논문의 데이터를 확인해보니 주어진 npy파일들이 결국 내가,그리고 교수님이 원하는 TCGA 데이터를 가지고 만든것이였다. 굳이 내가 GCA 포털에서 다운을 안받아도 된다는 의미.
다만 문제는 cluster방식이랑 gene_ontology_grouping을 사용하기 위해서는 해당 환자들이 가진 feature(아마)에 대한 columns가 필요하기 때문에 분석이 조금 필요했다.
아래의 캡쳐화면은 해당 논문에서 제공한 npy에 대해서 전처리한 것을 count해서 보여주게 만들었다.
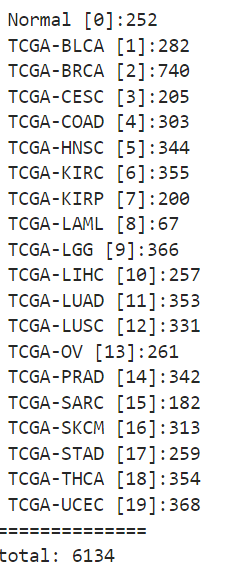
논문에서 말한 자료의 사진이다.
보면 숫자들도 같기 때문에 GCA에서 가져온 데이터가 맞음은 확실했다.
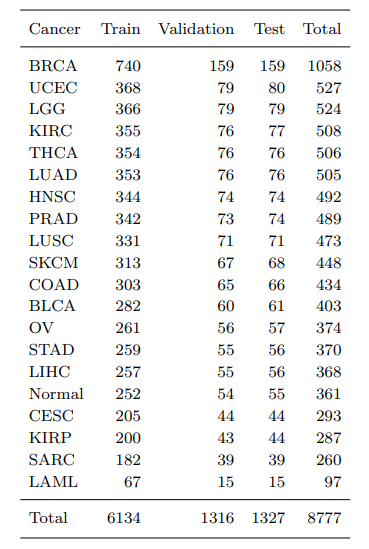
일단 교수님을 통해서 받은 TCGA - BRCA의 경우 아래와 같은 데이터 형태를 가지고 있다.

아마 columns에 있는 정보들을 불러와서 이를 처리를 해야되는데 논문에서 제공한 데이터의 경우
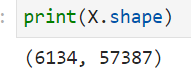
처럼 feature갯수가 거의 3배급으로 차이난다. 이를 어떻게 처리 해야될까?
일단 기간이 지나고 찾아보니 일단 교수님한테 받은 데이터는 의미가 없다고 판단되어 일단 논문에 있는 데이터를 사용하기로 결정.
clustering이랑 Gene Ontology를 사용하는 경우에는 Data Frame로 변환을 해서 적용을 해야된다.
training에 넣는데 자꾸 아래와 같은 오류들이 뜬다.




환장하겠다. 아무리 돌려도 저 4개의 오류만 계속 돌려막기 식으로 3일내내 반복했었는데 오늘 당장은 또 갑자기 돌아갔다. 도대체 이게 무슨 상황인지 하나도 모르겠다.
계속 torch 커뮤니티랑 github을 아무리 뒤져서 나온 torch 버전 다운그레이드, export CUDA_LAUNCH_BLOCKING=1 등 별의별 시도를 했지만 아무것도 통하지 않았고 왜인지 좀 지나고 나서야 갑자기 작동했다....
