[논문 리뷰] FEQA : A Question Answering Evaluation Framework for Faithfulness Assessment in Abstractive Summarization
Paper review
본 논문은 2020 ACL에 실린 논문입니다. Summarization task에서 factual inconsistency를 해결하기 위해 QA방식을 이용해 metric을 제안하고 있습니다. factual inconsistency에 관해 궁금하다면 전의 포스트 중 하나인 "The Factual Inconsistency Problem in Abstractive Text Summarization: A Survey" 논문 리뷰를 읽어보시는 것을 추천드립니다.
Abstract
신경망 생성 요약 모델은 원문과 일치하지 않는 내용을 생성하는 경향이 있다(즉, unfaithful). 현존하는 automatic metrics는 이러한 실수를 효과적으로 잡지 못한다. 우리는 본문이 주어졌을 때, 생성된 요약의 faithfulness를 평가하는 문제를 해결하고자 한다. 우선 2개의 데이터셋에 대해서 수많은 모델로부터 output에 대한 faithfulness의 human anootations을 수집했다. 우리는 현재 모델에선 abstractiveness와 faithfullness사이의 trade-off가 존재한다는 것을 발견했다 : 원문과 적은 단어로 overlap되는 결과가 unfaithfullness할 가능성이 높다.(즉, abstractiveness가 높아질수록, faithfullness가 낮아짐) 그래서, 우리는 automatic question answering(QA)를 기반으로 한 faithfulness metric, FEQA를 제안한다. FEQA는 현재 독해에서의 장점을 극대화한다. 요약문을 바탕으로 생성된 QA가 주어질 때, QA모델이 문서에서 답을 추출해낸다. 그리고 그 답이 요약과 매치되지 않으면 unfaithfull한 정보라는 것을 의미한다. word overlap, embedding similarity, learned language understanding models을 기반으로 한 평가지표 중에서, 우리의 QA-based 지표가 human faithfulness scores와 유의미하게 더 높은 상관관계를 보였다(특히 highly abstractive sumamries에 대해).
1 Introduction
생성 요약 모델은 원문에서 중요한 내용을 모델에 결합해야 faithful을 유지할 수 있음. 신경망 생성 모델은 중요한 내용을 식별하고, 유창한 요약을 생상하는데에 효과적. 하지만, 생성된 요약문이 항상 faithful한 정보를 갖고 있는 것은 아니기 때문에 실제 응용에 적용하기에 치명적이다. 아래 표를 보면, unfaithful generation의 예시가 나와있다. 최근 연구에 따르면, 생성된 요약문의 약 30%정도가 unfaithful 정보를 포함하고 있다고 한다. 특히, 여러 원문 문장의 정보를 합칠때!

핵심 인사이트
- 현재 모델들이 abstractiveness와 faithfulness사이에 trade-off로 제한된다는 것(section 2)
- 요약문이 더 abstractive할수록(==less overlap with the source doument) unfaithful sentences의 수가 증가
- 현존하는 다양한 평가 지표들과 faithfulness의 human score의 상관관계가 abstractive정도가 높은 요약문일수록 떨어짐(즉, 표면적인 유사성을 넘어서 더 깊은 텍스트 이해가 요구됨)
이전 논문들의 인사이트
- QA(Question answering)기반 automatic metric이 요약에서 내용 선택을 평가하기 위한 용도로 제안됨
- cloze-style QA는 원문에서 중요한 정보가 요약에서 커버되고 있는지를 평가하기 위해 사용됨
==> automatically generated QA pairs를 사용해 요약문의 정보를 나타내고, 이를 원문과 비교해 평가하자!
- 선언적 문장(declarative sentence)와 답변 범위를 질문으로 변환하는 학습된 모델 사용해서 "groudtruth" QA pair를 요약문에서 생성(section 3)
- 기성(off-the-shelf) 독해 모델은 원문에서 답변 범위를 추출해 평가됨.
높은 정확도 == 원문과 요약문이 같은 답을 생성 == 각 질문에 대해 factual consistenct가 있다고 볼 수 있음
cloze test를 사용하는 이전 방법들과 비교하면, 우리의 질문 생성 접근은 더 넓은 범위의 QA model과 답변 유형(extractive와 generative)을 통해 평가할 수 있다.
2 The Abstractiveness-Faithfulness Tradeoff
추출 요약 모델은 매우 faithful하지만(왜냐면 원문에서 그대로 문장을 갖고 오는거니까!), 현재의 생성 모델은 copy없이 faithful summary를 생성하는데에 고군분투하고 있다. 우리는 더 abstractive할수록 factual error가 더 많이 발생한다는 것을 관찰했다(Lebanoff et al. (2019)). 이번 섹션에서, 우리는 생성된 요약을 2개의 차원으로 분석하려고 한다 : abstractivness와 faithfulness
특히, 우리는 다음 질문에 대한 답변을 하는 것을 목표로 한다.
- 요약문의 abstractiveness를 어떻게 계량화할 수 있을까?
- abstractiveness가 data또는 model에 의해 더 권장되나?
- abstractive함이 어떻게 faithfulness에 영향을 끼칠까?
2.1 Characterizing Abstractivenss of a Summary
생성 요약은 중요한 정보를 간결한 서술로 rephraing하는 것(원문을 살짝 고치는 것 ~ 여러 문장을 새로운 단어로 압축시키는 것)을 포함한다. 원문과 요약이 주어질 때, 우리는 요약문의 abstractivness의 정도를 평가하고자 한다.
이전 논문은 abstractivness를 요약문과 원문 사이에 얼마나 많은 text가 겹치는지를 이용해 abstractiveness의 수준을 평가하거나 LEAD-3와 같은 extractive baseline의 효율성에 의해 간접적으로 평가했다. extractive fragment coverage와 density와 같은 지표는 abstractiveness의 수준에 대해 연속적인 측정값을 제공한 반면, 우리는 요약에서 각 문장들이 얼마나 형성되었는지를 분석하며 abstractiveness의 세밀한 범주화(fine-grained categerization)를 정의한다.
더 abstractive한 summary문장은 원문의 더 큰 chunk에 대한 정보를 통합한다. 즉, 간결함을 유지하기 위해 더 적은 단어만을 copy해야만 한다. 그러므로, 우리는 abstractiveness 종류를 copy된 양에 의해 정의한다.(copy한 것이 문장, 한 부분 or 그 이상, 단어 수준으로 정의)
- Sentence extraction : 원문 중 하나의 완전히 같은 요약문
- Span extraction : 요약문이 원문의 substring과 동일.
ex) "the plane was coming back from the NCAA final"은 원문의 "the plane was coming back form the NCAA final, according to spokesman John Twork"에서 추출됨 - Word extraction : 요약문이 원문의 토큰들의 하위 집합으로 형성됨
ex) "Capybara Joejoe has almost 60000 followers"는 원문의 단어 몇개를 삭제한 것과 같음 "Capybara joejoe who lives in LasVagas has almost 60000 followers on Instragram" - Perfect fusion : 요약문은 원래 순서를 가진 k개의 요약 문장에서부터 substring들을 조합한 것에 의해 만들어짐
ex) "Capybara Joejoe has almost 60000 followers"는 원문의 단어 몇개를 삭제한 것과 같음 "Capybara joejoe lives in LasVagas", "He has almost 60000 followers on Instragram"
요약문의 abstractiveness 정도를 계량화하기 위해, 위의 카테고리 중 하나에 충족될 경우 각 문장에 labeling을 했다. 그리고 나서, category에 의해 라벨링된 문장의 percentage를 각 type의 점수로 정의한다. 이 종류는 abstractiveness의 정도에 따라 오름차순으로 정렬되어 있다. 예를 들어, 더 높은 fusion score와 낮은 extraction 점수를 가진 요약문은 더 abstractive한 것으로 여겨진다. 게다가, 우리는 원문에서 나타나지 않은 novel n-grams의 비율을 계산해, abstractiveness의 또 다른 지표로 사용했다.
2.2 Is abstractiveness from the model or teh data?
위에 언급된 abstractivenss에 대한 지표를 사용해서, 우리는 생성된 요약이 얼마나 abstractive하고, 그것의 양이 training data 또는 model의 결과인지 아닌지를 더 이해하고자 한다. 그래서, 우리는 다양한 모델과 2개의 dataset에 대해 reference summary와 생성된 요약 모두에 대한 abstractiveness scores를 계산했다.
Datasets
우리는 CNN/DailyMail(CNN/DM)와 XSUM을 사용했고, 둘다 single-document news summarization task에 사용된다. CNN/DM은 CNN과 Daily Mail 웹사이트의 기사들로 구성되어 있다. XSum은 BBC기사로 구성되어 있고, 요약문은 artile에 대한 opening introductory sentence으로 쓰여진 하나의 문장으로 구성되어 있다. XSum은 highly abstractive summarization system에 대한 연구를 촉진하기 위해 출시되었다. Appendix A에선 CNN/DM과 XSum 데이터셋에 대한 통계자료를 제공한다 : 그들은 각각 약 288k와 204k개의 학습 데이터를 가지고 있다; CNN/DM은 평균적으로 더 긴 원문과 요약을 포함하고 있다.
Models
대부분의 신경망 생성 요약 모델들은 sequence-to-sequence 모델에 기반을 두고 있다. 그들은 copying/extraction와 같은 요약 특화 작업이 인스턴스화되는 방식이 다르다. 우리는 5개의 유명한 모델을 사용하고, 그들의 특성을 Table2에 요약해두었다.

각 모델의 세부사항은 Appendix B에서 찾을 수 있다. PGC는 decoding중에 copy mechanism을 사용해 추출을 허용한다. FASTRL과 BOTTOMUP은 처음에 문장과 단어를 선택해 학습하고, extraction과 abstractive generation을 분리한다(decouple). 이 모델은 PGG과 비교해서 더 abstrative summaries을 생성한다고 알려져 있다. TCONV는 XUsm을 위해 초기에 설계되었고, 그렇기 때문에 어떠한 외재적인 copying/extraction 요소를 포함하지 않고 CNN을 사용해 긴 문서 표현에 초점을 둔다. BERTSUM은 BERT 기반 encoder와 6개의 Transformer decoder로 구성되어 있다. 이는 추출 요약 task에 대해선 인코더를 먼저 fine-tuning하여 내재적으로 추출을 통합한다.
Results
우리의 목표는 다양한 모델에 의해 생성된 요약문의 abstractiveness의 수준을 이해하고, 학습 데이터로부터 abstractiveness에 대한 영향을 이해하는 것이다. 그러므로, 우리는 CNN/DM과 XSum에 대해 위의 모델들에 의해 생선된 요약문을 분석한다. 우리는 test set의 generated summaries와 reference summaries에 대해 Section 2.1에 서술된 지표를 계산한다. 그 결과는 Table 3에 나와있다.
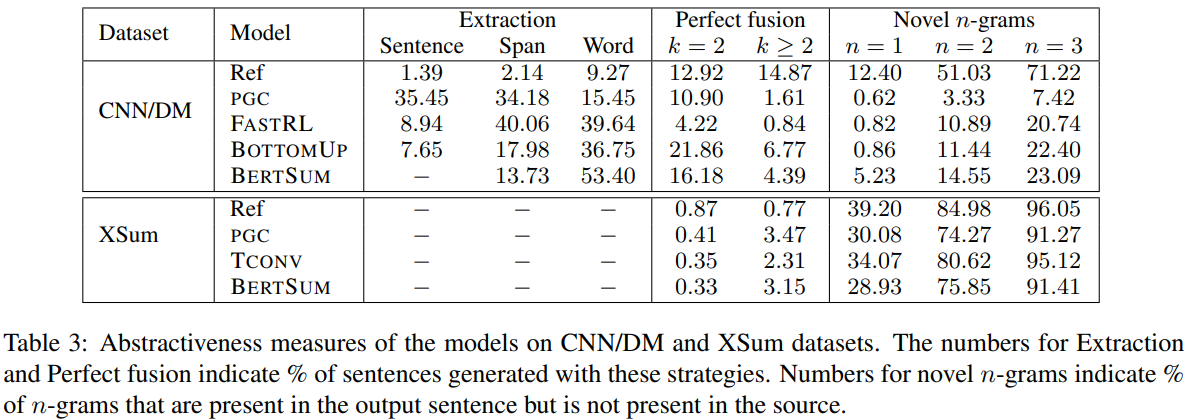
-
CNN/DM은 XSum보다 더 extractive하다.
CNN/DM에서 reference summary에 대한 extractive score은 거의 문장의 반절 이상이 원문의 문장 중 하나에서 단어를 삭제해 생성되었다는 것을 보여준다. 이 데이터셋에서 sentence compression이 주된 테크닉으로 사용되었다는 걸 보여준다. 반대로, XSum의 요약문에선 단 한 문장도 원문 문장을 그대로 copy해 만들어지지 않았다. 그들은 거의 input content를 paraphrasing하여 생성되었고, 이는 novel n-gram의 large fraction에 의해 설명될 수 있다. -
학습 데이터는 model output의 abstractiveness에 대해 큰 영향을 끼친다.
우리는 CNN/DM에 대해 학습한 모델이 더 near-extractive하다는 것을 알았따. 하지만, 같은 모델이 XSum에 대해 학습되었을 때는 확연히 더 abstractive했다. 사실, 어떤 모델도 단일 원문 문장에서 단어/구를 복사하는 문장을 생성하지 않았고, 이는 XSum의 reference summary의 특성과 일치한다. 정보는 참신한(novel) 단어/구에서 더 rephrase되었다. 그러나, 두 데이터셋 모두에 대해서 현재의 모델들은 reference summary과 동일한 수준의 abstractiveness을 달성하기 위해 고군분투하고 있고, 이는 다시 말하자면 여러 문장을 압축하기 위해 추가적인 inductive bias가 필요함을 나타낸다. -
다양한 모델들은 다양한 방식으로 extraction을 한다.
CNN/DM에 대해 학습할 때, PGC는 원문을 완전히 copying하면서 문장의 대다수를 생성했지만 FASTRL, BOTTOMUP, BERTSUM은 삭제하면서 더 간단하게 압축을 진행했다. 게다가 BOTTOMUP은 PGC, FASTRL과 BERTSUM에 비교해 더 fusion를 했다.
2.3 Annotating Summary Faithfulness
현재 시스템의 faithfulness와 abstractive에 대한 그들의 관계를 이해하기 위해, 우리는 Section 2.2에 서술된대로 각 모델-데이터셋 쌍의 결과값에 대해 human annotations을 했다. extractive에 가까운 문장들은 더 grammatical하고 faithful했기 때문에, 우리는 완전한 copy 또는 원문 중 하나의 substring을 copy하는 output sentence는 배제하고 더 abstractive한 경우에 집중했다.
믿을만한 human annotation에 대한 중요한 문제점은 faithfulness에 대한 inter-annotator agreement가 비교적 낮았다는 것이다. 우리의 파일럿 연구는 annotator가 종종 앞뒤가 맞지 않는 문장에 대해 동의하지 않았다는 것을 보인다. (ex. Chelsea beat Chelsea 5-3 in the Premier Leargue on Saturday와 같은 문장은 faithful하냐 아니냐와 같이) annotation 과정을 표준화하기 위해, 우리는 문장을 무의미하게 만드는 실패한 생성, 의미론적 이해에 거의 영향을 미치지 않는 낮은 수준의 문법 오류, 부정확한(그러나 의미있는) 정보를 포함하는 충실도 오류
를 구별하는 계층적 질문을 설계했다.
Figure 1은 우리의 human annotation steps의 decision tree를 보여준다.
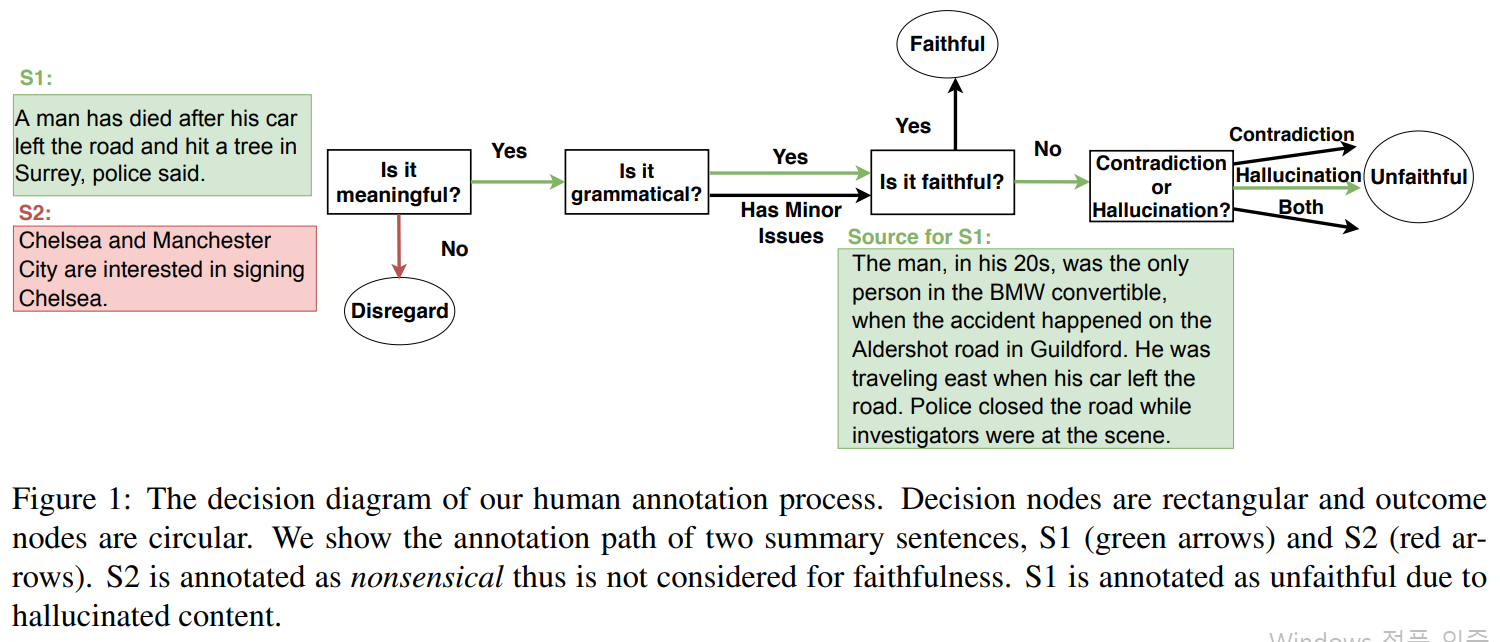
- 우리는 먼저 생성된 문장(원문과 독립)의 문법성을 평가한다.
- 문장의 의미 있는지 없는지 선택
- 문장이 의미 있다면, 문법 오류가 있는지 확인
- 의미있다고 분류된 문장에 대해, 제공된 원문에 대해 faithful한지 평가
- unfaithful하다고 붙여진 문장들의 경우, 해당 문장에 원문에 누락된 정보나 상충되는 정보가 포함되어 있는지를 확인해 오류를 분석한다.
더 자세한 정보는 Appendix C에 나타나있다.
2.3.1 Human Annotation Results
Section 2.2에서 서술한 dataset-model pair에 대해서, 우리는 완전한 혹은 substring copy인 문장을 제외하고 무작위로 sentence-source pair를 1000개 추출한다. 우리는 이러한 문장에 대해 5명의 annotators에게 grammaticality annotation을 수집했다. 우리는 만약 첫 단계에서 5명 중 4명 이상이 의미있다고 라벨링한 문장만 meaningful하다고 생각했다. 우리는 faithfulness에 대해 annotation을 수집하기 위해 200개의 의미 있는 문장을 무작위로 샘플링했다. Table 4는 grammaticality와 faithfulness human evaluation을 보여준다.
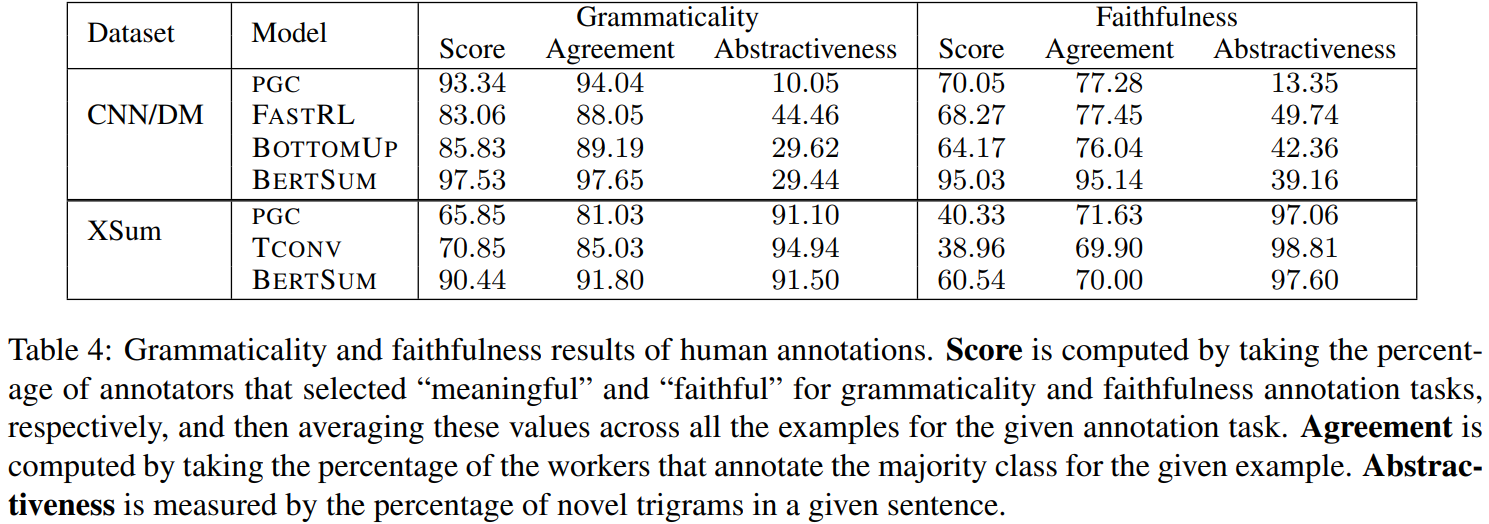
(확실히 보면 abstractive가 낮은 애들이 문법성도 높고, Faithfulness도 높음)
Grammaticality
전반적으로, 모든 모델에 대한 결과는 높은 inter-annotator간 일치와 함께 문법성(grammaticality)에서 높은 점수를 받았다. 그러나 더 abstractive한 요약에 대해서는 문법성 점수가 크게 낮아졌다. 하나 예외는 BERTSUM인데, 이 모델은 XSum에 대해서도 높은 성능을 유지함과 종시에 두 데이터셋 모두에 대해 가장 높은 문법성 점수를 기록했다.
Faithfulness
extractive에 가까운 요약(CNN/DM에 대해 학습된 모델에서 생성한 요약)은 abstractive에 가까운 요약(XSum에 대해 학습된 모델에서 생성한 요약) 보다 더 높은 faithfulness 점수를 가진다. 우리는 PGC와 TCONV가 XSum으로 학습했을 떄 문장의 절반 이상에서 faithfulness error가 나타난다는 것을 발견했다. 하지만 BERTSUM은 덜 unfaithful sentence를 생성하지만, 여전히 XSum에 대해 성능이 낮다. 흥미로운건, faithfulness에 대한 사람의 동의도 XSum으로 얻은 요약문일 경우에 더 낮다. 이는 faithfulness error자체가 더 abstractive한 환경에선 사람이 포착하기에도 어렵다는 것을 의미한다. CNN/DM으로 학습된 경우 원문과 상충되는 정보가 나오는 경우가 흔했고, XSum으로 학습된 경우 hallucination(원문에 없는 정보)이 나오는 경우가 더 흔했다. Table 5는 의미는 있지만 unfaithful한 문장들의 예시를 보여주고 있다.
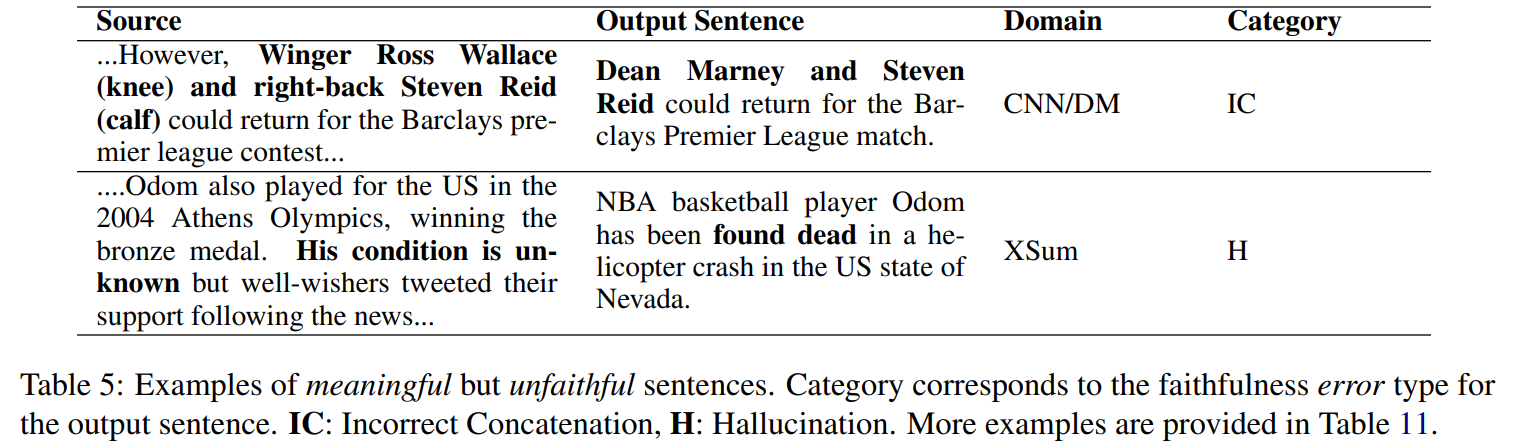
3 FEQA : Faithfulness Evaluation with Question Answering
위에서 한 우리의 연구는 abstractive summaries이 생성될 때 더 unfaithful한 문장의 수가 증가한다는 것을 보여준다. 이와 같이, faithfulness evaluation에 대한 중요한 문제는 원문에 비해 매우 abstractive한 문장을 증명해야한다는 것이다.(유사도 매칭이 어려움!!)
만약 표면적인 형태와 관계 없이(예 : 누가 누구에게 무엇을 했는지에 대한 사실 목록) 문장의 좋은 의미적인 표현을 가진다면, 우리는 단순히 원문과 문장의 표현을 비교할 수 있다(예 : 요약문의 사실 목록이 원문의 사실 목록의 하위집합인지 확인하는 것). 이상적으로, 그 표현은 간단한 에러 분석에 대해 domain-general하고 interpretable 해야한다.
reading comprehension의 급진적인 성장에서 영감을 받아, 우리는 faithfulness evaluation에 대한 문장의 일반적인 의미 표현으로 QA 쌍을 사용하는 방법을 제안한다. 요약 문장이 주어질 때, 우리는 문장에서 핵심 정보에 대해 묻는 질문들과 그와 상응하는 답을 만들 수 있다. 이 정보가 원문에 있음을 증명하기 위해, 우리는 원문으로부터 답을 예측하는 QA모델을 사용한다. 질문과 QA모델은 그러므로 2개의 텍스트에서 비교할만한 정보를 추출해낸다. 원문과 일치되는 답이 더 많을 수록, 질문들이 다루는 정보가 원문과 요약문에 일관된다는 것을 의미하기 때문에, 더 faithful한 요약이라고 볼 수 있다. Figure 2는 FEQA의 플로우를 보여준다.
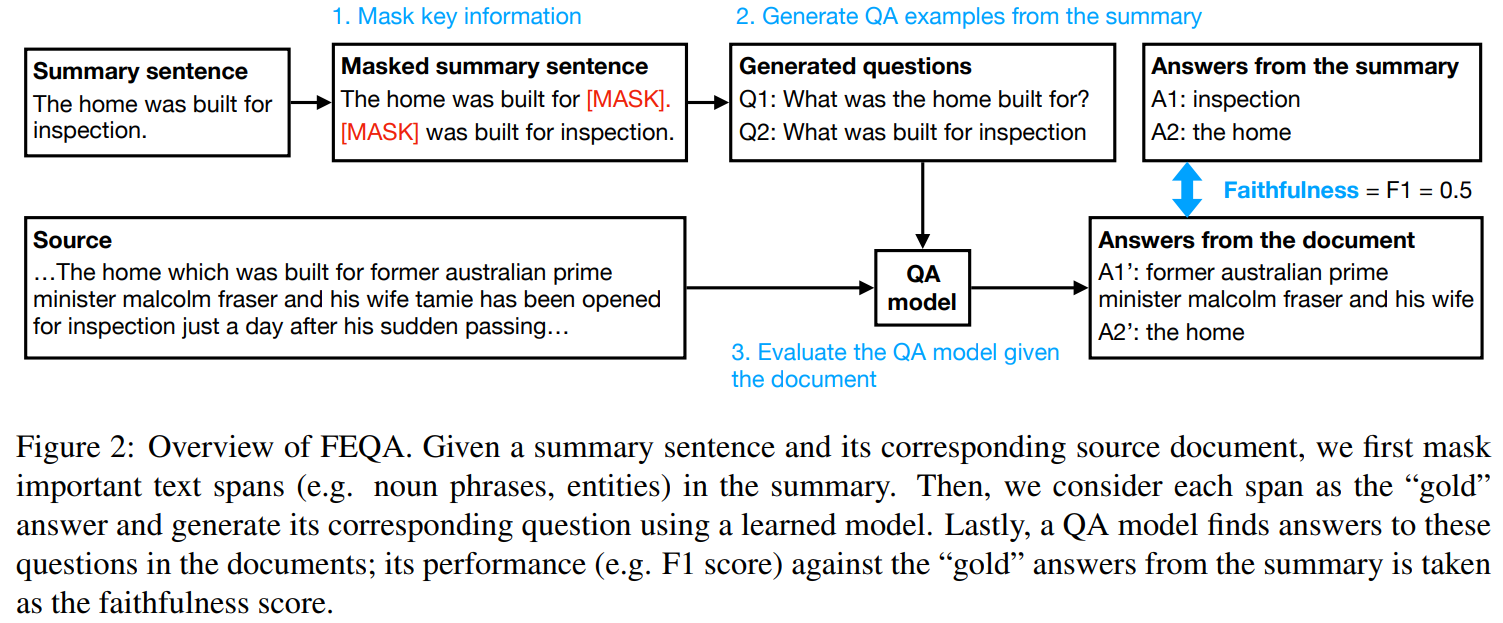
Question generation
이전 논문은 entities를 마스킹한 것을 question으로 cloze tests을 사용한다. cloze-style QA을 넘어 더 최근의 extractive 또는 generative QA 모델을 활용하기 위해 요약 문장에서 자연어 질문을 자동으로 생성합니다. 특히, constituency parser에 의해 추출된 명사구와 Stanford CoreNLP NER모델에 의해 추출된 named entity를 포함하여 문장에서 중요한 텍스트 범위를 마스킹한다. 우리는 각 span을 golde answer로 삼고, 사전 학습된 BART 언어 모델을 fine-tuning해 이와 상응하는 질문을 생성한다. 질문 생성기를 학습하기 위해, 우리는 QA2D dataset을 사용했다. 입력값은 마스킹된 답변이 포함된 선언적 문장이고 출력값은 질문이다. 학습 데이터의 예시는 다음과 같다
Input : Sally was born in [m] 1959 [/m]
Output : When was Sally born?
선언적 문장에서 질문으로의 변형이 거의 paraphrasing없이 rule-based이기 때문에, 우리는 모델이 다양한 도메인에 으로 일반화되기를 기대한다.
Answer verification
요약문에서 생성된 QA pair가 주어질 떄, 우리는 이미 있는 QA모델을 사용해 원문에서 이러한 질문에 대한 답을 구한다. 이후 요약에서의 "gold" 답변에 대해 평균 F1 score를 측정한다. 이 과정은 QA모델에 대해 어떠한 제약도 없다. 우리는 사전 학습된 BERT-base모델을 SQuAD-1.1과 2.0으로 fine-tunign해 실험했다. SQuAD-2.9의 경우, 모델이 질문에 답변할 수 없다는 가설이 가능하게 했다. 이는 답변이 incorrect하다는 것과 의미적으로 동일하다(==unfaithful!)
4 Experiments
우리는 제안된 QA기반 지표와 기존 지표가 요약의 정확성을 어느 정도 포착하는지 이해하는 것을 목표로 한다. reference summary가 없는 원문과 요약 문장의 pair가 주어질 때, 우리는 human-annotated faithfulness score와 아래 서술된 지표를 사용해 계산된 점수와의 상관관계를 측정했다.
4.1 Automated Metrics for Faithfulness
Word overlap-based metrics
faithfullness에 대한 직관적인 지표는 요약문과 원문 사이의 word overlap이다. 우리는 결과 문장과 원문의 문장 각각에 대한 ROUGE(R), BLEU(B)를 계산한다(원문 문장을 reference로 삼음). 우리는 모든 원문 문장에 대해 평균 점수와 최대 점수를 계산한다. 분석에 따르며 평균 점수를 일관되게 취하는 것이 더 높은 상관 관계를 가지므로 평균에 대한 상관 관계만 작성하였다.
Embbeding-based metrics
word embbeding은 word overlap기반 지표를 정확한 매칭 이상으로 확장한다. 최근에, BERTScore는 BERT에서 contextual word embbeding을 사용해 두 문장 사이의 유사성을 계산하는 방법을 제안했다. 이는 image captioning과 machine translation에서 wor overlap기반 지표보다 더 human judgement와 높은 상관관계를 보인다. 우리는 원문 문장 각각과 요약문장 사이의 BERTScore를 계산한다. 최종적인 점수를 얻기 위해, 우리는 각각의 원문 문장과 요약 문장에서 계산된 평균과 최대 점수 둘다에 대해 실험한다. 성능이 더 좋기 때문에, 최대 점수를 사용해 결과를 보고한다.
Model-based metrics
QA에 더해, 현재 논문들은 faithfulness evaluation을 위해 relation extraction과 text entailment model을 사용해왔다. relation extraction metric(RE)에 대해, 우리는 Standard Open IE에 있는 모델을 사용해 원문과 요약문에서 relation triplets에 대한 precision을 계산한다. textual entailment metric(ENT)에 대해, AllenNLP에서 사전 학습된 ESIM모델을 사용해 요약문이 원문에 대해 entail되는지를 측정한다.
4.2 Results
Metric Comparison
우리는 CNN/DM과 XSum 데이터셋(748개, 268개) 모두에 대해 원문과 결과 문장에 대해 각각 지표를 적용해 점수를 계산했다. 그리고 우리는 각 지표와 human annotation scores사이의 Pearson과 Spearman 상관계수를 계산했다. Table 7에 각 데이터셋의 데이터에 대한 상관계수들이 나타나있다. 우리는 CNN/DM과 XSum 모두, 다른 지표보다 QA를 바탕으로 한 평가가 faithfulness와 높은 상관관계를 보인다는 것을 알 수 있었다(QA기반 방법이 짱이다). word-overlap기반 방법은 더 extractive한 상황(CNN/DM)에서 더 faithfulness와 상관성이 높았지만, abstractive한 상황(XSum)에선 faithfulness와 상관관계가 없었다. 우리는 XSum에 대해 모든 지표가 human score과의 상관관계가 상당히 낮다는 것을 알았고, faithfulness를 평가하는 것은 more abstractive setting에서 더 힘들어진다는 것을 제시한다. 원문과 요약문에 대한 더 깊은 이해가 필요하다.
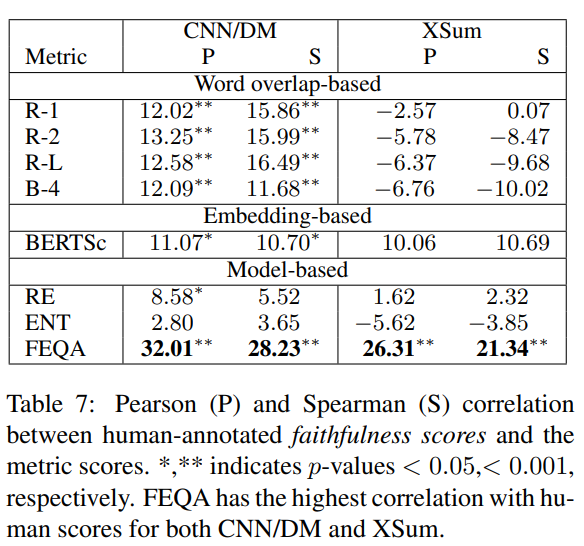
이전 연구에 따르면, entailment metirc은 대부분의 경우에서 faithfulness와 높은 상관관계를 갖지 않았다. 이러한 모델들은 횬재 entailment dataset에 대해 학습된 모델들은 lexical overlap과 같은 간단한 휴리스틱에 의존하기 때문에 원문과 요약문이 크게 overlap될 때 entailed(faithful)과 non-entailed(unfaithful) 요약 문장을 구별하는 것에 실패했다. 유사하게, BERTScore도 문장사이에 겹치는 개념이 있을 때, 내용이 같이 않더라도 높은 점수를 주는 경향이 있다. Table 6에 예시가 나와있다.

Content selection and faithfulness
요약에 대한 현재의 평가 지표들은 요약문의 전반적인 푸질에 대해 하나의 측정값을 생성한다. 전형적으로, 결과 요약문은 n-gram의 관점에서 reference 요약문과 비교된다. 이러한 지표들은 주로 content selection을 평가한다(ex. reference의 content와 유사한지 비교) 반대로, faithfulness를 평가하기 위해, 우리는 원문과 생성한 요약문을 비교한다. 이에 따르는 하나의 질문은 높은 content matching이 faithfulness에 대해 충분한지이다. 우리는 human annotated faithfulness 점수와 ROUGE score와의 상관계수를 계산했다. Table 8에서 볼 수 있듯이, CNN/DM에선 약한 상관관계를 보이고, 그 상관관계는 faithfulness의 ROUGE score(원문과 생성 요약문 비교해 계산)보다 훨씬 낮다. XSum에 대해선, content seclection metric과 faithfulness사이에 큰 상관관계가 없다.
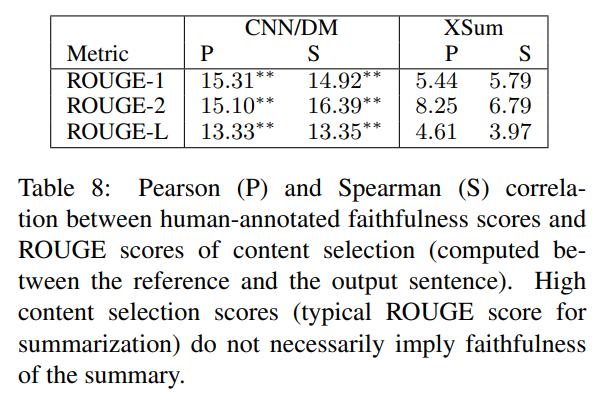
우리는 높은 content selection score를 갖는 unfaithful example를 Appendix D.3에 기술해놓았다. 이는 contenct selection과 faithfulness는 점수를 단일화 해 측정하는게 아니라 분리되어 측정되어야 한다는 것을 보여준다.

Analysis and limitations of QA-based evaluation
Table 9는 상응하는 QA pair와 faithful and unfaithful output sentence의 예시에 대해 나와있다. QA시스템은 생성 요약문에서 충돌하는 정보와 같은 흔한 에러들을 포착할 수 있다. FEQA의 신뢰성을 측정하기 위해, 우리는 무작위로 샘플링된 100개의 QA pair를 사용해 manual error를 분석했다. 생성된 질문의 약 94%가 대부분 문법적이고 mask를 사용할 때 정확했다. 질문의 78%에 대해 QA 시스템은 올바르게 동작한다. 문장이 원문에 충실하면 질문에 올바르게 대답하고, 그렇지 않으면 답변 불가 또는 오답을 생성한다. QA시스템의 대부분의 오류는 답변할 수 없는 질문을 감지하지 못하거나 답변이 이씅ㄹ 때 "응답할 수 없음"을 생성하기 때문이다(14%). 게다가, 원문이 길 때, QA시스템은 더 실수하는 경향이 있다. 특히 더 abstractive한 환경에서, F1-score는 답과 원문이 정확히 일치하지 않을 때 correct answer에 패널티를 준다(ex. "Donald Trump" vs "the President of the United States Donald Trump")(16%)

5 Related Work
Problems in current neural generation models
신경망 생성 모델의 초기엔, 반복 및 일반적인 응단 문제가 많은 관심을 받았다. 최근엔, 기계 번역의 적절성, 요약의 충실도, 대화의 일관성과 같은 모델 출력의 의미 오류에 더 많은 논문이 집중되었다. abstractive-faithfulness trade-off에 대한 우리의 분석은 현재 모델의 추가적인 한계를 드러내고, 모방을 넘어 요약하는 방법에 대한 새로운 inductive bias가 필요함을 시사
QA as a proxy
QA는 많은 태스크를 포괄하는 넓은 포맷이다. QA를 요약을 위한 외재적인 평가로 처음 사용한건 Main et al.[1999]이었다 : 좋은 요약은 독자가 기사에 대해 가질 수 있는 핵심 질문에 답해야 한다. 후에, QA는 한 명이 요약에 대해 질문을 쓰면, 다른 한명이 답을 하는 사람 평가 방식으로 통합되었다. 우리의 방법은 자동화된 질문 생성을 적용한 최초의 방법이다. 우리는 faithfulness에 초점을 두었지만, 우리의 QA방식 평가 지표는 2개의 text사이의 semantic comparison에도 적용될 수 있다.
Automated evaluation for NLG
자동화된 NLG 평가는 텍스트의 깊은 이해를 요구하기 때문에 어렵다. reference text를 이용한 word overlap기반의 평가지표가 흔히 사용되지만, 이는 human judgement와 잘 맞지 않는다(상관관계가 떨어진다)고 알려져 있다. 최근에, 많은 논문들이 discriminator, entailment models, information extraction, question answering를 사용한 모델 기반 평가에 초점을 두고 있다.
6 Concolusion
우리는 신경망 생성 요약에서의 faithfulness문제를 조사하고, 요약의 faithfulness를 평가하기 위해 QA기반의 평가지표를 제안하였다. abstractiveness와 faithfulness사이의 내재적인 trade-off로 현재 모델들이 고통받고 있다는 것을 볼 수 있었다. 모델들은 중요한 원문 콘텐츠를 복사하는덴 능숙하지만 더 추상적인 문장을 생성할 때 관련 없는 구간을 연결하고 세부 내용을 착각(hallucination)하는 경향이 있다. 새로운 inductive bias 또는 추가적인 supervision이 신뢰성 있는 모델을 학습하기 위해 필요하다. human judgment와 높은 상관관계를 가지는 우리의 QA기반 평가지표는 모델을 발전시키는데에 유용하다. 하지만 이는 QA모델의 성능에 달려있다. 최종적인 평가는 여전히 human annotation이나 human-in-the-loop방법에 의존한다는 한계가 있다.
