1. 계기
Kaggle에서 도대체 내가 참여할만한 competition이 무엇이 있을까 하고 찾아보던 중 Lux AI Challenge라는 competition을 발견하게 되었었다. 강화학습과 주어진 파이썬 API를 이용해 참여해야 했는데, 이 당시(8월 말)의 나는 강화학습에 대해서는 정말 아무것도 몰라서 이론부터 시작해야 하는 입장이었다. 그래서 에라이 모르겠다 아주 간단한 것부터 구현해 보면서 감을 잡아야겠다고 느꼈고, cartpole 환경에서 제일 기본적인 이론인 DQN을 구현해보아야겠다고 생각했다
2. 시작
처음 개발은 Deep Q-learning으로 뱀 게임 인공지능 만들기 블로그 사이트를 참조했다. DQN을 코드로 아주 자세하게 정리해두셔서 코드를 통째로 VSCode에 붙여넣고 한줄한줄 주석 달고 뜯어가면서 공부했다. 고등학생 시절부터 책에 하이라이트 치고 옆에 작은 글씨로 주석 달듯이 필기하면서 공부하던 습관이 있었는데 비슷한 공부법이라서 잘 먹히는 것 같다. 시간은 좀 많이 걸리지만...
3. 개발 과정
사실 전체적인 구조는 Deep Q-learning으로 뱀 게임 인공지능 만들기의 구조를 거의 베끼다시피 해서 만들었다. 다만, 코드를 무작정 베끼기보다는 먼저 블로그에 나온 코드 구현을 이해한 후, 스스로 만들어볼려고 노력했다. 사실 구조 자체는 엄청 간단하다.
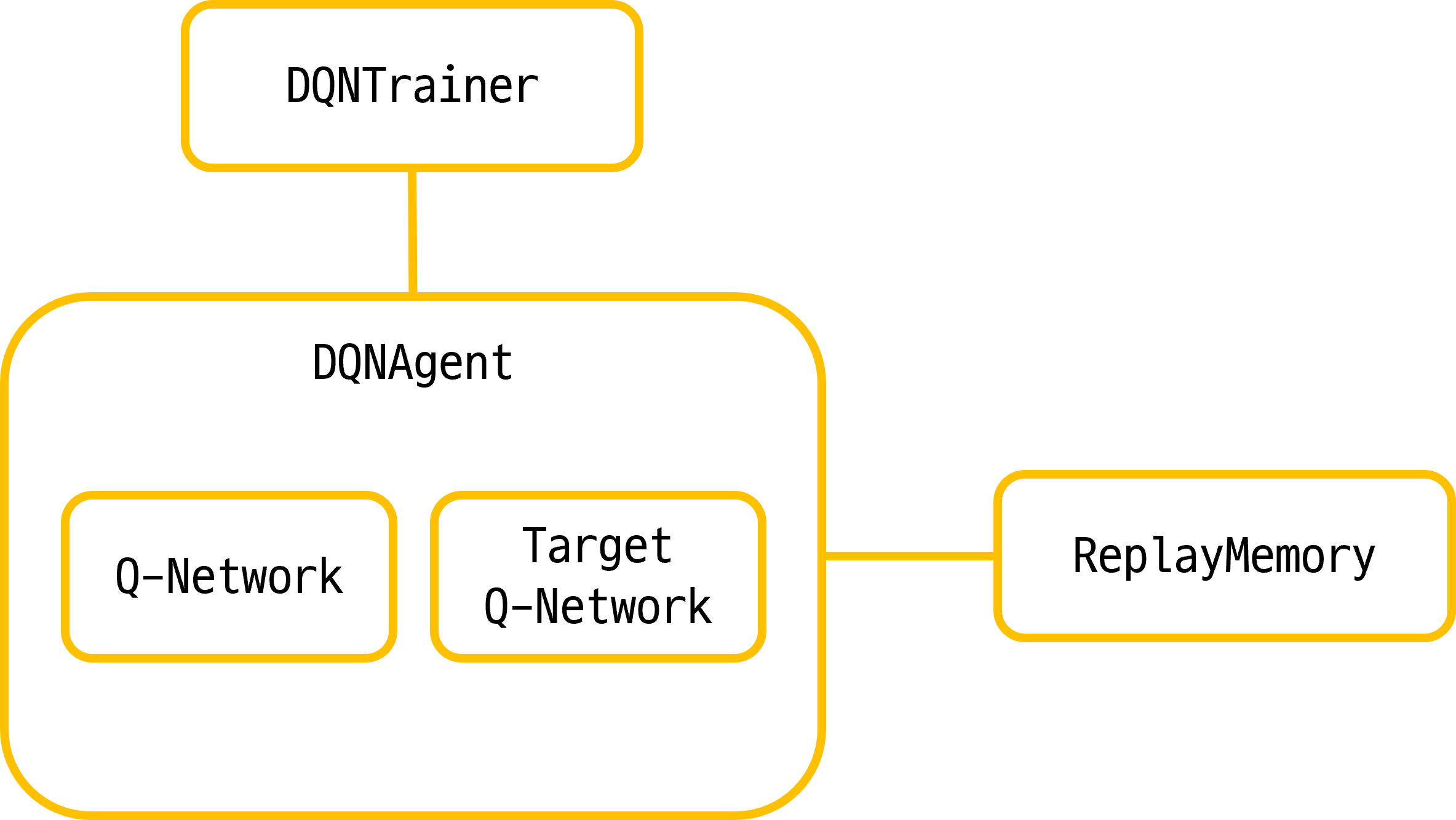
DQNAgent
from tensorflow import keras
from keras import models
from keras import layers
from tensorflow.python.keras.backend import relu, sigmoid
from tensorflow.python.keras.models import Sequential
from ReplayMemory import ReplayMemory
import numpy as np
from ReplayMemory import ReplayMemory
class DQNAgent(object):
def __init__(self, batch_size=100, gamma=0.9):
# 학습에 사용할 model과 target_model을 설정한다
self.model = self._create_model()
self.target_model = self._create_model()
# 처음에는 두 모델을 동일 weight로 설정해준다
self.target_model.set_weights(self.model.get_weights())
self.replayMemory = ReplayMemory()
self.gamma = gamma # 감마, 클수록 미래의 이익을 고려한다
self.batch_size = batch_size
self.callbacks = [
keras.callbacks.TensorBoard(
log_dir="my_log_dir",
histogram_freq=1,
embeddings_freq=1,
)
]
def _create_model(self) -> Sequential:
model = models.Sequential()
model.add(layers.Dense(10, activation=relu, input_shape=(4,)))
model.add(layers.Dense(10, activation=relu))
model.add(layers.Dense(2))
model.compile(optimizer="rmsprop", loss="mse")
return model
def forward(self, data):
return self.model.predict(data)
# replayMemory를 이용해 Agent를 학습
def train(self):
# replayMemory에 저장된 experience의 개수는 2000개 이상이어야 함
if 2000 > len(self.replayMemory):
return
# batch_size만큼 샘플링한다
# (cur_state, action, reward, done, info, next_state) : list
samples = self.replayMemory.sample(self.batch_size)
# batch data를 생성한다
current_states = np.stack([sample[0] for sample in samples])
current_q = self.model.predict(current_states)
next_states = np.stack([sample[5] for sample in samples])
next_q = self.target_model.predict(next_states)
for i, (cur_state, action, reward, done, info, next_state) in enumerate(
samples
):
if done:
next_q_value = reward
else:
next_q_value = reward + self.gamma * np.max(next_q[i])
current_q[i][action] = next_q_value
# 학습!!
self.model.fit(
x=current_states,
y=current_q,
batch_size=self.batch_size,
verbose=False,
)
# target model의 가중치를 model의 가중치로 update 한다
def _update_target_model(self):
self.target_model.set_weights(self.model.get_weights())
def save(
self,
path: str,
model_name: str,
version: str,
num_trained: int,
target_model_name: str = None,
):
"""
모델 저장 이름 예시
/path/cartpole_v5_300_trained.h5
"""
save_name = f"{path}/{model_name}_{version}_{num_trained}_trained.h5"
target_model_name = f"target_{model_name}"
target_save_name = (
f"{path}/{target_model_name}_{version}_{num_trained}_trained.h5"
)
self.model.save(save_name)
self.target_model.save(target_save_name)
def load(
self,
path: str,
model_name: str,
version: str,
num_trained: int,
target_model_name: str = None,
):
save_name = f"{path}/{model_name}_{version}_{num_trained}_trained.h5"
target_model_name = f"target_{model_name}"
target_save_name = (
f"{path}/{target_model_name}_{version}_{num_trained}_trained.h5"
)
self.model = keras.models.load_model(save_name)
self.target_model = keras.models.load_model(target_save_name)
DQNTrainer
self.agent = DQNAgent()로 DQNAgent를 불러온 후, Agent로 Episode를 반복하면서 학습을 진행하도록 하는 것이 주된 목적이다. 학습을 담당하는 코드는 다음과 같다.
from sys import version
from DQNAgent import DQNAgent
import numpy as np
import gym
from tqdm import tqdm
import os
import matplotlib.pyplot as plt
class DQNTrainer(object):
def __init__(
self,
env: gym.Env,
max_episode=500,
step_size=2000,
epsilon=0.99,
epsilon_decay=0.995,
temp_save_freq=100,
model_path=os.path.join(os.getcwd(), "model"),
model_name="model",
version="test",
min_epsilon=0.01,
temp_save=True,
save_on_colab=False,
):
self.agent = DQNAgent()
self.max_episode = max_episode
self.env = env
self.step_size = step_size
self.epsilon = epsilon
# 학습할때 임시로 저장할 빈도
self.temp_save_freq = temp_save_freq
# 모델을 저장할 경로
self.model_path = model_path
# 저장할 모델의 경로
self.model_name = model_name
# 저장할 최종 모델의 버전
self.version = version
self.target_model_path = "target_" + model_path
# epsilon greedy
self.min_epsilon = min_epsilon
self.epsilon_decay = epsilon_decay
# 임시 저장 여부
self.temp_save = temp_save
# colab에서 저장할지 여부
self.save_on_colab = save_on_colab
# episode별로 sum of reward를 저장
self.save_epi_reward = []
self.save_epi_step_num = []
def train(self):
pbar = tqdm(initial=0, total=self.max_episode, unit="episodes")
for episode in range(self.max_episode):
cur_state = self.env.reset()
step, episode_reward, done = 0, 0, False
while not done:
if (np.random.randn(1)) <= self.epsilon:
# 0, 1 중에서 무작위로 수를 하나 뽑는다
action = np.random.randint(2)
else:
# Q(cur_state,a)중에서 가장 값이 높도록 하는 a를 action으로 고른다
output = self.agent.forward(cur_state.reshape(-1, 4))
output = np.argmax(output)
action = output
next_state, reward, done, info = self.env.step(action)
# replayMemory에 결과를 저장한다
self.agent.replayMemory.add(
(cur_state, action, reward, done, info, next_state)
)
# replayMemory를 이용해 학습을 진행한다
self.agent.train()
# 상태 업데이트
cur_state = next_state
episode_reward += reward
step += 1
if done:
break
# target_model의 가중치를 model과 동기화
self.agent._update_target_model()
# epsilon decay
self.epsilon = max(self.epsilon * self.epsilon_decay, self.min_epsilon)
# 설정한 빈도에 따라서 임시 저장
if self.temp_save == True:
if (episode % self.temp_save_freq) == 0:
if self.save_on_colab:
self.colab_save(
model_name=self.model_name,
version=self.version,
num_trained=episode,
)
else:
self.agent.save(
path=self.model_path,
model_name=self.model_name,
version=self.version,
num_trained=episode,
)
pbar.update(1)
self.save_epi_reward.append(episode_reward)
self.save_epi_step_num.append(step)
####### 한 EPISODE 종료 #########
# --------------모든 에피소드 종료---------------- #
# 모든 학습이 끝나면 모델을 저장한다
if self.save_on_colab:
self.colab_save(
model_name=self.model_name,
version=self.version,
num_trained=self.max_episode,
)
else:
self.agent.save(
path=self.model_path,
model_name=self.model_name,
version=self.version,
num_trained=self.max_episode,
)
# episode에 따른 학습결과 (reward의 총합)을 그래프로 표시한다.
plt.plot(self.save_epi_reward)
def colab_save(self, model_name: str, version: str, num_trained: int):
from google.colab import drive
import os
mount_path = "/content/drive"
drive.mount(mount_path)
model_path = os.path.join(mount_path, "MyDrive", "model")
# save model on google drive
self.agent.save(
path=model_path,
model_name=model_name,
version=version,
num_trained=num_trained,
)
def colab_load(self, model_name: str, version: str, num_trained: int):
from google.colab import drive
import os
mount_path = "/content/drive"
drive.mount(mount_path)
model_path = os.path.join(mount_path, "MyDrive", "model")
# load model on google drive
self.agent.load(
path=model_path,
model_name=model_name,
version=version,
num_trained=num_trained,
)
RL을 학습하기 위해서는 먼저 environment에서 직접 행동을 해보며 데이터를 쌓아야한다. 이 부분을 구현한 코드가 위의 def train(self)이다. 최대 max_episode만큼 episode를 진행하면서 경험을 하고, ReplayMemory에 결과를 저장한다. self.agent.train()부분이 ReplayMemory에 저장된 학습 결과들을 이용해서 학습을 수행하는 코드이다. 이 부분은 DQNAgent.py에 따로 구현해놓았다.
주된 학습 환경으로는 Google의 Colab을 이용했다. 학습 중간 중간 self.temp_save_freq마다 임시 저장을 진행한다. self.save_on_colab이 True이면 Colab상에서 학습한다고 가정하고 모델을 Google Drive에 임시 저장한다. False인 경우에는 학습이 로컬 환경에서 진행된다고 가정하고 모델을 로컬에 임시 저장한다.
4. 첫번째 구현 시도와 실패, 그리고 완성
위에서 구현한 코드들은 완성 버전의 코드들이다. 첫번째 구현은 30000번의 Episode를 플레이해도 도무지 학습이 제대로 진행되지 않는 문제점이 있었다. 그래서 내 코드를 고쳐보면서 참고한 블로그가 바로 Tensorflow2로 만든 DQN 코드: CartPole-v1였다. 비교해본 결과, 전반적으로 내 코드의 문제점이 보였다.
학습에는 항상 충분한 양과 질의 데이터가 필요하다는 점을 명심할 것 (둘 다 중요!)
-
ReplayMemory의 문제
처음에는 아무 생각 없이, 데이터가batch_size보다 많으면 ReplayMemory를 이용한 학습이 진행될 수 있도록 했었다.batch_size의 기본값은 100이었는데, 그러다보니까 충분한 양의 데이터가 모이지 못했음에도 학습을 진행하게 되어서, 결과적으로 모델이 올바르게 학습하지 못했던 것 같다. 학습이 잘 진행되지 못했던 주 원인. -
Episode Play 단계에서의 문제
처음에는 한 Episode를 플레이할때 특정 step(2000정도)까지만 반복하고 Episode를 종료하게 했었다. CartPole environmnet에서는 action을 취할때마다 +1, 쓰러지지 않도록 성공할 때(done == True)+200의 reward를 지급한다. step 수의 제한때문에done == True성공할 수 있는 상태임에도 성공 상태에 도달하지 못할 수도 있을 것 같아서 반복문을while not done :으로 수정했다. 다만 나중에 체크했을때, 이렇게 해놔도 step이 2000이상 반복되는 경우는 없어서 크게 영향은 없었던 것으로 추정한다
학습 결과 : Episode 별 Reward
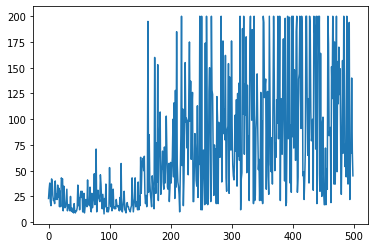
대충 200 Episode가 넘어가면서 200 이상의 Reward를 엄청 자주 찍는 것을 볼 수 있다. Pole이 넘어지지 않고 똑바로 서있는 '성공'을 달성시 200의 Reward가 주어지므로, 모델이 아주 잘 훈련되었다는 의미이다. 다만, 왜 이렇게 그래프가 좀 왔다리갔다리 하는지는 잘 모르겠다. 실제로 훈련한 모델을 이용해 실행시켜 보면 Pole이 무너지지 않고 아주 잘 서있다.
5. 주저리주저리
- 사실 Target Network를 업데이트할 때에는 원래는 freq를 설정해서 일정 빈도로 업데이트한다. 이것도 하이퍼 파라미터인데 귀찮아서 그냥 한 Episode마다 업데이트하도록 설정했다 ㅎㅎ...
- 이번 Project를 진행하면서 대충 Colab에서 어떻게 안정적으로 임시 저장을 반복하면서 학습을 진행할 수 있는가를 깨달았다는 건 좀 좋은거 같다. 돈 없는 학생 입장에서 최대한 굴려먹어야 하는데 나중에 캐글할때 대충 이런 프로세스는 유용하게 써먹을 수 있을 것 같다.
- PS하면서 주석 쓰는 습관을 들였는데 (이렇게 안하면 내가 다음날 봤을때 저게 뭔 코드인지 못 알아먹기 때문에) 습관 좀 잘 들은 거 같아서 좀 뿌듯하다
6. 실습 이론
- Deep Q Network
- Epsilon Decay
- Replay Buffer
- Target Network
