
시험기간이라서 진도를 따로 빼진않았다. 관련햇 교수님이 PAAD 췌장암 Classification을 위해 subtype을 조사를 하라 그랬는데 너무 힘들었다.
프로그래밍을 전공하고있는데 존스 홉킨스 의과대학 홈페이지를 들어가서 보고 네이쳐 논문에 발간된 췌장암 논문을 읽는등 진짜 정신 나갈정도로 Domain 지식이 나를 괴롭혔다.
이러지 말아다오
결론적으로 말하면 쉽게 subtype을 나눌 수 없다는게 결론.
그래서 교수님이 일단은 PAAD관련에서는 미루고 Pan cancer classification 을 좀 돌려보라 하셨다.
GDC 포털 데이터를 쓰는법이 너무 감이 안잡히고 그래서 교수님이 서치해보면 데이터 어딘가에 있을거다....라는 안일한 대답 덕에 계속 찾아본 결과 아래와 같은 사이트를 하나 찾았다.
2020년도 네이쳐지에 실린 TCGA 데이터를 다운 받을수 있는 거같다.... 이걸로 한번해보자
찾아서 확인해보니 gene expression이 아니라 그냥 clinical data 였어서 나에게는 쓸모가 없었다.
나는 mRNA seq gene expression데이터가 필요한데 해당사항이 아닌 것.
논문을 좀 찾아보니 아래 R 통해서 TCGA 데이터를 접근할 수 있는 방법이 있었다.
TCGA2STAT이라는 데이터인데 일단 다운받을라 했는데

갑자기 인터넷 연결 오류라고 뜬다. 좀 찾아보니까 CRAN이랑 Bioconducter에서 사라졌단다..
위에서 찾은 cBioportal의 경우에는 1200개에 70개의 cancer label이라 학습을 한다해도 이게 유의미하게 잡힐련지 의문이 간다. 그래서 일단 교수님한테 요청을 해서 교수님이 데이터 찾아봐주겠다고는 했다.
TCGA 데이터는 결국 받았다 사실 이전에 좀 찾아 놓은거랑 같긴한데 해당 환자에 대한 Tumor 타입이 없어서 쓰지 못했던걸 교수님이 관련 레이블 데이터를 주셔서 진행 할 수 있었다.
모델을 돌린 결과
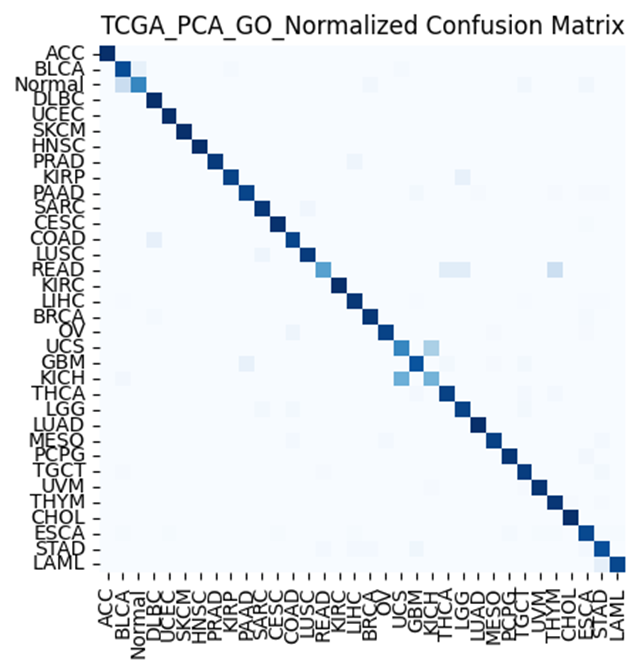
평균 정확도가 91% 대로 나오고 각 label 마다 좀 확인을 해보았다.
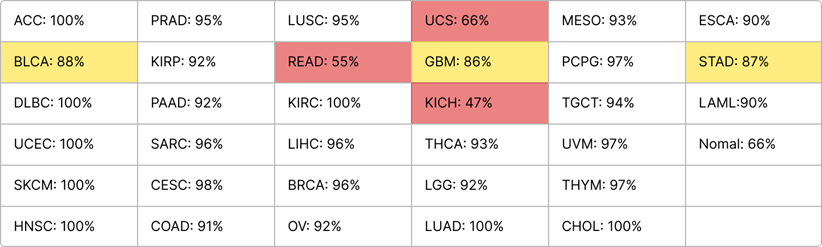
전반적으로 괜찮긴한데 일단 Normal의 경우를 제외만 해도 일정 수준이상 정확도가 높아 질것같다. 사실 각 종양에 대한 데이터도 매우 불균형하게 존재해서 데이터가 너무 적은 label은 빼야될지 고민중이다.
가장 먼저 해봐야 될 것은 Normal 빼기
이후에 Early-Stopping 조건을 변경하면서 정확도 가장 잘나온 케이스를 만들고 Layer부분까지 건드릴 생각 해야된다
