[논문요약] OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
논문읽기
목록 보기
3/6

이번 글에서 요약할 논문은 CV 분야의 인식, 지역화 그리고 탐지를 하나의 프레임워크로 가능하게 한 OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks입니다.
Link: arXiv - OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
Abstract 🍎
- 본 논문에서는 분류, 지역화 및 탐지를 위한 CNN을 사용한 통합 프레임워크를 제시합니다.
- 네트워크에서 다중 스케일 및 슬라이딩 윈도우 접근 방식을 통한 효율적인 구현 방식을 보여주며, bounding box를 예측하는 방법을 학습하여 지역화에 대한 새로운 딥러닝 접근법을 소개합니다.
- 또한 탐지에 대한 정확도(또는 신뢰도)를 높이기 위해 bounding box를 제한하지 않고, 누적하는 방식을 채택합니다.
- 마지막으로 단일 공유 네트워크에서 서로 다른 작업을 동시에 할 수 있다는 것을 보여줍니다.
Classification 📚
Model Design and Training 🎛
- 본 논문에서 사용된 분류 아키텍쳐는 Krizhevsky 등의 최고의 ILSVRC12 아키텍쳐와 유사하지만, 네트워크 설계와 추론 단계를 개선했습니다.
- 데이터셋으로 ImageNet 2012을 사용했습니다.
- 1.2M images
- 1000 classes
- 고정된 입력 사이즈(가장 작은 부분의 크기가 256)를 이용하며, 221 x 221의 5 Random Crop과 좌우 반전을 적용합니다.
- 세부적인 파라미터는 다음과 같이 초기화됩니다.
- Batch size: 128
- Weight Random Initialize
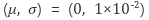
- Momentum SGD: 0.6
- Wegith Decay: 1 x 10^-5
- Learning Rate: 5 x 10^-2로 시작하여 (30, 50, 60, 70, 80) epoch마다 0.5 factor씩 감소
- 6, 7번째 레이어에 대해서 Fully-Connected Layer와 Dropout(0.5의 확률) 적용
- 1~5번째 Convolution Layer에 대해서 ReLU 활성화 함수 적용
- 1~5번째의 Convolution Layer를 Feature Extractor라고 부른다.
- 본 논문에서는 상대적으로 느리지만 정확도가 높은 Accurate Model과 상대적으로 정확도 낮지만 빠른 Fast Model로, 2개의 모델로 나누어 소개합니다.
Multi-Scale Classification 🗃
- 성능의 향상을 위해 multi-view voting을 사용하기도 합니다.
- 6, 7번균적으로 10 views로 고정하고, 4개의 코너와 중앙으로 총 5개를 뽑고, 추출된 5개의 이미지에 대해서 좌우반전을 적용합니다.
- 이렇게 사용하면 이미지의 많은 부분을 무시하게 되거나 중복적인 연산을 진행하게 될 수도 있다.
- Convolutional Network를 사용하게 되면 전체 이미지를 각 위치와 여러 스케일에서 조밀하게 탐색하는 것이 가능한데, 이 방식에 따르면 효율이 좋아지고 견고해진다고 합니다.
- 그러나 CNN을 계속해서 통과시키다보면, subsampling이 되어 subsampling ratio에따라 작게 변하게 됩니다.
- 이렇게 되면 최종 feature map이 원본 이미지에 대해서 표현하는 해상도가 너무 포괄적이게 되는데, 논문에서는 객체와 feature map 사이의 정렬(align)이 맞지 않는다고 표현합니다.
- OverFeat의 경우 R-CNN과 다르게 One Stage Detector로 R-CNN처럼 Object Proposal을 생성하지 않고 single forward pass 방식으로 CNN 모델을 학습시킨 후, Multi-scale evaluation을 통해 사물을 검출합니다.
ConvNets and Sliding Window Efficiency 🎞
- 본 논문에서 한 번에 하나씩 입력의 각 창에 대해 전체 파이프 라인을 계산하는 많은 슬라이딩 윈도우 접근 방식과 달리, ConvNet은 중첩 영역에 공통적인 계산을 자연스럽게 공유하기에 슬라이딩 방식으로 적용될 때 본질적으로 효율적이라고 주장합니다.
- 이렇게 하면 각 레이어의 출력이 새로운 이미지 크기를 포함하도록 확장되어 결국 입력의 각 window(시야)에 대해 하나의 공간 위치가 있는 출력 클래스 예측 맵이 생성되는데, 인접한 창에 공통된 계산은 한 번만 수행하면 됩니다.
- 마지막으로 FC레이어에 대해 1x1 사이즈의 커널로 효과적이게 대체할 수 있다.
Result 🔑
- 위에서 설명한 접근 방식으로 6개의 스케일을 사용하여 13.6%의 top-5 error를 달성했습니다.
- 예상대로 더 적은 스케일을 사용할 경우, 성능이 저하되며 단일 스케일 모델은 top-5 error가 16.97%로 더 낮았다고 합니다.
- 또한 ILSVRC 2013 데이터셋의 경우 최상 정확도는 11.7% 이였다고 주장합니다.
Localization 🖼
Generating Prediction 🤖
- 분류에 대해 훈련된 네트워크에서 시작하여 분류 계층을 회귀 네트워크로 대처하고 각 공간 위치 및 규모에서 bounding box를 예측하도록 훈련합니다.
- 그런 후 지회귀 예측을 각 위치의 분류 결과와 함께 결합합니다.
- bounding box 예측을 생성하기 위해서 모든 위치와 규모에 걸쳐 분류기와 회귀 네트워크를 동시에 실행합니다.
- 각 위치에서 클래스에 대한 최종 소프트맥스 계층의 출력은 해당 위치에 객체(클래스)가 존재한다는 신뢰도(정확도)를 제공하게 됩니다.
Regressor Training 🥍
- 5번째 레이어에서 풀링된 피처 맵을 입력으로 사용합니다.
- 분류 네트워크에서 특징 추출 계층을 수정하고 각 예제에 대해 예측된 bounding box와 실제 bounding box 간의 L2 손실을 사용하여 회귀 네트워크를 학습시킵니다.
- 단일 스케일도에 대한 교육은 해당 스케일에서 잘 수행되고 다른 스케일에서는 여전히 합리적으로 수행되게 됩니다.
- 그러나 다중 스케일을 훈련하면 스케일간에 예측이 올바르게 일치하고 병합된 예측의 신뢰도가 기하 급수적으로 증가하게 됩니다.
- 결과적으로 이는 일반적으로 탐지의 경우와 같이 여러 스케일이 아닌 몇 가지 스케일로만 잘 수행할 수 있게 됩니다.
Combining Predictions 🕶
- bounding box에 적용된 Greedy Merge Strategy을 통해 개별 예측을 합칩니다.
- 이 경우 두 bounding box의 중심과 box의 교차 영역 사이의 거리 합계를 사용하여 일치 점수를 계산하게 됩니다.
- 최종적으로 예측된 결과는 최대 점수를 보유하고 있는 bounding box로 나타나게 됩니다.
Experiments 🔍
- 검증을 위해서 ImageNet 2012 검증 세트를 사용했으며, 29.9%의 오류율로 2013년 대회에서 우승했습니다.
- 핵심적으로 다중 스케일 및 다중 뷰 접근 방식은 우수한 성능을 위해서 중요합니다.
- 만약 단일 중심 crop만 사용시 40%의 오류율에 도달하게 된다.
Detection 🔭
- 탐지 학습은 분류 학습과 유사하지만 차이점이 존재한다.
- 이미지의 여러 위치를 동시에 학습할 수 있으며, 가장 큰 차이점은 개체가 없을 경우 배경에 대해서 예측을 해야한다는 것이다.
- 본 논문 속 탐지 시스템이 평균 평균 정밀도 (mAP) 19.4 %로 3 위를 차지한 ILSVRC 2013 대회 결과를 만들어냈습니다.
Discussion & Conclusion 🙄
OverFeat
- OverFeat 모델은 다음과 같은 순서로 동작하게 됩니다.
1. 6-Scale의 이미지를 입력 받습니다.- Classification task 목적으로 학습된 Feature extractor에 이미지를 입력하여 feature map을 얻습니다.
- Feature map을 Classifier와 Bounding box regressor에 입력하여 spatial map을 출력합니다.
- 예측 bounding box에 Greedy Merge Strategy 알고리즘을 적용하여 예측 bounding box를 출력합니다.
- Overfeat 모델은 Classification, Localization, Detection task에 모두 사용할 수 있습니다.
- Overfeat을 Classification task를 위해 학습시킨 후, fc layer를 제거하여 feature extractor로 활용하여 localization, detection task에 사용될 수 있습니다.

인공지능처럼 공부하고 싶은 인공지능 개발자