이번 포스팅에서는 자료 구조를 공부하든 , 코딩 테스트 문제를 풀든 자주 마주치는 해시에 대해 알아보겠습니다.
⭐️ 해시 테이블(Hash Table)이란 ?
해시 테이블이란 데이터를 저장하고 검색하는 데에 사용되는 자료구조입니다. 해시 함수를 통해 인덱스로 매핑된 최종 데이터를 해시 테이블이라고도 하는데요. 해시 테이블에 저장된 값은 (key, value) 쌍으로 저장되며 , 모든 데이터는 유일한 key를 가지고 있습니다. 그렇기 때문에 해시 테이블에 저장된 데이터들은 특정한 값을 찾는 데에 최적화 되어 있습니다. 해시 테이블에 저장된 값을 검색하는 데에 걸리는 시간은 O(1)의 Time Complexity를 지닙니다.
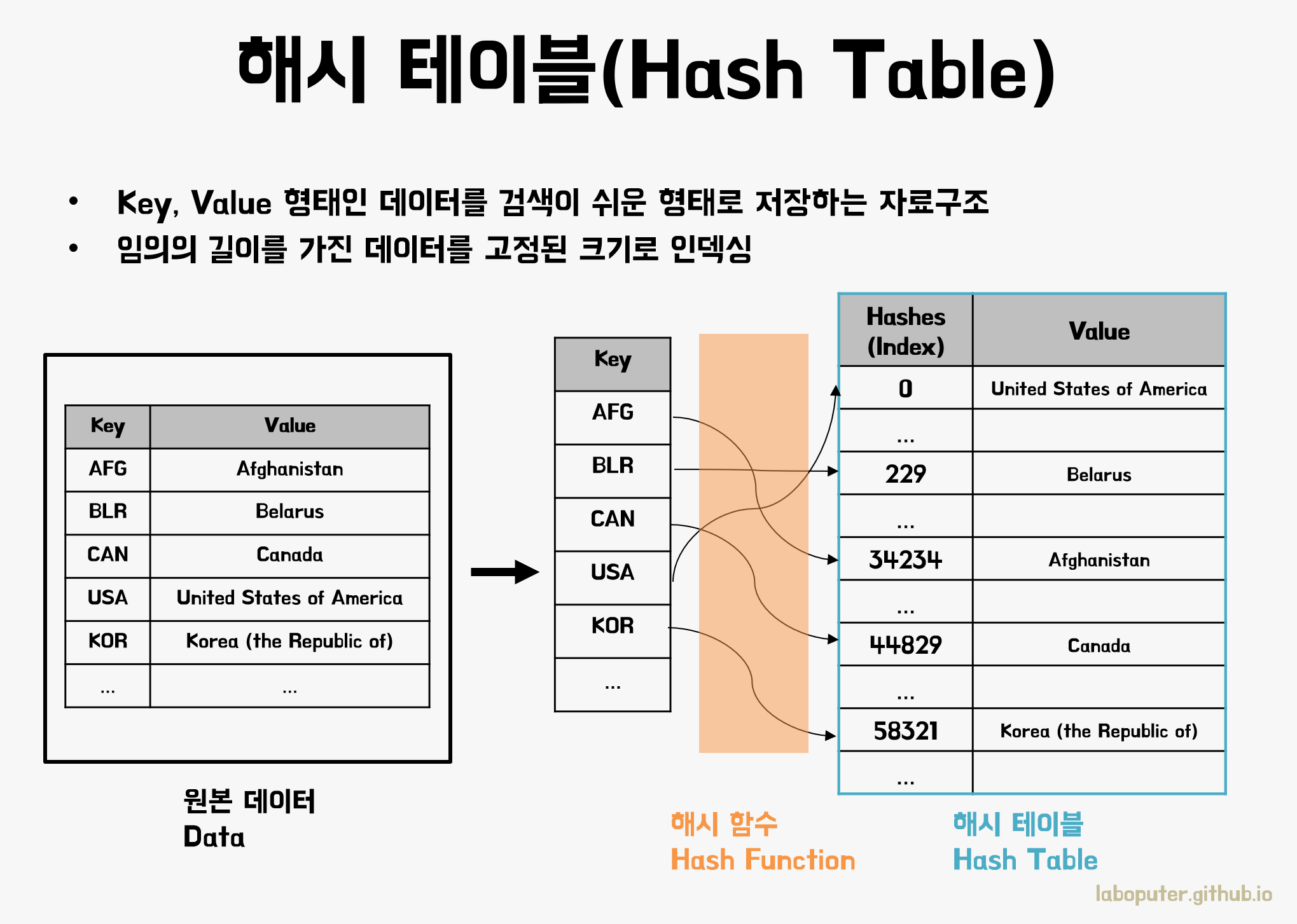
그러면 해시 테이블에 값을 저장할 때 해시 함수 (Hash Function )를 통해 해당 값을 인덱스화 (Indexing)해줘야 하는데 어떤 방법들이 있을까요 ?
⭐️ 해시 함수 (Hash Function)
해시 함수는 키 값을 입력으로 받아 해시 테이블상의 주소를 리턴합니다. (index)
해시 함수는 두 가지 성질을 가져야 하는데요.
- 입력 원소가 해시 테이블 전체에 고루 저장되어야 한다. (메모리 효율성 증가 및 충돌 예방)
- 계산이 간단해야 한다.
1번에서 말하는 충돌(Collision)이란 무엇일까요 ?
해시 충돌 (Hash Collision)
예를 들어, 해시 함수가 H(x)=x mod 13 이라고 가정해봅시다. 이는 키 값을 입력하면 13으로 나눈 나머지 값을 해시 테이블의 인덱스로 사용하겠다는 것과 마찬가지인데요.
x가 3일 때도 return 값은 3일 것이고 16을 넣어도 3일 것입니다. 그럼 서로 다른 키 값이 동일한 해시 테이블 인덱스에 배치되는 것인데 우리는 이것을 해시 충돌이라고 부릅니다.
해시 충돌이 발생하게 되면 O(1)의 검색 속도가 O(n)까지 증가할 수 있습니다. 그 이유는 중첩된 키에 저장하게 된 여러 값들을 일일이 하나씩 찾아야(선형 탐색) 되기 떄문입니다.
이런 해시 충돌 처리는 해시 테이블 이론의 핵심이기에 , 다양한 해시 함수들이 고안되고 있는 것입니다.
⭐️ 나누기 방법 (Division Method)
위에서 예를 든 것과 같이 입력으로 들어온 키 값을 임의의 수로 나눈 나머지 값을 해시 테이블의 인덱스로 만드는 것입니다.
h(x)=x mod m
여기서 m은 해시 테이블의 크기로 설정하고 2의 멱수(거듭 제곱)에 가깝지 않은 소수를 택하는 것이 좋습니다.
⭐️ 루즈루즈 함수 (lose lose)
루즈루즈 함수는 키를 구성하는 문자의 아스키 값을 단순히 더한 해시 함수입니다.
예를 들어 , John이 입력되면 J(74)+o(111)+h(104)+n(110) 399를 리턴하고 해시 테이블의 399번 째 인덱스에 John에 맞는 value값이 저장되는 것입니다.
다양한 해시 함수들이 있음에도 불구하고 , 해시 충돌은 발생하기에 여러 가지 충돌 해결 방법들 또한 고안되었습니다.
⭐️ 체이닝 (Chaining)
체이닝에서는 같은 주소로 해싱되는 원소를 모두 하나의 연결 리스트에 매달아서 관리합니다.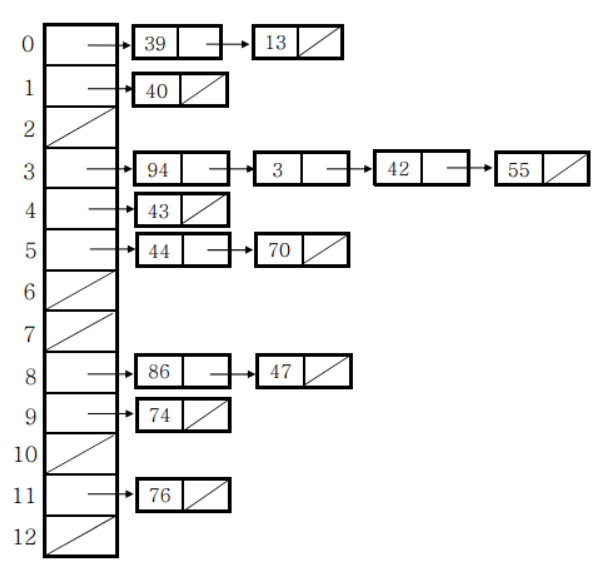
해시 테이블의 각 주소 (idx)가 리스트의 헤더 역할을 하고 있습니다. 체이닝에서 임의의 원소를 연결 리스트에 삽입할 때는 해당 리스트의 맨 앞에 삽입합니다. 굳이 다른 자리에 삽입하는 것은 연결할 자리를 찾는 시간이 발생하기 때문에 그렇게 할 이유가 없기 때문입니다.
원소를 검색할 때는 연결 리스트를 순차적으로 검색합니다.
원소를 삭제할 때는 연결 리스트에서 해당 원소를 삭제합니다.
⭐️ 개방 주소 방법
개방 주소 방법은 체이닝과 같은 추가 공간(연결 리스트 생성)을 허용하지 않습니다. 충돌이 일어나더라도 주어진 테이블 공간에서 해결하는 것인데 이는 모든 입력 값이 자신의 해시 값과 일치하는 주소에 저장되는 보장이 없습니다.
체이닝이 개방 주소 방법보다 평균 조사 횟수가 적기 때문에 구체적으로 작성하지는 않겠습니다. 궁금하시다면 좀 더 자세한 해시 테이블을 참고하시길 바랍니다.
사실 대부분의 프로그래밍 언어는 해시를 구현해놨기 때문에 개발자들이 따로 구현할 필요는 없습니다.
