Grouping Function
1. 집계함수
집계함수란 데이터를 그룹화해서 통계를 계산해주는 함수로 숫자나 날짜 데이터에 사용한다.
GROUP BY 이후에 그룹화가 이루어지므로 HAVING절이나 SELECT절에서만 사용이 가능하다.
GROUP BY절이 존재하는 경우 SELECT절에서는 GROUP BY에 사용된 컬럼과 집계함수만 사용이 가능하다. MariaDB와 MySQL은 사용이 가능하다.
1) 집계함수 종류
SUM
AVG
COUNT
MAX
MIN
STDDEV
VARIANCE
COUNT
COUNT(컬럼이름) : 데이터의 개수를 세는 함수
NULL인 데이터를 제외하고 개수를 센다.
컬럼 이름 대신에 *을 사용해서 모든 데이터의 개수를 세기도한다
예시) EMP테이블의 데이터 개수 조회
select count(ename), count(comm),count(*)
from emp;
null이 포함된 값은 개수가 적게 나오기 때문에 모든 데이터 개수를 세기 위해서는 *을 이용한다.
SUM , AVG
SUM(컬럼) AVG(컬럼) : 합계와 평균을 구해주는 함수이고 NULL인 데이터를 제외하고 연산을 한다.
이 함수는 문자열 컬럼을 사용할 수 없습니다.
select sum(SAL),ROUND(AVG(SAL))
FROM EMP;
MAX , MIN, STDDEV, VARIANCE
최대, 최소, 표준편차, 분산
COUNT 함수는 모든 데이터가 NULL인경우 0을 리턴하지만 나머지 함수들은 NULL을 리턴한다.
2. GROUP BY
컬럼의 값이나 연산의 결과가 동일한 데이터끼리 모아서 처리하는 절이다.
이 절에 사용한 컬럼과 집계함수를 같이 출력하고 2개 이상의 컬럼으로 묶는 것도 가능하다.
예시) EMP 테이블에서 JOB 별로 묶어서 각 JOB의 SALARY의 합계를 조회
select job, sum(sal)
from emp
group by job;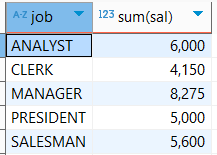
표준 SQL에서는 GROUP BY가 있는 경우 SELECT 절에서 그룹화한 컬럼과 집계함수만 사용이 가능한데 MariaDB에서는 다른 컬럼을 조회해도 에러가 나지 않고 첫번째 데이터가 조회된다.
-- ENAME의 첫번째 데이터가 출력됨
select ENAME, job, sum(sal)
from emp
group by job;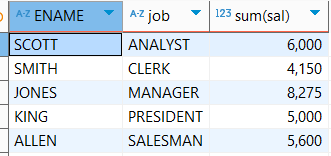
2개 이상 Grouping
select deptno, job, sum(sal)
from emp
group by deptno, job;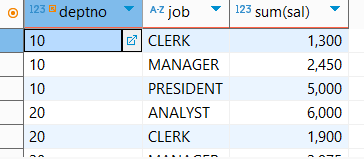
3. HAVING
HAVING 절 : GROUP BY 이후의 조건을 기술하는 절
SQL 문 순서
SELECT -- 5, 열을 필터링 FROM -- 1, 사용할 테이블을 가져옴 WHERE -- 2, 행을 필터링 GROUP BY -- 3, 행들을 그룹화 HAVING -- 4, 그룹화 이후 조건 ORDER BY -- 6, 정렬 LIMIT -- 7, 행의 개수 설정
예시) emp테이블에서 deptno별로 그룹화 한 후 데이터가 4개 이상인 부서의 데이터 개수와 sal의 평균을 구하기
select deptno, COUNT(*), AVG(SAL)
from emp
group by deptno
having COUNT(*) > 3;
4. 연습문제
1. EMP 테이블에서 인원수, 최대 급여(SAL), 최소 급여, 급여의 합을 계산하여 출력하는 SELECT 문장 작성
select count(*),max(sal),min(sal),sum(sal)
from emp;
2. EMP 테이블에서 각 업무별(JOB)로 최대 급여(SAL), 최소급여, 급여의 합을 출력
select job,max(sal) '최대급여',min(sal) '최소급여',sum(sal) '급여합계'
from emp
group by job;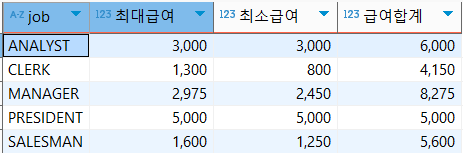
3. emp테이블에서 업무별 인원수를 구하여 출력
select job,count(*)
from emp
group by job;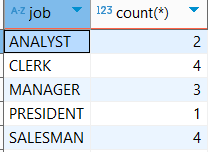
4. emp 테이블에서 최고 급여(sal)와 최소급여의 차이는 얼마인지 출력
select max(sal) - min(sal)
from emp;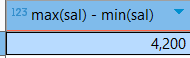
Window 함수
윈도우함수란 행과 행 사이의 관계를 쉽게 정의하기 위해서 제공되는 함수이다.
-
OVER절을 포함하게 되는데 집계함수(AVG(), COUNT(), MAX(), MIN(), STDDEV(), SUM(), VARIANCE())와 같이 사용하는 경우도 많음
-
윈도우함수와 함께 사용되는 비집계함수에는 CUME_DIST(), DENSE_RANK(), FIRST_VALUE(), LAG(), LAST_VALUE(), LEAD(), NTH_VALUE(), NTILE(), PERCENT_RANK(), RANK(), ROW_NUMBER() 등이 있음
1. 순위 함수
- 함수 :
RANK(),NTILE(),DENSE_RANK(),ROW_NUMBER()
기본형식
순위함수( ) OVER(
[PARTITION BY 파티션 리스트]
ORDER BY 정렬 리스트)ROW_NUMBER
: 일련번호
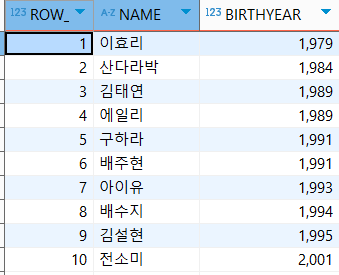
select ROW_NUMBER() OVER(ORDER BY birthyear ASC, name ASC), NAME, BIRTHYEAR
FROM usertbl;나이가 같을 시 이름 순으로 정렬
파티션
-- 지역별로 나누기
select addr, ROW_NUMBER() OVER(PARTITION BY addr ORDER BY birthyear ASC, name ASC) '나이 많은 순', NAME, BIRTHYEAR
FROM usertbl;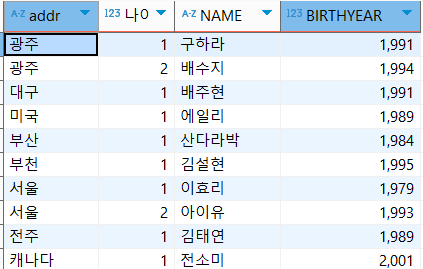
DENSE_RANK
: 동일한 값은 동일 순위를 설정하는데 다음 순위는 건너뛰지 않는다
select DENSE_RANK() OVER(ORDER BY birthyear ASC) '나이 많은 순', NAME, BIRTHYEAR
FROM usertbl;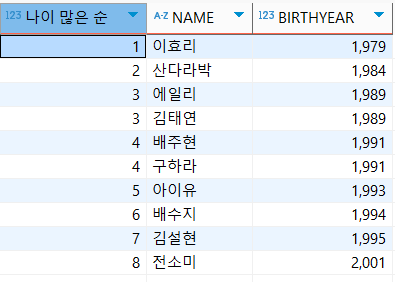
RANK
: 동일한 값은 동일 순위를 설정하는데 다음 순위 건너뛰기
select RANK() OVER(ORDER BY birthyear ASC) '나이 많은 순', NAME, BIRTHYEAR
FROM usertbl;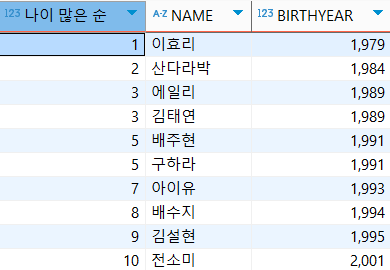
NTILE
: N등분하기, 등분을 나누어서 각 등급을 조회하는 것이다
select NTILE(5) OVER(ORDER BY birthyear ASC) '나이 많은 순', NAME, BIRTHYEAR
FROM usertbl;
분석함수
CUME_DIST(), LEAD(), FIRST_VALUE(), LAG(), LAST_VALUE(), PERCENT_RANK() 등
LEAD
: 다음 행과의 차이, 현재 행 - 다음행
select name, addr, birthyear as '태어난해', birthyear - (LEAD(birthyear,1) over(order by birthyear desc)) as '나이차이'
from usertbl;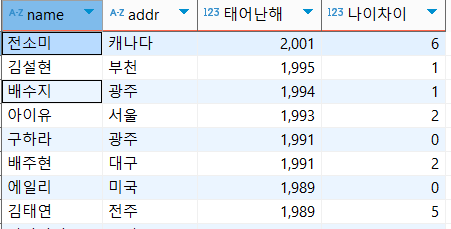
LAG
: 이전 행과의 차이, 현재행 - 이전행
select name, addr, birthyear as '태어난해', birthyear - (LAG(birthyear,1) over(order by birthyear desc)) as '나이차이'
from usertbl;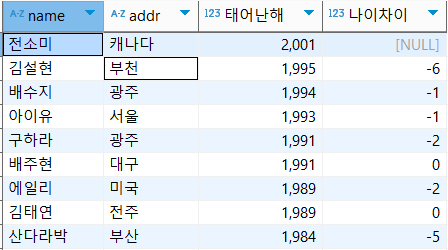
FIRST_VALUE
: 첫번째 행과의 차이
select name, addr, birthyear as '태어난해', birthyear - (FIRST_VALUE(birthyear) over(order by birthyear ASC)) as '나이차이'
from usertbl;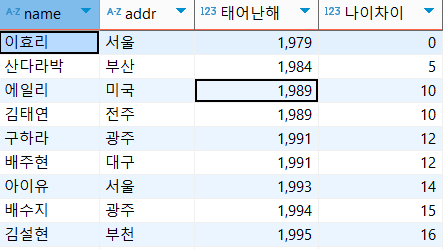
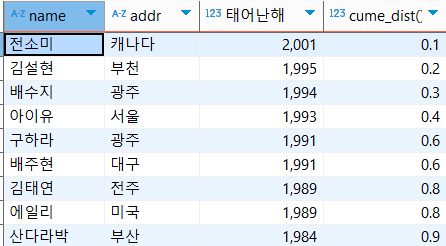
CUME_DIST
: 누적 비율
select name, addr, birthyear as '태어난해', cume_dist() over(order by birthyear desc)
from usertbl;