지금 인공지능에 있어서 Transformer 모델을 절대 빼놓을 수 없다. 거의 모르면 첩자 수준.
논문은 2017년에 나왔지만 여전히 잘 우려먹히고 있다.

뉴진스 Attention 말고
그래서 다시한번 Attention를 상기하는 겸 논문 리뷰를 해볼까 한다. 꽤 괜찮은 영상도 있기에 참고하면서 공부를 할 수있었다
생각보다 논문을 보면 매우 불친절하게 느껴질법하다.
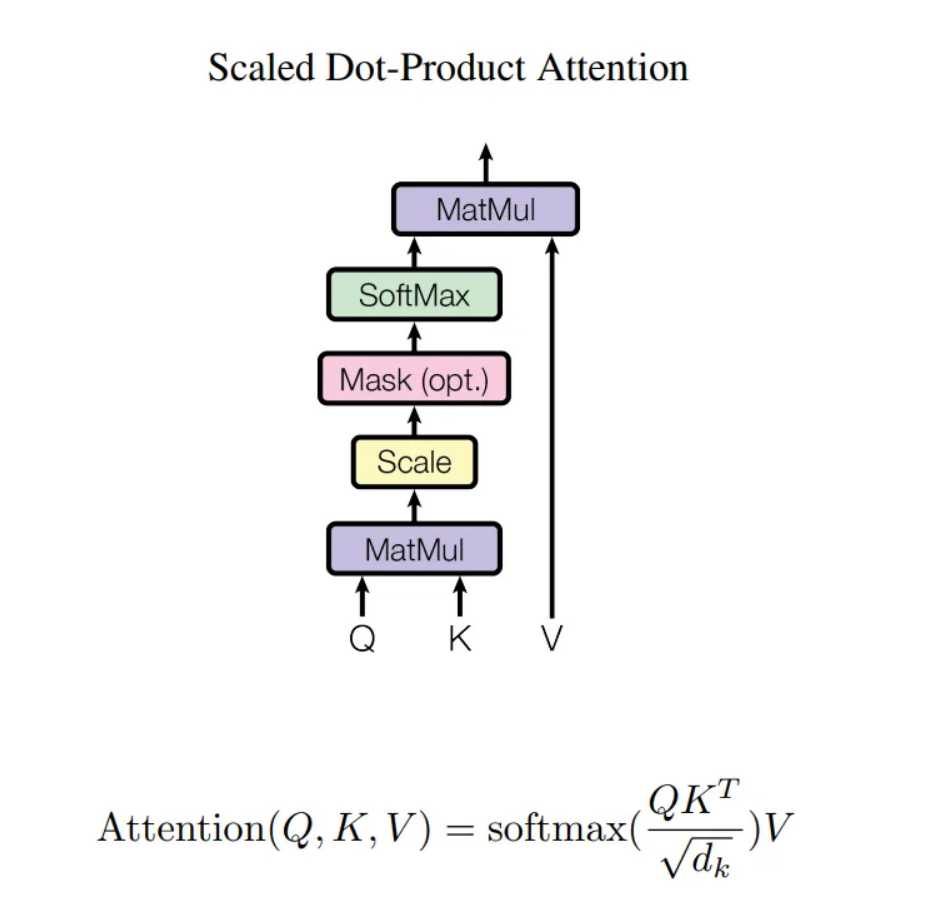
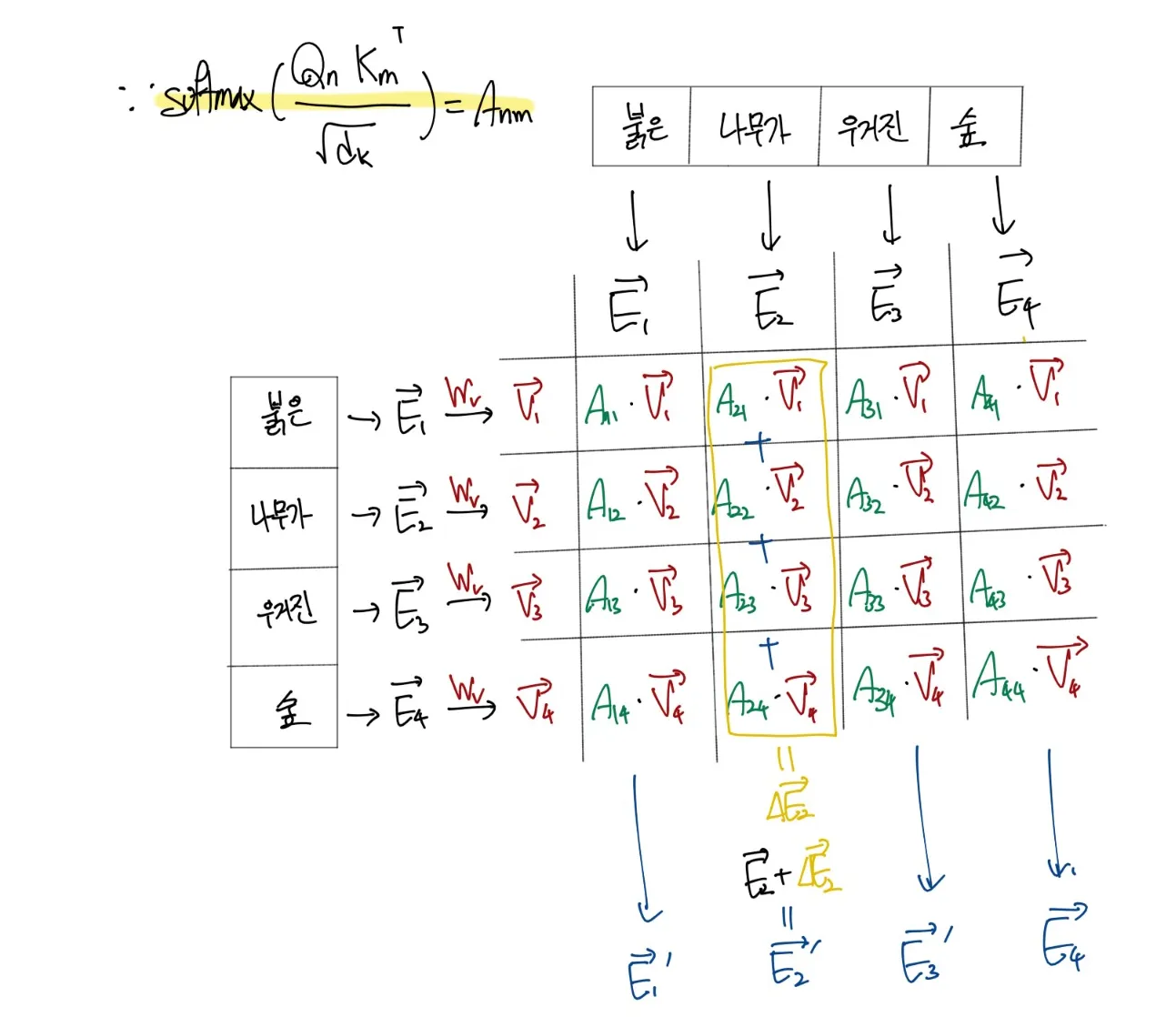
이게 뭐하자는건가. 가장 핵심 부분인 Scaled Dot-Product Attention에서는 딸랑 수식 하나와 사진을 남긴채 갑자기 성능지표로 넘어가니 개인적으로 뭐지 싶어서 자세한 예를 들면서 작성해볼까 한다.
혹시 이 포스트를 보는 사람들의 이해가 되길 바라면서...
물론 기본적인 임베딩, Softmax와 같은 설명은 대폭 생략했으니 해당 개념들을 모르면 뒤로가기를 추천한다.
결국 Transformer에서 하고자하는건 기존의 LSTM, GRU, Recurrent Neural Network의 한계인 데이터의 순차적 입력, Sequence 데이터간의 Dependency 모델링 그리고 하드웨어적인 성능으로 인한 길이 제한들을 벗어나는 방식인 것이다.
붉은 나무가 우거진 숲이라는 문장으로 예시를 들어보자. 단어 임베딩의 경우 단순하게 아래 사진과 같이 나누었다고 가정을 하자 (사실 영어로 했으면 단어를 나누는게 좀 더 편했을지도 모르지만 그냥 넘어가자)
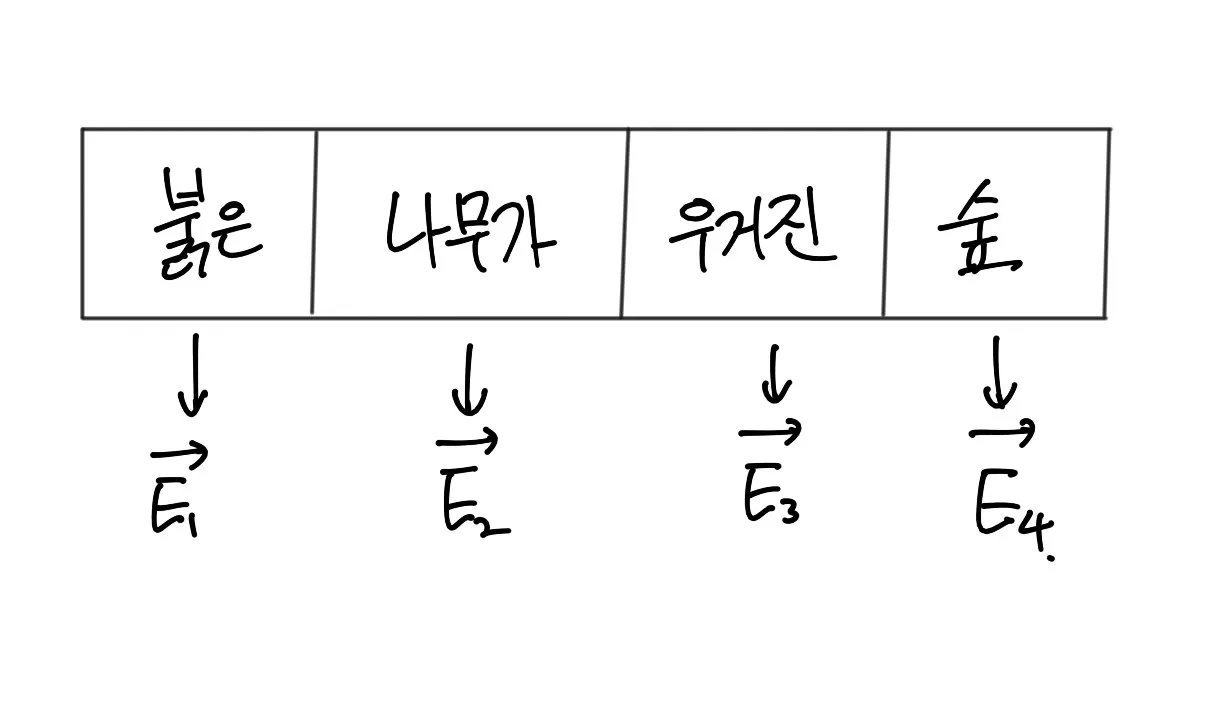
해당 논문에서는 Query, Key, Value라는 값을 만든다.
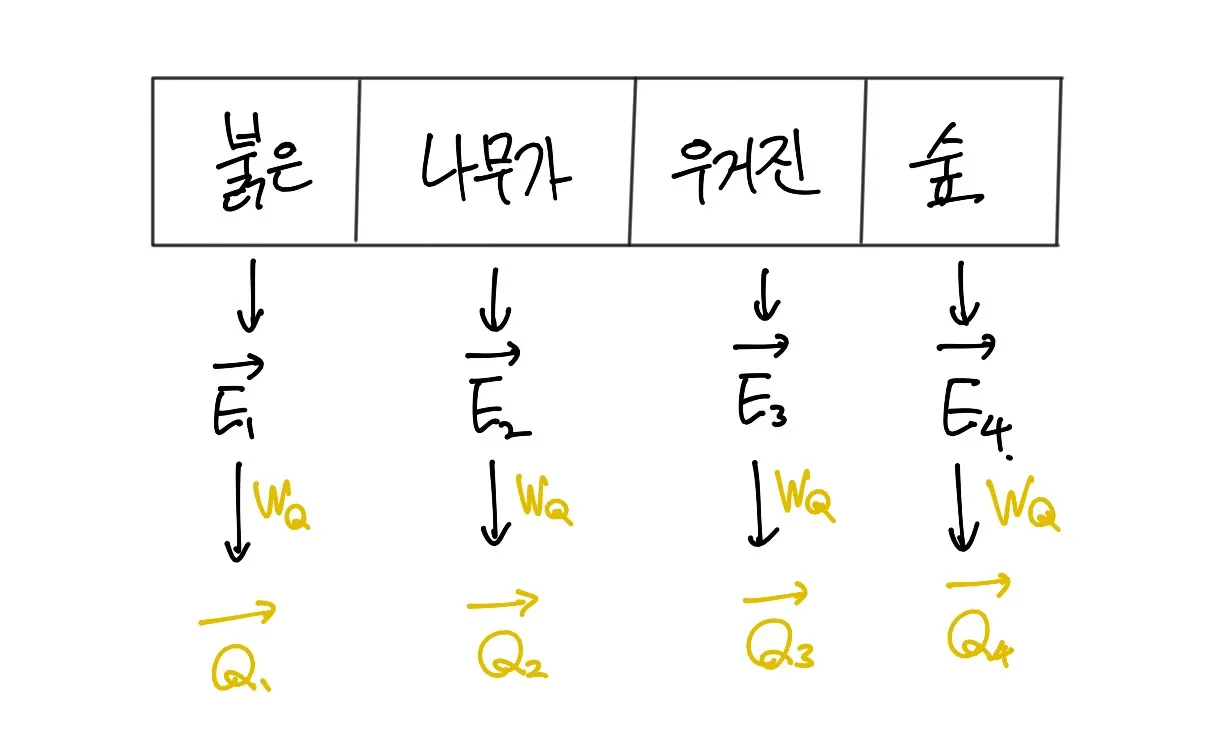
특정 단어에 대한 이전의 연결성(Dependency)를 물어보는 질의문(Query)벡터를 학습 가능한 파라미터인 WQ 를 통해 생성한다.
질의에 대한 답변(Key)벡터도 마찬가지로 모델내에서 학습 가능한 파라미터인 WK을 통해 생성하고 만들어진 두 벡터를 내적을 통해 값을 만든다.
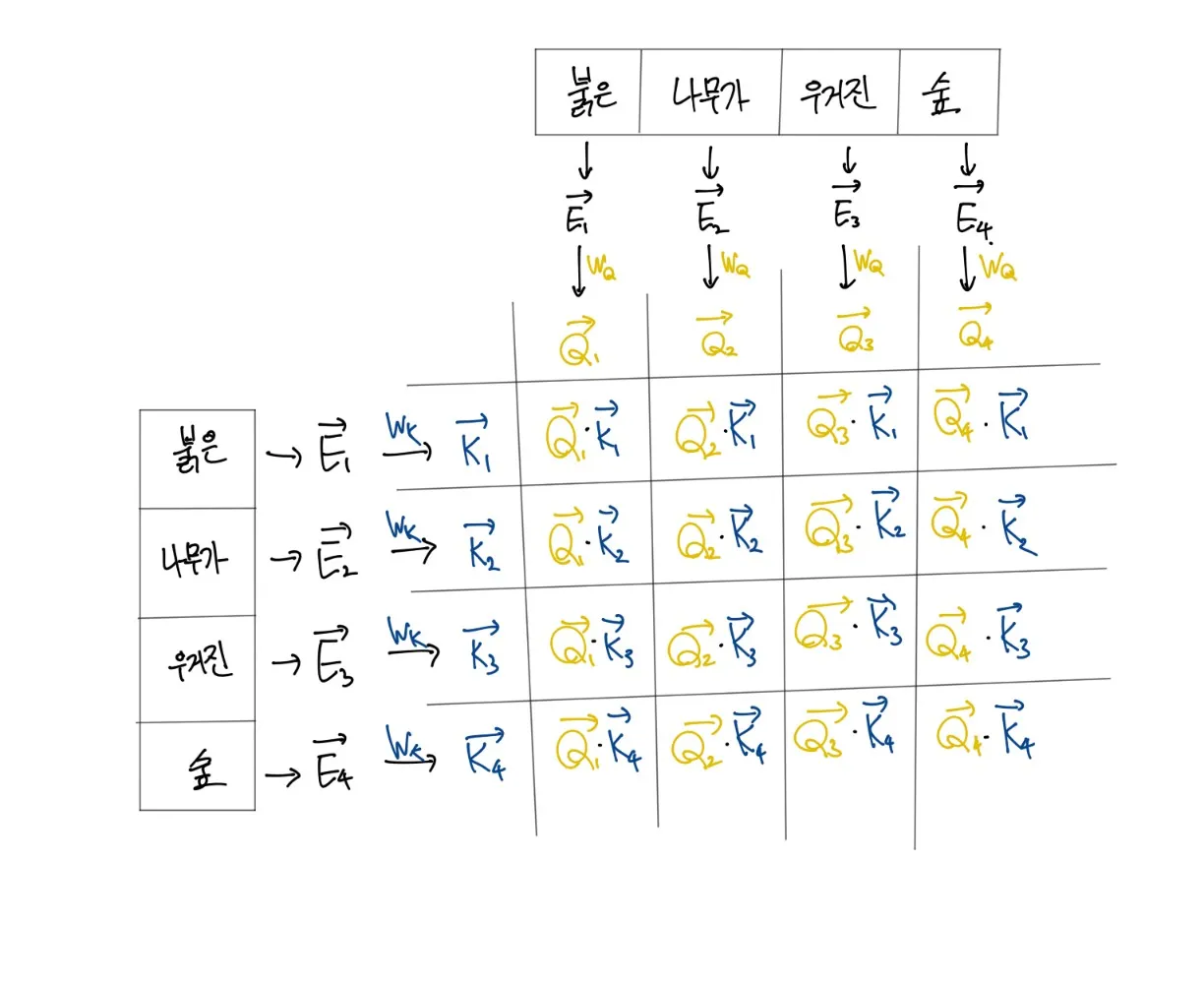
이렇게 만들어진 값은 어떠한 상수값을 가지게 되는데 의미적으로 생각하면 다음과 같다.
임의의 단어는 이전에 있던 단어들에 의한 수식을 받게되는데 이러한 단어들이 특정 정도(혹은 수치)를 내적을 통해 만들고 이를 softmax함수를 통해 수치를 통일화 하는 것이다.
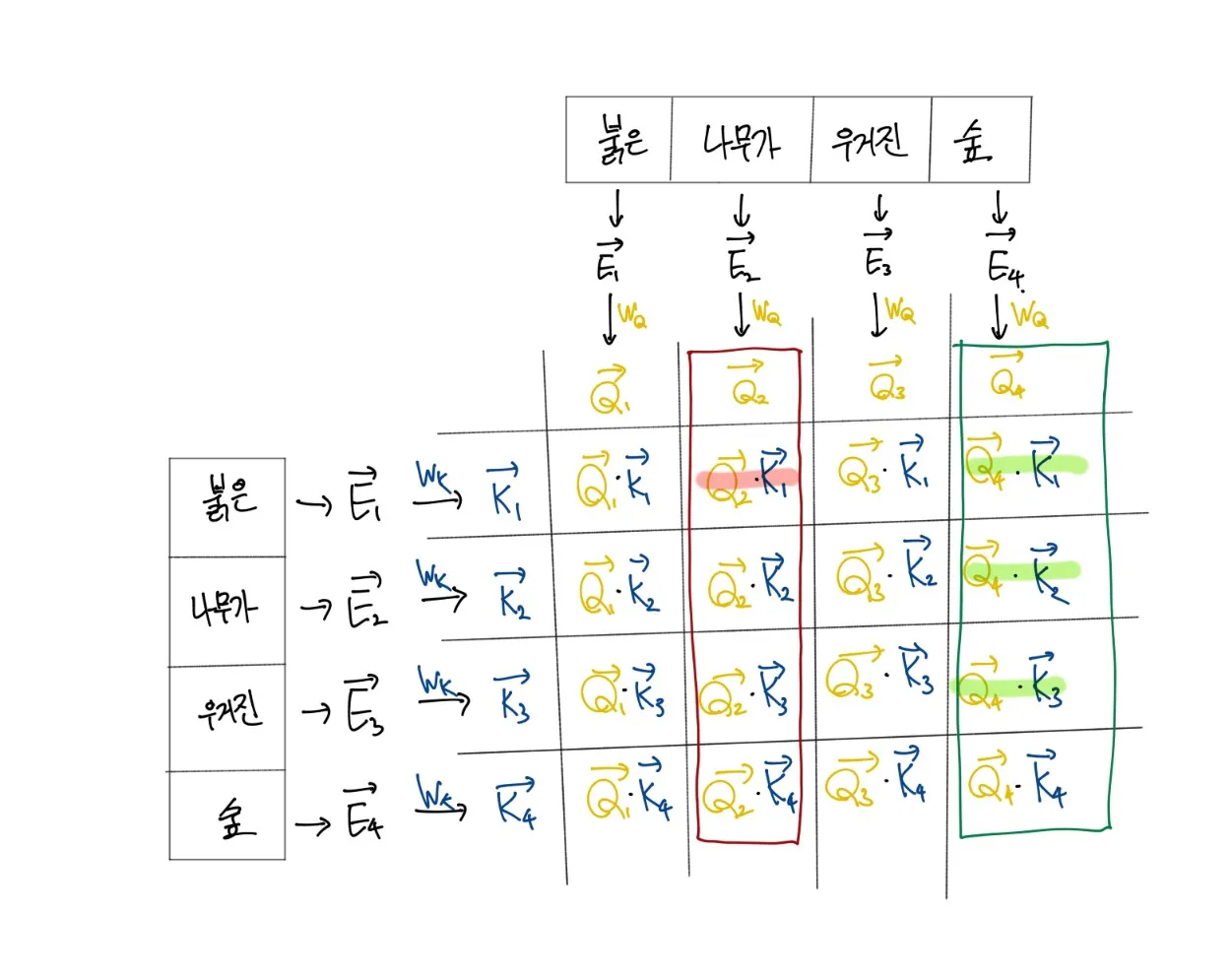
"나무가" 라는 단어에서는 "붉은" 이라는 단어에 대한 내적값이 가장 높을 것이고 "숲"이라는 단어는 이전에 있던 모든 단어들인 "붉은","나무가","우거진"들의 내적값들이 어떤 비율로 꾸며주고 있을 것이다.
다만 Sequence의 과정에서는 현재 단어보다 더 앞에 있는 단어를 학습하는 것을 막기 위해 내적값을 없애고 음의 무한대의 값을 주어 학습을 시키기도 하는데 이를 masking이라고도 한다.
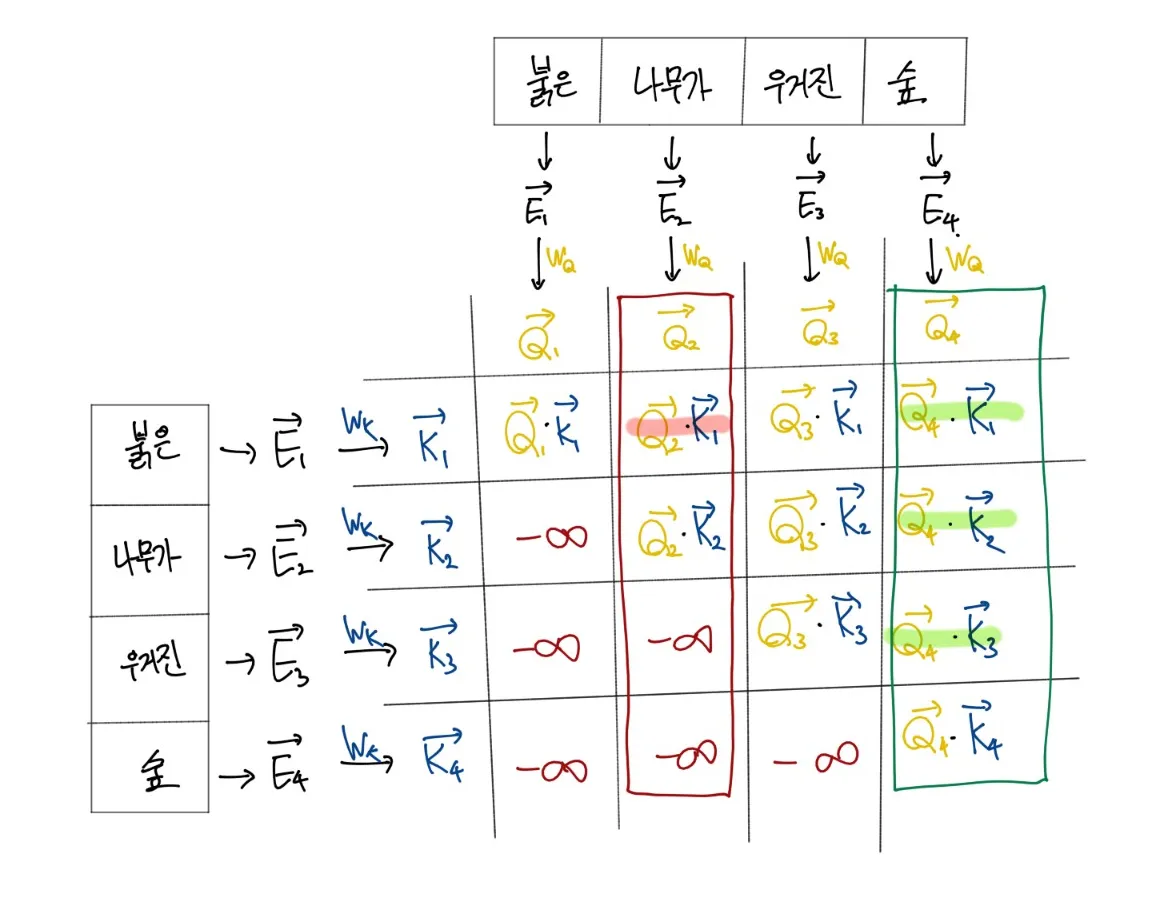
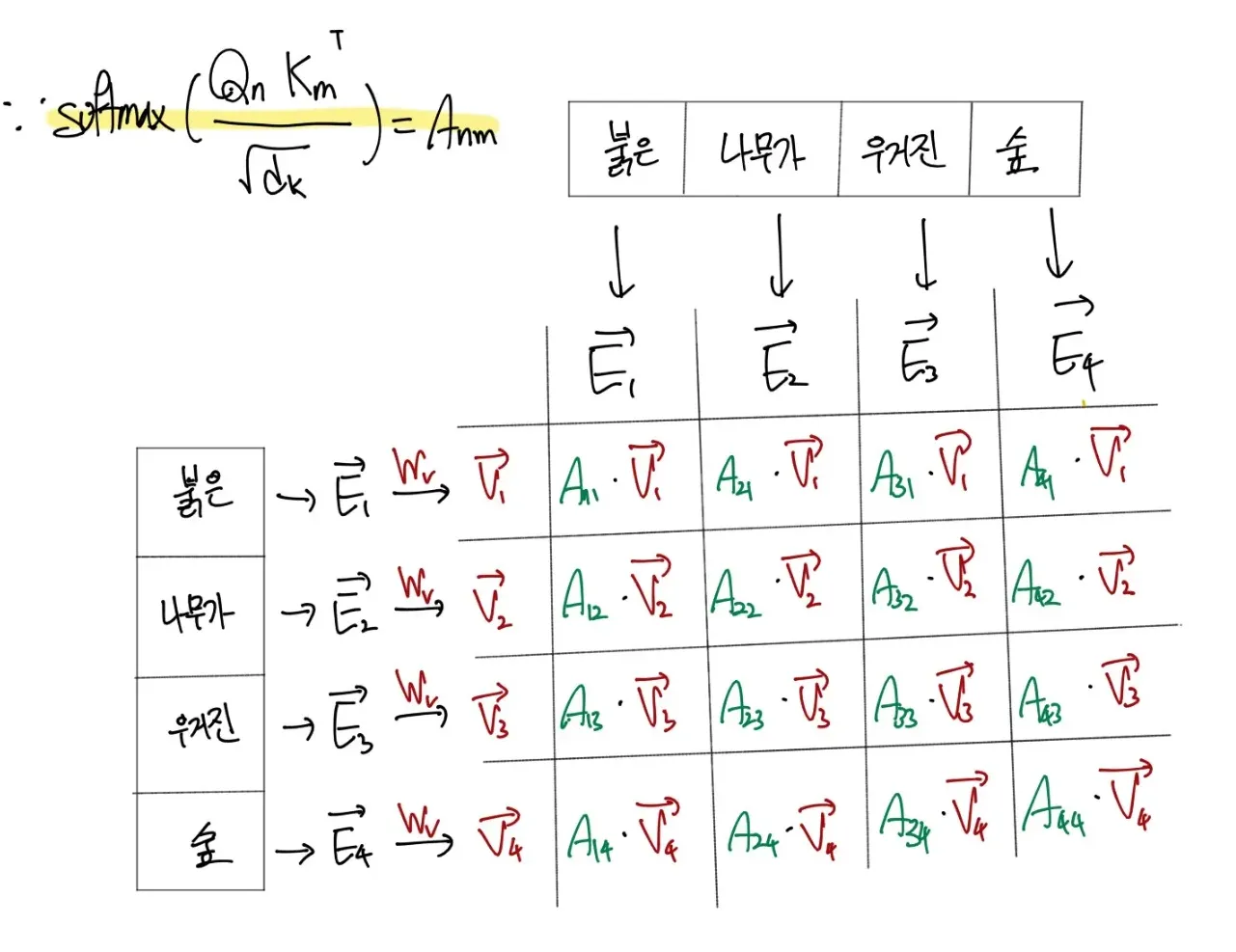
사진에서는 너무 수치화 하는 것이 귀찮아서 위에 softmax를 취한값을 A로 정의하고 표현했다.
이게 바로 논문에서 그냥 띡하고 던진 수식의 뜻이다.
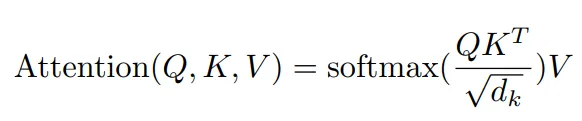
물론 로 나눈건 사진에는 없지만 이는 scaling을 위해서 적용한거니 그러려니하자.
이렇게 만들어진 값을 모두 더하면 기존 단어 벡터에서 이를 좀더 구체화 해주는 벡터(정확히는 벡터 변화량이라 말하는게 맞을거같다.)를 얻게 되는데 이를 더하면 한번 업데이트 된 값이다.
수식에서 벗어나서 뭔가 그림적으로 그려본다.
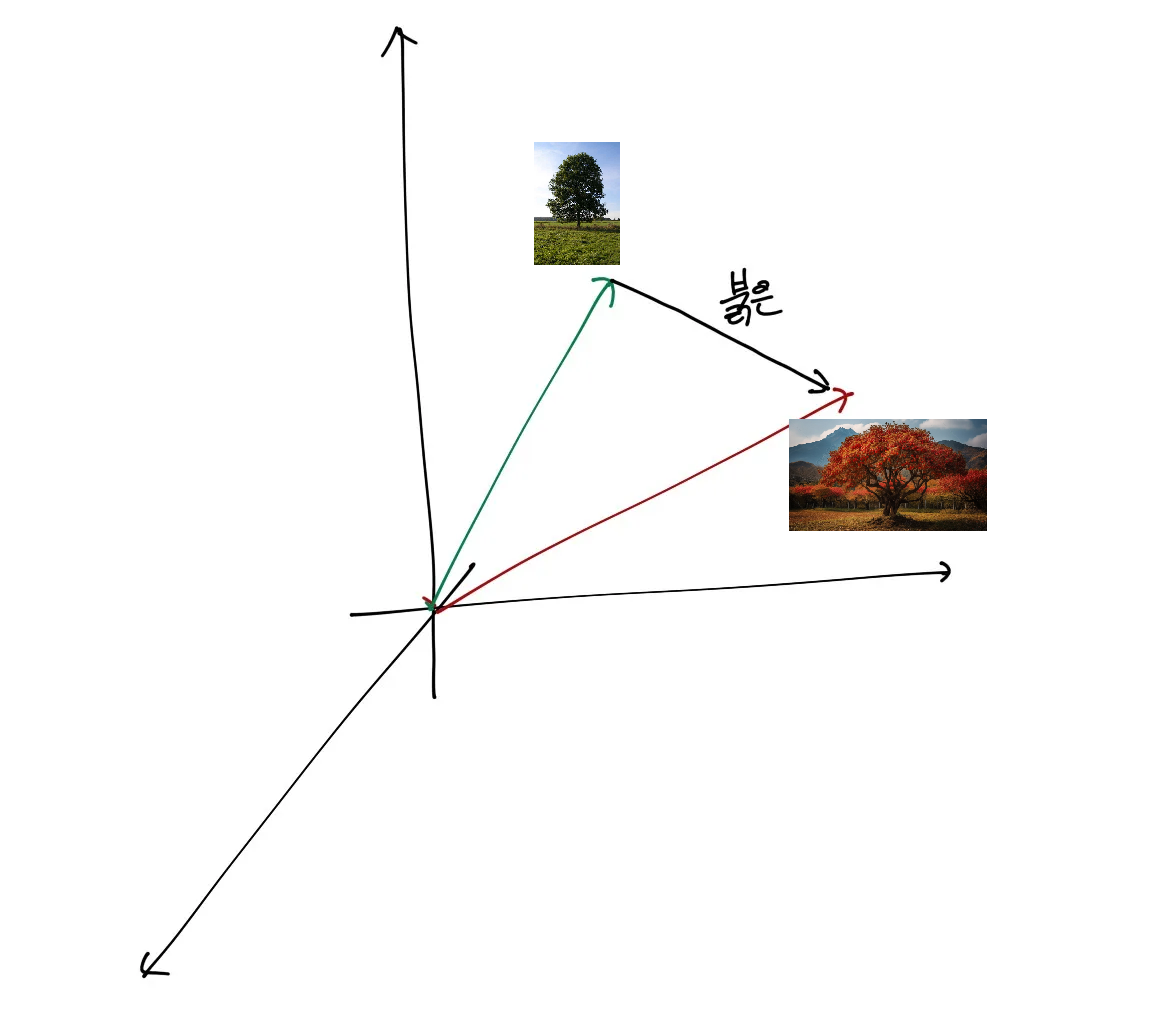
나무에 대한 임베딩 벡터가 있으면 해당 Transformer를 거치면 붉은 이라는 벡터 변화량이 추가되어서 붉은 나무로 임베딩이 좀더 이전 정보들을 반영하는식으로 업데이트를 하게 되는 것이다.
