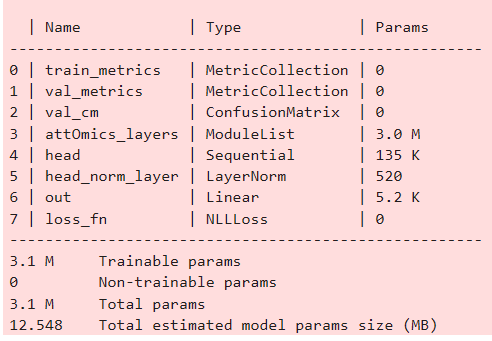
위와 같이 파라미터가 정보를 볼 수 있다. 총합해서 3백만개 정도의 paramater가 나왔다.
문제는 test 할때가 문제였는데 아래사진처럼 마지막 test_epoch_end에서 논문작성자가 가지있는 또다른 Omics를 쓰는것으로 판단이 된다. 이유인 즉슨 코드에서 가지고 있는 OmicsDataset Class에서는 name이 없기 때문.

사실 test_epoch_end의 코드는 test_step에서의 data를 통해 받은 결과값을 단순히 log를 남겨주는 역할을 한다 생각되어 기존의 mRNA data랑 label를 집어넣고 예측하는 것을 출력해주는 방식으로 바꾸어주었다.
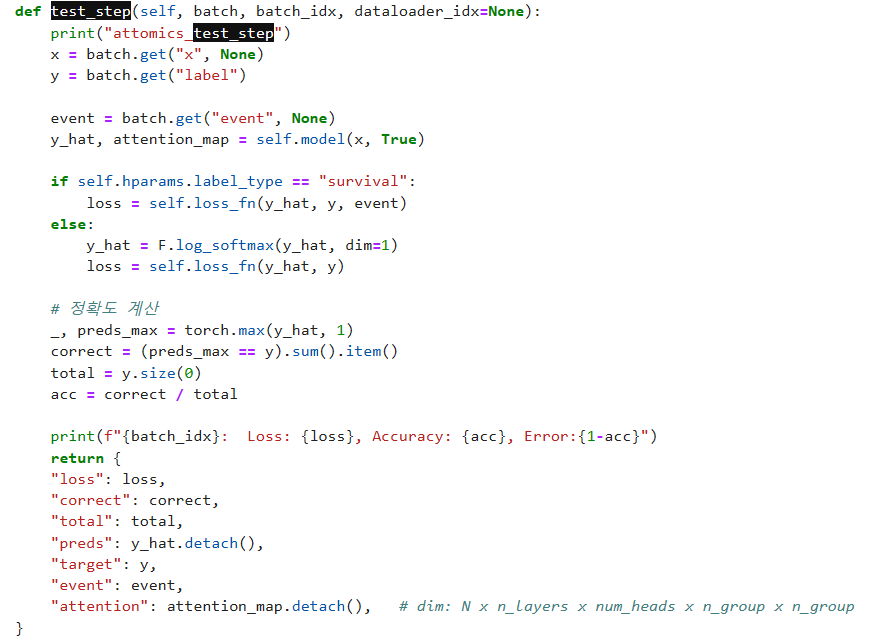

이렇게 수정해 결과를 확인해보았다.
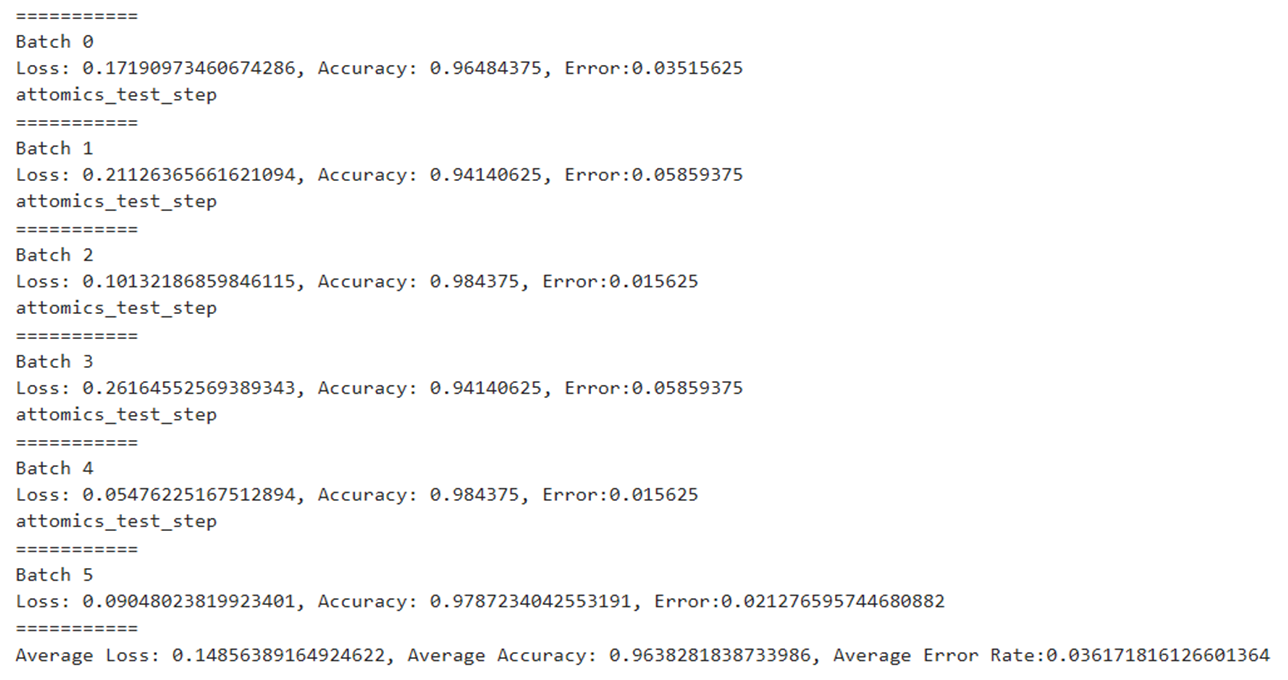
random 전체 정확도는 0.96 오류는 0.036정도나왔다. 다시한번 논문을 봐보자
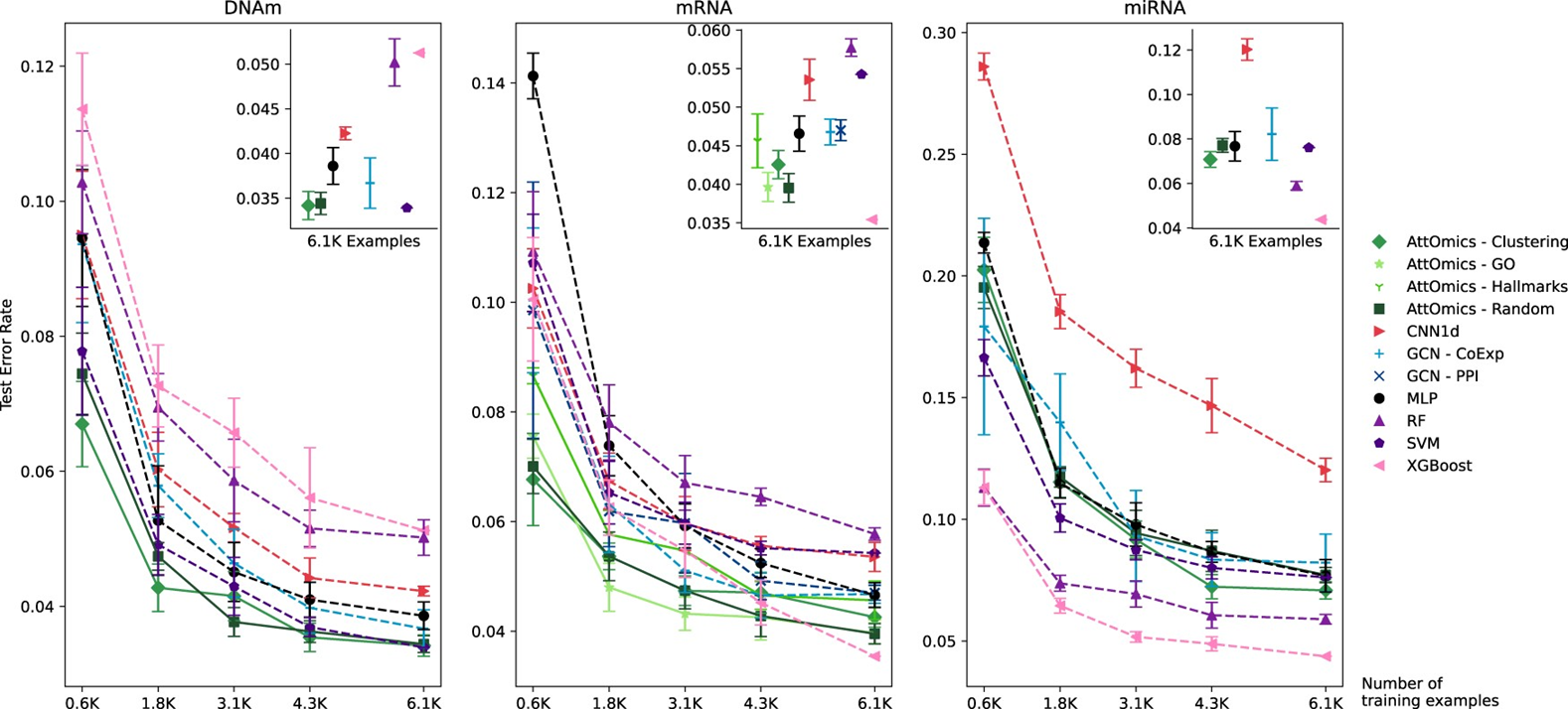
우리가 사용한 train 갯수는 6134개로 6.1k를보면 0.036언저리임을 알 수 있다. 일단 모델은 정상적으로 돌아가고 있다는 뜻
random도 random이지만 Gene Ontoloy를 기준으로 블럭을 나누는 기준으로 사용하는 것도 논문에서 나온거같아 이를 실행하려고했는데

이렇게 오류가 떠서 확인해봤다.
넣는 데이터 자체가 Dataframe이고 이름도 있는걸봐서 애초에 넣는데이터가 다르다 판단. 일단 발표에서 언급하기로했다.

인간입니다. 다만 컴공을 전공하고있는...