Spring Cloud Config
분산 시스템에서 애플리케이션의 설정 데이터를 중앙 집중식으로 관리하고 동적으로 업데이트 할 수 있도록 돕는 도구
Spring cloud에서 제공. Git, 파일 시스템, 데이터베이스 등 다양한 구성 저장소와 통합 가능
특징
-
중앙 집중식 구성 관리
- 여러 애플리케이션의 설정 파일을 한 곳에서 관리
- 설정 변경 시 모든 애플리케이션에 즉시 반영 가능
-
환경별 설정 관리
- 개발, 테스트, 운영 등 다양한 환경에 따른 설정 구분 가능
- 애플리케이션명 또는 프로파일 설정으로 다른 설정 적용 가능
-
다양한 저장소 지원
- Git, SVN, 파일 시스템, 데이터베이스 등 다양한 저장소 지원
- Git과 통합하면 변경 이력도 관리할 수 있다
-
동적 구성 업데이트
- Spring Cloud Bus와 통합하여 애플리케이션 실행 중에도 설정 변경 내용 반영 가능
-
보안 관리
- 민감 데이터는 암호화해서 저장하여 보안에 좀 더 신경쓸 수 있음
장단점
장점
1. 중앙 집중 관리: 유지보수가 용이해짐
2. 환경별 설정
3. 동적 구성 업데이트
4. 보안 강화
단점
1. 복잡성
- 중앙 집중식 구성 도입으로 시스템 아키텍처가 복잡해질 수 있음
2. 의존성
- Config Server가 다운되면 클라이언트 애플리케이션에도 영향이 갈 수 있음
- 이를 방지하기 위해 로컬 캐싱이나 Confing Server 다중화를 고려할 수 있다
비슷한거
| 도구 | 특징 |
|---|---|
| Spring Cloud Config | Spring 기반 애플리케이션에 최적화. Git, 파일 시스템 등 다양한 저장소 지원 |
| Consul | Key-Value 저장소와 서비스 디스커버리 기능 제공 |
| etcd | 고가용성과 분산 시스템을 위한 Key-Value 저장소 |
| Zookeeper | 분산 시스템의 설정 관리와 동기화 기능 제공 |
핵심 개념
-
Config Server
- 설정 데이터를 중앙에서 관리함
- 클라이언트 애플리케이션이 설정 데이터를 요청하면 적절한 구성 값을 반환함
- 설정 저장소(Git 등)와 통신하여 데이터를 가져옴
-
Config Client
- Config Server에서 설정 데이터를 가져와 애플리케이션에서 사용
- Spring Boot 애플리케이션에서
spring-cloud-starter-config를 통해 구현
동작 흐름
- Config Server가 Git 등에서 설정 데이터를 가져옴
- Config Client가 Config Server에 설정 데이터를 요청
- Config Server는 요청에 따라 클라이언트에게 적절한 설정 값을 반환
- 필요시 Spring Cloud Bus를 통해 설정 변경 내용을 실시간으로 반영함
Spring Cloud Config와 Spring Cloud Bus
Spring Cloud Bus
분산 시스템에서 애플리케이션 간의 이벤트와 메시지를 전달하기 위한 도구
주로 Spring Cloud Config와 함께 사용
RabbitMQ, Kafka와 같은 메시징 브로커를 통해 구성 변경 사항이나 이벤트를 다른 애플리케이션에 실시간으로 전파하는 데 사용됨
역할
- 구성 변경 전파
- Spring Cloud Config와 통합하여 Config Server에서 설정이 변경되면 클라이언트 애플리케이션에 실시간으로 변경 내용 전파
- 애플리케이션 간 이벤트 전달
- 분산 시스템의 서비스 간에 상태 변경이나 작업 요청과 같은 이벤트 전달
- 확장성과 효율성
- 메시징 브로커를 사용해 네트워크 대역폭과 리소스를 효율적으로 사용
특징
- 메시지 브로커 기반
- 분산 이벤트 관리: 분산 애플리케이션 간에 이벤트를 전달해 시스템 동기화
- 전역 브로드캐스트: 메시지를 수신한 애플리케이션이 이를 브로드캐스트하여 다른 애플리케이션이 변경 내용을 수신
- Custom 이벤트 지원: 사용자 정의 이벤트를 생성하고 전달할 수 있음
동작 원리
- Config Server에서 설정 파일을 변경
- 변경 사항을
/actuator/bus-refresh엔드포인트로 알림 - Spring Cloud Bus는 RabbitMQ 또는 Kafka를 통해 구성 변경 이벤트를 브로드캐스트
- 클라이언트 애플리케이션이 이벤트를 수신하고 변경 사항을 적용
장단점
장점
1. 실시간 동기화
2. 확장성: 메시징 시스템 기반으로 대규모 분산 시스템에서도 안정적으로 작동
3. 간편한 통합: Spring Cloud Config와 자연스럽게 통합
4. 유연성: Custom 이벤트 및 특정 대상 지정으로 다양한 요구사항 반영 가능
단점
1. 메시징 브로커 의존: 외부 메시징 시스템이 필요함
2. 복잡성 증가: 러닝커브..
3. 브로커 장애 시 문제 발생
주요 API
/actuator/bus-refresh- Spring Cloud Bus를 이용해 Confing Server의 설정 변경 내용을 모든 클라이언트에 전파
- 메시지 브로커 필요
- HTTP POST 요청을 통해 실행
/actuator/bus-env- 특정 애플리케이션에만 환경 변수 업데이트 전파
/actuator/bus-refresh/{destination}- 특정 인스턴스에만 변경 내용을 전파
- destination: 애플리케이션 이름 또는 ID
/actuator/bus-refresh와 /actuator/refresh
- /actuator/bus-refresh
- Spring Cloud Config Client에서만 동작
- Config Server로부터 최신 설정 값을 다시 가져오고, 해당 애플리케이션의 컨텍스트를 갱신함
- 다른 애플리케이션으로 변경 사항이 전파되지 않음
- 특정 애플리케이션만 수동으로 설정을 업데이트 해야 할 때, Spring Cloud Bus가 없는 환경에서 사용
- HTTP POST 요청을 통해 실행
Spring Cloud Config와 Spring Cloud Bus의 관계
- Spring Cloud Config는 애플리케이션의 설정을 중앙에서 관리
- Spring Cloud Bus는 Config Server와 클라이언트 애플리케이션 간에 설정 변경 내용을 실시간으로 전파
비슷한거: Spring Cloud Stream
| 특징 | Spring Cloud Bus | Spring Cloud Stream |
|---|---|---|
| 주요 목적 | 분산 시스템의 구성 변경 전파 및 이벤트 관리 | 이벤트 기반의 메시지 처리 및 스트림 데이터 관리 |
| 메시징 방식 | 브로드캐스트 중심 | 이벤트 프로듀서와 컨슈머 간의 직접적인 메시징 |
| 사용 사례 | Spring Cloud Config와 통합하여 구성 변경 전파 | 비즈니스 로직에서 메시지 기반 데이터 흐름 처리 |
| 주요 의존성 | RabbitMQ, Kafka 등 메시징 브로커 | RabbitMQ, Kafka 등 메시징 브로커 |
| 구현 복잡성 | 상대적으로 간단 (구성 변경 전파 중심) | 상대적으로 복잡 (이벤트 흐름 설계 필요) |
설정
Spring Cloud Bus 없이 /actuator/refresh를 통해 각각의 서버에 설정 파일을 반영할 수 있다
- 서버 애플리케이션 설정
- Config
@EnableConfigServer
@SpringBootApplication
public class ConfigApplication {
public static void main(String[] args) {
SpringApplication.run(ConfigApplication.class, args);
}
}- 의존성 설정
- Config
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.cloud:spring-cloud-config-server'
implementation 'org.springframework.cloud:spring-cloud-starter-netflix-eureka-client'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testRuntimeOnly 'org.junit.platform:junit-platform-launcher'
}yml을 전달받아 적용할 서비스에도 의존성을 추가해준다.
Config Server에 yml 파일을 작성하고, Product가 이를 받아 적용할 것이다
- Product
implementation 'org.springframework.cloud:spring-cloud-starter-config'- yml 설정
- application.yml (Config)
server:
port: 18080
spring:
profiles:
active: native
application:
name: config-server
cloud:
config:
server:
native:
search-locations: classpath:/config-repo
eureka:
client:
service-url:
defaultZone: http://localhost:19090/eureka
추가로 전달할(적용시킬) yml 파일도 작성
- product-service.yml (Config)
server:
port: 19093
message: "product service message"- product-service-local.yml (Config)
server:
port: 19083
message: "product service local message"message를 다르게 작성해서 어느 설정 파일이 적용되었는지 확인해 볼 것이다
Config Server에서 설정 파일을 가져와 적용하기 위해서 Product의 yml을 수정해준다
- Product
spring:
profiles:
active: local
application:
name: product-service
config:
import: "configserver:"
cloud:
config:
discovery:
enabled: true # 서비스 디스커버리를 사용해 Config Server를 찾겠다
service-id: config-server # Config Server의 서비스 ID(Eureka에 등록된 이름)
server:
port: 0
eureka:
client:
service-url:
defaultZone: http://localhost:19090/eureka/
message: "dafault-message"port를 임의로 0으로 설정하고 message를 다르게 설정하여 config server의 설정파일의 port가 적용되는지 확인할 것이다
spring.cloud.config.discovery.enabled
-
enabled: true
- 서비스 디스커버리를 활성화하여 Config Server의 위치를 Eureka 등에서 동적으로 찾음
- service-id로 지정된 이름(여기서는 config-server)을 기반으로 서비스 디스커버리에서 Config Server의 주소를 가져옴
-
enabled: false
- 서비스 디스커버리 안쓰고 Config Server의 URI를 정적으로 지정
spring.cloud.config.uri설정에 Config Server의 URL을 직접 명시해야 함
- 확인
실행하면
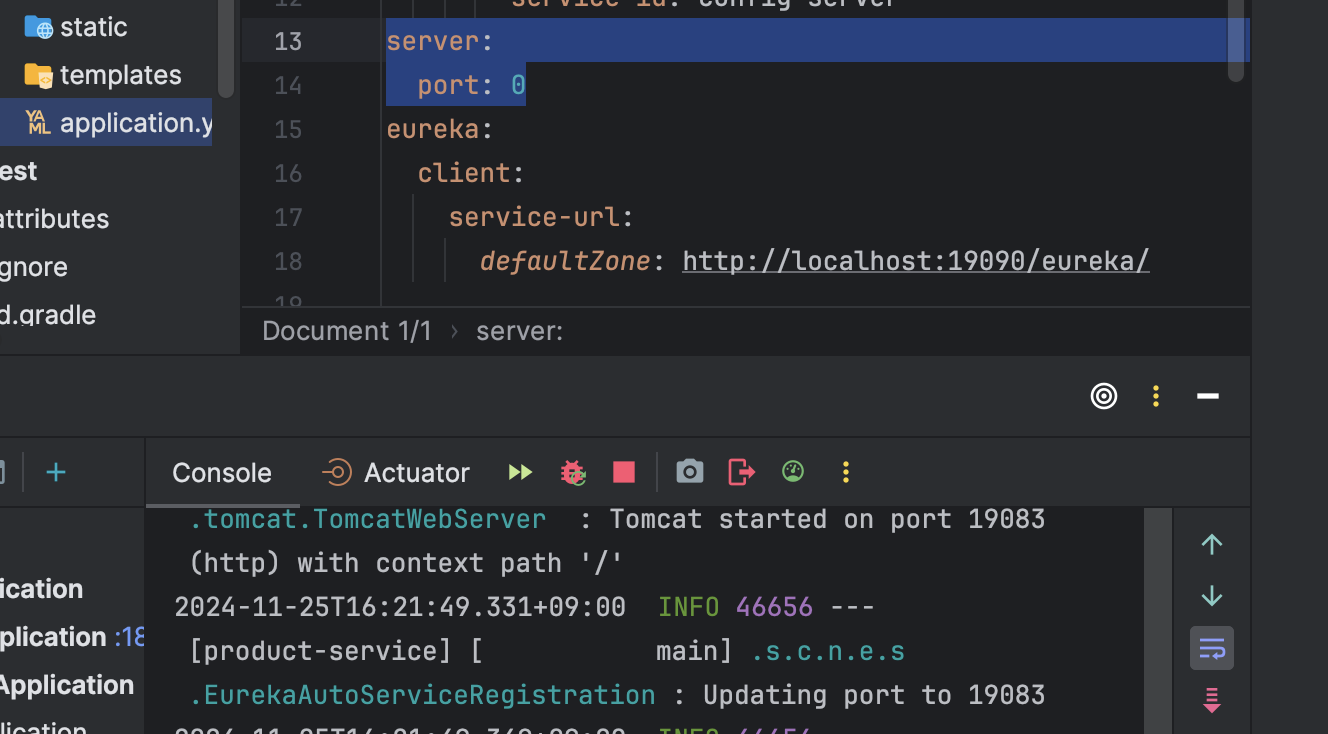
Product의 yml에 port를 0으로 명시해줬는데도 19083 포트로 열린것을 볼 수 있다
product-service-local.yml에 작성된 포트 번호이다
http://localhost:19083/product 으로 호출할 시
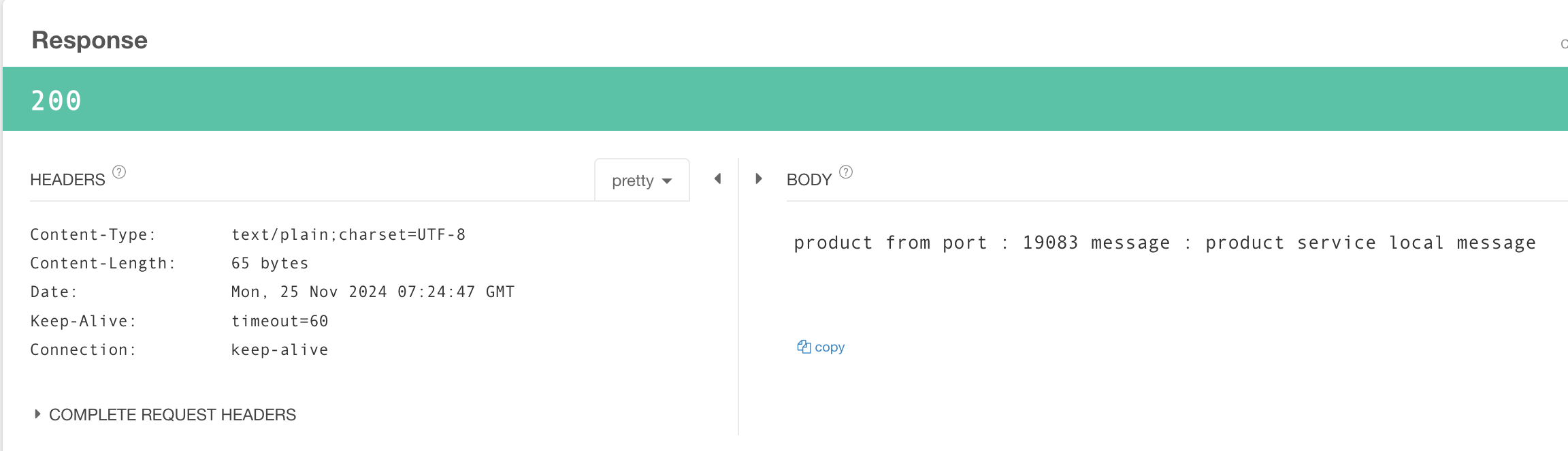
Product의 application.yml의 message("dafault-message")가 아닌
product-service-local.yml에 작성한 message("product service local message")를 반환한다
- Config 변경사항 반영하기
product에 의존성 추가
implementation 'org.springframework.boot:spring-boot-starter-actuator'Product의 yml에서 refresh 활성화
management:
endpoints:
web:
exposure:
include: refreshProductController 수정
@RefreshScope 적용
-> 없을 경우 bean의 설정값이 업데이트 되지 않음
Product Application 재실행 후 19083으로 호출 시 이전 응답값과 같음 확인("product service local message")
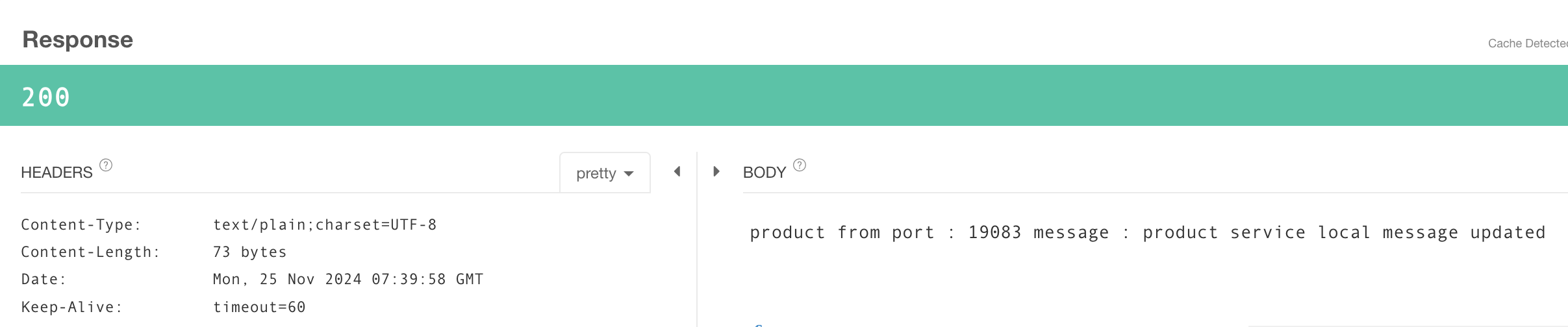
Config Server에 작성되어 있는 product-service-local.yml의 message를 다음과 같이 수정
message: "product service local message updated"Config Server 재실행 후 http://localhost:19083/actuator/refresh 로 설정 재반영(POST)
19083에서 Product 호출 시 업데이트 된 message 반환 확인
분산 추적 및 로깅
분산추적(Distributed Tracing)과 로깅(Logging)은 MSA에서 시스템의 가시성과 문제 해결을 위한 필 수 도 구 이다
분산 추적
MSA 환경에서 요청이 여러 서비스간을 거쳐 처리될 때 각 서비스 간의 호출 관계와 성능 데이터를 추적하고 시각화하는 기술
복잡한 처리에서 발생하는 문제를 해결하기 위해서는 필수적이다
주요 개념
- Trace(추적)
- 단일 요청에 대한 전반적인 기록
- 하나의 Trace는 요청이 여러 서비스에서 처리되는 전체 흐름을 나타냄
- Span(구간)
- Trace의 하위 작업. 특정 서비스나 작업의 단위를 나타냄
- 각 Span에는 작업 시작/종료 시간, 상태 코드 등이 포함됨
- Trace ID(추적 ID)
- 요청 단위를 식별하는 고유 ID
- 모든 Span은 동일한 Trace ID를 공유함
- Span ID
- 각 Span의 고유 ID. Trace 내에서 해당 작업을 식별
- Parent-Child Relationship (부모-자식 관계)
- 분산 추적에서는 Span 간의 부모-자식 관계를 유지해 서비스 호출 계층 구조를 표현함
주요 구성요소
- Instrumentation (계측)
- 서비스 코드에 추적 데이터를 기록하는 라이브러리나 프레임워크를 삽입
- ex) Spring Cloud Sleuth, OpenTelemetry
- Tracer (추적기)
- Trace와 Span 데이터를 생성하고 관리하는 도구
- Collector (수집기)
- 각 서비스에서 수집한 Trace 데이터를 중앙으로 모아 저장
- ex) Zipkin, Jaeger
- Storage (저장소)
- Trace 데이터를 저장하는 시스템
- ex) Elasticsearch, Cassandra
- Visualizer (시각화 도구)
- 수집된 Trace 데이터를 UI로 시각화하여 분석
- ex) Zipkin UI, Jaeger UI
동작 흐름
- 클라이언트가 서비스 A에 요청을 보냄
- 서비스 A는 새로운 Trace ID를 생성하고, 자신의 작업에 대해 Span ID를 생성
- 서비스 A가 서비스 B를 호출하면 Trace ID, Span ID를 전달
- 서비스 B는 전달받은 Span ID를 부모로 설정하고, 자신의 작업에 대한 새로운 Span ID를 생성
- 모든 서비스에 대해 위의 과정이 반복되어 흐름이 기록됨
- 모든 Trace와 Span 데이터는 Collector로 전송되고, 시각화 도구를 통해 분석할 수 있음
장단점
장점
1. 복잡한 서비스 호출 관계를 쉽게 이해
2. 성능 병목 지점 및 오류 원인 파악이 용이함
3. 요청 흐름의 전체적인 가시성 제공
단점
1. 초기 설정 및 도입이 복잡(귀찮)할 수 있음
2. 네트워크 및 스토리지 리소스를 추가로 사용함
3. 잘못된 계측이나 과도한 데이터 수집은 성능에 영향을 미칠 수 있다
필요성
- 요청 흐름 이해: 요청이 여러 서비스 간에서 어떻게 처리되는지 시각적으로 파악
- 병목현상 탐지: 요청 처리 과정에서 지연이 발생한 구간을 확인하여 성능 최적화
- 장애 원인 분석: 오류가 발생한 지점을 신속히 식별하고 문제 해결
- 성능 모니터링: 각 서비스의 응답 시간, 호출 횟수 등을 모니터링 해 운영 효율성을 향상시킬 수 있음
도구
| 도구 | 특징 |
|---|---|
| Zipkin | 오픈소스 분산 추적 시스템. 간단하고 가벼우며 Spring Cloud Sleuth와 통합에 적합 |
| Jaeger | CNCF 프로젝트로, 고성능 분산 추적 솔루션. Kubernetes 환경에 최적화 |
| OpenTelemetry | 표준화된 API와 SDK를 제공하여 다양한 언어와 도구에서 분산 추적을 지원 |
| AWS X-Ray | AWS 클라우드에서 네이티브 지원하는 분산 추적 서비스 |
| New Relic/APM | 상용 애플리케이션 성능 관리 도구로, 분산 추적과 모니터링 기능 제공 |
로깅
애플리케이션에서 발생하는 이벤트를 기록해 시스템 동작을 이해하거나 문제를 디버깅하는 데 사용됨
일반적으로 파일, 콘솔 또는 중앙 로깅 시스템에 저장됨
주요 요소
로그 수준(Log Levels)
- DEBUG: 디버깅에 필요한 상세 정보
- INFO: 일반적인 애플리케이션 상태 정보
- WARN: 경고 메시지 (심각하지 않은 문제)
- ERROR: 치명적인 오류 메시지
로그 구조
- 일반적으로 타임스탬프, 로그 수준, 메시지, 스레드 정보 등을 포함
목적
- 운영 모니터링: 시스템에서 발생하는 이벤트를 실시간으로 모니터링
- 문제 해결: 오류 발생 시 원인 디버깅
- 이력 관리: 과거 기록을 통해 시스템 동작 분석
도구
| 도구 | 특징 |
|---|---|
| Logback | Spring Boot의 기본 로깅 프레임워크 |
| Log4j/Log4j2 | 고성능 로깅 프레임워크 |
| ELK Stack | Elasticsearch, Logstash, Kibana를 사용한 중앙 집중식 로깅 |
| Fluentd | 로그 수집 및 전송 도구. 다양한 데이터 소스 지원 |
분산 추적과 로깅
| 항목 | 분산 추적 (Distributed Tracing) | 로깅 (Logging) |
|---|---|---|
| 주요 목적 | 요청의 흐름과 처리 시간 추적 | 이벤트 기록 및 디버깅 |
| 관점 | 요청(Request) 단위의 흐름 추적 | 이벤트(Event) 단위의 세부 정보 기록 |
| 주요 정보 | Trace ID, Span ID, 서비스 호출 관계 | 타임스탬프, 로그 수준, 메시지, 스택 트레이스 등 |
| 대상 | 서비스 간의 호출 관계와 성능 | 개별 애플리케이션 또는 컴포넌트 내부의 이벤트 |
| 도구 예시 | Zipkin, Jaeger, OpenTelemetry | Logback, Log4j2, ELK Stack, Fluentd |
Micrometer
애플리케이션의 Metrics를 수집하고 다양한 모니터링 시스템에 데이터를 전달하기 위한 Java 기반 라이브러리
성능, 상태, 리소스 사용량 등을 모니터링하기 위해 표준화된 API를 제공하며 Spring Boot와 자연스럽게 통합됨
특징
- 다양한 모니터링 시스템 지원
- Prometheus, Datadog, InfluxDB, AWS CloudWatch 등 여러 모니터링 백엔드와 통합 가능
- 일관된 API
- 다양한 모니터링 시스템에 데이터를 전송하기 위해 동일한 API 사용
- Spring Boot와 통합
- Spring Boot Actuator와 연동하여 애플리케이션 메트릭을 자동으로 노출
- 경량성
- 애플리케이션에 최소한의 오버헤드를 추가해 성능에 영향을 적게 미침
- 다양한 메트릭 유형 지원
- 카운터(Counter), 게이지(Gauge), 타이머(Timer), 분포 요약(Distribution Summary), LongTask Timer 등을 지원
구성요소
- Registry
- 메트릭 데이터를 수집하고 특정 모니터링 시스템으로 전송
- ex) PrometheusMeterRegistry, CloudWatchMeterRegistry
- Meter
- 수집된 메트릭의 측정 단위
- 종류: Counter, Gauge, Timer, Distribution Summary etc
- Tag
- 메트릭에 추가 정보를 제공하기 위해 사용
- ex) http.status, region, instance
- Binding
- Spring Boot Actuator를 통해 JVM, CPU, 메모리 등 기본적인 시스템 메트릭을 자동으로 수집
메트릭 유형
| 메트릭 유형 | 설명 |
|---|---|
| Counter | 증가만 가능한 메트릭. ex: 요청 수, 에러 발생 횟수 |
| Gauge | 값이 변동 가능한 메트릭. ex: 메모리 사용량, 큐 크기 |
| Timer | 작업의 수행 시간과 호출 횟수를 측정. ex: HTTP 요청 응답 시간 |
| Distribution Summary | 데이터의 분포(합계, 평균, 백분위수 등)를 요약 ex: 응답 크기 |
| LongTask Timer | 긴 작업의 실행 시간을 측정. ex: 데이터 처리 작업의 소요 시간 |
동작 원리
- 애플리케이션 코드에서 Micrometer API를 사용해 메트릭 데이터를 수집
- MeterRegistry가 데이터를 저장하고 관리
- MeterRegisrty는 특정 주기마다 데이터를 모니터링 시스템(Prometheus, Datadog etc)에 Push하거나, Pull 요청을 처리
장점
- 다양한 모니터링 도구와 유연하게 통합됨
- Spring Boot와 완벽하게 연동됨
- 확장성: 사용자 정의 메트릭과 시스템 메트릭을 함께 수집해 포괄적인 모니터링 가능
- 가벼운 오버헤드: 애플리케이션 성능에 미치는 영향이 적음. 가볍다!
Micrometer와 Actuator의 관계
- Spring Boot Actuator는 JVM과 Spring 애플리케이션에서 기본적인 메트릭을 수집
- Micrometer는 Acutator와 통합되어 메트릭을 다양한 모니터링 시스템에 전달
- Actuator와 함께 사용하여 추가적인 코드 작성 없이 많은 기본 메트릭을 자동으로 노출할 수 있음
Zipkin
분산 추적 시스템.
MSA 환경에서 요청이 여러 서비스를 거칠 때 요청의 흐름, 성능 데이터, 호출 관계를 수집하고 시각화하는 도구
성능 병목 현상을 식별하고 문제 발생시 원인 분석에 유용한 도구
구성 요소
- Instrumentation (계측)
- 애플리케이션 코드에 라이브러리를 추가해 요청 데이터를 수집
- Spring Cloud Sleuth와 같은 라이브러리를 사용해 쉽게 통합 가능
- Collector (수집기)
- 계측된 애플리케이션으로부터 데이터를 수신하여 저장
- 데이터는 HTTP, Kafka, RabbitMQ 등을 통해 수집
- Storage (저장소)
- 수집된 데이터를 저장하는 시스템
- In-Memory, MySQL, Elasticsearch, Cassandra와 같은 다양한 스토리지 지원
- Query (쿼리)
- 저장된 데이터를 조회하여 요청 흐름과 성능 데이터를 시각화
- UI
- 브라우저 기반의 대시보드를 제공해 Trace 데이터와 성능 정보를 시각적으로 분석할 수 있음
주요 기능
- 요청 흐름 시각화
- 요청이 여러 서비스 간에서 어떻게 흘러가는지 추적해 호출 관계를 그래프로 표시
- 성능 병목 탐지
- 서비스별 요청 처리 시간, 호출 빈도, 오류를 확인해 성능 병목 구간을 탐지
- 장애 원인 분석
- 요청 실패 시 장애가 발생한 서비스와 원인을 빠르게 식별함
- 다양한 데이터 저장소 지원
- Elasticsearch, MySQL, Cassandra 등 다양한 스토리지 백엔드와 통합 가능
- 오픈소스와 확장성
- 오픈소스. 필요에 따라 커스터마이징, 확장 가능
동작 원리
- Trace ID 생성
- 요청이 들어오면 고유 Trace ID 생성
- Span 데이터 수집
- 요청을 처리하는 각 서비스는 Span(작업 단위) 데이터를 생성, Trace ID와 함께 기록
- 데이터 전송
- 각 서비스는 Span 데이터를 Zipkin Collector로 전송
- 저장 및 조회
- Zipkin Collector는 Span 데이터를 저장소에 저장
- Zipkin UI로 저장된 데이터를 조회, 요청 흐름과 성능 정보를 시각화할 수 있음
장단점
장점
1. 가볍다!: Docker를 이용해 빠르게 설치 가능
2. Spring Cloud와의 통합: Spring Cloud Sleuth와 함께 사용 시 자동 계측 및 데이터 전송
3. 다양한 저장소 지원
4. 실시간 데이터 시각화
단점
1. 확장성 제한: 대규모 시스템에서는 데이터 처리와 저장소 사용량 증가로 성능 저하 가능
2. 데이터 분석 기능 부족: 단순한 시각화와 기본적인 성능 분석만 제공. 복잡한 분석은 추가 도구를 이용
3. 보안: 기본 설치는 인증/인가 기능이 없어 외부 접근에 취약할 수 있다
요약
- 분산 추적은 요청 흐름과 성능 분석을, 로깅은 세부적인 문제를 디버깅하는 데 초점이 맞춰져있다
- Zipkin은 요청 흐름을 추적하고 병목 구간을 시각화
- Micrometer는 리소스와 시스템 전반적인 성능을 모니터링
- 로깅은 세부적인 이벤트와 문제 원인 분석
상호 보완적으로 작동하여 분산 시스템의 가시성과 운영 효율성을 극대화할 수 있다
서비스의 구조나 사이즈를 잘 파악해서 적합한 레벨로 구성해야 함
적용해보자!
Eureka Server:19090, Product:19092, Order:19091 이용
- 의존성 추가
implementation 'io.micrometer:micrometer-tracing-bridge-brave'
implementation 'io.github.openfeign:feign-micrometer'
implementation 'io.zipkin.reporter2:zipkin-reporter-brave'- yml 설정
- product
spring:
application:
name: product-service
config:
import: "optional:configserver:"
server:
port: 19092
eureka:
client:
service-url:
defaultZone: http://localhost:19090/eureka/
management:
zipkin:
tracing:
endpoint: "http://localhost:9411/api/v2/spans"
tracing:
sampling:
probability: 1.0
message: "dafault-message"- order
spring:
application:
name: order-service
server:
port: 19091
eureka:
client:
service-url:
defaultZone: http://localhost:19090/eureka/
management:
zipkin:
tracing:
endpoint: "http://localhost:9411/api/v2/spans"
tracing:
sampling:
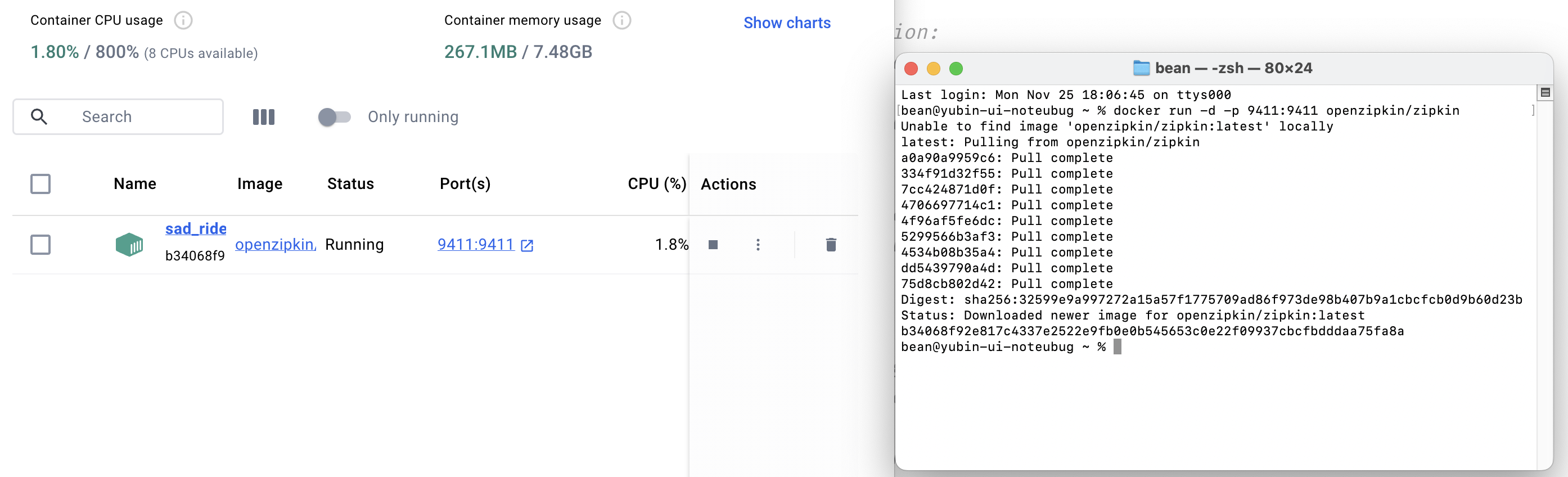
probability: 1.0- Docker 컨테이너 실행
docker run -d -p 9411:9411 openzipkin/zipkin
없으면 알아서 다운로드받아서 실행해준다

http://localhost:9411/zipkin/ 에서 대시보드 확인할 수 있음
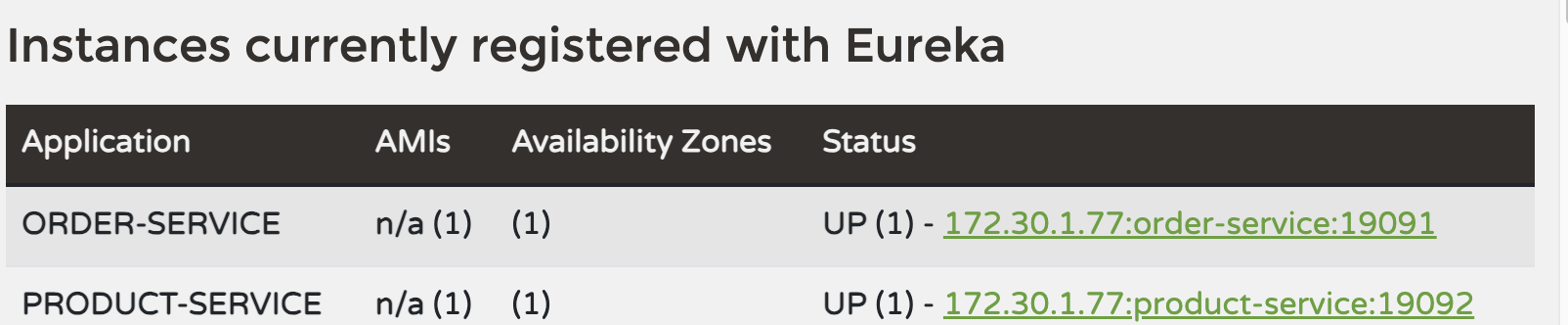
Eureka 대시보드에서 하위 서비스들이 정상적으로 실행된 것을 확인
order로 요청 전송
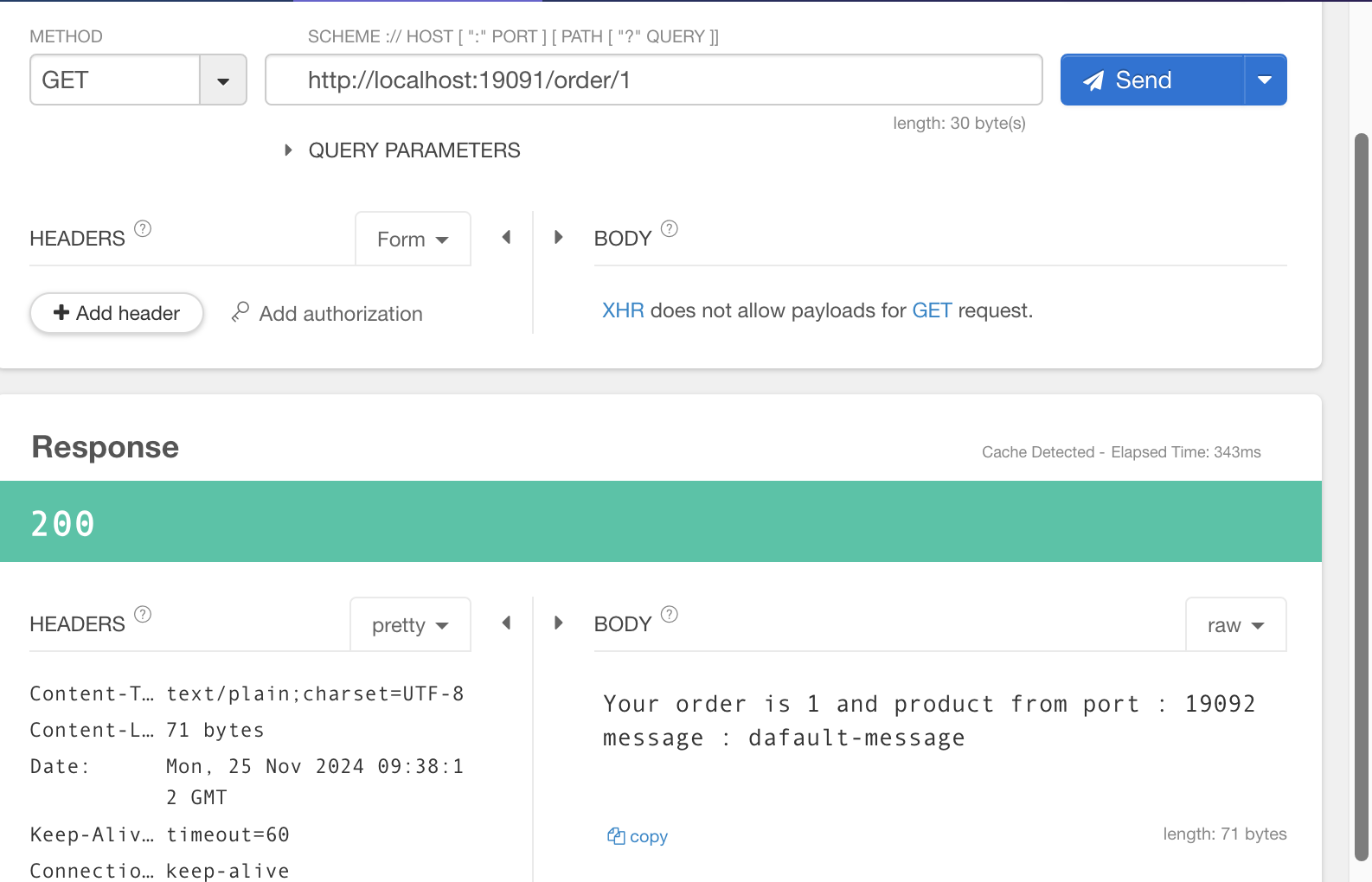
정상적으로 응답 반환 확인
zipkin에서 run qurey 실행
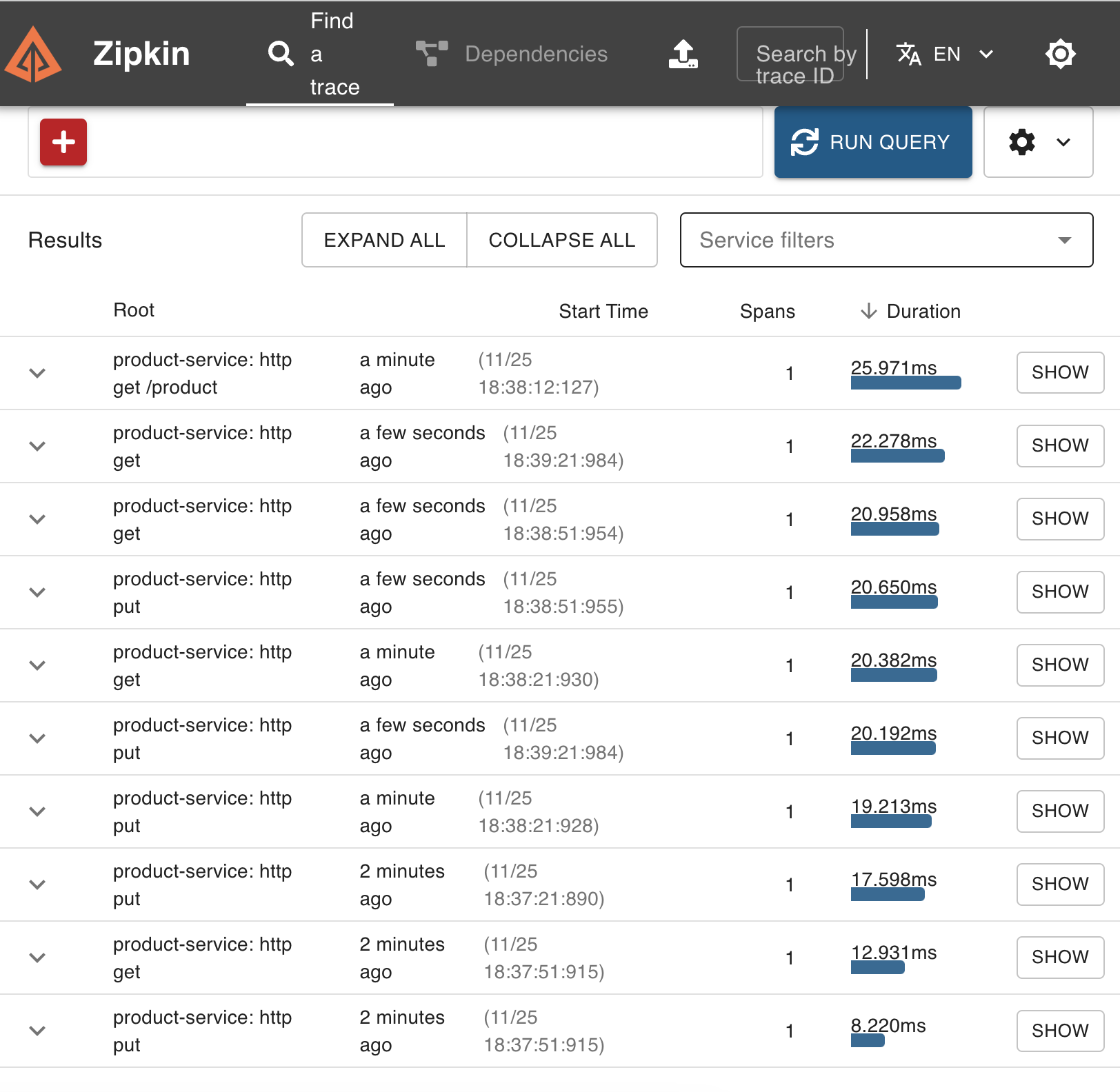
했는데, 확인해보니 잡히는 service가 product 하나뿐이었다
feign client로 order에서 product로 요청을 보내고, 응답을 반환하는데 그게 제대로 안 잡히는 것 같다
정상적으로 잡히는 product의 yml과 틀린그림찾기를 한참 하다가
Cannot resolve configuration property 'management.zipkin.tracing.endpoint',
Cannot resolve configuration property 'management.tracing.sampling.probability'
경고가 출력되는 걸 보고 gradle 틀린그림찾기를 거쳐
order에 누락된 acutator 의존성을 추가해줬다
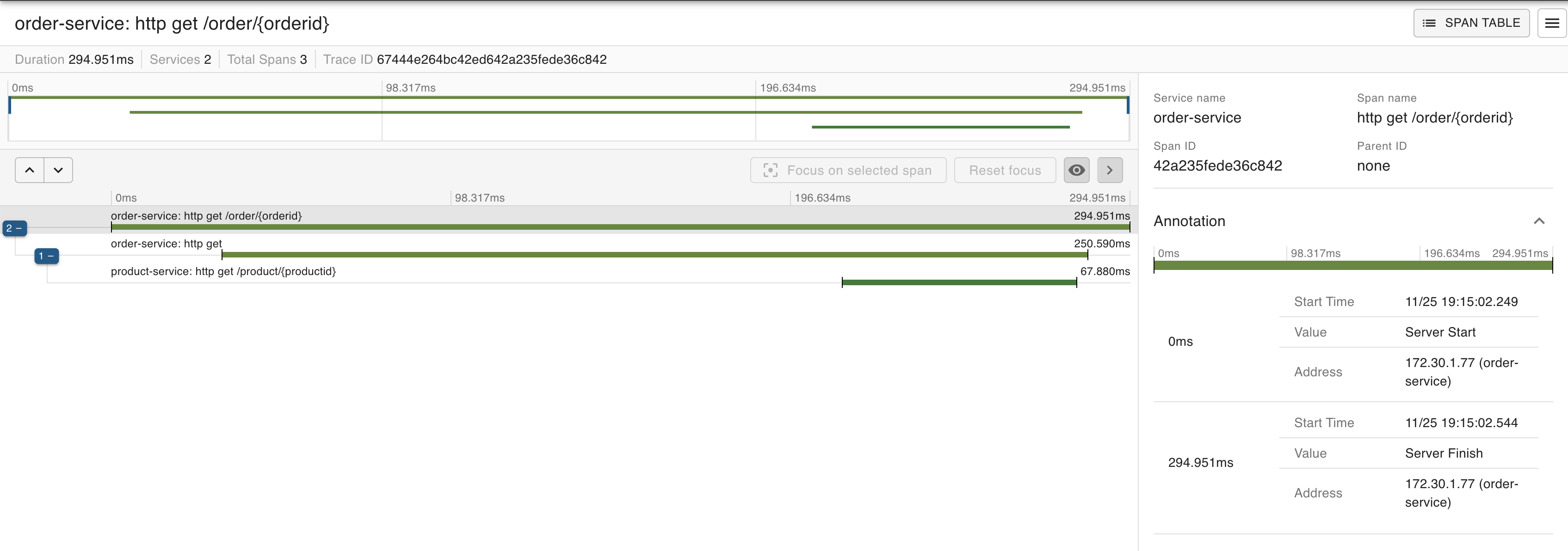
정상적으로 잡히는걸 확인할 수 있다
머리가 멍청하면 몸이 고생한다...
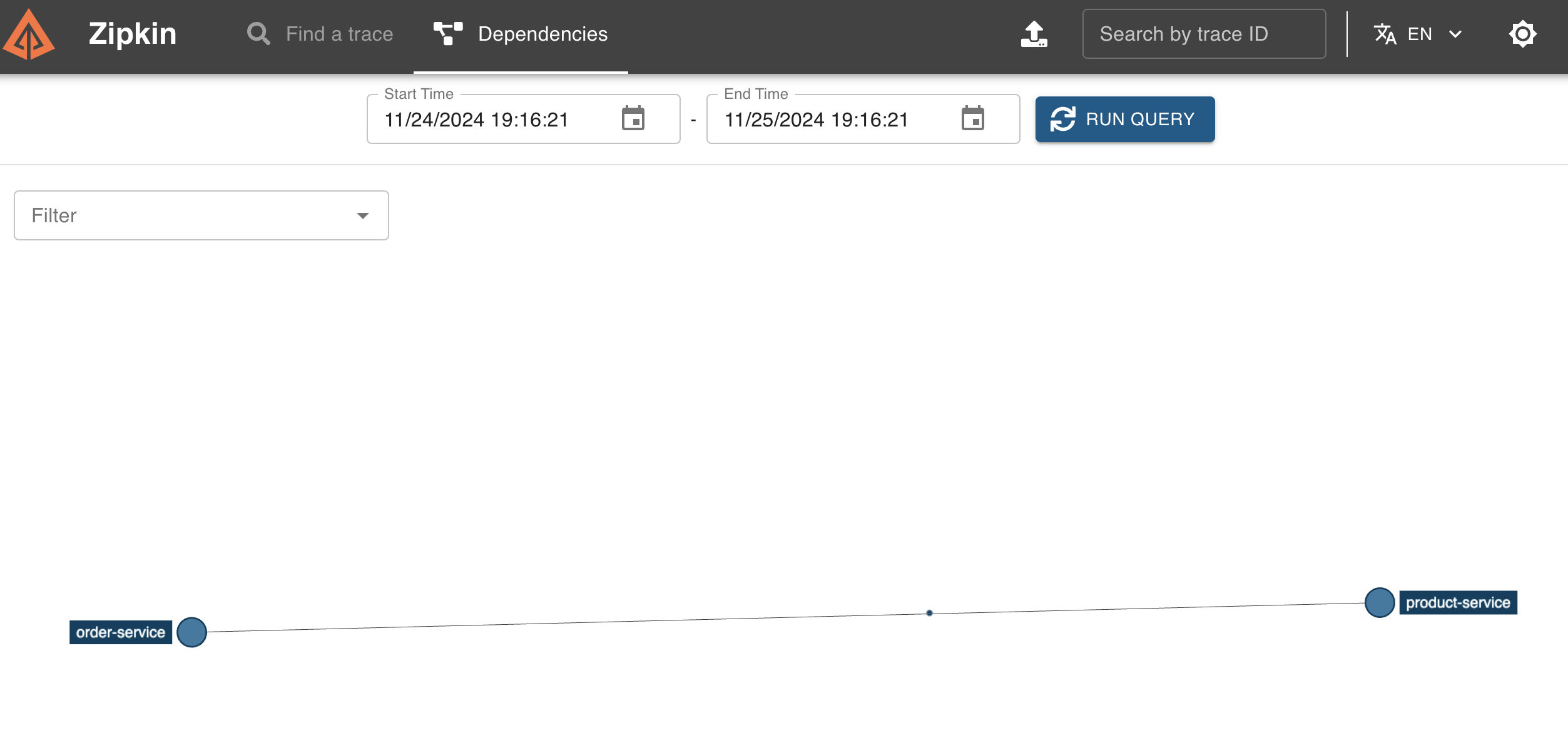
zipkins의 Dependencies에서 run query를 실행하면
시각적으로 요청의 흐름을 볼 수 있다!
끗.
Event-Driven
Event
시스템에서 발생한 상태 변화나 행동(주문 생성, 결제완료 등등)을 나타내는 메시지이다
발생한 사실을 한 번 전달(one-time notification)하며, 이 데이터는 이벤트 수신자(Consumer)가 처리한다
Event-Driven Architectue
애플리케이션 컴포넌트 간의 통신을 비동기 이벤트를 통해 수행하는 아키텍처 스타일
각 컴포넌트는 특정 상태 변화(이벤트)를 감지하거나 발생시키며, 이런 이벤트를 비동기로 처리한다
느슨한 결합과 확장성을 제공하여 복잡한 분산 시스템에서 효율적으로 동작한다
EDA의 핵심 요소
| 구성 요소 | 역할 |
|---|---|
| Event | 시스템에서 발생한 상태 변화 또는 행동을 나타내는 데이터 |
| Producer | 이벤트를 생성하고 브로커로 전송 |
| Broker | 이벤트를 전달하고 관리 |
| Consumer | 브로커로부터 이벤트를 수신하고 처리 |
| Channel | 이벤트 전달의 경로 |
| Event Source | Producer의 역할을 구체화. 상태 변화를 이벤트로 생성하여 전송 |
| Event Handler | Consumer의 역할을 구체화. 수신한 이벤트를 처리하는 비즈니스 로직 담당 |
| Event Bus | Broker의 역할을 구체화. 메시지 전달, 큐 관리, 라우팅을 수행 |
패턴
- 이벤트 브로커 패턴
- 이벤트를 브로커가 중간에서 관리
- 프로듀서와 컨슈머 간의 느슨한 결합 보장
- 메시지 큐 시스템(RabbitMQ, Kafka etc)이 주로 사용
- 이벤트 소싱 패턴
- 애플리케이션의 상태 변화를 이벤트로 기록하고 이벤트의 흐름을 통해 현재 상태를 재구성함
- 데이터베이스 상태 대신 이벤트 로그를 기반으로 데이터 일관성 유지
- 현상태를 이벤트 로그의 재생으로 복원할 수 있음
- ex) 주문 생성 -> 결제 완료 -> 배송 시작
- CQRS(Command Query Responsibility Segregation)
- 명령(Command)와 조회(Query)를 분리하여 읽기와 쓰기 작업을 독립적으로 처리
동작 흐름
- 이벤트 발생: 프로듀서에서 이벤트를 발생시키고 브로커로 전달
- 이벤트 전달: 브로커는 이벤트를 큐나 토픽에 저장하며, 구독 중인 컨슈머에게 전달
- 이벤트 처리: 컨슈머는 전달받은 이벤트를 비동기로 처리
- 결과 수행: 컨슈머는 이벤트를 처리한 후 다른 이벤트를 발생시키거나 결과를 저장
장단점
장점
1. 느슨한 결합
- 프로듀서와 컨슈머가 서로 독립적이며 직접적 의존성이 없음
2. 확장성
- 이벤트 브로커를 활용해 새로운 컨슈머를 쉽게 추가할 수 있음
3. 비동기 처리
- 요청-응답 방식과 달리 작업이 병렬 실행됨 ->성능 향상!
4. 실시간 데이터 처리
- 이벤트 발생 시 즉시 처리 가능
- 빠른 반응성과 실시간 데이터 처리가 요구되는 시스템에 적합함
단점
1. 복잡성 증가
- 이벤트 흐름과 상호작용 관리가 어려워질 수 있다
- 디버깅과 오류 추적이 복잡하다
2. 데이터 일관성 관리
- 비동기 시스템에서 데이터의 최종 일관성을 유지하는 데 추가 설계가 필요함
3. 이벤트 손실 위험
- 브로커나 네트워크 장애로 인해 이벤트가 손실될 가능성이 있음
4. 의도하지 않은 이벤트 폭주(!!)
- 잘못 설계될 경우 이벤트 폭주로 인한 성능 저하가 있을 수 있음
도구
| 도구 | 특징 |
|---|---|
| Apache Kafka | 고성능 이벤트 스트리밍 플랫폼. 대규모 이벤트 처리 및 분산 시스템에 적합함 |
| RabbitMQ | 메시지 큐 시스템으로, 다양한 메시징 패턴 지원 |
| AWS SNS/SQS | AWS에서 제공하는 이벤트 전달 및 큐 서비스 |
| Apache Pulsar | Apache Kafka와 유사한 분산 메시징 시스템으로, 멀티 테넌시 지원 |
| Google Pub/Sub | Google Cloud에서 제공하는 완전 관리형 메시지 브로커 서비스 |
기존 요청-응답 방식과의 비교
| 특징 | 이벤트 드리븐 | 요청-응답 방식 |
|---|---|---|
| 통신 방식 | 비동기 | 동기 |
| 결합도 | 느슨한 결합 | 강한 결합 |
| 확장성 | 높음 | 낮음 |
| 복잡성 | 높음 | 낮음 |
| 데이터 일관성 | 최종 일관성(Eventual Consistency) | 강한 일관성 |
Spring Cloud Stream
마이크로서비스 애플리케이션에서 메시지 기반의 비동기 통신을 쉽게 구현하기 위한 Spring 프레임워크
Kafka, RabbitMQ와 같은 메시징 시스템과 통합하여 메시지 생산 및 소비를 단순화함
분산 시스템의 EDA를 효율적으로 구현할 수 있도록 설계됨
주요 개념
- Binder
- Spring Cloud Stream과 메시징 미들웨어를 연결하는 추상화계층
- 메시징 시스템에 종속되지 않고, 애플리케이션에서 동일한 코드로 다양한 미들웨어를 사용할 수 있음
- 주요 Binder
- Kafka Binder
- RabbitMQ Binder
- Input/Output
- 메시지 채널을 의미. 애플리케이션의 메시지를 발행하거나 구독하는 인터페이스
@Input: Consumer를 위한 메시지 채널@Output: Producer를 위한 메시지 채널
- 메시지 채널을 의미. 애플리케이션의 메시지를 발행하거나 구독하는 인터페이스
- StreamBridge
- 동적으로 메시지를 전송하기 위한 API
- 런타임 시 토픽을 지정해 메시지를 전송할 수 있음
- Message
- Spring Cloud Stream에서 메시지는 헤더와 페이로드로 구성된 객체임
Message<?>타입으로 메시지를 주고받음
- Binding
- 애플리케이션의 메시지 채널을 외부 메시지 브로커(Kafka 토픽, RabbitMQ 큐 등)와 연결하는 설정
특징
- 미들웨어 추상화
- Kafka, RabbitMQ 같은 메시징 시스템과의 통합을 추상화해 미들웨어 교체가 용이함
- EDA 지원
- Spring Boot 통합
- 데이터 처리 지원
- 메시지 필터링, 라우팅 등을 지원
- Dynamic Destination
- 런타임에 동적으로 목적지를 설정 가능
동작 흐름
- Rroducer가 애플리케이션에서 메시지를 생성하고 @Output 채널을 통해 메시지를 브로커(Kafka, RabbitMQ)로 전송
- Broker가 메시지를 관리하고 지정된 큐나 토픽으로 전달
- Consumer가
@Input채널을 통해 브로커에서 메시지를 수신하고 처리함
장단점
장점
1. 미들웨어 독립성: 코드 변경 없이 다른 메시징 시스템으로 전환 가능
2. 비동기 메시징: 마이크로 서비스 간 통신을 비동기로 처리하여 성능 향상
3. EDA 지원
4. 유연한 설정: Functional Programming 모델로 동적인 메시지 처리가 가능
단점
1. 추상화로 인한 복잡성
2. 러닝커브
3. 추상화로 인한 성능 손실: 직접 메시징 시스템을 사용하는것에 비해 약간의 성능 손실이 있을 수 있음
주요 어노테이션
@EnableBinding(Deprecated)- 채널 인터페이스를 활성화하고 애플리케이션의 메시지 채널을 구성
- 현재는 @SpringBootApplication 설정만으로도 사용 가능
@StreamListener(Deprecated)- 메시지 처리를 위한 메서드를 정의
- 현재는 @Function 기반의 프로그래밍 모델을 사용
@Function,@Consumer,@Supplier- Functional Programming 방식으로 Producer/Consumer/Processor를 정의
