[논문 리뷰] Understanding the Properties of Minimum Bayes Risk Decoding in Neural Machine Translations
Abstract
- 현재, NMT(Neural Machine Translation)는 모델이 생성한 번역이 너무 짧거나 빈도가 높은 단어를 overgenerating, 학습 데이터의 copy noise나 domain shift에 poor robustenss한 경향이 있음
=> 최근 연구에서는, 이러한 현상이 NMT의 대표적인 inference algorithm인 beam search와 밀접하게 관련있다고 보고 있음
=> 그래서 unbiased sample에 대해 Minimum Bayes Risk(MBR)를 대신 제안하는 것을 제안 - 본 논문에서는 이전에 보고된 많은 bias와 beam search의 실패 사례에 대한 MBR decoding의 특성에 대해 경험적으로 분석
- 분석 결과,
- MBR에서도 length와 token frequency bias는 나타남
(이는 utility function으로 사용되는 MT metric으로 인한 것으로 보임) - 학습 데이터에 나타나는 copy noise와 domain shift에 대해서는 robust함
- MBR에서도 length와 token frequency bias는 나타남
1 Introduction
-
현재 NMT는 다음과 같은 문제들이 존재
- underestimating the true length of translations
- underestimating the probability of rare words
- over-generating very frequent words
- being susceptible to copy noise in the training data
- hallucination in out-of-domain translation
-
이전에는 위와 같은 문제들에 대해 length normalization, data cleaning, model regularization과 같은 heuristic한 방법을 사용
-
하지만, 최근에는 가장 높은 점수를 받은 번역을 찾는 decision rule에 부분적으로 책임이 있다는 주장도 제기됨
- NMT모델에서 샘플링한 데이터는 학습 데이터 통계에 충실하지만 beam search는 그렇지 않다는 것을 발견함
- 그래서 beam search 대안으로 MBR decoding을 추천
-
본 논문의 저자들은 MBR이 NMT의 기존 bias들을 극복할 잠재력을 가졌다고 보고, 이에 대해 실험
- 만약 기존 bias들이 beam search의 mode-seeking 특성으로 발생한 거라면, MBR이 이러한 현상이 덜 할거라는 가설을 세울 수 있음!
- length bias, hallucination에 대해선 약간 다르게 가설을 설정하는데, 만약 샘플들 안에 이런 biase를 가진 문장이 있다면 MBR이 이를 최종 번역으로 선택하지 않을거라 가정
-
[Eikema and Aziz(2020)]에서 sample과 beam search의 통계적 특성에 대해 비교하고, MBR이 beam search에 비해 automatic metric에 대해 유리하게 디코딩할 수 있음을 보여주지만 본 논문에서는 MBR에만 초점을 두고 실험.
-
실험 결과,
- 짧은 번역을 선호하는 uility function을 사용할 때, MBR 역시 이러한 편향을 가짐
- MBR은 여전히 token probability bias를 가짐
- token probaility bias : 드문 토큰은 등장 확률을 낮게 생각하고, 흔한 토큰은 등장 확률을 높게 생각
- beam search와 비교했을 때, MBR decoding은 학습 데이터에서 copy noise와 domain shift에 robust함
- domain이 바뀌어도 beam search에 비해 hallucinated content를 생성하는 경향이 적음
2 Background
2.1 Maximum-a-posteriori(MAP) decoding
-
사실상 NMT에서 기본적으로 쓰는 decoding algorithm은 beam search.
-
beam search는 MAP 알고리즘이라고 하는 더 넓은 범주의 inference procedures라고 볼 수 있음
-
MAP 알고리즘의 공통점은 주어진 모델에서 가장 확률이 높은 번역을 찾으려고 한다는 것
-
특히, 이 알고리즘은 시퀀스에 대해 output distribution의 mode를 복구(recover)하려고 함
- 이게 무슨 의미지.. sequence를 하나씩 decoding하면서 바뀌는 distribution의 mode를 계속 잡아내려고 한다는 건가??
-
이러한 search problem의 정확한 답은 보통 계산할 수 없음(intractable).
==> Beam search는 이를 tractable하게 근사한 거지만, 분포의 진짜 mode를 찾는데 자주 실패
2.2 Known deficiencies of NMT systems
- NMT system은 여러 방면에서 문제가 있음
Length bias
- 모델이 번역의 true length를 과소평가
- 평균적으로, 모델이 생성한 번역은 reference(진짜 번역 결과)보다 짧음
Skewed word frequencies
- 번역에서, 학습데이터에서 자주 등장하는 토큰이 과도하게 표현(overrepresent)되는 경향이 있음
- 반대로 등장 빈도가 낮은 토큰은 학습데이터의 확률보다 더 적은 횟수로 발생
Beam search curse
- beam size를 늘리는 것은 모델에서 더 확률이 높은 문장을 찾도록 함
- 이론적으로, 이는 번역의 질을 향상시켜야 함
- 하지만 역설적으로, 실험 결과를 보면 beam size가 커질수록 번역의 질이 낮아짐
Susceptibility to copy noise
- 학습데이터에서 복사된 내용이 번역 품질에 불균형하게 영향을 끼침
- 가장 나쁜 종류가 학습 데이터의 target side에 있는 원문 문장의 복사!
(학습 데이터에 내재된 노이즈!) - 만약 이러한 복사가 학습데이터에 존재한다면, beam search에서 copy hypotheses는 과도하게 표현될 것.
=> 학습 데이터에 이러한 노이즈가 존재할 경우, beam search에서는 이를 output으로 선택할 가능성이 높아진다는 것(?)
Low domain robustness
- 모델은 domain shift와 같은 distribution shift에 roubst하지 않음
- unknown test domain에 대해 번역할 경우 품질이 저하되진 않지만 hallucination이 발생
- 과거엔 이 문제를 beam search를 상수로 놓고, 모델의 아키텍쳐나 학습 알고리즘에서 원인을 찾으려고 했지만, 최근 연구에서는 모델의 fitting이 문제가 아니라 beam search가 문제라는 주장이 제기됨
Inadequacy of the mode
- output sequence에 대한 분포의 mode가 최고의 번역이 아니라고 주장. 오히려, 대부분의 경우에서 mode는 empty sequence(공백)임
- output distribution은 광범위한 output space에서 꽤 flat하기 때문에, mode의 확률은 다른 sequence과 크게 차이 나지 않음
- 직관적으로, MLE training은 모델이 mode만으로 잘 특성화(characterized)되도록 제한하지 않음
- 만약 mode가 적절하지 않다면, beam search와 같은 mode-seeking procedure은 문제가 될 수 있음
- 사실 MAP decoding은 output distribution의 mode를 신뢰할 수 있을 경우에만 사용되어야 함
2.3 Minimum Bayes Risk Decoding
-
MBR decoding은 음성인식과 통계 번역에서 사용됐던 방법
-
최근에는, NMT에서 beam search decoding을 개선하기 위해 사용되고 있음
-
본 논문에서는 MBR를 NMT에서 간단하게 사용할 수 있게 정의함
- MBR의 목표는 가장 높은 확률의 번역을 찾는것이 아니라, 주어진 loss function과 true posterior에서 기대되는 리스크를 최소화하는 번역을 찾는 것!
-
여기서 모든 가능한 후보 번역문들을 size n크기의 샘플링으로 모델에서 근사할 수 있음
-
이 집합을 사용해서 posterior distribution을 근사하는데도 사용할 수 있음!
-
각 샘플 에 대해, expected untility(the inverse risk)를 계산해 pool안의 다른 샘플과 비교할 쑤 있음
-
가장 높은 expected utility 를 가진 샘플이 최종 번역문으로 선택됨
-
의 크기와 utility function 는 알고리즘의 하이퍼퍼라미터
-
utility function으로는 보통 가설(후보 번역문)과 reference translation(정답 요약문)사이의 유사도를 계산한다
-
즉, MBR는 "모든 가능성 있는 번역에 평균적으로 가장 가까운 consensus 번역을 선택하는 것"으롭 볼 수 있음
3 Motivation for experiments
- 본 논문에선 MBR decoding이 beam search에서 발생하는 특정 실패 케이스들에 대해 유용할거라는 가설을 설정
- beam search에선 틀린 번역이어도 가장 확률이 높은 번역을 최종 번역문으로 선택하지만, 만약 그와 준하는 유사한 확률이면서 정답인 번역이 후보에 있을 때 MBR이 이런 상황을 개선할 수 있을거라 가정
- 예를 들어, beam search 번역이 다른 유사한 확률의 번역문보다 짧을 때, length bias가 발생
- 혹은, copies of input sentence 또는 hallucination이 있는 번역이 sample pool내에서 흔하지 않다면 MBR에선 이를 피할 수 있으니까!
- 마지막으로, 번역에서 token frequencies의 skewdness를 연구
- Kikema와 Aziz는 NMT모델 lexical biases를 연구하여 모델 샘플이 MAP decoding보다 training distribution와 더 잘 일치함을 보임
- 본 논문에서도 이것이 MBR decoding에서도 사실인지 실험
4 Experimental Setup
4.1 Data
- Tatobeba Challenge : language families, scripts, training set size에서 상당히 다른 데이터셋
- 5가지 도메인에 대한 German-English 데이터셋 : 학습할 때는 medical, 테스트할 때는 IT, koran, law 등에 대한 도메인 사용
- training data에서 랜덤으로 샘플링해서 testing함
4.2 Models
- 전처리와 모델 세팅은 OPUS-MT에서 착안.
- 전처리 단계에서 subword regularization을 위해 Sentencepiece를 사용
- NMT모델을 Sockeye2로 학습
- 몇몇 세팅을 빼면 Standard Transformer
4.3 Decoding and evaluation
- 모든 실험에서 MBR decoding, beam search, single sample를 비교
- beam search에서 beam size는 5로 설정
- single sample은 variance를 보기 위해 적어도 100번 이상 샘플링
- automatic translation quality는 BLEU, CHRF, METEOR로 평가
- MBR은 샘플링에 영향을 받기 때문에, vairance를 보기 위해 MBR 실험을 2번 이상 반복
- MBR에 사용된 샘플 데이터의 수는 5에서 100사이로 5씩 증가하면서 테스트
- 최종적으로, 우리는 다양한 utility function을 써서 MBR translation을 만듦
- 모든 utility function은 문장 수준의 평가 메트릭 : BLEU, CHRF, METEOR
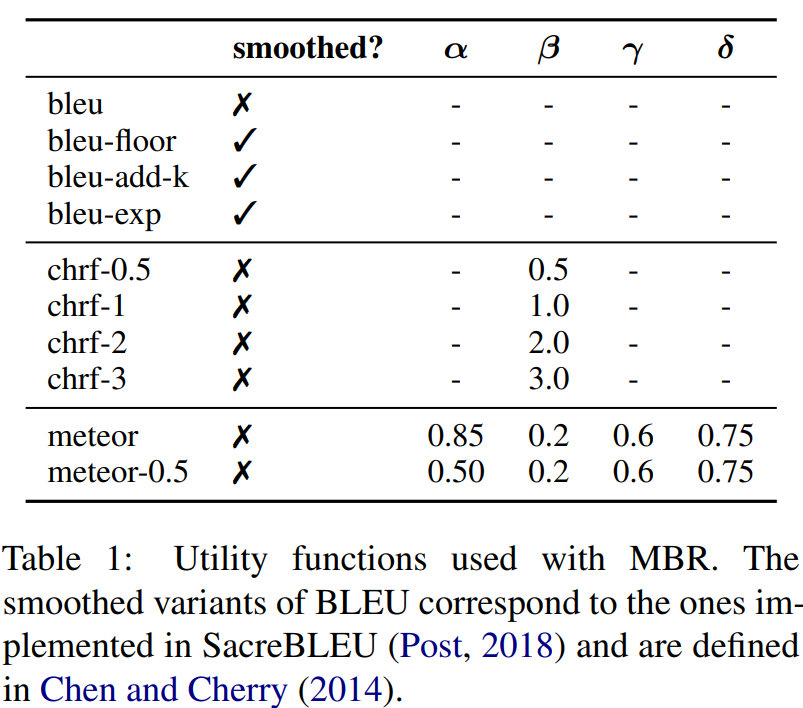
- 샘플 크기가 기술되지 않았다면 MBR결과는 100 samples, chrf-1을 utility function으로 한것!
5 Length bias
- MBR decoding을 평가할 때 다양한 utilty function을 사용하였는데, 모든 방면에서 최고를 달성한 utility function은 없었음
- 대신, 우리의 평가 메트릭과 밀접하게 관련이 있는 utility function을 선택하는게 최적이었음
- chrf-2를 utility function으로 사용했을 때, CHRF2 평가 지표에서 가장 높은 성능을 보임
Number of samples
-
sample 크기가 커질수록 MBR의 번역 품질이 높아진다는 것을 확인
- 이는, MBR이 번역 품질을 위태롭게 할 수 있는 beam search curse를 겪지 않는다는 것을 의미
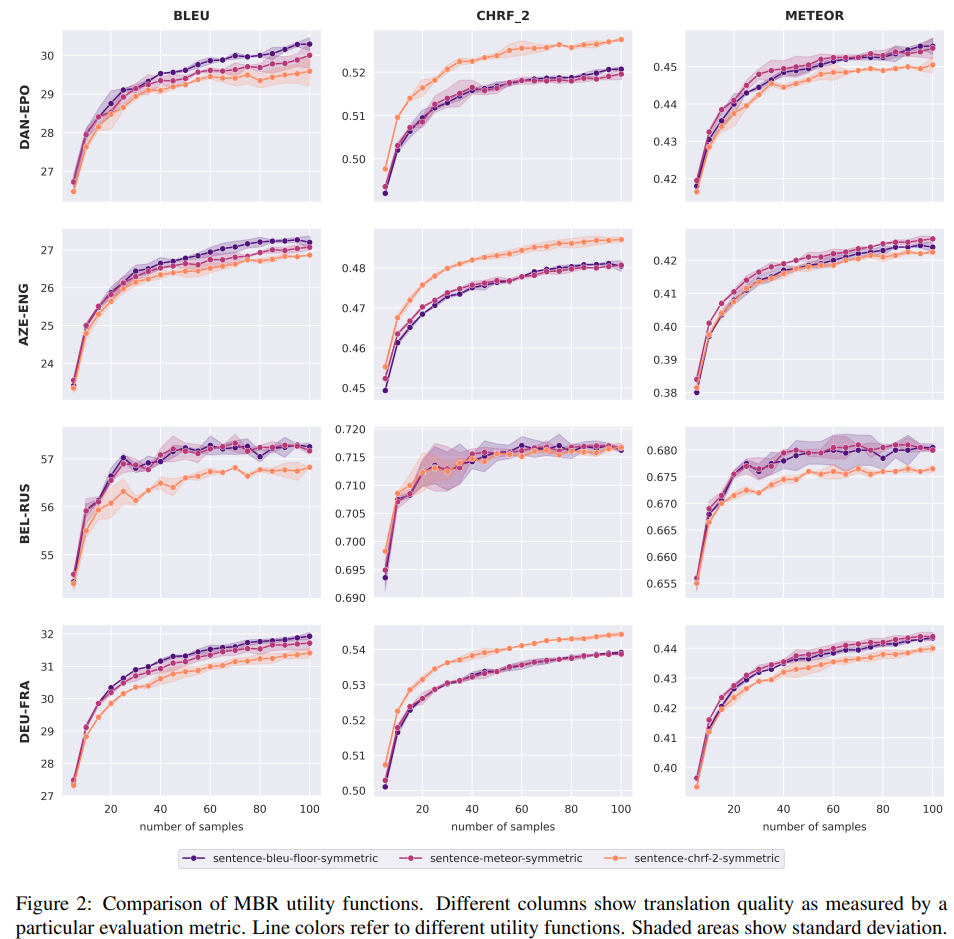
- 이는, MBR이 번역 품질을 위태롭게 할 수 있는 beam search curse를 겪지 않는다는 것을 의미
-
아래 표와 같이 번역문의 길이를 보사해본 결과, 평균적으로 beam search는 번역문의 true length를 과소평가하지만 샘플링에 의해 생성된 후보 번역문들은 reference length와 보다 더 가까움
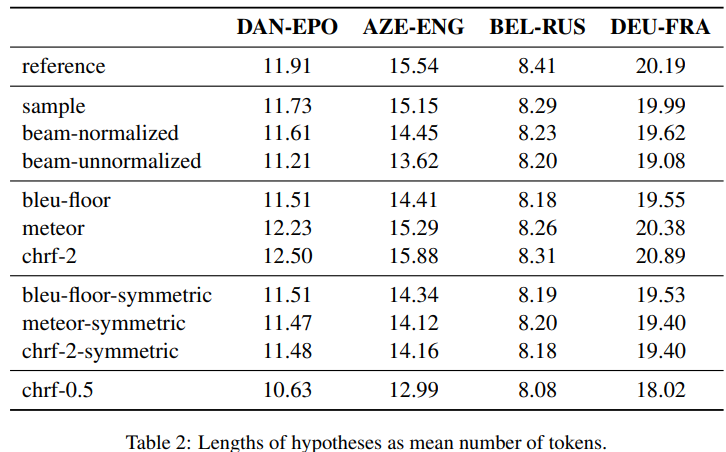
(근데 사실 별 차이 없는거 아닌가..) -
MBR decoding에서 utilty function의 선택이 생성한 번역문의 길이에 큰 영향을 끼친다는 것을 알 수 있음
- 예를 들어, sentence-level BLEU를 utility function으로 사용한 경우, 번역문이 너무 짧아짐
- BLEU는 precision based metric이므로 sentence level에서 더 짧은 번역문을 선호
- chrf-2와 meteor는 recall을 더 강조하기 때문에 MBR 번역이 번역문의 true length를 과대 평가함
- 반대로 chrf-0.5와 같이 precision에 편향이 있는 chrf의 변형은 번역문이 짧게 나오는 경향이 있음
-
이러한 length biases를 줄일 수 있는지 확인하기 위해 다음과 같이 utiliyy function u를 symmetrizing함
(이 때 H는 harmonic mean을 의미) -
이렇게 하면 recall 또는 precision을 선호하는 경향을 피할 수 있지만, 사실 symmetric utility function도 평균적으로 reference보다 길이가 짦음
-
이러한 실험을 토대로, MBR이 uility function과 연관된 length biases를 가진다고 결론 지음
6 Token frequency bias
- Beam search는 학습 데이터에서 흔한 토큰을 과대 생성하고, 희귀한 토큰은 과소 생성한다
- 반면에 샘플링은 흔한 코튼과 희귀 토큰에 올바른 확률을 할당
- 아래 그림을 보면, beam search에 비해 MBR은 probabilities의 skewdeness는 덜하지만, 여전히 frequent event에 너무 높은 확률을 할당하고 있다는 것을 알 수 있다
- 이러한 현상의 이유는, 우리의 utility function는 샘플들 사이의 표면적인 유사도를 기반으로 하기때문에 드물게 샘플링되는 희귀 토큰의 경우, 여전히 low utility를 갖게 되기 때문
- 이는, trade-off between correct probability statistics for very common and very rare words and translation quality가 있다고 볼 수 있음
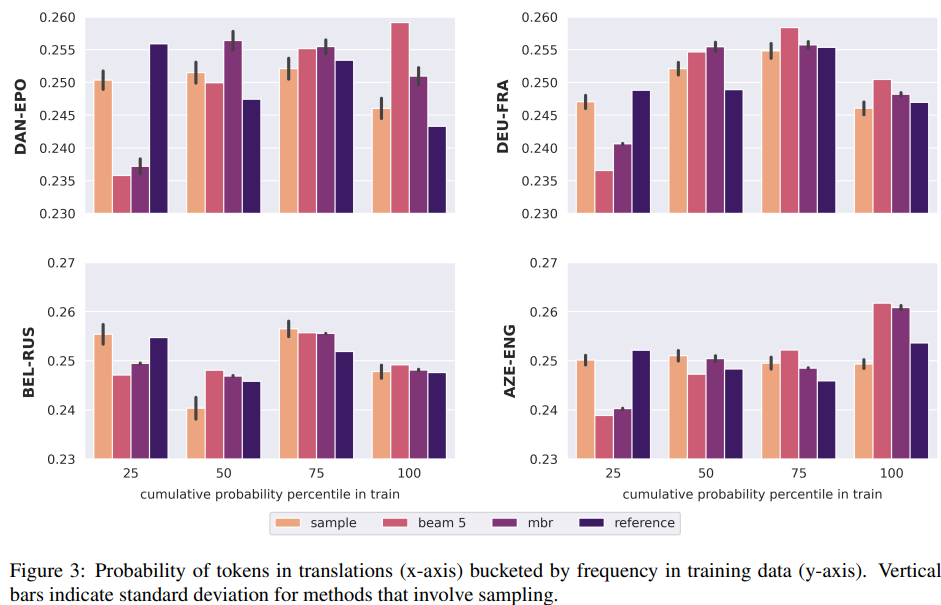
7 Domain robustness
- 일반적으로, 샘플 크기가 증가함에 따라 MBR은 beam searh의 성능이 근접해지지만 더 좋아지진 않음
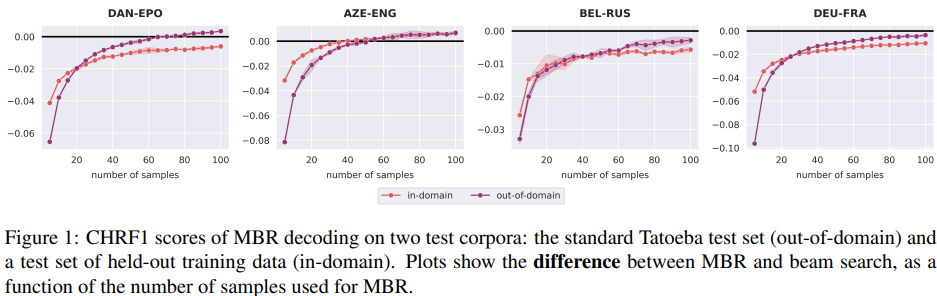
- out-of-domain data에서는 MBR과 beam seach의 갭이 더 작아짐
- MBR은 out-of-domain translation에 유용할 것이라는 가설 설정
- MBR의 domain robustness를 평가, 아래 그림을 보면 unknown test domain 4개 중 2개에선 beam search보다 뛰어남.
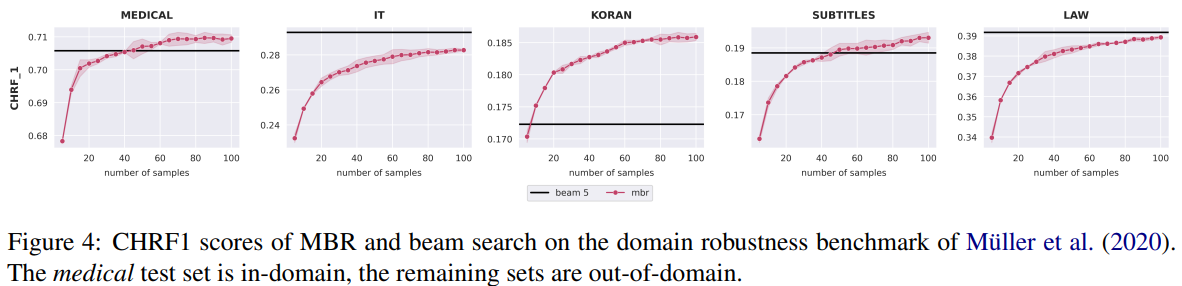
- MBR이 beam search보다 unknown domain에서 뛰어난 이유는, hallucinated translation이 줄기 때문
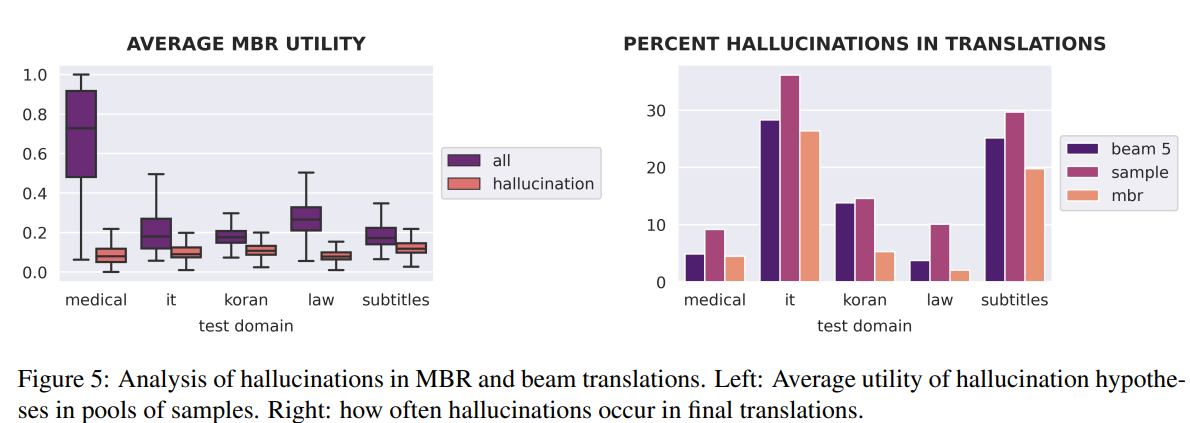
- 이러한 가설을 검증하기 위해, 우리는 reference와 비교했을 때, CHRF2 점수가 0.01보다 낮은 번역문을 hallucination으로 정의
- 이러한 hallucination의 정의에 따라, 아래 그림을 보면 평균적으로 MBR이 이러한 hallucination이 있는 번역문에 더 낮은 utility score를 배정한다는 것을 알 수 있음
- 유사하게, MBR에서 beam search나 sampling에 비해 최종 번역문에서 hallucination이 있을 확률이 낮음
- 요약하면, beam search에 비해 MBR decoding이 더 높은 domain robustness를 보인다
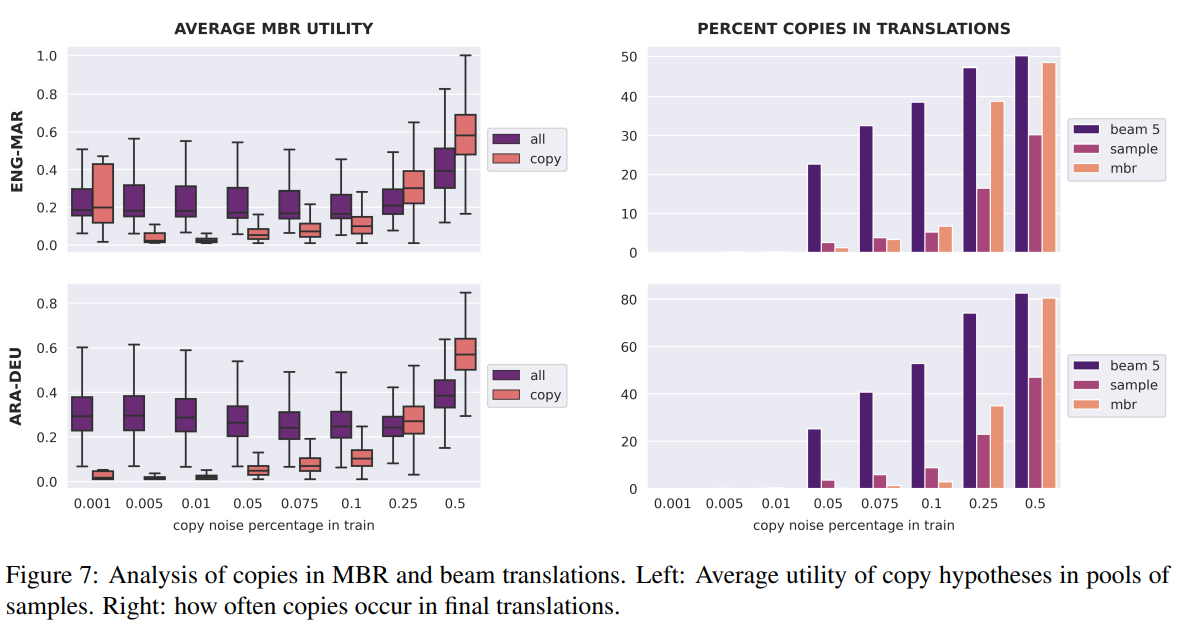
8 Impact of copy noise in the training dta
-
학습 데이터에서 원문의 copy가 target side에 존재할 경우, copies는 beam search에서 과대표현됨
-
MBR도 이와 같은 현상을 겪는지 확인하기 위해, 기존 학습데이터를 바탕으로 원문 copy 비율을 0.1%에서 50%사이로 설정.
-
아래 그림을 보면, 학습 데이터의 copy비율이 낮을때는 MBR과 beam search을 비교할만 함
-
하지만, 5%에서 25%사이에서는 MBR이 beam search보다 훨씬 뛰어난 성능을 보임
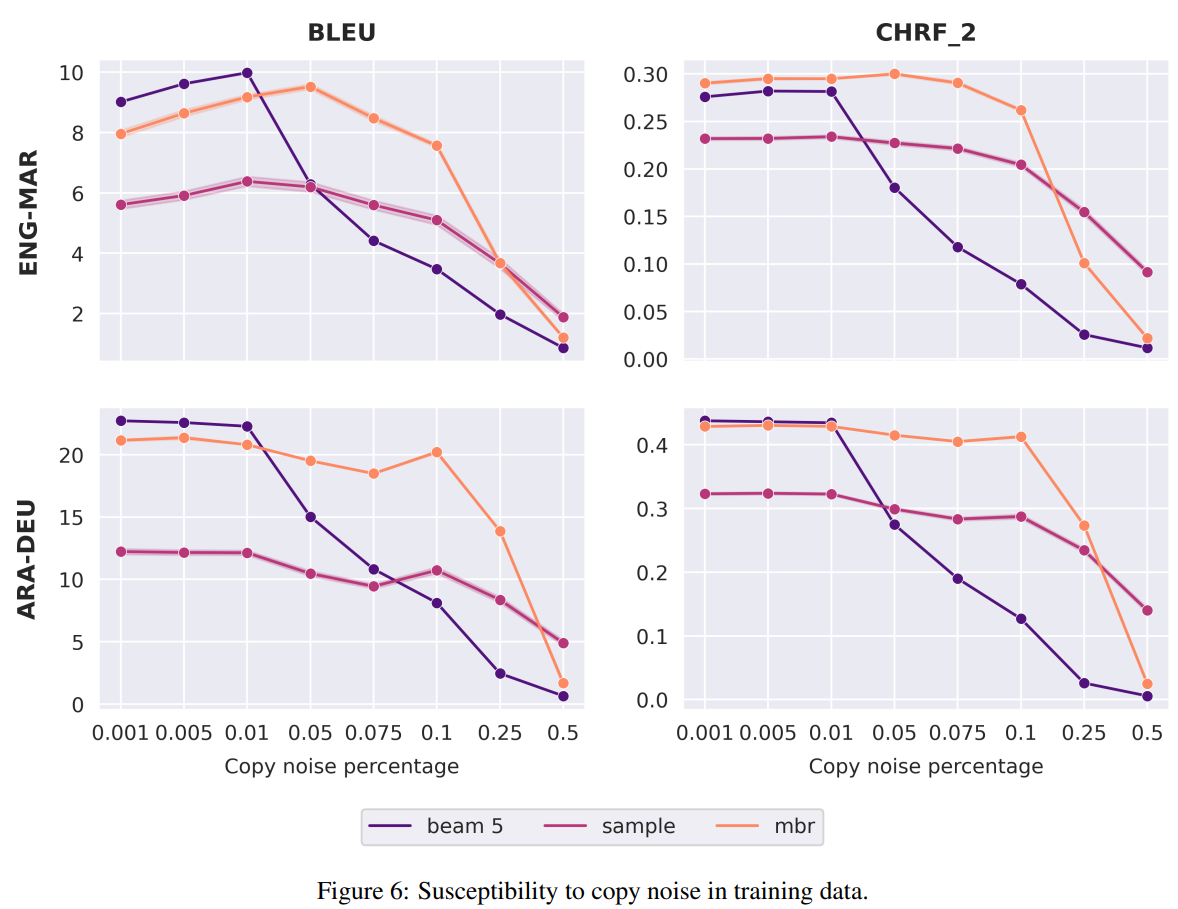
-
번역에서 copy를 reference와 90%이상 단어가 겹칠 경우 copy라고 정의
-
MBR이 copy hypotheses에 훨씬 낮은 utility를 배정, 최종 번역이 copy가 될 확률을 매우 낮음
-
예를 들어, 학습 데이터의 10%가 copies라면, beam search는 거의 50%정도의 copy를 만들지만 MBR는 10%이하의 copy를 만듦
-
즉, MBR이 학습 데이터에 내재된 copy noise에 더 robust하다고 볼 수 있음
9 Conclusion and future work
- 우리가 흔히 쓰는 MT metric을 utility function으로 사용해 MBR decoding의 특성에 대해 연구
- 실험 결과,
- 여전히 beam search와 유사하게 length bias와 token frequency bias를 가짐
(이는 utility function과 밀접하게 관련) - 하지만, domain shift에서 빈번하게 발생하는 copying, hallucination과 같은 문제는 잘 다룸
(pool에 있는 샘플 중 copies나 hallucinated hypotheses는 낮은 utility를 갖기 때문에 최종 번역으로 잘 선태고디지 ㅇ낳음) - 또한, 기존에 automatic metric에 대해선 beam search보다 성능이 좋지 못했지만 robustness측면에서 보면 MAP decoding의 좋은 대안이 될 수 있을 것
- 여전히 beam search와 유사하게 length bias와 token frequency bias를 가짐
