
정규 표현식 (Regular Expression)
정규식(Regular Expression)은 문자열에서 특정 내용을 찾거나 대체 또는 발췌하는데 사용된다.
대표적으로 입력칸에 전화번호나 이메일을 입력하라고 했을때 옳지 않은 값을 입력하면 정규표현식에 의해 필터링되어 걸러져 경고창을 띄우는 화면을 본적이 있을 것이다.
이처럼 반복문과 조건문을 사용해야 할것같은 복잡한 코드도 정규표현식을 이용하면 매우 간단하게 표현할 수 있으며 주로 다음과 같은 상황에서 굉장히 유용하게 사용된다.
각각 다른 포맷으로 저장된 엄청나게 많은 전화번호 데이터를 추출해야 할 때
사용자가 입력한 이메일, 휴대폰 번호, IP 주소 등이 올바른지 검증하고 싶을 때
코드에서 특정 변수의 이름을 치환하고 싶지만, 해당 변수의 이름을 포함하고 있는 함수는 제외하고 싶을 때
특정 조건과 위치에 따라서 문자열에 포함된 공백이나 특수문자를 제거하고 싶을 때
// 회원가입 할때 휴대폰번호 양식 검사
// 예를 들어 010-1111-2222 라는 전호번호는
// "숫자3개", "-", "숫자4개", "-", "숫자4개" 로 이루어져 있는데,
const regex = /\d{3}-\d{4}-\d{4}/;
// (\d는 숫자를 의미하고, {} 안의 숫자는 갯수를 의미한다.)
regex.test('010-1111-2222') // true;
regex.test('01-11-22') // false;그러나 정규표현식은 주석이나 공백을 허용하지 않고 여러가지 기호를 혼합하여 사용하기 때문에 가독성이 좋지 않다는 문제가 있다는 단점이 있다.
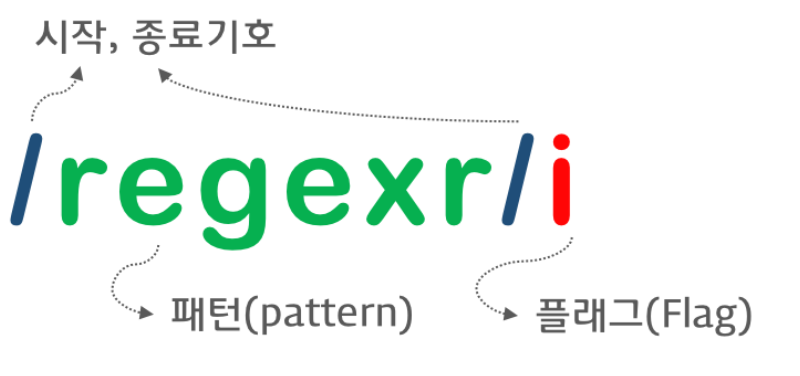
정규식 구성
정규식 구성 코드는 다음과 같다.
슬래쉬 문자 두개 사이로 정규식 기호가 들어가는 형태이다. 뒤의 i 는 정규식 플래그이다.
// 리터럴 방식
const regex = /abc/;
// 생성자 방식
const regex = new RegExp("abc");
const regex = new RegExp(/abc/); // 이렇게 해도 됨아래 예제는 자바스크립트 코드지만 대부분의 언어의 정규식 문법은 비슷하니, 하나의 언어의 정규식을 잘 익혀두면 다른 언어의 정규식을 익히는데 아주 빠르게 학습이 가능하다.
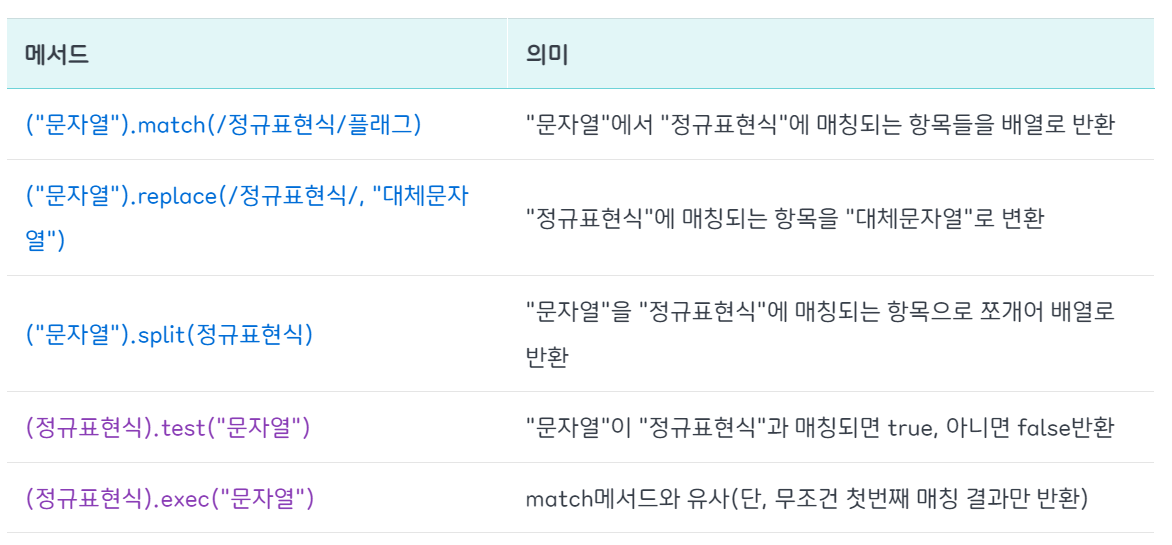
정규식 메서드
위의 정규표현식을 가지고 이메일이나 전화번호 매칭 필터링을 하기위해선 자바스크립트 정규식 메서드를 이용하여 패턴을 검사하고, 매칭되는 문자열을 추출, 변환한다.
// 정규표현식을 담은 변수
const regex = /apple/; // apple 이라는 단어가 있는지 필터링
// "문자열"이 "정규표현식"과 매칭되면 true, 아니면 false반환
regex.test("Hello banana and apple hahahaha"); // true
// "문자열"에서 "정규표현식"에 매칭되는 항목들을 배열로 반환
const txt = "Hello banana and apple hahahaha";
txt.match(regex); // ['apple']
// "정규표현식"에 매칭되는 항목을 "대체문자열"로 변환
txt.replace(regex, "watermelon"); // 'Hello banana and watermelon hahahaha'정규식 플래그
정규식 플래그는 정규식을 생성할 때 고급 검색을 위한 전역 옵션을 설정할 수 있도록 지원하는 기능이다.
// flags 에 플래그 문자열이 들어간다.
cosnt flags = 'i';
const regex = new RegExp('abapplec', flags);
// 리터럴로 슬래쉬 문자뒤에 바로 표현이 가능
const regex1 = /apple/i;
const regex2 = /apple/gm;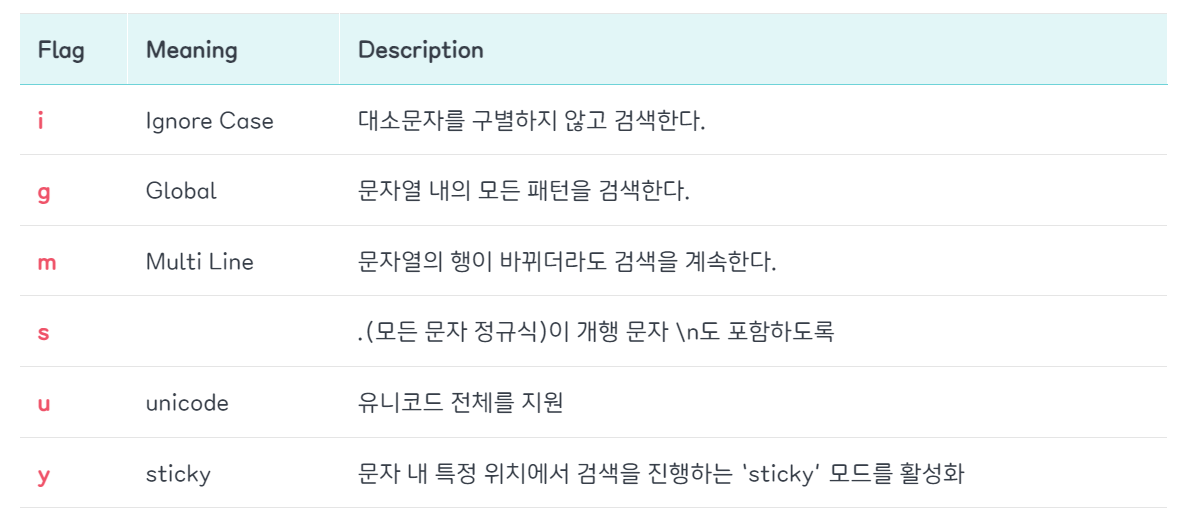
g : 전역 검색
전역 검색 플래그가 없는 경우에는 최초 검색 결과 한번만 반환하는 반면,
전역 검색 플래그가 있는 경우에는 모든 검색 결과를 배열로 반환
// `a`가 두 개 포함된 문자열
const str = "abcabc";
// `g` 플래그 없이는 최초에 발견된 문자만 반환
str.match(/a/); // ["a", index: 0, input: "abcabc", groups: undefined]
// `g` 플래그가 있으면 모든 결과가 배열로 반환
str.match(/a/g); // (2) ["a", "a"]m : 줄바꿈 검색
여러 줄의 문자열에서 필터링 해야 될때 사용된다.
뒤에서 배울 입력 시작(^) 앵커나 입력 종료($) 앵커는 전체 문자열이 아닌 각 줄 별로 대응되게 만들어졌기 때문에, 만일 여러줄을 검색해야 한다면 m 플래그를 사용한다고 보면 된다
// 줄바꿈이 포함된 3줄 문자열
const str = "Hello World and\nPower Hello?\nPower Overwhelming!!";
/*
Hello World and
Power Hello?
Power Overwhelming!!
*/
// Hello 단어로 시작하는지 검사 (^ 문자는 문장 시작점을 의미)
str.match(/^Hello/); // ["Hello"]
// → 첫번째 줄은 잘 찾음
// Power 단어로 시작하는지 검사 (^ 문자는 문장 시작점을 의미)
str.match(/^Power/); // null
// → 그러나 그 다음 줄은 검색되지 아니함
// 따라서 m 플래그를 통해 개행되는 다음 줄도 검색되게 설정
str.match(/^Power/m); // ['Power']
// 세번째 줄도 검색되게 하고싶으면 g 플래그와 혼합 사용
str.match(/^Power/gm); // ['Power', 'Power']i : 대소문자 구분 없음
정규식은 기본적으로 대소문자를 구분 (Case sensitive)
대신 i 플래그를 통해 대소문자 구분 하지 않을수 있다.
const str = "abcABC";
// 대소문자 a 검색
str.match(/a/gi); // (2) ["a", "A"]정규식 특정 문자 숫자 매칭 패턴
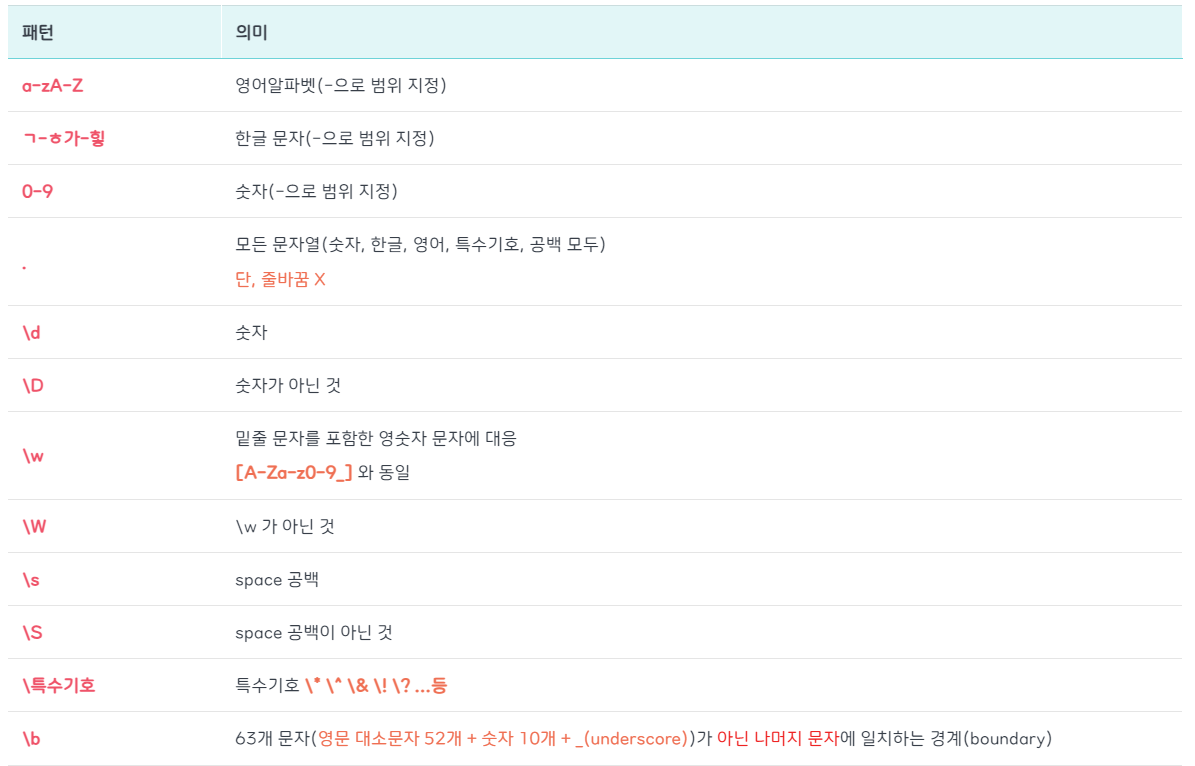
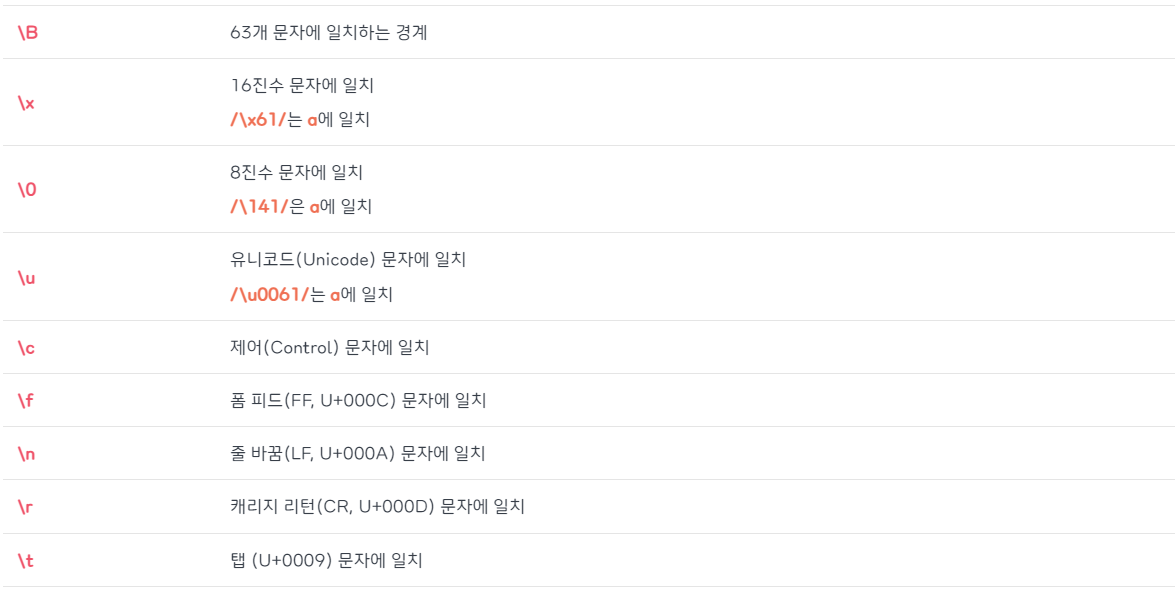
정규식 검색 기준 패턴
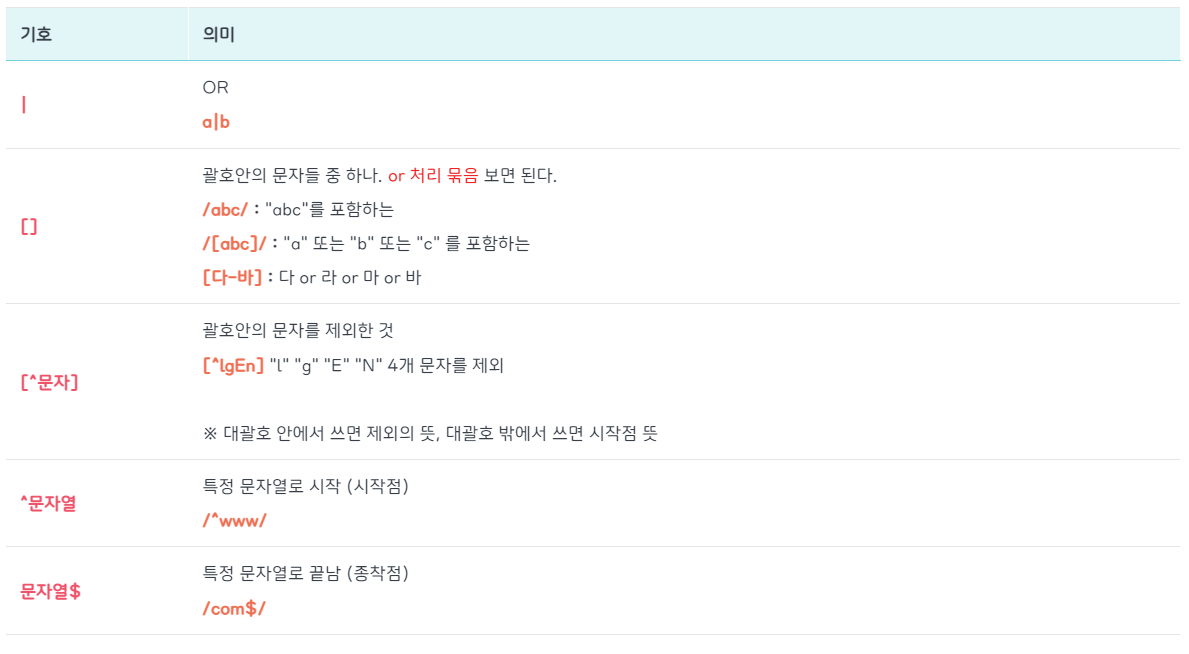
정규식 갯수 반복 패턴
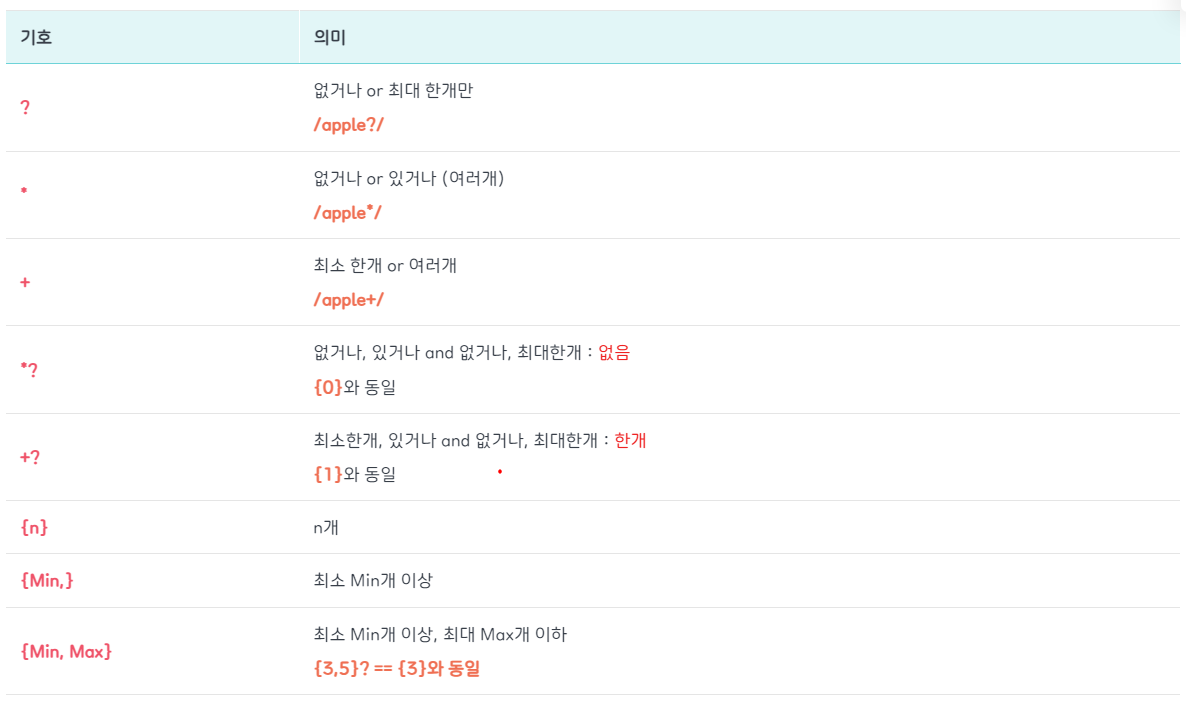
정규식 그룹 패턴
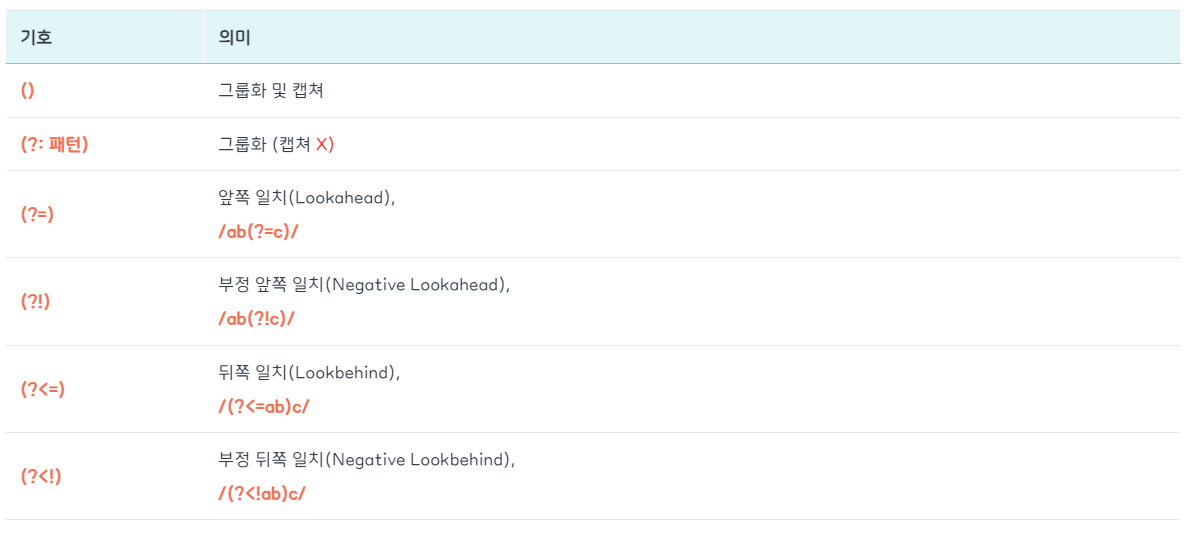
정규식 그룹화
'kokokoko'.match(/ko+/); // "ko"
'kooookoooo'.match(/ko+/); // "koooo"코드를 보면 알수 있듯이, 표현식 ko+는 "o"만 + 를 적용시킨다. ("k" 는 적용안시킴)
그 결과로 "koooo"가 반환되었다.
'kokokoko'.match(/(ko)+/); // "kokokoko", "ko"
'kooookoooo'.match(/(ko)+/); // "ko", "ko"하지만 표현식 (ko)+는 "k"와 "o"를 묶었기(그룹화) 때문에 "ko" 자체를 1회 이상 연속으로 반복되는 문자로 검색하게 된다.
따라서 결과가 "kokokoko"가 반환되었다.
그런데 마지막으로 패턴 ()를 사용한 정규식들의 결과를 잘 보면 일치한 결과가 2개가 나온다.
일부러 한번만 검색되라고, 플래그 g를 사용하지 않았는데 말이다.
정규표현식 샘플 코드
특정 단어로 끝나는지 검사
const fileName = 'index.html';
// 'html'로 끝나는지 검사
// $ : 문자열의 끝을 의미한다.
const regexr = /html$/;숫자로만 이루어져 있는지 검사
const targetStr = '12345';
// 모두 숫자인지 검사
// [] 바깥의 ^는 문자열의 처음을 의미한다.
const regexr = /^\d+$/;아이디 사용 검사
알파벳 대소문자 또는 숫자로 시작하고 끝나며 4 ~10자리인지 검사
const id = 'abc123';
// 알파벳 대소문자 또는 숫자로 시작하고 끝나며 4 ~10자리인지 검사
// {4,10}: 4 ~ 10자리
const regexr = /^[A-Za-z0-9]{4,10}$/;핸드폰 번호 형식
const cellphone = '010-1234-5678';
const regexr = /^\d{3}-\d{3,4}-\d{4}$/;웹사이트 주소 형식
http:// 나 https://로 시작하고, 알파벳, 어더스코어(_), 하이픈(-), dot(.)으로 이루어져 있는 정규식
const text =
`http://dogumaster.com http://google.com 010-1111-2222 02-333-7777 curryyou@aaa.com`;
text.match(/https?:\/\/[\w\-\.]+/g); // ["http://dogumaster.com", "http://google.com"]
/*
1) http => 로 시작하고,
2) s? => 다음에 s는 없거나, 있고,
3) \/\/ => 다음에 특수기호 // 가 오고
4) [\w\-\.]+ => \w(영문자, 언더스코어), 하이픈, 쩜 으로 이루어진 문자열이 한개 이상(+) 있다.
5) g => 매칭되는걸 모두 다 찾는다.(플래그)
*/전화번호 형식
유선번호라면 02-111-2222 형식이고, 핸드폰번호라면 010-1111-2222 형식을 모두 포함하는 정규식 (숫자의 갯수가 다름)
const text =
`http://dogumaster.com http://google.com 010-1111-2222 02-333-7777 curryyou@aaa.com`;
text.match(/\d{2,3}-\d{3,4}-\d{4}/g); // [ '010-1111-2222', '02-333-7777' ]
/*
1) \d{2,3} => 숫자 2~3개로 시작하고,
2) \- => 다음에 하이픈(-)이 오고
3) \d{3, 4} => 다음에 숫자가 3~4개 오고,
4) \- => 다음에 하이픈(-)이 오고,
5) \d{4} => 다음에 숫자가 4개 온다.
6) g => 매칭되는걸 모두 다 찾는다(플래그)
*/이메일주소 형식 - xxx@xxxx.com 등의 형식
const text = `http://dogumaster.com http://google.com 010-1111-2222 02-333-7777 curryyou@aaa.com`;
text.match(/[\w\-\.]+\@[\w\-\.]+/g); // [ 'curryyou@aaa.com' ]
Copy
JAVASCRIPT
// 좀더 엄격한 검사가 필요하다면, 상황에 맞게 수정해서 사용면 된다.
const email = 'ungmo2@gmail.com';
const regexr = /^[0-9a-zA-Z]([-_\.]?[0-9a-zA-Z])*@[0-9a-zA-Z]([-_\.]?[0-9a-zA-Z])*\.[a-zA-Z]{2,3}$/;특수기호 정규표현식
// 모든 특수기호를 나열
const regex = /\[\]\{\}\/\(\)\.\?\<\>!@#$%^&*/g
// 문자와 숫자가 아닌것을 매칭
const regex = /[^a-zA-Z0-9가-힣ㄱ-ㅎ]/g이 밖의 다양한 정규표현식들이 존재
/* 전화번호 */
var localPhone = /^(0(2|3[1-3]|4[1-4]|5[1-5]|6[1-4]))(\d{3,4})(\d{4})$/;
var cellPhone = /^(?:(010\d{4})|(01[1|6|7|8|9]-\d{3,4}))(\d{4})$/;
/* 숫자 형식 */
var number = /[0-9]/;
var unsignedInt = /^[1-9][0-9]*$/;
var notNumber = /[^(0-9)]/gi;
/* 문자 형식 */
var korea_cv = /[ㄱ-ㅎ|ㅏ-ㅣ]/;
var korea = /[가-힣]/;
var koreaName = /[가-힣]/;
var english = /[a-z | A-Z]/;
/* 특문 */
var special_char = /[\{\}\[\]\/?.,;:|\)*~`!^\-+<>@\#$%&\\\=\(\'\"]/;
var comma_char = /,/g;
var blank = /[\s]/g;
/* 아이디 / 비밀번호 */
var id_check = /^[a-z | A-Z]{3,6}[0-9]{3,6}$/;
var password =/^.*(?=.{6,20})(?=.*[0-9])(?=.*[a-zA-Z]).*$/;
/* 이메일 형식 */
var email =/([\w-\.]+)@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.)|(([\w-]+\.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(\]?)$/;
/* 도메인 형식 */
var domain_all =/([\w-\.]+)@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.)
|(([\w-]+\.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(\]?)$/;
var domain_include = /^((http(s?))\:\/\/)([0-9a-zA-Z\-]+\.)+[a-zA-Z]{2,6}(\:[0-9]+)?(\/\S*)?$/;
var domain_exclude = /^[^((http(s?))\:\/\/)]([0-9a-zA-Z\-]+\.)+[a-zA-Z]{2,6}(\:[0-9]+)?(\/\S*)?$/;
/* 영문 한글만 */
var ko_en_num_charactor = /^[가-힣a-zA-Z0-9]*$/;
var ko_en_charactor = /^[가-힣a-zA-Z]*$/;
/* 자동차 번호판 */
var car = /^[0-9]{2}[\s]*[가-힣]{1}[\s]*[0-9]{4}$/;
var old_car = /^[가-힣]{2}[\s]*[0-9]{2}[\s]*[가-힣]{1}[\s]*[0-9]{4}$/;이 정규표현식들을 모두 외우고, 스스로 구현해내야 하는 것은 아니다.
해당 정규표현식의 구조와 방식을 이해할 수 있고, 필요할 경우 수정이 필요한 부분들을 컨트롤 해줄 수 있어야 한다. 모든 정규표현식을 다 구현하고 만들어내야하는 것은 아니다!
자주 사용하는 정규표현식 예제들이 모여있는 사이트이다.
만일 이메일이나 전화번호를 체크하는 정규식 문법이 필요하다면, 검색창에 찾으려는 타입을 치고 검색하면 여러 정규식 예제들을 얻을 수 있다.
https://regexlib.com/?AspxAutoDetectCookieSupport=1
(위 사이트에서 필요한 정규표현식을 참조할 수 있다)
https://new93helloworld.tistory.com/361 콜스택 동작 예제

정말 유익한 글이었습니다.