본 논문은 2022년 5월에 ACL에 실린 논문으로, textcnn의 저자인 Yoon Kim님이 2저자인 논문입니다.
Abstract
-
pretrained transofrmers based langauge generation models의 fine-tuning은 모델이 스스로 연관있는 input의 일부를 attend하는 방식으로 학습
-
하지만, 모델의 어디에 집중할지를 직접적으로 컨트롤하는 방법은 존재 X
-
그래서 본 논문에서는 유저가 모델이 집중해야하는 부분을 선택해 highlights해 모델이 관련된 output을 만들어내는 control mechanism을 개발하는 것을 목표로 함
-
이를 위해, 학습가능한 "focus vector"(모델의 임베딩에 직접 적용할 수 O)를 가진 사전 학습 모델을 제안
- 이러한 벡터들은 문맥 중요도에 대한 indicator로 작동
-
모델을 테스트하기 위해 2가지 생성 태스크를 사용 : 대화 응답 생성 & 생성 요약
- 데이터는 사람에 의해 표기된 highlight-generation pair가 표시된 평가 데이터 수집
-
실험 결과, trained focus vectors는 유져가 선택한 highlight에 관련한 결과를 생성하도록 모델을 유도하는데 효과적이었음
1. Introduction
-
attention module은 단어 단위의 임베딩에 대해 가중 평균을 통해 정보를 통합해 모델에서 중요한 역할을 한다.
-
어텐션 메카니즘은 2가지 중요한 목적이 있다
- 입력의 linguistic phenomena를 포착
- 모델이 input의 관련 부분에 집중하도록 함
-
하지만 어텐션 메타니즘은 어느 부분에 집중할지 스스로 학습하기 때문에, 유저가 중요하다고 생각하지 않는 부분에 모델이 집중할 경우 이를 고쳐줄 방법이 없음
==> 그래서 유저가 픽한 input span과 관련된 결과를 생성하도록 모델을 조종해보자!가 목표 -
하지만 문제는 대부분의 유명한 NLG 데이터셋은 end-to-end방식으로 수집된다. 즉, 입력값의 어느 부분이 reference target과 가장 관련됐는지 표기되어 있지 않음. + 제안된 방법도 기존의 사전학습된 트랜스포머 모델이랑 양립할 수 있어야 최고.
-
본 논문에선, 위의 문제를 다루는 focus vector framework를 제안.
우리의 contribution은 다음과 같다- 모델의 focus를 컨트롤하기 위해, 학습가능한 focus vector가 있는 사전 학습된 모델을 제안. 이 벡터는 인코더 임베딩에 바로 적용되고, 모델은 고정된 상태로 보존
- focus vector를 학습하는 것은 추가 annotation을 요구하지 않음. 존재하는 end-to-end training data로부터 자동적으로 highlight annotation를 이끌어내는 attribution method를 활용.
- 이러한 방향의 평가와 향후 연구를 위해 사람이 annotation한 평가 데이터를 수집해 공개
- 2가지 NLG task(대화 응답 생성과 생성 요약)에 대해 본 논문의 모델을 테스트 : 실험 결과, trained focus vector는 하이라이트가 주어질 때 관련된 결과값을 생성하도록 모델을 조종하는데 효과적
2. Model Formulation
- 타겟 모델은 이미 task-specific data에 NLL로 finetuned된 standard pretrained transformer encoder-decoder model를 가정.
- 중요한 점은 이 메카니즘이 기본 모델을 바꿔선 안됨, 나중에 유저가 원할 때 default로 돌아갈 수 있도록 하기 위해!
- notaion
- : end-to-end training data
- : input token sequence // : corresponding reference target token sequence
- : binary indicator, input token is to be highlighted during generation
- 본 모델에선 오직 완전한 문장의 집합을 valid hightlight span으로 가정.(데이터 수집 용이성 및 구 단위 highlight에도 쉽게 일반화할 수 있을거라 판단)
- encoder model이 L개의 transformer layer로 구성되어 있다고 가정
- : l번째 인코더 레이어에서 i번째 위치의 d차원의 결과 임베딩
- : input embeddings
- 각 decoder layer는 encoder의 결과에 대한 multi-head cross attention사용. 이 때 l번째 decoder layer에서 h번째 head에 대한 attention weight computation은 다음과 같이 쓸 수 있다
- : linear transform
- : decoder query vector 에 대해 encoder output 에 할당된 attention weight
- : 원래 target model에서 input x가 주어졌을 때 y에 할당되는 확률
- 우리가 제안하는 모델은 크게 2단계를 포함하고 있다.
- automatic highlight anotations using attribution method
- these annotations are used to train the focus vectors
2.1 Attribution Methods
-
saliency map으로도 알려져 있는 Attribution methods는 모델의 예측을 입력 특징에 귀속시킨다.
-
대부분의 saliency method는 원래 이미지 분류를 위해 설계되었는데, input feature의 각 차원에 대해 importance score를 할당하는데 사용되었다.
-
언어 데이터에 적용하기 위해 약간의 수정(ex. dot-product with the word embeddings)을 거친다.
-
target y와 model 에서 sentence (denoting the set of token indexes in the sentence)가 주어질 때, attribution score를 계산해 여러 유명한 attribution method를 구현하고 비교한다.
- Leave-one-out(LOO) : S의 토큰을 token으로 교체하고, NLL관점에서 차이르 ㄹ계산
- Attention-weight : S에 속한 toknes에 대한 모든 decoder layer의 모든 attention head에 배정된 attention weight를 합함
- Grad-norm : S에서 input word embedding에 대한 gradient norm의 합
- Grad-input-product : input embedding과 각 gradient사이의 내적을 계산
- Leave-one-out(LOO) : S의 토큰을 token으로 교체하고, NLL관점에서 차이르 ㄹ계산
-
attributin methods는 black-box model를 해석하는데 사용된다 - 모델의 focus를 컨트롤하기 위해 추가로 사용할 수 있는 label를 유도하는 것은 본 논문이 처음임!
-
실험에서 LOO가 human annoation dataset에서 가장 좋은 상관관계를 가지고 있다는 것을 알아냄
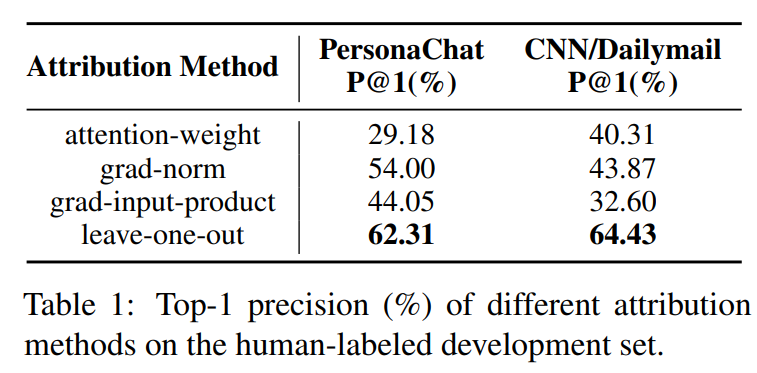
-
그래서 automatic highlight annoations을 하기 위해 LOO를 사용
- input-ouput pair에 대해, input문장들의 LOO attribution scores을 내림차순으로 정렬해서, 앞에서 몇 개의 문장들의 토큰에 마킹(task마다 highlight하는 문장 개수는 다름)
- 그래서 위의 방법으로 얻은 highlight label을 binary indicator variables 으로 표시
2.2 Focus Vectors
-
모델의 focus를 제어하기 위해, focus vector인 d차원의 벡터 를 사용
-
모델에 indicator로 작동하고, input의 어느 부분에 집중해야하는지를 보여줌
-
학습 데이터셋이 로 구성되어 있다고 가정
- 여기서 은 위에서 설명한 방법대로 구함
-
focus vector는 각 레이어의 output embedding에 대한 간단한 transformation을 적용해encoder model의 forward pass를 수정
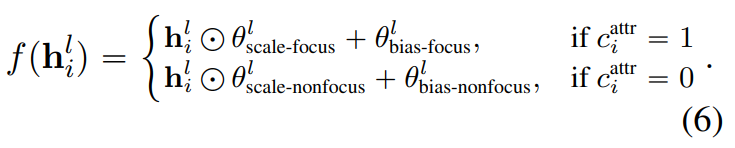
-
아래 그림을 보면, focus-vector에 의해 사용된 파라미터의 수는 4x(L+1)xd개 이고, 이는 고정된 트랜스포머 모델의 파라미터 수와 비교해봤을 때 무시할만한 수준이다.
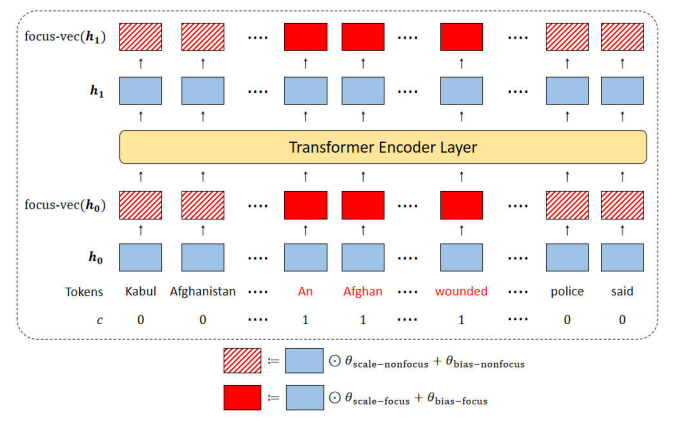
-
focus vector는 encoder embedding에 바로 적용되기 때문에, 모델에 외재적인 attention module이 있을 필요가 없으므로 LSTM과 같은 non-attentional architecture에도 적용가능하다.
-
우리는 SGD로 standard NLL loss를 사용해 focus vector를 학습한다.
이 때, 은 focus vectors가 적용된 후의 output에 대한 distribution을 의미한다.
-
focus vector를 학습하는 동안 모델의 파라미터는 고정된다.
-
loss 를 줄이기 위해, focus vector는 에 표시된 span쪽으로 model의 focus가 움직이도록 한다.
3 Evaluation Data Collection
-
본 논문에서는 2가지 NLG task에 대해 실험 : 대화 응답 생성과 생성 요약
-
Dialogue task에서, PersonaChat 데이터셋 사용
- open domain multi-turn chit-chat dataset
- 2명의 참가자가 chatting하면서 서로를 알아가는게 요구됨
- 각각은 주어진 persona가 있음 : 개인적인 정보 몇가지가 주어짐("I major in Coputer Science")
- 대화에서 각각 참여자는 배정된 persona를 반영해야 함
-
summarization에서 CNN/Dailymail dataset사용
- 기본적인 end-to-end abstractive summarization
-
두 데이터셋 모두 end-to-end로 만들어졌고, annotated highlight spans를 포함하지 않음.
-
원론적인 평가를 위해, AMT(Amazon Mechanical Turk) platform를 활용해서 인간 라벨링을 한 evaluation set를 제작
- PersonaChat의 경우, dialogue history와 persona를 보고 persona에서 하나 dialogue history에서 하나 선택하는 식으로 1-3문장을 highlight로 선택, 이후 higlight로 선택한 것과 관련되면서 현재 대화를 이어가는 대화 응답을 작성
- CNN/Dailymail의 경우, reference summary를 읽고 원문에서 이와 관련한 문장을 2-5개를 선택하도록 함(약간 extractive summary느낌.. 인듯)
- 최종적으로 PersonaChat에 대해선 3902, CNN/Dailymail에 대해선 4159개를 수집, 이를 반반으로 무작위로 나눠서 50/50으로 dev/test set으로 사용
Comparison of Attribution Methods
-
human-annotated highlight를 이용해 attribution method를 비교
-
특히, 우리는 표1에서 처럼 가장 높은 랭킹인 문장의 top-one precision을 계산
-
PersonaChat과 Cnn/Dailymail 둘다에서 LOO가 best alignment였음
==> LOO를 사용해서 focus vector training을 위한 automatic annotation을 얻음 -
attention weight derived attribution scores과 human judgment사이의 low alignment를 봤지만, 이것이 attention ditributions에 개입을 통해 모델 생성을 통재하는 것이 최적이 아닐 수 있음을 보임.(높아봐야 62정도니까..? 하지만 이게 안되면 이 논문은 의미가..?)
4. Experiments
4.1 Experiment Setting and baselines
-
PersonaChat에 대해선 Blenderbot을 CNN/Dailymail에 대해선 BART를 기본 모델로 사용
- Blenderbot은 2개의 encoder와 12개의 decoder layer로 구성되지만, BART는 6개의 endoer와 6개의 decoder로 구성됨.
- Blenderbot의 position embedding index를 128에서 256으로 늘림.
- Decoding에서 beam-search를 사용하였는데, Belnderbot에선 10, BART에선 4를 사용
-
각 모델 파인튜닝 후에, LOO를 사용해 자동으로 PersonaChat에선 1-3개 문장, CNN/Dailmail에선 2-5개 문장을 highlight를 한 학습 데이터셋을 사용
-
4가지 focus-vector approach를 비교
- Vanilla : input과 model 둘다에서 어떠한 수정도 하지 않은 모델
- Padding : highlight외에 모든 input을 토큰으로 교체해 모델의 focus를 통제하는 방법. 그러나 이 방법은 perplexity를 급격하게 낮춤
==> 그래서 기본 end-to-end finetuning하는 동안 input에서 문장의 일부분을 무작위하게 padding처리함(모델이 오직 input의 부분만 보고 인지하도록) - Keyword-control : 모델 finetuning시, Yake라는 비지도 keyword extraction method를 활용해 reference sequence에서 추출한 key-phrases를 원래 input으로 선행시킴. 평가 동안, 우리는 highlighted sentences에서 추출된 key-phrase를 추출하고 preprend한다.(이해 못함)
- Attention-offset : 모델의 attention을 통제하는 직접적인 방법으로, 양의 스칼라 offset 을 softmax operation전에 cross-attention head에 더함.
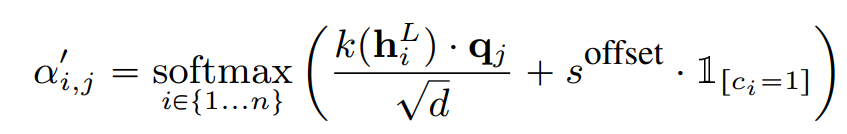
- 은 하이퍼파라미터로, 디코더의 모든 cross-attention head에 적용됨
4.2 Results and Analysis
-
평가 동안, human-annotated highlight가 모델로 들어감
-
평가 지표 : perplexity, ROUGE, BERTScore
-
실험 결과
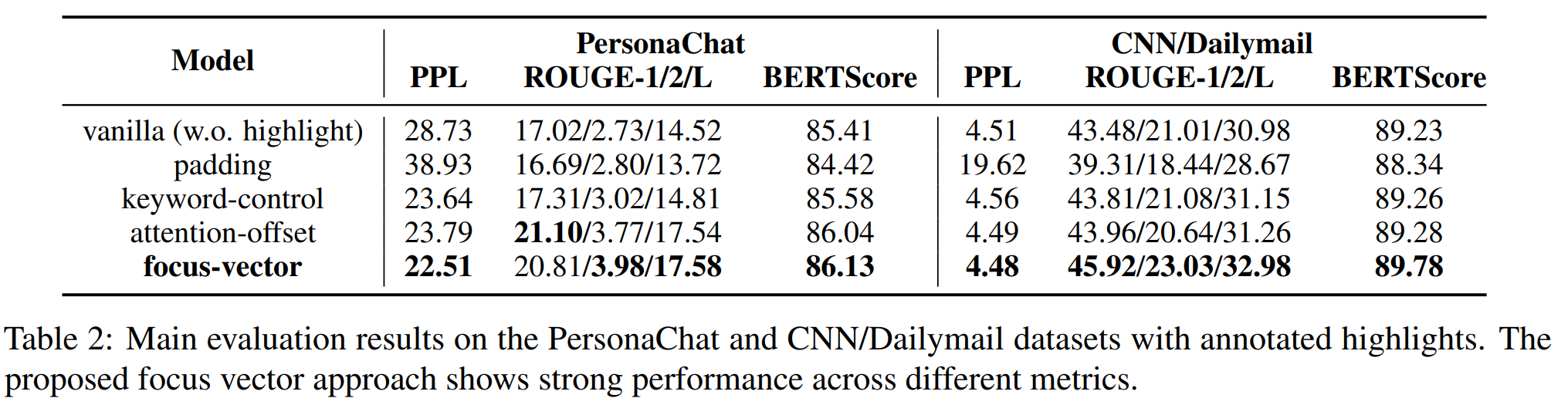
-
padding baseline은 성능 안좋음(입력의 대부분이 마스크로 날라가니까)
-
다양한 베이스라인을 비교했을 때, 두 태스크 모두에서 ROUGE, BERTScore가 크게 증가
-
이는 focus-vec이 모델을 조종하는데 효과적이고, 원하는 방향으로 생성을 이끌어낼 수 있다는 것을 의미
-
CNN/Dailymail에 대해선 focus-vector의 perplexity가 vanilla model과 유사했다(단 ROUGE는 큰 차이가 남)
-
key-phrases는 vanilla model보단 낫지만, attention-offset이나 focus-vector보단 안좋았다.
저자는 그 이유로,
1) key-phrases는 highlighted span을 완전히 표현할 수 없다
2) training과 evaluation사이에 추출된 key-phrases의 불일치 를 뽑았다. -
focus-vector와 attention-offset사이에서 ROUGE와 BERTScore의 성능 갭은 CNN/Dailmail dataset에서 더 컸다.
=> BART가 Blenderbot model보다 더 깊은 인코더를 가지고 있기 때문으로 추정 / 인코더가 깊을수록 임베딩이 더 가까워지고, identifiability가 감소한다. 결국 인코더의 마지막단을 디코더가 attent하기 때문에, 이런 직접적인 attention weight 조작이 딥 인코더에선 효과적이지 않을 수 있다. -
PersonaChat에서 다양한 focus-control approaches들이 샘플을 생성하는 예시를 보여주고 있다.
highlights와 관련된 생성 부분이 빨간색으로 표기 됨

-
