Abatract
-
SMART는 토큰 대신 문장을 matching시 기본 단위로 사용
-
또한 문장과 문장이 완전히 일치하는 방법이 아니라 matching function을 사용해 soft-matching되는 문장을 사용
-
Candidate 문장은 reference문장 뿐만 아니라 원문 문장과도 비교됨
-
결론적으로 SMART with model-based matching function는 system-level correlation에서 모든 metric과 비교해서 뛰어난 성능을 보임
-
SMART with string-based matching function은 현재의 model-based metric과 견줄만한 성능을 보임
Introduction
-
현재 텍스트 생성 태스크에서 발전을 저해하는 요소 중 하나는 바로 automatic evalutation!
-
현재의 automatic metric은 token-level의 matching에 의존하고 있음(ROUGE, BLEU)
- 이러한 metric은 텍스트의 질을 평가하는 4가지 차원(coherence, factuailty, fluency, informativeness)에 대해 human judgment와 낮은 상관관계를 보임
- 이 때문에, 현재 텍스트 생성에서 평가는 소수의 데이터를 바탕으로 human elicitation study와 병행되고 있음
-
혹은, 자동으로 모델이 생성한 텍스트를 평가하기 위해 pretrained language model를 leverage함
-
하지만 ROUGE와 LM-based metrics모두 3가지 큰 문제점을 가지고 있음
-
이러한 metric은 문장이 길고, 여러 문장으로 되어있을수록 평가 성능이 낮아짐
- 특히 ROUGE의 경우 긴 결과값에서 정보가 섞여있을 때 제대로 평가하지 못함(coherence를 평가하는데 있어 취약)
- LM 기반의 평가 방식의 경우, max length가 정해져 있음
-
metric의 대부분이 평가시에 reference text만을 사용
-
LM 기반 모델들은 매우 느려질 수 있고, 이는 모델 development단계에서의 응용을 저해함
- 그래서 이러한 단계에서는 ROUGE를 사용하지만, subdoptimal modeling으로 빠질 수 있음
-
본 논문에선 automatic metric SMART(Sentence MAtching for Raring Text)를 제안
- 길고 여러 문장인 텍스트를 잘 다루기 위해, matching시 basic unit을 token이 아닌 sentence로 사용
- 0과 1사이의 값이 나오는 soft-matching function을 사용
- ROUGE와 유사하게 N에 따라 다양한 SMART버전의 평가 지표가 존재
- SMART with BLEURT는 모든 차원에 대해서 뛰어난 성능을 보여줌
- SMART with string-based matching function의 경우, 속도가 빠르고 별도의 자원이 필요하지 않음에도 기존의 model-based metric과 견줄만한 성능을 냄
- 또한, SMART는 더 긴 요약에 대해 뛰어나고, 특정 모델쪽으로의 biased가 덜함
-
Related Work
Strinb-based Text Evaluation
- ROUGE
- BLEU
Model-based Text Evaluation - BERTScore
- MoverScore
- BLEURT
- BARTScore
Factuality in summarization - NLI based approaches
- model-based approaches
- QA based approaches
Problem Definition
- : list of source document
- : list of summaries generated for by a candidate system
- : list of reference summaries produced by human annotators for
- : list of dimensions of summary quality
- : list of human-annotated scores for in temrs of a certatin summary quality (each )
- : outputs a list of scores that correlates well with
- list of summary quality
- Coherence : The summary should be well structured and well-orgainzed. The summary should build from sentence to sentence to a coherent body of information about a topic
- Factuality : The summary should only contain statements that are entailed by the source document
- Fluency : The summary should have no formatting problems, capitalization errors or obviously ungrammatical sentences
- Informativeness : The summary should include only important information from the source document
Sentence Matching for Rating Text
- sentence를 reference summaries와 system summaries사이의 matching basic unit으로 사용
- 문장의 경우 완전히 일치하는 경우가 드물기 때문에, soft mathcing function을 사용
- SMART는 candidate summary와 reference summary, source document 모두를 고려해 점수 계산
SMART-N
- 기본적으로 summaries를 문장 단위로 쪼개서 사용
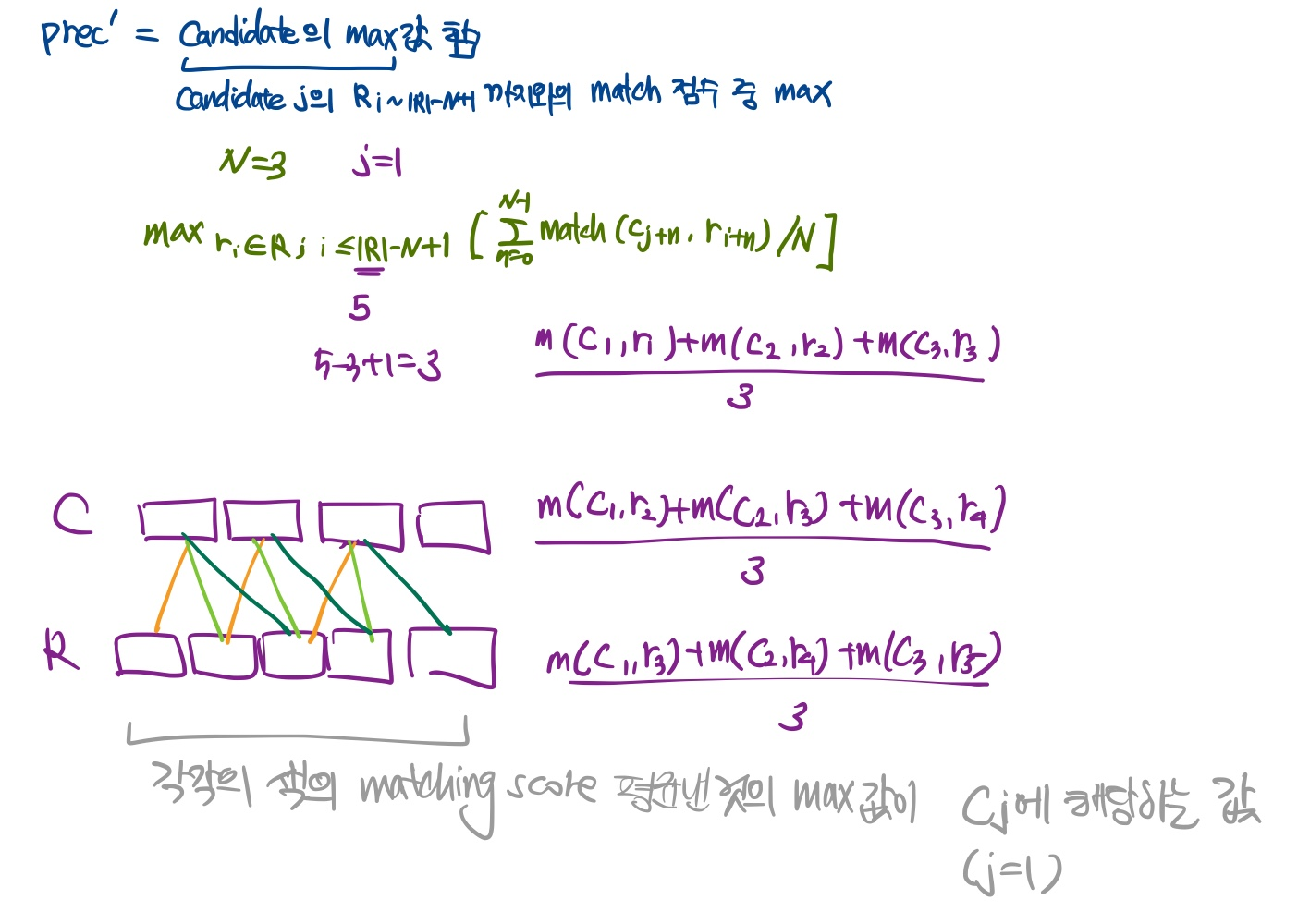
- SMART-N은 sentence macthing functino이 주어졌을 때 가장 높은 matching score를 가지는 과 사이의 sentence n-gram의 쌍을 찾음
- 문장 n-gram에서 문장의 수로 N을 사용하고, SMART-M은 다음과 같이 계산 가능

직관적으로 안 와닿아서 생각해봤을 때,
prec'만 생각해보면 prec'는 candidate의 max matching score의 합이고, 각각의 는 r과 1:1매칭을 해서 나온 matching score의 N개를 평균 냈을 때 가장 큰 값을 택하는 것.
즉, ref 문장 3개가 비슷한 내용에 대한 요약이고, cand 문장 3개도 비슷한 내용에 대한 요약이라면 둘의 위치가 유사하지 않아도 어차피 최대값을 택할 것이니까, 이에 대한 matching score는 크게 나올 것. (해석이 잘못 이상하다면 댓글 남겨주세요!)
SMART-L
-
ref 요약과 candidate 요약에서 문장들의 Longest Common Sumbsequence(LCS)
-
원래 LCS와의 차이가 있다면, exact match가 아닌 soft match사용
-
Find two soft-subsequences and of length with and -
normal subsequences와 달리, soft-subsequences는 이전 문장으로는 돌아갈 순 없지만 sentences의 반복은 허용(덕분에!)
-
이렇게 허용한 이유는, 한 문장 내용이 다른 요약문에선 여러 문장에 걸쳐서 나올 수 있기 때문

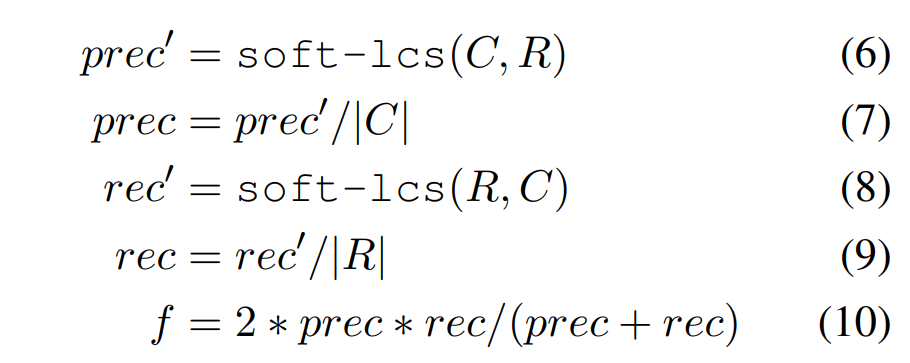
Comparing with Source
- SMART는 candidate system을 reference summary와 비교할 뿐만 아니라 source document와도 비교!
1) candidate system summary 와 reference summary 비교
2) candidate system summary 와 source document 와 비교
3) 이 두 점수 중 큰 값을 최종 score로 사용

Multiple References
- 각 reference에 대해서 SMART를 계산한 뒤, 최대값을 최종 점수로 사용
- 직관적으로 봤을 때, candidate system summary는 최소 하나
reference summary와 맞으면 되기 때문
Shorter Acronym
- SMART의 여러 변형을 표기하기 위해 다음과 같이 씀
여기서 m은 matching function을 의미
ex) SMART-1 with a BLEURT는 S1-BLEURT라고 씀
Sentence Matching Functions
-SMART는 sentence matching function에 따라 다양한 버전을 만들 수 있음
- NMT와 summarization에 널리 사용되는 6가지 sentence matching functnions을 실험
- string-based
- ROUGE : It measures the number of overlapping textual units
- BLEU : It is a precision-focused metric that calculates n-gram overlap between two texts and also includes a brevity penalty
- CHRF : It calculates character-based n-gram overlap between system and reference sentences. It is more effective especially in morphologically-rich languages
- model-based
- BERTScore : It computes similarity scores by alignming tokens from reference and candidate summaries, and token alignments are computed greedily to maximize cosine similarity
- T5-NALI : It used T5 finetuned on the ANLI dataset to produce a score between 0 and 1. We use the source/reference as premise and the candidate summary as hypothesis
- BLEURT : It uses BERT that is trained to predict human judgment scores using a small-scale dataset. To make it more robust, the model is first pretrained with a large-scale synthetic dataset. Moreover, It is optimized using several objectives including ROUGE, BLEU, BERTScore, and entailments.
- string-based
Experiments and Results
Experimental Setting
Dataset and Evaluation
- SummEval : a document summarization meta-evaluation suite consisting of summaries form the CNN/DM dataset
- Annotation은 2단계로 매겨짐
- 100개의 데이터에 대해 16개의 모델이 생성한 1600개의 요약문에 대해서 각 text qauilty aspect에 1~5점 사이의 점수를 매김
- 각 데이터는 또한 11개의 reference summaries를 가짐 : CNN/DM dataset에 원래 있던 정답 요약문 + 10명의 사람이 직접 작성한 요약문
- 평가를 위해서, 각 시스템의 점수를 평균내고, 이를 바탕으로 Kendall tau를 사용해서 system-level correlation을 계산
SMART with Different Matching Functions
- 우선 6가지 다양한 matching function을 서로 비교하는 실험을 진행
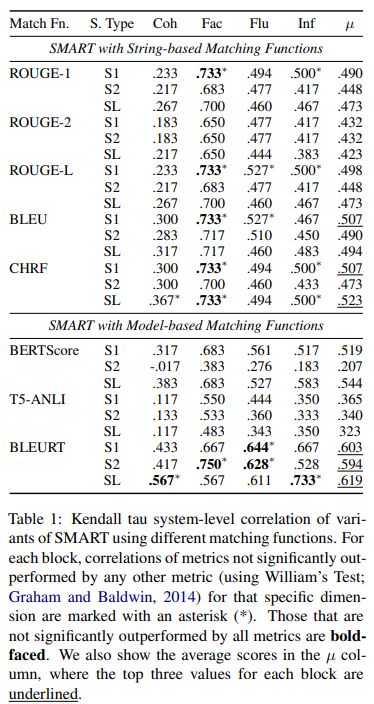
- 각각의 coh, Fac, Flu와 Inf는 coherence, factuality, fluency, informativeness를 의미
- string-based matching function에서는 CHRF가, model-based matching function에서는 BLEURT가 가장 우수한 성능을 보임
- 그 이유는 논문에 따르면 BLEURT가 문장이 일치하는지에 대한 학습 뿐만 아니라 다양한 ROUCE, BLEU, BERTScore, entailment scores까지 예측하도록 최적화되었기 때문이라고 추측
- 특이한 점은 T5-ANLI를 matching function으로 썼을 때, factuality부분에서 가장 성능이 떨어짐
- 그 이유는 논문에서 문장을 넣을 때 주변 맥락 없이 matching function에 태웠기 때문이라고 추측
SMART Compared to Other Text Evaluation Metrics
-
3가지 종류의 SMART를 비교 - string-based, source-free, source-dependent model-based
-
String-based metrics
- ROUGE 1/2/L : reference와 output summaries사이의 token 단위의 overlap을 측정
- BLEU : precision에 초점을 두고 referece와 output summaries간의 token단위의 overlap으 측정
- CHRF : reference와 output summaries사이의 문자 기반의 n-gram의 overlap을 측정
- S1/2/L-CHRF : string-based matching function을 사용한 최고 성능의 SMART metric
-
Source-free model-based
- BERTScore : BERT모델을 기반으로 토큰 수준의 유사도 점수를 계산해서 aggregate
- MoverScore : Word Mover's Distance를 사용해서 reference와 candidate summaries의 BERT n-gram 임베딩사이의 의미적 거리를 측정
- BLEURT : gold/silver-standard human judgment scores를 가진 real and synthetic training data을 합쳐서 BERT를 finetune
-
Source-dependent model-based metrics
- PRISM : leverages a zero-shot paraphrasing model and uses probailites from force-decoding the candidates summary given the source as input
- : question generation과 question answering모델을 사용해서 원문을 기반으로 생성한 질문을 요약문으로 답할 수 있는지(entail되는지) 확인
- T5-ANLI : 원문을 premise로 요약을 hypothesis로 주어질 때 entailment score를 계산하도록 T5를 ANLI dataset으로 파인튜닝
- BARTScore : evaluates text using probailities from force-decoding the candidate summary given the source as input using BART without finetuning with CNN/DM summarization dataset
- BARTScore+CNN : evaluates text using probailities from force-decoding the candidate summary given the source as input using BART with finetuning with CNN/DM summarization dataset
- S1/2/L-BLEURT : Table1에서 최고 성능을 기록한 model based matching function을 사용한 SMART metric
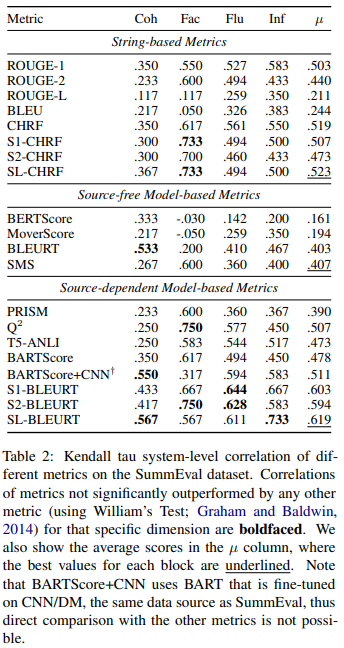
-
SMART with BLEURT matching function은 가장 높은 correlation을 보임
-
SL-BELURT는 coherence와 informativeness에서 뛰어남
-
S1-BELURT와 S2-BELURT는 factuality와 fluency에서 각각 뛰어남
-
평균적으로 SL-BLEURT가 가장 좋은 성능을 보임
-
다양한 quality dimension에 대해 뛰어난 SMART버전이 다르므로 여러개를 사용하는 것을 추천
-
source-dependent metrics이 source-free보다 뛰어남
- 즉, 요약문을 평가할 때 원문을 사용하는 것이 중요!
-
또한, SMART의 경우 기존의 LM-based metrics보다 pretrained language models를 사용하지 않아도 견줄만한 성능을 보임
Ablation Studies
-
SMART-X : SMART-1, SMART-2, SMART-L을 평균낸 것
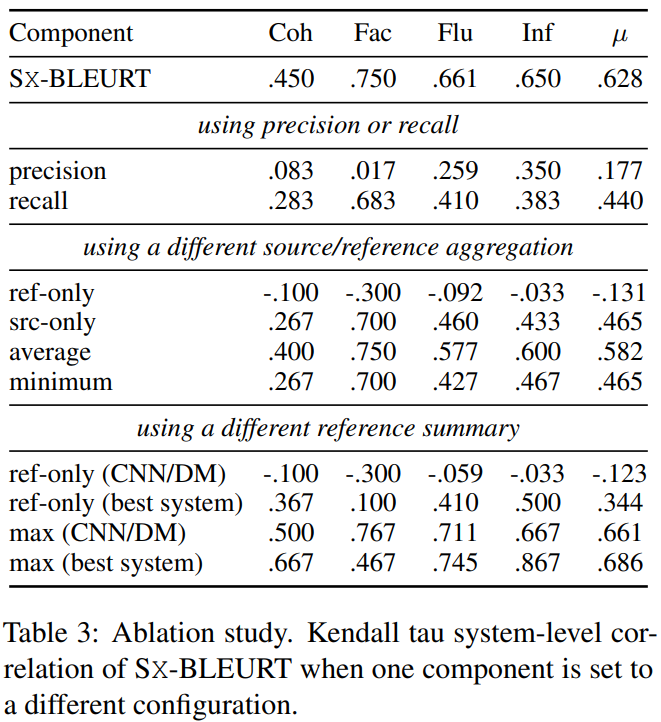
-
compare SMARTs using precision or recall only(첫번째 블록)
- precision이나 recall만 사용한 SMART-X이 f-measure를 사용한 것 보다 훨씬 낮은 system-level correlation을 보임
-
candidate summaries를 비교하는 SMART score를 aggregate하는 다양한 방법 비교(두번째 블록)
- reference or source만 사용할 때 SMART의 점수가 크게 나빠짐
- 즉, source와 reference를 둘다 사용하는게 SMART에선 필수적!
- aggregation방법으로 average, minimum 등을 사용해봤지만 maximize하는게 제일 좋았음
- 특이한 점은 reference summaries만 가지고 SMART를 계산했을 때 모든 차원에서 음수가 나온 것
- CNN/DM의 정답 요약문은 사람의 평가 관점에서 모델이 생성한 요약문보다 좋지 않음
- reference or source만 사용할 때 SMART의 점수가 크게 나빠짐
-
다양한 reference summary를 사용해서 평가(세번째 블록)
- SummEval의 reference summaries를 CNN/DM의 원래 summaries로 교체 --> 표에서 CNN/DM
- human score가 가장 높은 best system summary(generated summary)를 reference summary로 사용 --> 표에서 best system
- 결과를 보면, ref-only(CNN/DM)의 경우 음수가 나옴
- reference로 best system summary을 사용했을 때, 모든 차원에서 양수의 상관관계를 얻음
Further Analyses
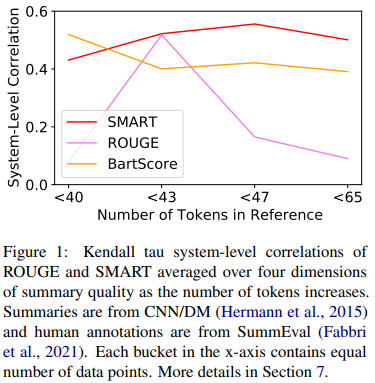
SMART Works Well with Longer Summaries
- reference summary에 있는 평균 토큰의 수를 기반으로 데이터셋을 4개로 나눠서, 첫번째 bucket에는 가장 짧은 reference summaries를 가진 데이터로 구성
- 각 bucket에 대해서 모든 비교 metric의 system-level correlation을 계산

- 모든 metric이 ROUGE에 비해 43개 토큰보다 긴 요약문에 대해선 뛰어남
- 즉, ROUGE는 긴 요약문을 평가하는데에 있어 적합하지 않음
- ROUGE는 또한, 첫번째 bucket에서 가장 낮은 성능으 보이는데, 이는 ROUGE가 짧은 요약문을 평가하는데에도 적합하지 않다는 것을 의미
- 비교 metric중에서 SX-BLEURT가 전반적으로 뛰어난 성능을 보임
SMART is Less Biased towards Specific Models
- 각 quality dimension에 대해 다양한 요약 모델을 가지고 automatic metrics과 사람이 매긴 점수와의 ranking차를 시각화
- 이를 통해, metric이 특정 모델에 bias가 있는지 확인 가능
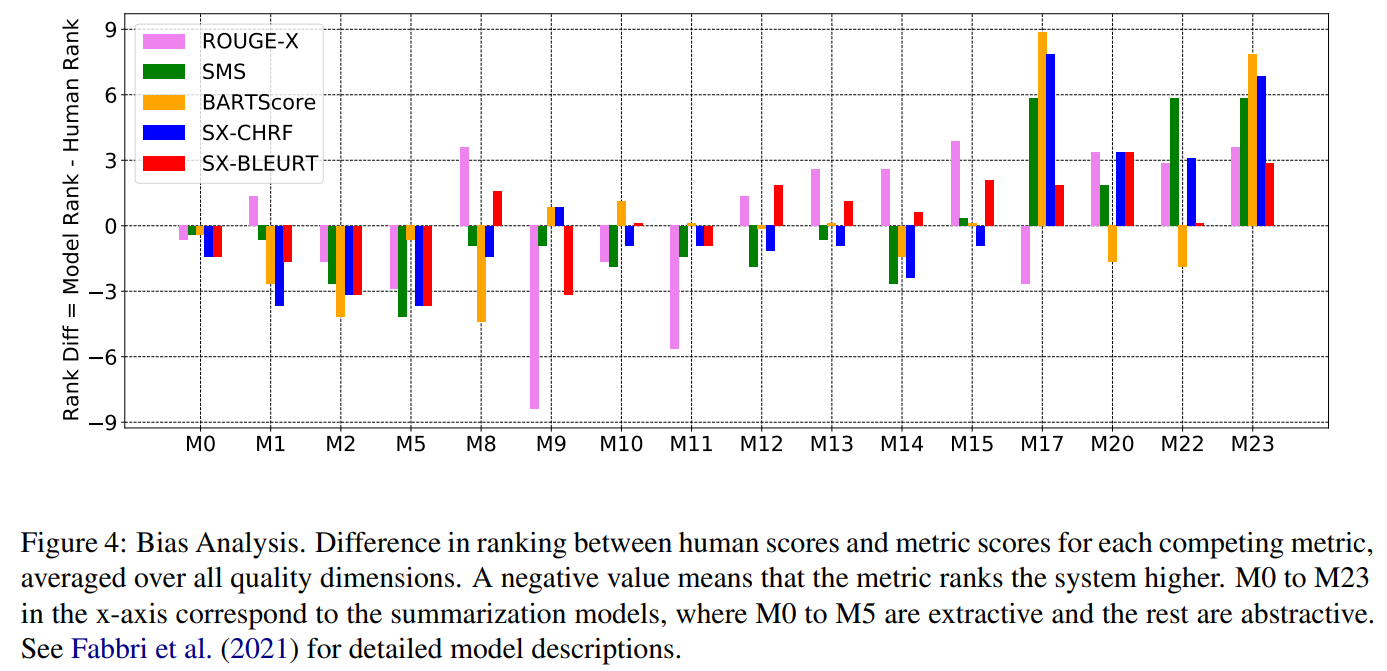
- 모든 metric은 일반적으로 extractive system을 높게 평가하는 경향이 있음
- 현재의 automatic metric으로 평가할 때 extractive와 abstractive model을 분리해서 비교할 필요가 있음
- BARTScore가 BART를 굉장히 높게 평가함
- 요약문 평가할 때 을 pretrained encoder-decoder 모델을 사용하면 같은 모델로 finetune한 ㅇ약 모델 쪽으로 bias가 생김
- SX-BLEURT가 human score와 rank가 0에 가깝기 때문에 가장 biased가 덜하다는 것을 볼 수 있음
- 이 결과가 맞는지 수치적으로 측정하기 위해 rank difference의 표준편차와 pairwise ranking accuracy를 사용.

- 표4를 보면, SX-BLEURT가 가장 낮은 표준편차를 갖고 있고, 모든 quality dimension에 대해 가장 높은 pairwise rank accuracy를 가진다는 것을 알 수 있음
==> 진짜로 이 metric이 가장 적은 bias를 가지고 있다!
- 이 결과가 맞는지 수치적으로 측정하기 위해 rank difference의 표준편차와 pairwise ranking accuracy를 사용.
Conclusion
- SMART는 문서 요약을 평가할 때 summary quality의 4가지 모든 측면에서 뛰어남
- SMART는 요약문의 길이가 길어짐에 따라 나은 성능을 보이고 가장 덜 biased된 평가를 함
- 실험 결과를 바탕으로, SMART[1|2|L]-BLEURT를 사용하는 것을 추천
- 빠른 평가를 위해서는 SMART[1|2|L]-CHRF를 사용하는 것을 추천
