[알고리즘] DFS , BFS , 백준 7576
이번엔 DFS와 BFS에 대해 다뤄보도록 하겠습니다.
DFS와 BFS는 그래프 탐색 기법입니다.
그래프란 정점(Vertex)과 간선(Edge)으로 이루어진 자료 구조인데요. 정점과 간선을 통해 데이터나 개체들간의 상호 관계를 표현할 수 있습니다.
⭐️ DFS (Depth-First Search)
DFS는 깊이 우선 탐색입니다. 깊이 우선 탐색이란 임의의 정점에서 시작하여 해당 점의 브랜치를 우선적으로 탐색한 후 , 다음 브랜치로 넘어가는 탐색 방법입니다. 즉 , 해당 정점의 모든 자식을 탐색하는 것과 같습니다.
예를 들면 , 미로 찾기를 할 때 여러 갈림길 중 하나의 갈림길을 선택하여 그 길을 쭉 가본 후 막혔으면 다른 갈림길을 선택하는 방식을 들 수 있습니다.
DFS는 스택과 재귀를 통해 구현할 수 있습니다. 왜 스택일까요 ? 스택은 LIFO(후입선출) 특성을 가지고 있습니다. 임의의 정점과 인접한 모든 정점들을 stack에 넣은 후 마지막에 들어온 정점을 pop하게 되면 해당 정점의 브랜치를 따라가게 되기 때문입니다.
⭐️ BFS (Breadth-First Search)
BFS는 너비 우선 탐색입니다. 너비 우선 탐색이란 임의의 정점과 인접한 정점들부터 탐색을 시작하는 기법입니다.
예를 들면 , 임의의 정점에서 특정 정점까지의 최단 경로를 구해야 한다고 가정해봅시다. 이웃한 정점들부터 순회하다 특정 정점을 발견하면 프로그램의 실행을 바로 멈출 수 있기 때문에 DFS보다 BFS가 더 효과적입니다.
BFS는 큐를 통해 구현할 수 있습니다. 왜 큐일까요 ? 큐는 FIFO 특성을 가지고 있는데 , 인접한 모든 정점들을 queue에 넣고 shift 하게 되면 인접한 정점들부터 탐색하기 때문입니다.
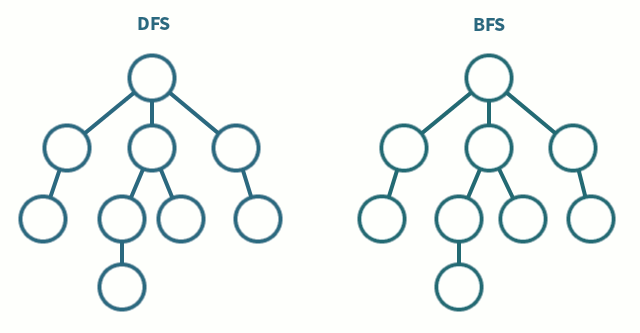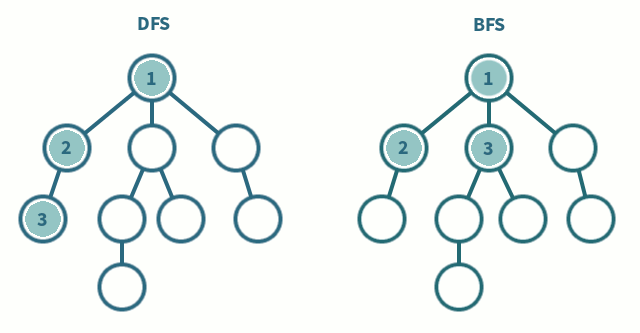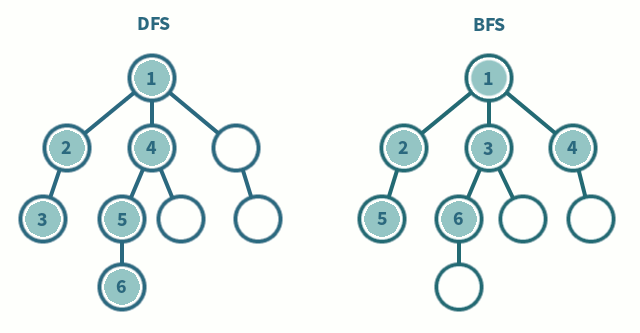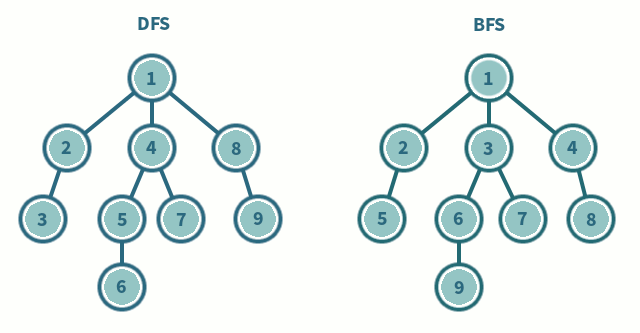
출처 : 나무 위키
⭐️ BFS와 DFS의 시간 복잡도
BFS와 DFS의 시간 복잡도는 인접 행렬일 때는 O(V^2) 인접 리스트일 때는 O(V+E)의 시간 복잡도를 가집니다.
인접 행렬과 인접 리스트에 대한 설명
⭐️ BFS와 DFS 구현
// 너비 우선 탐색 (Breadth First Search)
// 최단 경로를 찾아준다는 점에서 최단 길이를 보장해야 할 때 많이 사용
// 큐를 이용한다는 특징이 있다. (why ?) -> 선입선출을 이용해야하기 때문에
// 그래프를 탐색하는 것 .
// 프로퍼티 키는 정점을 뜻하며 , 프로퍼티 값은 해당 정점과 연결된 정점을 의미한다.
const graph = {
A: ["B", "C"],
B: ["A", "D"],
C: ["A", "G", "H", "I"],
D: ["B", "E", "F"],
E: ["D"],
F: ["D"],
G: ["C"],
H: ["C"],
I: ["C", "J"],
J: ["I"],
};
const BFS = (graph, startNode) => {
const visited = [];
let needVisit = [];
needVisit.push(startNode);
let i = 1;
while (needVisit.length !== 0) {
const node = needVisit.shift(); // 첫 번째 반복에서는 node="A"
if (!visited.includes(node)) {
visited.push(node);
needVisit = [...needVisit, ...graph[node]];
}
console.log(`${i}번 째 반복문 needVisit : ${needVisit}`);
i++;
}
return visited;
};
console.log(BFS(graph, "A"));// 깊이 우선 탐색 (Depth First Search)
// 미로 찾기
// 스택을 이용한다는 특징이 있다. (why ?)
// 그래프를 탐색하는 것 .
// 프로퍼티 키는 정점을 뜻하며 , 프로퍼티 값은 해당 정점과 연결된 정점을 의미한다.
const graph = {
A: ["B", "C"],
B: ["A", "D"],
C: ["A", "G", "H", "I"],
D: ["B", "E", "F"],
E: ["D"],
F: ["D"],
G: ["C"],
H: ["C"],
I: ["C", "J"],
J: ["I"],
};
const DFS = (graph, startNode) => {
const visited = [];
let needVisit = [];
needVisit.push(startNode);
let i = 1;
while (needVisit.length !== 0) {
const node = needVisit.shift(); // 첫 번째 반복에서는 node="A"
if (!visited.includes(node)) {
visited.push(node);
needVisit = [...graph[node], ...needVisit]; // stack 구조와 같다 , 후입 선출
}
console.log(`${i}번 째 반복문 needVisit : ${needVisit}`);
i++;
}
return visited;
};
console.log(DFS(graph, "A"));⭐️ 예시 문제 7576번 : 토마토

// 시간 초과
function solution(input) {
// m은 가로 , n은 세로
const [m, n] = input[0];
const tomatoes = input.slice(1);
// row , column 기준 상,좌,하,우
const drc = [
[-1, 0],
[0, -1],
[1, 0],
[0, 1],
];
const visited = Array.from({ length: n }, () => Array(m).fill(0));
// 최소 일수를 구하는 문제이며 , 인접 정점들에 대한 것들을 모두 구해야 함 .
const queue = [];
tomatoes.forEach((tomato, row) => {
tomato.forEach((t, col) => {
if (t === 1) {
queue.push([row, col]);
visited[row][col] = 1;
}
});
});
let cnt = -1;
const bfs = () => {
let head = 0;
while (queue.length) {
const len = queue.length;
for (let i = 0; i < len; i++) {
const [curR, curC] = queue.shift();
for (let i = 0; i < 4; i++) {
const [nextR, nextC] = [curR + drc[i][0], curC + drc[i][1]];
if (nextR >= 0 && nextC >= 0 && nextC < m && nextR < n) {
if (
tomatoes[nextR][nextC] === 0 &&
!visited[nextR][nextC]
) {
visited[nextR][nextC] = 1;
queue.push([nextR, nextC]);
}
}
}
}
cnt++;
}
};
bfs();
visited.forEach((el, row) =>
el.forEach((_, col) => {
if (
tomatoes[row][col] === 0 &&
visited[row][col] - 1 !== tomatoes[row][col]
) {
cnt = -1;
}
})
);
console.log(cnt);
}
const rl = require("readline").createInterface({
input: process.stdin,
output: process.stdout,
});
const input = [];
rl.on("line", (line) => {
input.push(line.split(" ").map((el) => parseInt(el)));
}).on("close", () => {
solution(input);
process.exit();
});위 코드는 시간 초과가 난 코드입니다. js에는 queue나 stack , heap 등에 대한 자료 구조가 따로 없다보니 배열로 해결해야 하는데 shift() (O(n) time complexity)를 사용하니 시간 초과가 난 것 같습니다.
최소 일수를 구하고 있고 , 토마토가 익은 인접 토마토들을 전부 방문해야 하니 BFS를 사용해주었습니다.
function solution(input) {
// m은 가로 , n은 세로
const [m, n] = input[0];
const tomatoes = input.slice(1);
// row , column 기준 상,좌,하,우
const drc = [
[-1, 0],
[0, -1],
[1, 0],
[0, 1],
];
const visited = Array.from({ length: n }, () => Array(m).fill(0));
// 최소 일수를 구하는 문제이며 , 인접 정점들에 대한 것들을 모두 구해야 함 .
const queue = [];
tomatoes.forEach((tomato, row) => {
tomato.forEach((t, col) => {
if (t === 1) {
queue.push([row, col]);
}
if (t === 0) {
visited[row][col] = -1;
}
});
});
const bfs = () => {
let head = 0;
while (queue.length > head) {
const [curR, curC] = queue[head++];
for (let i = 0; i < 4; i++) {
const [nextR, nextC] = [curR + drc[i][0], curC + drc[i][1]];
if (nextR >= 0 && nextC >= 0 && nextC < m && nextR < n) {
if (visited[nextR][nextC] < 0) {
visited[nextR][nextC] = visited[curR][curC] + 1;
queue.push([nextR, nextC]);
}
}
}
}
};
bfs();
let cnt = 0;
for (let i = 0; i < n; i++) {
for (let j = 0; j < m; j++) {
// 익지 않은 토마토가 있음
if (visited[i][j] === -1) {
console.log(-1);
return;
}
cnt = Math.max(cnt, visited[i][j]);
}
}
console.log(cnt);
}
const rl = require("readline").createInterface({
input: process.stdin,
output: process.stdout,
});
const input = [];
rl.on("line", (line) => {
input.push(line.split(" ").map((el) => parseInt(el)));
}).on("close", () => {
solution(input);
process.exit();
});
//
시간 초과가 나기 이전 [[nextR,nextC],...queue]로 코드를 작성했을 때는 메모리 초과가 났는데 , 배열 재선언 없이 head를 사용하면 훨씬 효율적인 코드가 나올 수 있다는 것을 알아냈습니다.
