
데이터베이스 (Database)
효율적인 데이터 관리를 위한 조건
- 데이터를 통합해서 관리
- 일관된 방법으로 관리
- 데이터 누락 및 중복 제거(중복은 허용해야 하는 경우가 있긴함- 속도개선)
- 여러 사용자가 공동으로 실시간 사용이 가능해야 한다
✅ Microservice Architecture의 진화
🔹 초창기
- 모든 서비스가 하나의 데이터베이스를 공유
→ 서비스 간 데이터 일관성 유지가 쉬움
→ 하지만 서비스 간 강한 결합(Coupling)이 발생
[공통 DB]
├── 서비스1
├── 서비스2
└── 서비스3🔹 최근: 마이크로서비스 + 독립 데이터베이스
- 각 서비스가 자신만의 데이터베이스를 가짐
→ 서비스 간 결합도 ↓, 독립적 배포 가능
→ 그러나 데이터 동기화/중복 문제 발생
[DB1] ← 서비스1
[DB2] ← 서비스2
[DB3] ← 서비스3❗️문제점
-
데이터 동기화 문제: 각 DB가 독립되다 보니, 다른 서비스에서 동일한 데이터가 변경되어도 반영되지 않을 수 있음
-
데이터 중복 문제: 동일한 데이터를 각 서비스가 따로 저장 → 중복 저장 발생
✅ CQRS (Command Query Responsibility Segregation)
CQRS는 명령(Command)과 조회(Query) 책임을 분리하는 아키텍처 패턴입니다.
-
Command 모델 → 데이터 수정 전용 (예: MySQL, PostgreSQL 등 RDB)
-
Query 모델 → 데이터 조회 전용 (예: MongoDB, Elasticsearch 등 NoSQL)
예시
사용자 수의 비대칭
- 수정을 하는 사람: 1만 명
- 조회를 하는 사람: 100만 명
→ 조회와 수정을 분리해 성능과 확장성 모두 확보
✅ CQRS 적용 시 필수 요소: 데이터 동기화
-
수정한 데이터를 조회용 DB로 동기화해야 함
-
실시간 또는 지연 동기화를 위한 기술이 필요
🔧 동기화 기술
-
Kafka (이벤트 스트리밍): 실시간 데이터 전파에 적합
-
Batch 처리 시스템: 일정 시간마다 데이터를 묶어서 전달
-
Change Data Capture (CDC): DB 변경을 감지해 전파
1. 데이터베이스 (Database)
-
정의: 데이터베이스는 자료의 집합 또는 자료를 효율적으로 관리하는 기술입니다.
-
다양한 사용자와 애플리케이션이 동시에 데이터를 통합, 저장, 관리, 운영할 수 있도록 지원합니다.
📌 현대적인 데이터베이스의 필수 조건
- 대용량: 많은 데이터를 저장하고 처리할 수 있어야 함
- 효율성: 빠르고 자원 절약적인 처리가 가능해야 함
- 무결성(Integrity): 데이터가 일관되고 오류 없이 유지되도록 보장
- 활용성: 데이터를 다양한 방식으로 쉽게 활용 가능
- 공유성: 여러 사용자가 동시에 접근 가능
- 보안성: 접근 제어와 데이터 보호 기능
2. DBMS (Database Management System)
정의: DBMS는 데이터를 편리하게 관리하고, 효율적으로 저장 및 검색할 수 있는 환경을 제공하는 소프트웨어입니다.
📌 DBMS의 필요성
- 생산성 향상: 데이터 생성/조회/수정/삭제가 쉬움
- 기능성 향상: 트랜잭션, 동시성, 백업 등 다양한 기능 제공
- 신뢰성 향상:
- 확장성(Scalability): 시스템이 커져도 성능 유지
- 부하분산(Load Balancing): 여러 사용자 요청을 효율적으로 분산
📌 DBMS의 3대 기능
-
정의 기능: 데이터 구조와 스키마 정의 (테이블, 관계 등)
-
조작 기능: 데이터 조회, 삽입, 수정, 삭제 등 CRUD 기능
-
제어 기능: 보안, 접근 제어, 무결성 유지, 트랜잭션 처리, 장애 복구 등
📚 DBMS의 역사
| 시대 | 특징 |
|---|---|
| 1960년대 | 🔹 파일 시스템 기반 (Flat File) 예: CSV, 텍스트 파일 ❗ 단점: 데이터 중복, 무결성 유지 어려움, 검색 불편 |
| 1970년대 | 🔹 계층형 DBMS (Hierarchical) – 부모-자식 구조 🔹 네트워크형 DBMS (Network) – 복잡한 다대다 관계 표현 가능 |
| 1980년대 | 🔹 관계형 DBMS (RDBMS) 등장 📌 테이블 기반 구조, SQL 사용 예: Oracle, IBM DB2, MySQL |
| 1990년대 | 🔹 관계형 DBMS (RDBMS) 🔹 객체지향형 DBMS 등장 🔹 객체-관계형 DBMS (ORDBMS) – 객체 개념과 관계형 구조의 혼합 |
| 2000년대 이후 | 🔹 NoSQL DB – 비정형/대용량 데이터 처리에 적합 - Key-Value: Redis - Document: MongoDB - Wide Column: Cassandra, HBase - Graph: Neo4j 🔹 분산 파일 시스템 – 예: Hadoop, HDFS 🔹 클라우드 환경과 빅데이터 처리를 위한 구조로 발전 |
3. RDBMS (Relational Database Management System)
RDBMS는 데이터를 테이블의 집합으로 관리하는 데이터베이스 관리 시스템입니다.
📌 RDBMS 종류
-
상용 RDBMS:
- Oracle
- MySQL
- IBM의 DB2
- MS의 MS-SQL Server
- SAP의 HANA DB
- Tibero
-
오픈소스 RDBMS:
- MySQL
- SQLite
- MariaDB (MySQL fork)
- PostgreSQL
📌 RDBMS 구성 요소
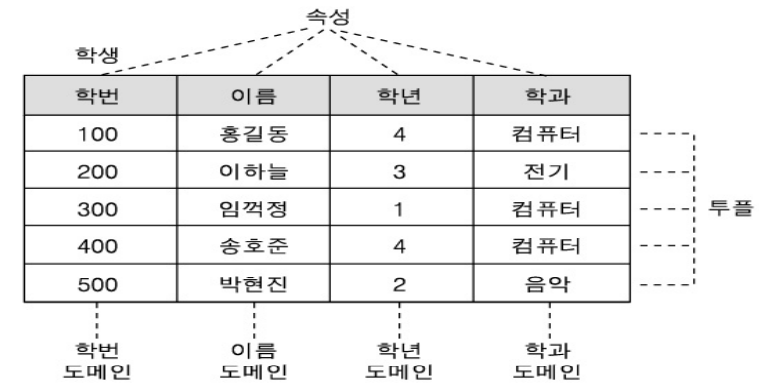
- 릴레이션(Relation): 테이블
- 속성(Attribute): 테이블의 열(Column)
- 도메인(Domain): 속성이 가질 수 있는 값들의 집합 (자료형, 값의 집합)
- 튜플(Tuple): 테이블의 행(Row) 또는 레코드(Record)
- 기수(Cardinality): 하나의 테이블에서 행의 수, 또는 서로 다른 테이블 간 대응되는 수
- 예: 테이블 간 1:1 관계 → 기수 = 1
- 1:N 관계 → 기수 = n
- 차수(Degree): 테이블에서 속성(열)의 수
- 제약조건(Constraint): 데이터 무결성을 보장하기 위해 저장할 데이터에 적용되는 검사 규칙
📌 key
Key는 각 튜플을 유일하게 식별할 수 있는 속성 또는 속성 집합입니다.
1. 슈퍼키(super key)
- 속성의 개수에 상관없이 유일성을 보장하는 속성 또는 속성의 집합입니다.
- 예: 학번, 전화번호 등
2. 후보키(candidate key)
- 속성의 개수를 최소로 해서 구분하는 key 이며, 최소성을 만족하는 유일한 식별자가 되는 키입니다.
예시
| 학번 | 전화번호 | 이름 | 학과 |
|---|---|---|---|
- 후보키 : 학번, 전화번호
- 만약에 같은 학과에 같은 이름이 없다는 가정 : 학과 + 이름 -> 후보키
학번과 이름을 합친건 후보키가 될 수 없음 - 이미 학번만으로도 구분이 가능하니까 최소성이 있어야하기 때문
3. 기본키(primary key)
- 후보키 중에서 하나 선정한 키
4. 대체키(alternate key)
- 기본키가 아닌 후보키
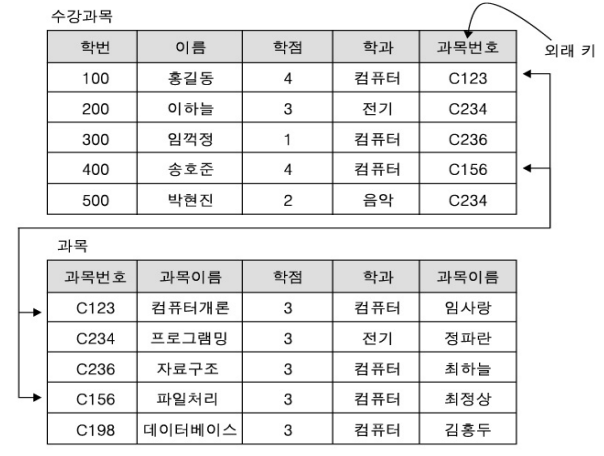
5. 외래키(foreign key)
- 다른 테이블에서 튜플을 식별하기 위한 key
- 테이블 간 관계 설정에서 참조 무결성을 유지할 수 있도록 합니다.
- 외래키는 다른 테이블의 기본키나 고유키(Unique Key)를 참조합니다.
데이터베이스 이론에서는 현재 테이블에서는 아무런 제약이 없지만 다른테이블에서는 기본키 이지만,
데이터베이스 실제에서는 현재 테이블에서는 아무런 제약이 없지만 다른테이블에서는 기본키 이거나 unique 하면 된다
외래키 설정방법:
- 1:1 관계 : 각 테이블의 기본키를 상대방 테이블의 외래키로 추가
- 1:N 관계 : 1쪽 테이블의 기본키를 N쪽 테이블의 외래키로 추가
- N:M 관계 : 양쪽 테이블의 기본키를 이용해서 별도의 테이블을 생성하고, 양쪽 테이블의 기본키를 외래키를 다시 설정
📌 제약조건
1. 개체무결성(Entity Integrity)
- 기본키는 null이 될 수 없고, 중복이 있을 수 없다.
2. 참조 무결성(Referential Integrity)
- 외래키는 참조할 수 없는 값이 될 수 없다.
- 외래키는 반드시 존재하는 데이터를 참조하거나,NULL이어야 한다.
📌 RDBMS의 개체들
-
Table: 데이터가 저장되는 기본 구조
-
View: 자주 사용하는 SELECT 구문을 저장하여 테이블처럼 사용할 수 있는 가상 테이블
-
Index: 데이터를 빠르게 조회할 수 있도록 도와주는 개체
-
Synonym: 다른 개체의 별명을 정의하는 개체
-
Sequence: 일련번호를 자동으로 생성해주는 개체
-
Procedure: 일련의 SQL 작업을 코드 블록으로 묶은 것
-
Function: 결과값을 리턴하는 코드 블록
-
Trigger: DML(Data Manipulation Language) 문장이 수행될 때 자동으로 실행되는 개체
4. SQL(Structured Query Language)
SQL : DBMS에 질의를 수행하기 위한 언어
📌 SQL의 특징
- 비절차적 : 작성한 순서대로 실행되지 않는다. SQL은 사용자가 "무엇을 할 것인가"를 정의하며, 실행 순서를 명시하지 않습니다. DBMS가 최적의 실행 계획을 수립하여 쿼리를 처리합니다.
- 집합 처리 : 처리 단위는 튜플 각각이 아니라 튜플들을 집합 단위로 처리
SQL의 분류
- DDL : 데이터 구조 정의(Create), 구조 수정(Alter), 구조 삭제(Drop), 이름변경(Rename), 데이터만 전체 삭제(Truncate)
- DCL : 권한 부여(Grant) , 권한 취소(Revoke)
- TCL : 트랜잭션 관련 명령어, Commit(작업 완료), Rollback(작업 취소), Savepoint(저장점 생성)
- DML : 데이터 추가(Insert),데이터 수정(Update), 데이터삭제(Delete)
- DQL : 데이터 조회(Select)
