Abstract
- 원문 기반 텍스트 생성은 factual inconsistency라는 치명적 단점 존재
- factual inconsistency는 생성문이 원문과 맞지 않는 사실 또는 존재하지 않는 사실을 내포하는 것을 의미
- 그래서 최근에 다양한 factual consistency evaluation 기법이 등장
- 하지만 이러한 기법은 하나의 태스크 또는 데이터셋에 맞춰서 개발되어 적용하기 어려움
- 또한 system-level에서 사람 annotation과의 상관관계에 초점
==> example-level에서 accuracy는 분명하지 않음
- 이러한 문제를 해결할 수 있는 데이터 단위의 evaluation protocol이 가능하게 표준화 ==> TRUE!
1 Introduction
-
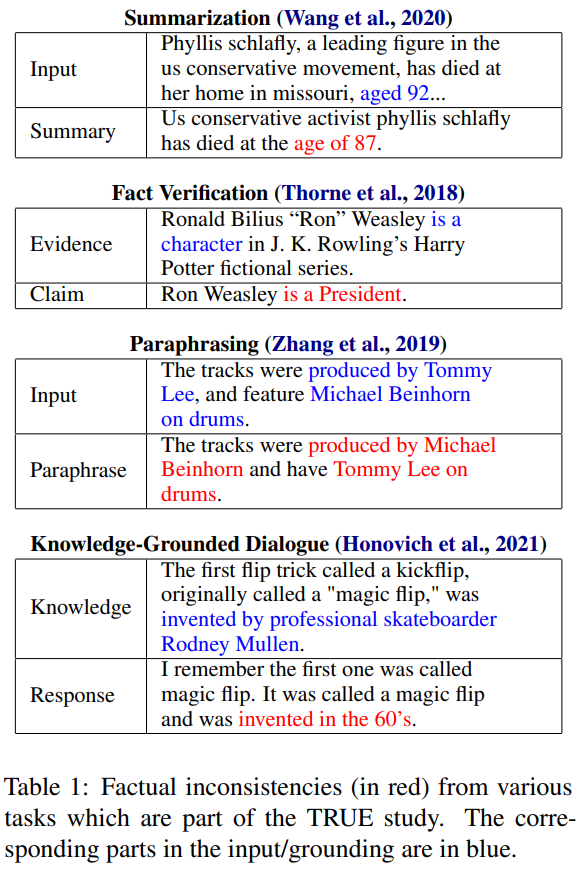
텍스트를 생성해야하는 task에서 다음과 같은 factual inconsistency가 발생

-
이러한 문제를 해소하기 위해, 자동적으로 생성된 텍스트가 각각의 원문에 대해 factually consistent한지 예측하는 방법을 고안 중.
=> 이러한 방법은 평가도 더 잘 할 수 있고, 자동적으로 학습 데이터를 필터링하거나 제한된 생성에 대해 학습 데이터를 생성함(정확히 뭔지 잘 모르겠음 / Rashkin et al. 2021b)으로써 생성 모델을 더 좋게 만듦 -
하지만 이러한 평가 방법들에 대해 평가하는 meta-evaluatation protocol이 합의되지 않았고, 라벨링 스케마 역시 세분화 되지 않음
=> 그래서, 이러한 방법의 robustness를 비교하는 것은 어려움 -
그래서 TRUE : a comprehensive survey and assessment of factual consistency evaluation methods, metrics, tasks and datasets을 제시
- 11개의 데이터셋을 통일된 포맷으로 정리
- target text - grouding source text - binary annoation of whether the garget text is factually consistenct w.r.t its source
- summarization, knowledge-grounded dialogue, paraphrasing and fact verification까지 커버
=> 이를 통해 다양한 태스크 및 도메인에 대해 robust하게 consistency evaluation method를 적절히 평가할 수 있다!
- 11개의 데이터셋을 통일된 포맷으로 정리
-
원래는 메트릭의 성능을 평가하기 위해 사람이 판단한 데이터와 system-level에서 상관관계가 얼마나 있는지를 측정
-
하지만 이 방법은 example-level에서 판단을 할 때는 유용하지 않음.
==> 그래서 방법이 얼마나 inconsistenct text를 잘 찾아내는지(recall), consistent한 text를 얼마나 잘못 분류하는지(precision)에 대해 측정하는 것을 목표로 함!
==> 그래서 ROC AUC를 사용할 수 있음.
Contribution
1. factual consistency evaluation을 task, dataset에 관계없이 일반화
2. 이전 상관관계를 측정하는 것보다 더 범용성이 높고 해석가능한 질적 측정이 가능한 meta-evaluation protocol을 제안
3. 12개의 다양한 메트릭에 대해 조사하고 평가. large-scale NLI와 QG-QA-based 방법은 task에 구분 없이 강하고 보완적인 결과를 냄.
4. 실험 결과에 대해 정량, 정성적으로 평가해 long input, personal statements와 같은 문제를 향후 연구에서 다뤄져야 함을 강조
2. Standardizin Factual Consistency
2.1 Definitionas and Terminology
- factually consistent : 생성문의 모든 사실적 정보가 원문에 나타나있는 사실과 일관될 때
- real world의 correctness와는 관계없음
- 외부 지식이 아니라 input text에 나타난 정보만 고려
- factual information의 범주에서 opinions과 chit-chat과 같은 개인적이고 사회적인 서술은 배제
- 본 논문에서는 consistent, grounded, faithful, factual을 혼용하며 사용
2.2 Standarization Process
- 다양한 task에서 factual consisteny를 갖는 human annotations을 포함하는 11개의 데이터셋 포함
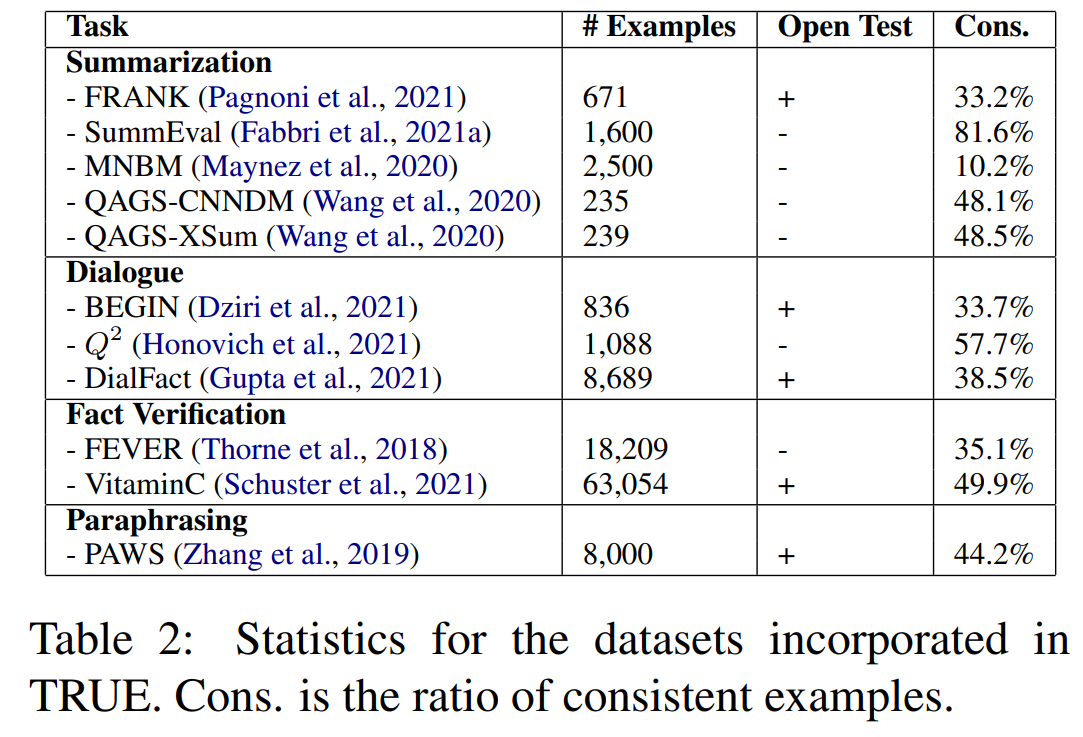
- unified evaluation framework을 만들기 위해 factually consistent에 관한 모든 표기를 binary label로 바꿈
2.2.1 Abstractive Summarization
- FRANK : CNN/DailyMail과 XSum에 대해 모델이 생성한 요약에 대한 annotation을 수집. 총 2250개의 annotated system output을 수집. 각 요약 문장은 3명의 annotator에 의해 라벨링 됨. 각 문장을 다수결에 따라 labeling하고 모든 문장이 consistent할 때만 요약문이 consistent하다고 표기.
- SummEval : extractive, abstractive 모델 둘다 사용해서 CNN/DM 데이터셋으로부터 100개의 기사에 대해 16개의 모델 output을 사람이 평가. Annotators는 4개의 차원(consistency, coherence, fluency, relevance)에 대해 1-5점을 부여. 각 요약문은 5명의 crowd-worker와 3명의 전문 annotator로 스코어링됨. 본 논문에선 요약문에 대해 모든 전문 annotators가 consistency점수를 5점 줬을 때만 consistent하다고 라벨링 함.
- MNBM : XSum에서 500개의 기사와 정답 요약문, 4개의 다른 시스템에서 생성된 annotated summary를 샘플링. Annotator들은 요약에 halluciation이 있는지 평가. 3명의 annotators에게 받은 평가가 각 데이터마다 수집됨. 이를 이진 포맷으로 바꾸기 위해, 3명의 annotator가 판단한 것의 다수결을 따라 배정.
- QAGS : CNN/DM과 XSum에 대해 생성된 요약문에 대해 factual consistency한지를 수집. annotators들은 한 번에 요약문의 한 문장과 원문을 받아서 이 문장이 factually consistent한지 평가. 각 문장은 3명의 annotator에게 라베링되고, 다수결이 최종 score가 됨. 이를 이진 포맷으로 바꾸기 위해서, 모든 문장이 consistent할 때만 요약문이 conssitenct하다고 판단.
2.2.2 Dialogue Generation
- BEGIN : knowledge-grounded dialogue system에서 groundedness를 평가하는 데이터셋. system output은 대화 상대에 제공되는 grounding knowledge에 반드시 consistent해야함. BEGIN은 task를 textual entailment와 같이 프레임화해서, 3가지 카테고리(hallucination, off-topic responses, generic reponses)를 내뱉음. 대화 응답은 Wizard of Wikipedia(WoW)데이터셋에 대해 파인튜닝된 2가지 system에 의해 생성됨. 생성된 응답을 문장 단위로 쪼개서 문장 각각에 대해 라벨링. 이진 라벨링으로 바꾸기 위해, entailed sentnece를 consistent로 나머지를 inconsistent로 처리.
- : WoW에 대해 학습된 2개의 dialogue model에 대해 생성된 1088개의 dialogue response를 annotate. 이미 이진 표기가 되었기 때문에 변환없이 사용.
- DialFact : 3가지 task를 정의 1) 응답이 berifiable content를 포함하고 있는가 2) 관련 증거 검색 3) 응답이 증거 기반인지, 증거에 의해 반박되는지, 아니면 판단하기에 충분한 정보가 없는지 예측. 3번째 task에 대해 annotated된 verificable response을 supported를 consistent로, 나머지를 inconsistent로 사용. verification을 위해서 3-4개의 증거가 표시된 경우, 모든 문장을 합쳐서 원문으로 사용.
2.2.3 Fact Verification
- FEVER : 원문에 대해 fact verification한 데이터셋. Wikipedia에서 정보를 추출해 구축, annotator을 사용해 claims을 생성. 각 claims에 대해 Wikipedia에 의해 반박되는지 지지되는지를 라벨링. NotEnoughInfo라고 라벨링 되는 경우도 존재. FEVER는 크게 2단계로 task정의. 1) evidence 추출 2) claim을 지지하는지 반박하는지 결정. 후자의 경우 claim이 factually consistent한지 아닌지를 결정하므로, TRUE에서 측정. FEVER의 NLI버전의 development set을 사용. supported를 consistent로, 나머지를 inconsistent로 라벨링
- VitaminC : 큰 스케일의 fact verification dataset. 각 데이터는 Wikipedia에서 evidience text와 fact, 그리고 fact가 지지, 반박, 중립 세개 중 하나로 라벨링 되어있음. 지지를 consistent로, 나머지를 inconsistent로 변환해 사용.
2.2.4 Paraphrase Detection
- PAWS : 108463개의 paraphrase와 non-paraphrase 쌍으로 구현된 데이터셋. 원문 문장은 Wikipedia와 Quora Question Pairs(QQP)에서 가져옴. 본 논문에서는 Wikipedia에서 온 데이터만 사용, paraphrase를 consistency label로 사용. paraphrase와 consistency는 다르지만, PAWS에서 non-paraphrases는 보통 원문과 반대되는 의미를 가지고 있도록 구축되었기 때문에 관련이 있다고 봄.
2.3 Meta-Evaluation
- 기존의 논문에서는 다양한 메트릭과 hhuman judgement와의 상관관계를 측정해 평가
- 데이터 단위에서 더 세분화된 평가를 위해서, 각각의 inconsistent example의 binary detection에 대해 ROC AUC를 보고
- ROC curve는 각 테스트된 메트릭에 대해 가능한 다른 임계값에서 true positive rate(recall)대 false positive rate(fallout)을 그래프로 표시
- ROC AUC를 측정하는 것은 측정 decision thredhold 세팅 없이 다양한 metric를 평가
- development/test split를 가진 데이터셋의 경우, dev에 대해서 binary consistent/inconsistent 결정을 위한 임계값을 조정하고 이 임계값을 사용해 test에 대해 정확도를 측정
- threshold를 TPR과 1-FPR의 기하 평균()을 최적화해 조정
3 Evaluation Metrics
- fatucl consistency를 측정하는 SOTA 방법 뿐만 아니라 다양한 기준들을 비교
- 예를 들어, robust한 평가지표는 여러 태스크에 구분 없이 잘돼야 함
- 각 메트릭에 대해, 점수가 [0,1]을 넘어갈 경우 normalize
3.1 N-Gram Based Metrics
- BLEU, ROUGE, token-level F1은 factual consistency와 낮은 상관관계 보여줌
- 이 방법들을 baseline에 추가
3.2 Model-Based Metrics
- BERTScore : 후보 문장과 정답 문장의 token을 BERT contextual embedding해, 둘의 유사도를 aggregates. BERTScore가 예비 실험에서 더 나은 결과를 보였기 때문에 보고.
본 논문에선 BERTScore version 0.3.11사용(DeBERTa-xl-NMLI model) - BLEURT : 텍스트 생성을 평가하기 위한 BERT기반 메트릭. BLEURT는 synthetic data에 대한 추가 pre-training + 점수를 산출하는 모델을 학습하기 위해 human judgement에 fine-tuning됨.
- FactCC : 요약문의 factual consistency를 검증하는 BERT기반의 지표. 룰베이스 기반의 변형을 적용해 consistent와 inconsistent summaries 데이터를 생성, 이에 대해 학습됨.
- BARTScore : BART모델로 강제 디코딩의 확률(probabilities from force-decoding)을 사용해 텍스트를 평가. 여기선 ParaBank2 데이터셋으로 파인튜닝된 버전을 사용.
- CTC : BERT sequence taging모델을 사용해 grounding text에 대해 genereated text의 token-level alignment의 평균을 측정. 이 모델은 준지도 학습 방식에서 BART model에 의해 생성된 hallucinate token를 찾아내도록 학습됨
3.3 Natural Language Inference Metrics
- ANLI : Adversarial NLI에 대해 T5-11B를 파인 튜닝한 NLI모델을 사용. grounding text을 premise로, 생성된 글을 hypothesis로 볼 entailment probaility를 계산. 이를 excample-level의 factaul consistency score로 사용.
- SUMMAC : NLI를 사용해서 문서와 요약문을 문장으로 쪼개고, 모든 문서/요약 문장 쌍에 대해 entailment probaility를 계산. 요약 문장에 대한 최대값 및 평균을 사용해 값을 합치거나() 점수를 집계하기 위해 컨볼류션 신경망을 학습시켜 모든 쌍에 대한 NLI점수를 집계(SCCconv)
3.4 QG-QA Based Metrics
QG-QA기반 방법은 다음과 같은 단계로 진행됨
- 생성된 글에서 span에 대해 자동적으로 질문이 생성됨
- 생성된 질문은 원문에 대한 QA모델을 사용해서 답변됨, answer span또는 no-answer값 반환
- 각각의 문장에 대해서, 원문과 생성된 글의 answer span을 비교해 점수 측정
- 모든 질문에 대한 점수가 합쳐져서 최종 점수가 됨
- : NLI모델을 각 질문에 대한 두가지 답을 비교하는 용도로 사용하는 QG-QA방법. 원문을 premise로 생성문을 hypothesis로 사용. backbone으로 T5-11B를 사용해 를 다시 re-implementation한 것을 바탕으로 결과를 보고. 본 논문에서는 사전 정의된 임계값과 F1-token-overlap을 사용해 추출된 답변 후보와 비교.
- QuestEval : factual consistency와 relevance를 모두 측정하는 QG-QA기반 방법. 저자는 생성된 텍스트에 나타나도록 생성된 각 질문에 대한 답변의 관련성에 따라 가중치를 부여하는 모델을 학습. SummEval에 대해 이전 연구보다 human annotation과 높은 상관관계 보여줌.
4 Results
-
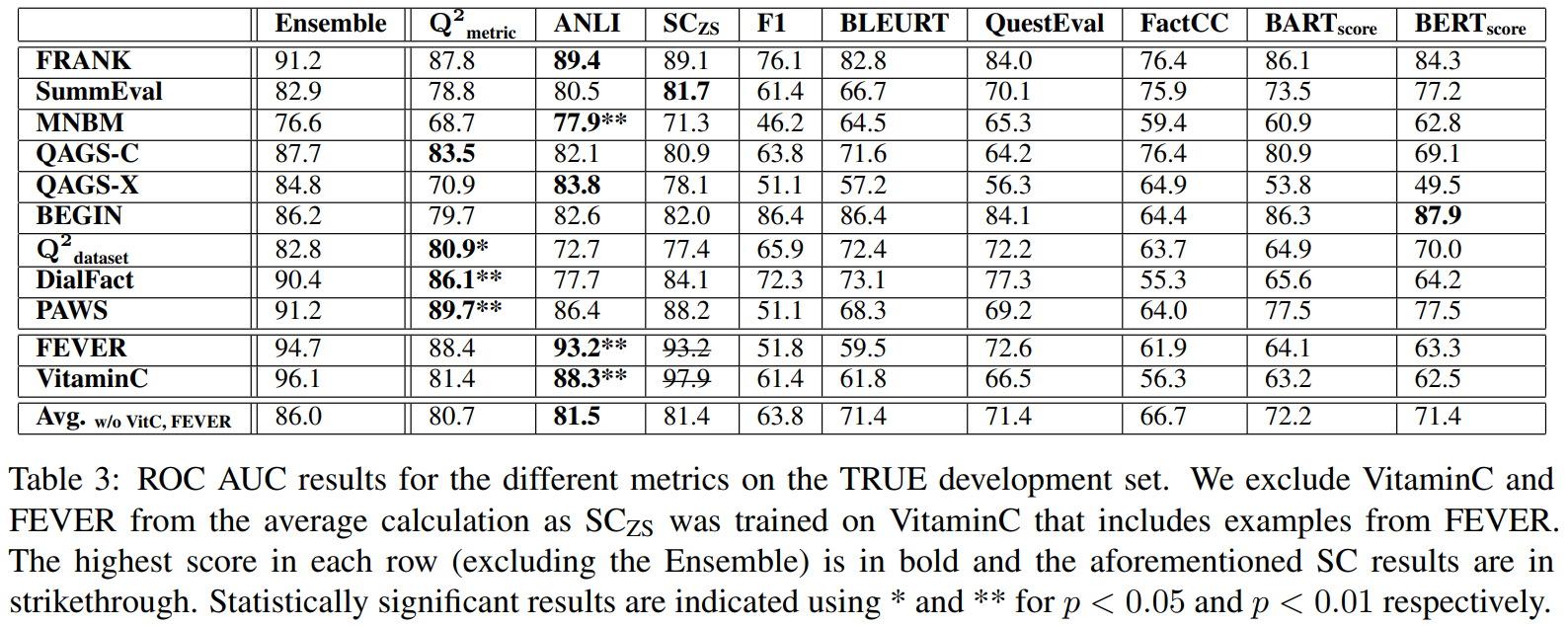
TRUE development set에 대해 다양한 메트릭의 ROC AUC 결과.
-
는 FEVER를 포함하는 VitaminC에 대해 학습됨. 그래서 정교한 비교를 위해 중복된 데이터셋을 배제하고 AUC평균을 계산.
-
NLI기반 모델(ANLI, )은 다른 방법보다 6개 데이터셋에 대해 뛰어남.
-
는 4개의 데이터셋에 대해서 뛰어난 성능을 보였고, 평균 AUC는 80.7
-
다음으로 좋은 방법은 BARTScore로 72.2의 평균 AUC를 보임
-
예상했던대로, 간단한 토큰 비교 방식은 잘 되지 않음
-
이상치 하나는 BEGIN으로, F1 overlap과 같은 간단한 메트릭이 80이상을 달성한 유일한 데이터셋
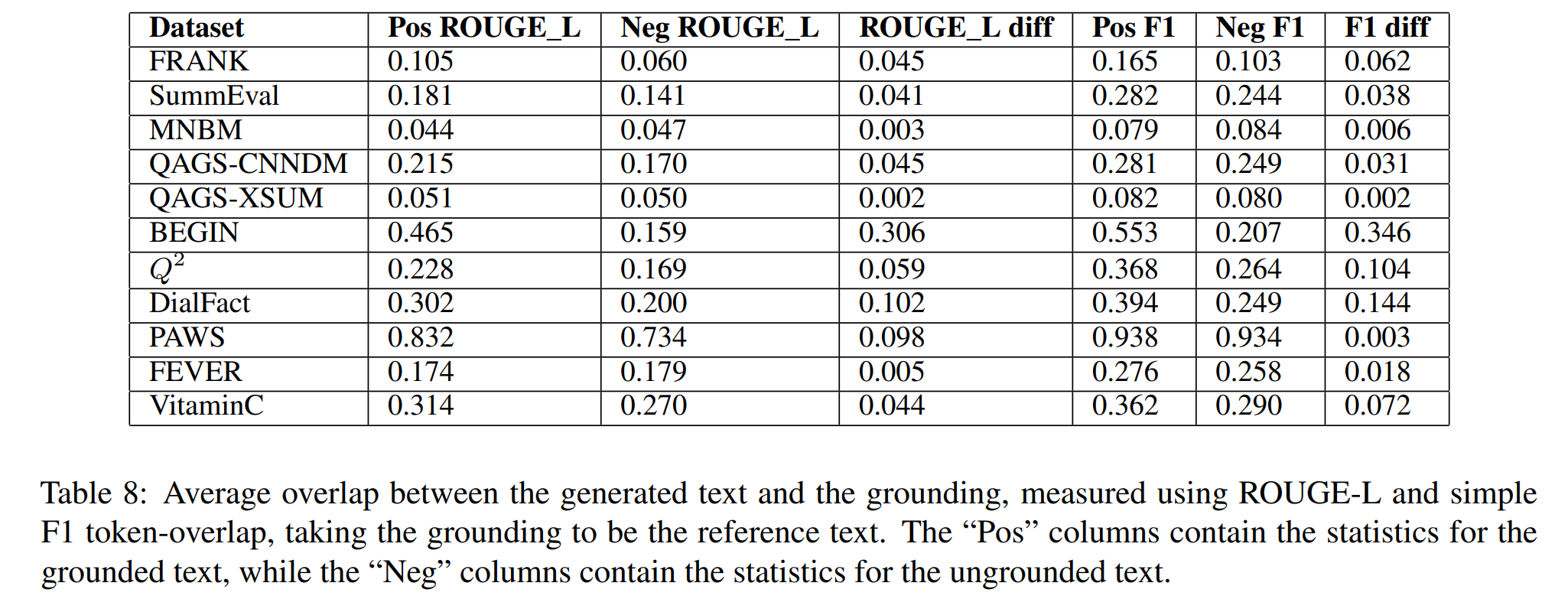
- 원문과 타겟 텍스트간의 평균 overlap을 측정해보니, BEGIN이 다른 데이터셋에 비해 원문과 원문이 아닌 텍스트 차이가 가장 컸음
(정확히 이해 못함. 거의 extractive처럼 원문에 정답 요약문이 있었던건가?)
- 원문과 타겟 텍스트간의 평균 overlap을 측정해보니, BEGIN이 다른 데이터셋에 비해 원문과 원문이 아닌 텍스트 차이가 가장 컸음
-
bootstrap resampling을 통해서 1번째로 좋은 방법이랑 2번째로 좋은 방법을 비교. 6개 데이터셋에 대해서 해보니 3개는 , 나머지 3개는 ANLI-based 모델이 가장 높은 성과를 냄
-
모든 데이터셋에 대해서 단일 방법으로 뛰어나지 않았던 것으로 보아, NLI와 QG-QA기반 모델이 서로 상보적이라는 가설을 세울 수 있음.
- 이를 테스트하기 위해, 와 ANLI와 점수를 데이터별로 평균냄(ensemble). 결과, 단일 모델보다 더 좋은 결과를 냄.
-
3개의 베스트 지표(, ANLI, )가 11개의 데이터셋에서 평균적으로 80이상의 점수를 낸다는 것을 보아 단일 지표는 모든 태스크와 데이터셋에서 잘 나옴.
5 Analysis
-
Input Length
- 200토큰 이상의 긴 텍스트에선 지속적으로 성능이 떨어짐.
- 긴 텍스트를 더 잘 다루게 설계된 도 포함.
- 오히려 ANLI기반 모델과 가 비교적으로 긴 데이터(500토큰 이상)에서도 좋은 성능을 냄.
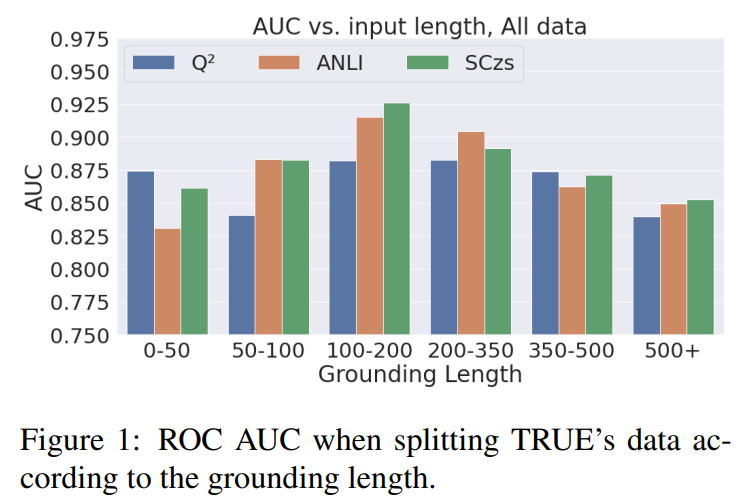
-
Model Size
- 모델 기반 방법들은 모델 크기가 커질수록 수혜를 받음
- 이를 계량화하기 위해서 더 작은 모델을 사용해 ANLI, BLEURT, BERTScone를 테스트
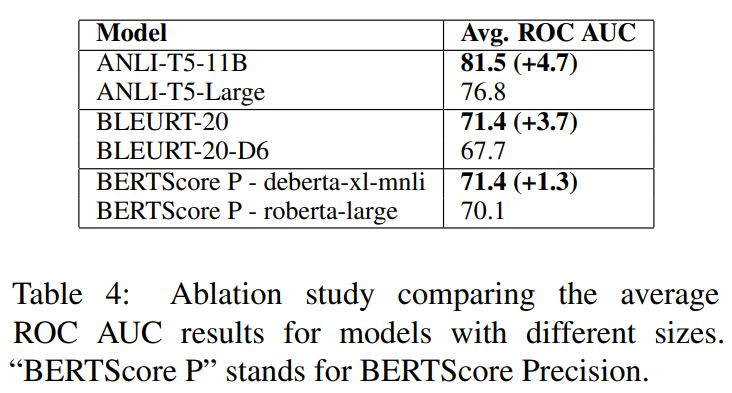
-
Qualitative Analysis
- 다양한 메트릭의 약점과 이 태스크에 존재하는 문제를 보이기 위해 mnual error analysis를 진행
- 3개의 메트릭에서 모두 잘못 분류된 80개의 데이터와 1개 또는2개의 메트릭이 옳게 분류한 100개의 데이터를 분석
- 분석된 데이터의 상당수가 틀린 라벨을 가지고 있는 것 처럼 보임
- 특히 베스트 3개 메트릭 모두가 실패한 데이터 80개 중 35개가 annotation error
- 1개 또는 2개의 메트릭이 실패한 경우엔 100개 중 27개가 annotation error
- 높은 annotation error가 실제로 본 논문에서 사용한 데이터셋의 일반적인 문제가 아니라 "가장 어려운 데이터"를 테스트한 결과인지 확인하기 위해, 100개를 임의로 샘플링. 10개만 annoration error.
==> 높은 miss annotation rate는 어려운 데이터의 특성이라는 결론. - 인상적인 결과를 보여줬음에도 불구하고, 최고의 성능을 내는 메트릭이 미묘한 inconsistency를 탐지하는데엔 실패(21/180 analyzed examples)

- target text의 부분을 합쳐서 점수를 집계하는 방식()의 메트릭의 경우 작은 부분(원문과 모순되는 부분)을 제외하고 다 consistent한 텍스트에 높은 점수를 부여할 수 있음. ==> aggregation에서 엄격한 방식(평균대신 최솟값 사용)을 사용하면 교정할 수 있지만 false-negative가 높아짐
- 다른 에러는 도메인에 특화된 문제에서 발생. ex) 대화에서 개인적인 진술
(10/62 analyzed dialogue response) => 이를 해결하기 위해선 평가에서 non-factual 부분을 자동으로 배제하도록 하는 것
-
Ensemble Analysis
- 3개의 베스트 메트릭을 사용해 간단히 평균 내 앙상블한 결과, 대부분의 데이터셋에서 단일 메트릭보다 뛰어남
- 이를 더 이해하기 위해 ,3개의 메트릭 중 하나이상 분류를 실패했지만 앙상블은 맞춘 경우(25761 examples)를 조사.
- 전체의 85.2%가 3개 중 1개가 실패했는데 앙상블은 맞춘 경우
- 14.6%는 3개중 2개가 실패했을 때 앙상블은 맞춘 경우
- 0.2%는 3개 메트릭은 다 틀렸는데 앙상블이 성공한 경우
