 메트릭에서 뛰어난 성능을 보임
==> 본 논문에서 제안하는 방법이 다양한 언어와 태스크에 일반화될 수 있음을 보임 - contrstive training없이, MLE model에 contrastive search를 사용했을 떄도 상다히 높은 성능을 보임
- 이는 중국어 언어 모델에서 MLE objective는 이미 높은 수준의 isotropy를 가지는 representation space를 산출할 수 있기 때문인 것으로 보임
-
Token Represenation Self-similarity
- 다른 토큰과의 similarity를 비교해봄
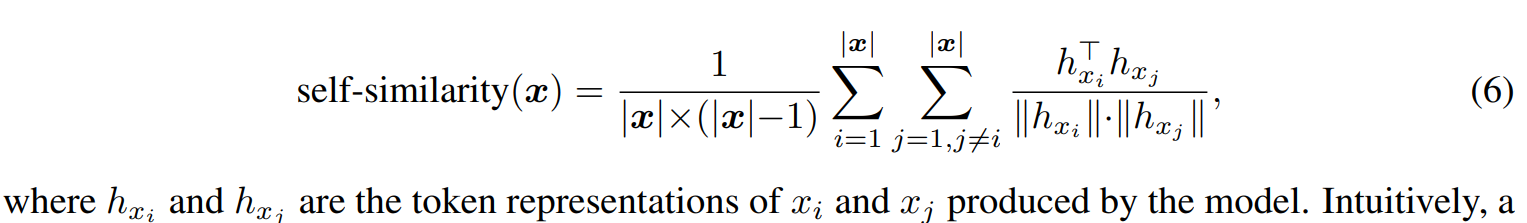
- SimCTG는 최적의 언어 모델 accuracy를 유지하면서도 distriminative하고 isotropic한 representation을 얻을 수 있는 것을 알 수 있음
- 근데 왜 마지막 레이어에서만 이렇게 격차가 벌어질까?
- 다른 토큰과의 similarity를 비교해봄
-
The Effect of Contrastive loss margin
- 에 따른 test set perplexity를 나타낸 표이다. 이를 보면 가 너무 작거나 클 경우 모델의 학습된 representation space가 너무 작거나 너무 isotropic해서 sub-optimal perplexity를 이끄는 것을 볼 수 있음
- 이걸 어떻게 알지?
- 에 따른 test set perplexity를 나타낸 표이다. 이를 보면 가 너무 작거나 클 경우 모델의 학습된 representation space가 너무 작거나 너무 isotropic해서 sub-optimal perplexity를 이끄는 것을 볼 수 있음
-
Contrastive search versus nucleus sampling
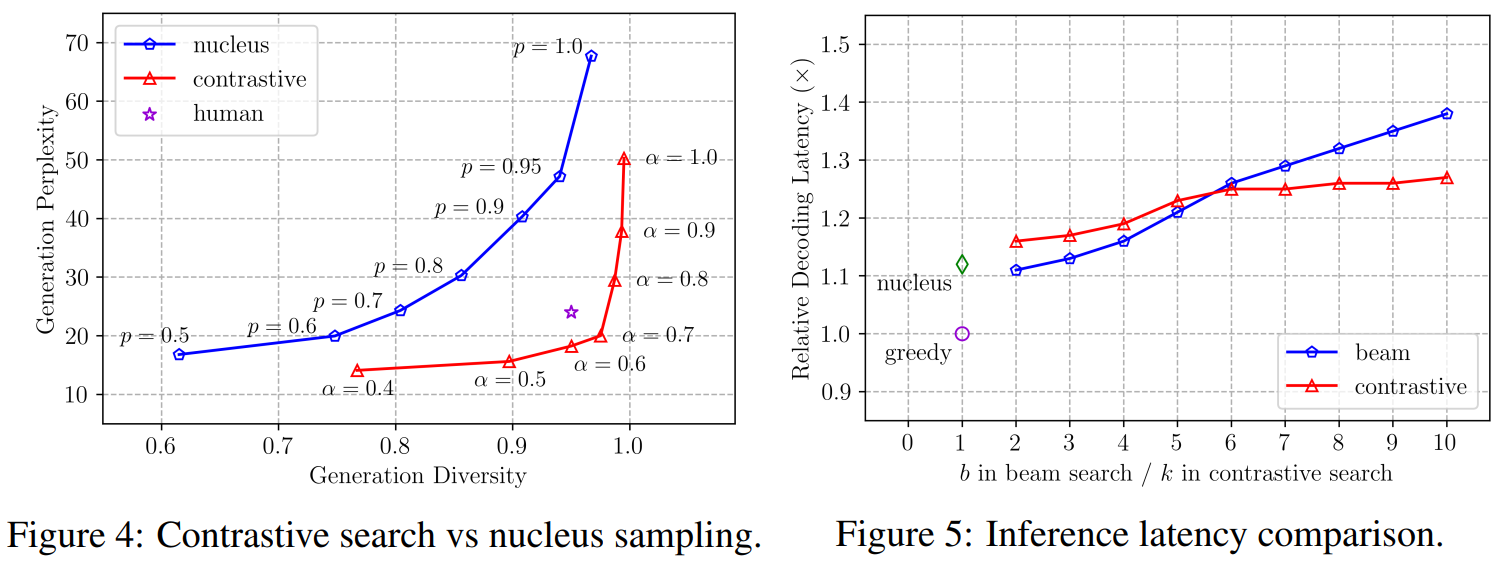
- nucleus sampling에 대한 확률 와 contrastive search를 위한 를 바꿔가며 Wikitext-103 test set에서 prefixes를 사용해 생성한 텍스트에 대해 Generation Perplexity를 나타낸 표
- 이 결과를 보면 contrastive search가 generation diversity와 perplexity사이의 trade-off에서 더 나은 밸런스를 가지고 있음
- 보라색 별표가 사람인데, 사람 기준으로 봤을 때, contrastive search가 nuclesus와 유사한 perplexity를 보이면서 훨씬 나은 Diversity를 가짐!
-
decoding latency comparison
- Figure 5를 보면, inference 속도가 비슷하지만 b와 k가 커질수록 contrastive search가 더 빠른 것을 알 수 있음
-
case study

- 빨간색은 degeneration repetitions, 파란색은 원문과 일관성이 없는 말, 초록색은 합리적인 repetition을 나타냄
-
Conparison of Token Similarity Matrix

- 빨간색이 prefix, 노란색이 generated text
- MLE+beam search가 유난히 유사도가 높은걸 볼 수 있음
- SimCTG+beam seach의 경우 전반적으로 isotropy하고 sparse해 보이나, degeneration repetitions가 여전히 생성된 글에 존재하는 것을 알 수 있음
Conclusion
- 본 논문에서는 token representation이 anisotropic한 것에서 neural language model의 degeneration이 발생한다고 주장
- 이를 위한 해결책으로, SimCTG와 contrsastive search를 제안
- 다양한 실험 결과 제안한 방법론이 text generation approaches에서 뛰어난 성능을 보임을 입증 (현재 SOTA모델보다 뛰어남)


좋은 글이네요