매번 모델을 돌려서 학습 시키는게 귀찮아서 모델의 파라미터가 저장된 정보들을 가지고 있는 ckpt파일을 불러와 실행을 시키는 방법을 선택했다.
1번째 문제는 처음에 train/valid/test를 나눌때 random하게 섞는 방식을 사용해서 매번 모델을 불러와 test를 돌리면 매번 Accuracy가 달라지는 현상이 있었다.

위의 그림처럼 무작위로 특정 비율로 선택된 train /valid 를 훈련해서 저장을 해놓고 Test 돌릴 때는
아래의 사진처럼 다른 test를 선택하게 해서 결과가 매번 달라지는 것이였다.

이게 유의미하다고 볼 수 없는게 이미 훈련 시켜놓은 모델의 파라미터에 포함된 데이터들이 leak이 되는거랑 다를바가 없어서......
Random으로 섞는 방식의 경우 대부분은 Random seed라는 값을 사용한다.
쉽게 말해 그냥 겉보기에는 랜덤으로 섞는거 같지만 컴퓨터는 이게 불가능하기에 어떤 특정한 방식으로 특정한값을 생성하는것을 우리가 단순히 랜덤으로 생성해준다는 느낌을 받는 것이다.
그렇기에 Random seed의 값이 같으면 랜덤하게 보이는 값도 같다는 것.
이를 사용해서 KIPAN 데이터를 섞을때, Train, Valid, Test 를 나눌때 내가 그냥 random seed만 가지고 있으면 항상 동일한 결과로 불러오는것이 가능하다.
Dataframe을 섞어주는 코드자체는 엄청 간단하다.
shuffled_df = new_df.sample(frac=1, random_state = 42).reset_index(drop=True)이전의 코드에서 그냥 random_state = 42 이거만 추가해주고 내 시드가 42인것만 알면 된다.
2번째 문제는 내가 그냥 훈련 epoch을 50으로 했다는 것이다. 이 학습량이 overfitting인지 underfitting인지 알수가 없기에 모델이 제대로 학습을 했는지 알 수 가 없다.
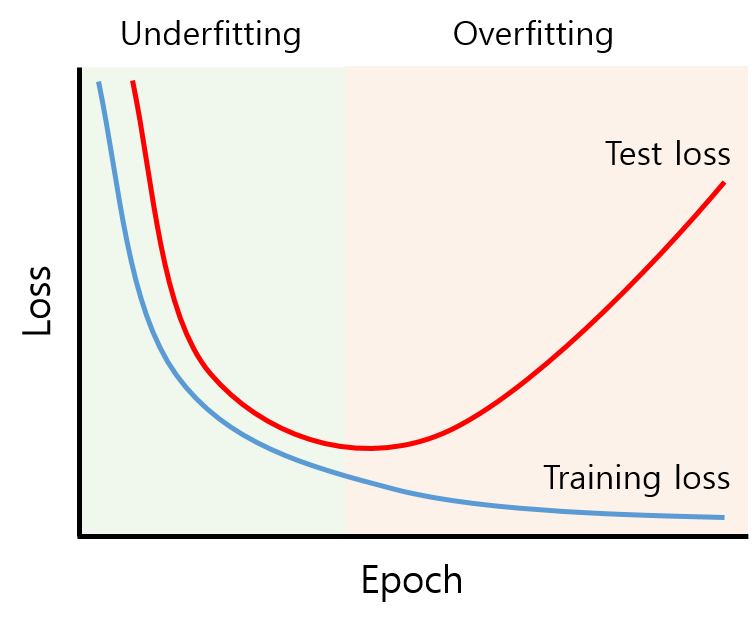
일반적으로 위의 그림처럼 training loss 는 계속 내려가고 test(혹은 valid)는 감소하다가 다시증가하는데 train과 test사이의 loss차이가 가장 작은 타이밍의 epoch이 적합한 모델인 것이다.
이를 구현하기 위해 train,valid loss계산 한 것을 따로 저장하고 이를 시각화 하는 방식이 필요하다.
def validation_epoch_end(self, val_step_outs):
if self.hparams.label_type not in self.surv_label:
preds = torch.cat([x["preds"] for x in val_step_outs], dim=0)
target = torch.cat([x["target"] for x in val_step_outs], dim=0)
cm = self.val_cm(preds, target)
val_loss_list = []
val_loss_list = [x["val_loss"].item() for x in val_step_outs]
avg_val_loss = torch.mean(torch.tensor(val_loss_list))
def on_train_epoch_end(self):
train_loss = self.trainer.callback_metrics.get("train_loss").item()
self.train_loss_history.append(train_loss)
print(f"Train Loss : {train_loss}")
def on_validation_epoch_end(self):
val_loss = self.trainer.callback_metrics.get("val_loss").item()
self.val_loss_history.append(val_loss)
print(f" Validation Loss : {val_loss}")
def on_train_end(self):
plt.figure()
plt.plot(self.train_loss_history, label="Train Loss")
plt.plot(self.val_loss_history[1:], label="Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.title("Train vs Validation Loss")
# 그래프를 파일로 저장 (예: 'final_loss_graph.png')
graph_filename = "final_loss_graph.png"
plt.savefig(graph_filename)
print(f"Final loss graph saved as {graph_filename}")2번째 문제는 내가 학습시킨 방식이 overfitting인지 underfitting인지 모른다는것이다. 따라서 earlystopping을 대입해서 혹시모를 overfitting 을 방지하는 코드로 수정했다.
from torch.utils.data import DataLoader
from pytorch_lightning import Trainer
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
from pytorch_lightning.loggers import MLFlowLogger
early_stop_callback = EarlyStopping(monitor="val_loss", min_delta=0.01, patience=10, verbose=True, mode="min")
trainer = Trainer(gpus=[1
],
logger=MLFlowLogger(experiment_name="AttOmics",save_dir= "./kipan_logs/random"),
max_epochs=200,
callbacks=[early_stop_callback]
)
trainer.fit(model, train_dataloader=train_loader, val_dataloaders=val_loader)min_delta 와 patience를 통해 어떠한 경우에 earlystopping을 적용할건지 정할 수 있다.
대충 작동 방식을 말하자면 patience(일정 횟수) 동안 min_delta(최소 변화량)이상으로 변하지 않으면 훈련을 멈추는 방식
mode 파라미터 같은 경우 min 혹은 max로 지정하는데 loss를 줄이냐, accuracy를 높이냐에 따라 어떤 값어치로 보냐에 따라 정하는 것이다. 필자의 경우에는 vaild loss를 기준으로 했기 때문에 min로 설정.
결과는 다음과 같이 나왔다.
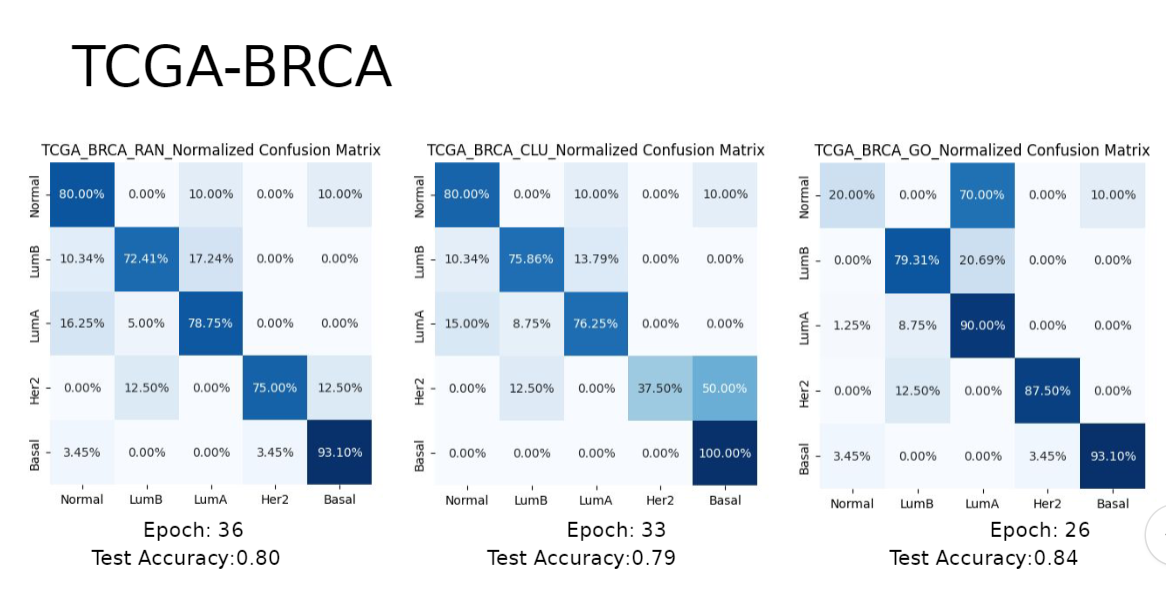
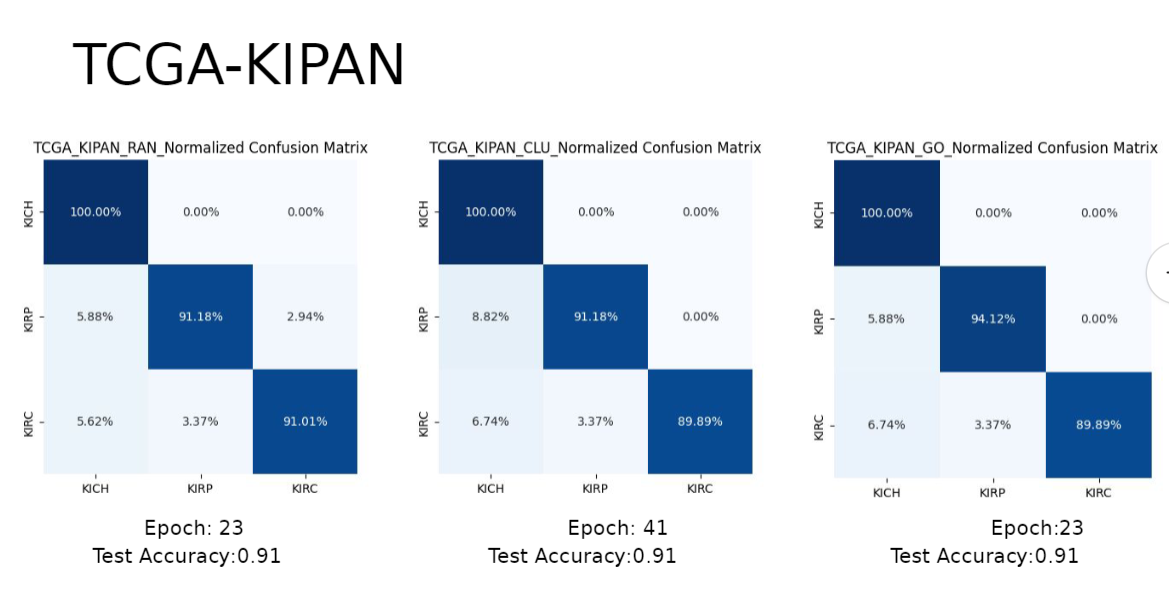
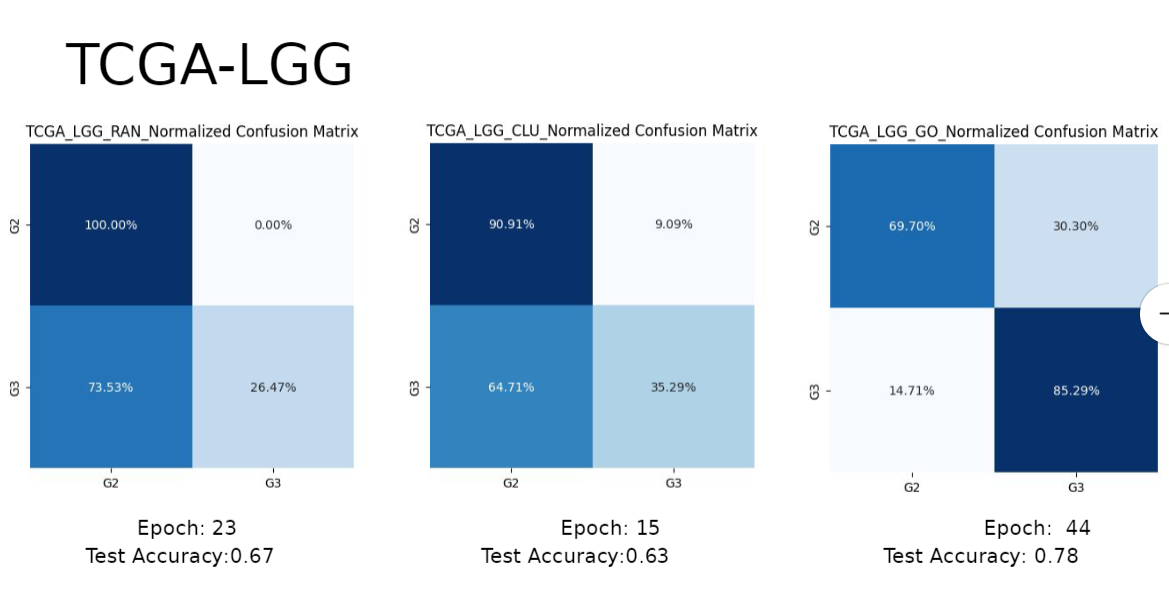
LGG의 경우에 애초에 워낙 데이터양이 다른 BRCA나 KIPAN에 비해 작다보니까 전체적인 정확도 자체가 낮게 나온걸로 보인다.
