DL 용어 정리
A
auxiliary loss
보조의 loss. 주요 loss는 아니고 학습에서 나타나는 안 좋은 현상을 막으려고 추가적으로 쓰이는 loss.
C
cascade
직렬. 네트워크를 병렬이 아니라 위로 쌓는 것.
canonical
=vanilla, 공식적인. 처음 제안된 아키텍쳐를 말함.
D
domain adaption
A 데이터에서 잘 훈련된 모델을 B 데이터에서도 잘 훈련되도록 하는 것
https://en.wikipedia.org/wiki/Domain_adaptation
I
inductive
<-> transductive
그냥 우리가 생각하는 supervised learning. labeled data로 학습하고 unlabeled로 prediction 하는걸 inductive learning.
O
online learning
batch size 1 짜리 학습. 실제 서비스에서 데이터 하나 들어오면 그걸로 학습하는 그런 환경의 학습.
P
parametric
<-> non-parametric
non parametric은 데이터에 따라 파라미터가 무한히 늘어날 수 있는 decision tree 같은 류를 뜻함.
parametric은 뉴럴네트워크처럼 모델을 정의할 때 파라미터가 고정되고 계속 늘어나지는 않으니 parametric.
pretext task
=pretraining task. BERT에서 Masked Lanugage Modeling. self-supervised learning(SSL)에서 사용자가 unlabeled data에 태스크와 label을 다는 것. 비전의 SSL에서 많이 쓰는 용어인듯?
https://hoya012.github.io/blog/Self-Supervised-Learning-Overview/
S
salient / non-salient

salient = 이미지에서 주인공. 중요한.
non-salient = 배경 background
stochastic
<-> deterministic
확률적인. 어떤 결과값이 0.37 처럼 나오는게 아니라(=deterministic) 0.5이상일 확률이 0.9, 이하일 확률이 0.1와 같이 확률로 나오는 것.
t
transductive
<-> inductive
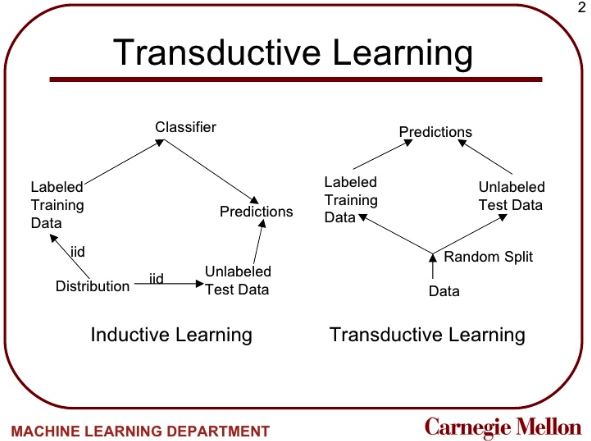
labeled 된 데이터로 모델 학습을 하는데, 그 모델을 unlabeled 데이터에 대해 바로 predict하는게 아니라 unlabeled 데이터의 분포도 고려해서 predict 하는 방식.
L
linear probing
backbone 모델에 linear(FCN)붙여서 linear만 학습하는 것. ( <-> finetuning은 모든 백본을 학습하는 것)
-> linear evaluation: linear probe로 학습한걸로 평가한거
이미지 출처
