
문제
민호는 다단계 조직을 이용하여 칫솔을 판매하고 있습니다. 판매원이 칫솔을 판매하면 그 이익이 피라미드 조직을 타고 조금씩 분배되는 형태의 판매망입니다. 어느정도 판매가 이루어진 후, 조직을 운영하던 민호는 조직 내 누가 얼마만큼의 이득을 가져갔는지가 궁금해졌습니다. 예를 들어, 민호가 운영하고 있는 다단계 칫솔 판매 조직이 아래 그림과 같다고 합시다.
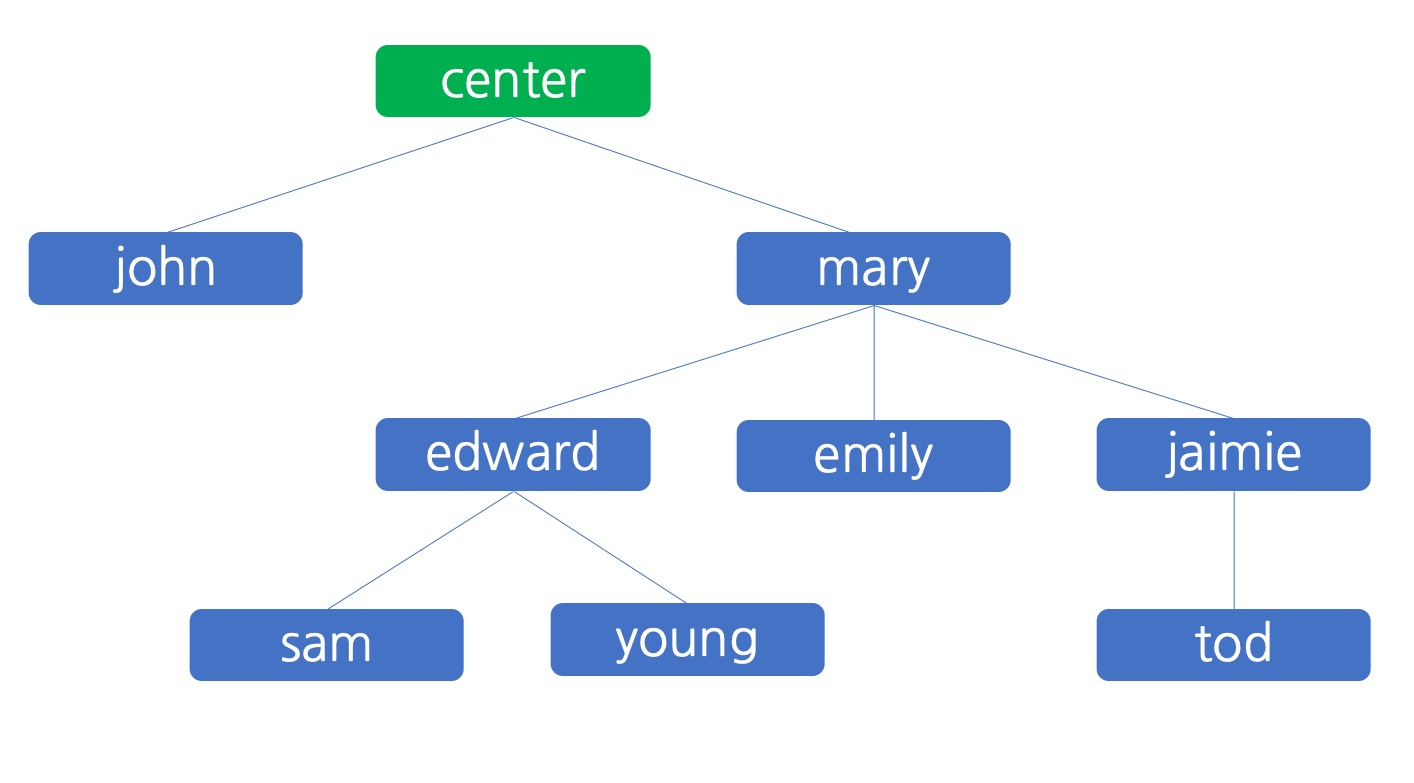
민호는 center이며, 파란색 네모는 여덟 명의 판매원을 표시한 것입니다. 각각은 자신을 조직에 참여시킨 추천인에 연결되어 피라미드 식의 구조를 이루고 있습니다. 조직의 이익 분배 규칙은 간단합니다. 모든 판매원은 칫솔의 판매에 의하여 발생하는 이익에서 10% 를 계산하여 자신을 조직에 참여시킨 추천인에게 배분하고 나머지는 자신이 가집니다. 모든 판매원은 자신이 칫솔 판매에서 발생한 이익 뿐만 아니라, 자신이 조직에 추천하여 가입시킨 판매원에게서 발생하는 이익의 10% 까지 자신에 이익이 됩니다. 자신에게 발생하는 이익 또한 마찬가지의 규칙으로 자신의 추천인에게 분배됩니다. 단, 10% 를 계산할 때에는 원 단위에서 절사하며, 10%를 계산한 금액이 1 원 미만인 경우에는 이득을 분배하지 않고 자신이 모두 가집니다.
각 판매원의 이름을 담은 배열 enroll, 각 판매원을 다단계 조직에 참여시킨 다른 판매원의 이름을 담은 배열 referral, 판매량 집계 데이터의 판매원 이름을 나열한 배열 seller, 판매량 집계 데이터의 판매 수량을 나열한 배열 amount가 매개변수로 주어질 때, 각 판매원이 득한 이익금을 나열한 배열을 return 하도록 solution 함수를 완성해주세요. 판매원에게 배분된 이익금의 총합을 계산하여(정수형으로), 입력으로 주어진 enroll에 이름이 포함된 순서에 따라 나열하면 됩니다.
제한
-
enroll의 길이는 1 이상 10,000 이하입니다.
- enroll에 민호의 이름은 없습니다. 따라서 enroll의 길이는 민호를 제외한 조직 구성원의 총 수입니다.
-
referral의 길이는 enroll의 길이와 같습니다.
- referral 내에서 i 번째에 있는 이름은 배열 enroll 내에서 i 번째에 있는 판매원을 조직에 참여시킨 사람의 이름입니다.
- 어느 누구의 추천도 없이 조직에 참여한 사람에 대해서는 referral 배열 내에 추천인의 이름이 기입되지 않고 “-“ 가 기입됩니다. 위 예제에서는 john 과 mary 가 이러한 예에 해당합니다.
- enroll 에 등장하는 이름은 조직에 참여한 순서에 따릅니다.
- 즉, 어느 판매원의 이름이 enroll 의 i 번째에 등장한다면, 이 판매원을 조직에 참여시킨 사람의 이름, 즉 referral 의 i 번째 원소는 이미 배열 enroll 의 j 번째 (j < i) 에 등장했음이 보장됩니다.
-
seller의 길이는 1 이상 100,000 이하입니다.
-
seller 내의 i 번째에 있는 이름은 i 번째 판매 집계 데이터가 어느 판매원에 의한 것인지를 나타냅니다.
-
seller 에는 같은 이름이 중복해서 들어있을 수 있습니다.
-
-
amount의 길이는 seller의 길이와 같습니다.
- amount 내의 i 번째에 있는 수는 i 번째 판매 집계 데이터의 판매량을 나타냅니다.
- 판매량의 범위, 즉 amount 의 원소들의 범위는 1 이상 100 이하인 자연수입니다.
-
칫솔 한 개를 판매하여 얻어지는 이익은 100 원으로 정해져 있습니다.
-
모든 조직 구성원들의 이름은 10 글자 이내의 영문 알파벳 소문자들로만 이루어져 있습니다.
입출력 예시
| enroll | referral | seller | amount | result |
|---|---|---|---|---|
| ["john", "mary", "edward", "sam", "emily", "jaimie", "tod", "young"] | ["-", "-", "mary", "edward", "mary", "mary", "jaimie", "edward"] | ["young", "john", "tod", "emily", "mary"] | [12, 4, 2, 5, 10] | [360, 958, 108, 0, 450, 18, 180, 1080] |
| ["john", "mary", "edward", "sam", "emily", "jaimie", "tod", "young"] | ["-", "-", "mary", "edward", "mary", "mary", "jaimie", "edward"] | ["sam", "emily", "jaimie", "edward"] | [2, 3, 5, 4] | [0, 110, 378, 180, 270, 450, 0, 0] |
풀이
2021 Dev-Matching: 웹 백엔드 개발자 상반기 문제에서 출제된 따끈따끈한 문제이다. 지문 설명도 길고 이미지도 많아서 문제를 읽기조차 싫게 만들지만 사실 난이도는 그렇게 어렵지 않다. 이전에 포스팅한 해당 포스트와 사실상 똑같은 문제다. 하나씩 살펴보도록 하자.
접근 방법 : DFS 알고리즘
수익 모델은 전형적인 다단계 모델을 취하고 있다. 가장 말단 사원에서 발생한 수익을 그 상위 등급에 위치한 사원에게 일정 퍼센트를 분할하는 구조이다. 이러한 다단계 구조는 DFS 알고리즘과 굉장히 유사하다. 말단 노드까지 내려간 후에 다시 그들의 부모 노드로 거슬러 올라오는 흐름이 동일하기 때문이다. 이와 관련된 자세한 설명은 위에 링크를 건 포스팅에서 확인할 수 있다. 따라서 해당 문제는 DFS 알고리즘을 이용하여 해결할 것 이다.
이때 자바스크립트의 고질적인 문제가 있다. DFS를 재귀호출 식으로 구현할 때 발생하는 스택 오버플로우 문제인데, 역시 이와 관련된 사항을 여기에 자세히 기술하였으니 관심이 있으면 참고하자. 해당 문제는 노드의 개수가 10000개 이하이기 때문에 사실 재귀적으로 풀어도 통과할 것 같지만, 안전하게 Iterative DFS 방식으로 풀도록 하자.
그래프 연결 리스트 생성
먼저 DFS 알고리즘을 돌리기위한 그래프 연결 리스트가 필요하다. 다단계 구조이니 사실상 순환이 없는 그래프이기 때문에 트리와도 같다. 트리의 root 노드는 문제 조건에 의해 항상 "minho"가 된다. 문제에서 주어진 enroll과 referral 배열을 가지고 tree를 구성하자.
자바스크립트의 객체(Object) 구조를 이용해서 구성할 것이다. key 값은 각 노드의 이름으로 두고, 이에 대한 value는 여려 명의 부하직원을 둘 수 있기 때문에 배열로 선언한다. 일단 enroll에 "minho"를 제외한 모든 노드들이 있기 때문에 이들의 이름을 key 값으로 하여 value를 넣어주고, referral을 돌면서 자신의 부모 노드 값을 찾아 현재 노드를 푸시하도록 하면 연결 리스트를 만들 수 있다.
// minho는 root 노드이면서 enroll에 따로 없기 때문에
// 먼저 선언과 동시에 다음과 같이 초기화한다.
const tree = { "minho" : [] };
// enroll은 개별 노드와 같다. 먼저 각각의 노드를 트리에 생성한다.
enroll.forEach(name => tree[name] = []);
for(const [idx, ref] of referral.entries()) {
// ref가 "-"일 경우 부모노드는 minho를 의미한다.
const target = ref === '-' ? "minho" : ref;
// enroll과 referral 은 크기가 동일하고
// 순서 역시 동일하기 때문에
// 현재 referral의 인덱스값으로 enroll을 참조하면
// ref를 부모로 갖는 현재 노드값을 구할 수 있다.
tree[target].push(enroll[idx]);
}판매 실적 리스트
위에서 언급한 다른 문제와 가장 크게 차이나는 부분이라고 할 수 있다. 먼저 누가 칫솔을 팔았는지에 대한 정보가 들어있는 seller 배열과 몇 개를 팔았는지에 대한 정보가 들어있는 amount 배열이 주어진다. 이 둘 역시 enroll과 referral 처럼 크기와 순서가 동일하다. 우리가 최종적으로 리턴해야 하는 값은 minho를 제외한 사원들의 판매실적이기 때문에 이 판매실적을 저장할 객체를 하나 또 만들어주자. 초기 판매실적은 seller에 등록된 사원들만 가지고 생성될 것 이다. 칫솔의 가격은 100원으로 고정되어 있으므로 다음과 같이 구현할 수 있다.
실제 코딩테스트에서 문제에서 제시된 조건을 빼먹고 지나가 애를 먹었는데, 다음의 조건을 주의해야 한다.
seller 에는 같은 이름이 중복해서 들어있을 수 있습니다.
사실 같은 이름이 중복되어 있다면 그냥 하나로 합쳐서 판매 실적을 내는게 일반적인 흐름일텐데, 알고리즘 문제로 탈바꿈하는 과정에서 나름의 변별력을 갖추기 위해서인지 약간 억지스러운 설정을 추가한 것이 아닌가 생각한다.
본론으로 돌아와서 이 조건에 유의해야 하는 이유는 만약 A라는 사람이 칫솔을 3개 팔고, 다음에 8개를 팔았다면 이를 한꺼번에 11개로 계산해서는 틀린 값이 나올 수 있다. 왜냐하면 판매 금액의 10%를 부모 노드에게 상납해야 하는데, 이 조건 중에 10%의 가격이 1원 미만이라면 이득을 분배하지 않는다라는 조항이 있다. 만약 이를 11개로 한꺼번에 계산해서 전달한다면 어느 시점에서 1원 미만의 이득을 제대로 걸러주지 못하는 경우가 생길 수 있다. 때문에 위에서 구성한 트리와 유사하게 sales 역시 이름을 key 값으로 두고, 그에 대한 value를 배열로 하여 발생한 모든 수익을 차례대로 푸시하여 계산할 것이다.
const sales = seller.reduce((acc, cur, idx) => {
// seller와 amount는 크기와 순서가 동일하므로
// seller의 인덱스는 amount의 인덱스와 동일
// 판매금액 = 판매개수 * 100
const cost = amount[idx] * 100;
// 이미 키 값이 있다면 푸시, 없으면 배열 형태로 판매금액 선언
acc[cur] ? acc[cur].push(cost) : acc[cur] = [ cost ];
return acc;
}, {});Iterative DFS
만약 아직 Iterative DFS가 무엇인지 잘 모른다면 여기를 참고하자. 먼저 stack은 선언과 동시에 root 노드인 ['minho', null] 로 초기화하자. 방문 여부를 체크 할 visit 역시 객체로 만들어 키 값으로 이름을 두고, value는 false로 지정하여 반복문을 돌 준비를 하도록 하자.
그 후엔 Iterative하게 DFS를 위한 반복문을 돌리면 된다. 더 이상 내려갈 지점이 없을 때 자신의 이득과 이에 대한 10%를 계산하여 부모 노드에게 전달해주도록 구현하자. 이때 위에서 자신의 이득에 대한 정보를 배열로 선언했기 때문에, 해당 배열을 모두 반복하여 이에 대한 계산을 수행해야 한다.
// [ 현재노드, 부모노드 ] 형태의 원소값을 취한다
const stack = [ ['minho', null] ];
// minho는 enroll에 포함되지 않으므로 초기값으로 지정하여 선언
const visit = { 'minho' : false };
// 초기 visit은 모두 false로 초기화
enroll.forEach(name => visit[name] = false);
while(stack.length) {
const [cur, parent] = stack.pop();
// 더 이상 내려갈 곳이 없는 노드의 영역
// 해당 영역에서 이득 분배 관련 계산을 실시
if(visit[cur]) {
// 현재 노드의 판매 수익이 있는 경우 이득 분배
// 민호의 수익은 문제에서 요구하지 않으므로 제외
if(sales[cur] && cur !== "minho") {
// 판매 실적이 2개 이상일 수 있으므로 (배열)
// 반복문을 돌며 개별로 이득 계산 후 분배
for(let i = 0; i < sales[cur].length; i++) {
// 1원 미만의 분배금액인 경우엔 분배 X
// 소수점은 포함하지 않으므로 버림
const income = sales[cur][i] < 10 ? 0 : sales[cur][i] * 0.1 >> 0;
// 부모노드에게 분배 금액 전달
// 부모노드 역시 여러 개의 분배 금액을 전달 받을 수 있으므로
// 배열 형태로 전달
sales[parent] ? sales[parent].push(income) : sales[parent] = [ income ];
// 분배금액을 제외한 소득을 자기 최종 소득으로 계산
sales[cur][i] -= income;
}
}
continue;
}
// 부모노드로 backtrack 하기 위해 첫 방문일 경우엔
// pop 한 원소를 다시 푸시하고 방문 체크
stack.push([cur, parent]);
visit[cur] = true;
// 연결된 노드를 탐방하여 방문하지 않았을 경우 stack에 푸시
for(const next of tree[cur]) {
if(!visit[next]) {
stack.push([next, cur]);
}
}
}정답 반환
DFS 알고리즘을 모두 수행하고 나면 sales에는 민호를 제외한 각 노드의 모든 소득 정보가 저장되어 있다. 이때 각 소득 정보는 아직 합산되지 않은 배열 형태일 것이므로, 이 값을 합산하여 리턴해야 한다. 또한 소득이 없는 경우는 0원으로 만들어 리턴해주어야 한다.
// 각 노드를 돌며 판매 실적이 있는지를 체크하고
// 있다면 배열 모든 값의 합, 없으면 0을 리턴
const answer = enroll.map(name => sales[name] ? sales.reduce((a, b) => a+b) : 0);
return answer;전체 코드
위에서 유사하다고 했던 문제를 이미 풀어보거나 DFS 에 익숙하다면 굉장히 쉽게 풀 수 있는 문제였던 것 같다. 다만 중복이 가능하다는 조건이 조금 까다롭게 작용했다. 앞에서도 이야기했지만, 본 시험 과정에서도 이 조건을 누락하고 문제에 접근하여 테스트는 통과했지만 채점 시 오답이 계속 나와 오랜 시간 헤매게 했던 원인이다. 또 다른 사람의 풀이를 보니 노멀하게 재귀적으로 접근해도 시간초과가 나지 않는 것을 확인했다. 본 풀이 방식은 반복문을 조금 쓸데없이 반복하는 경향이 있기 때문에 문제 자체는 통과하지만 사실 성능 상 최적화가 이루어지진 않았다는 점을 감안하자. 주석을 제외한 전체코드는 다음과 같다.
function solution (enroll, referral, seller, amount) {
const tree = { "minho" : [] };
enroll.forEach(name => tree[name] = []);
for(const [idx, ref] of referral.entries()) {
const target = ref === '-' ? "minho" : ref;
tree[target].push(enroll[idx]);
}
const sales = seller.reduce((acc, cur, idx) => {
const cost = amount[idx] * 100;
acc[cur] ? acc[cur].push(cost) : acc[cur] = [ cost ];
return acc;
}, {});
const stack = [ ["minho", null] ];
const visit = { "minho" : false };
enroll.forEach(name => visit[name] = false);
while(stack.length) {
const [cur, parent] = stack.pop();
if(visit[cur]) {
if(sales[cur] && cur !== "minho") {
for(let i = 0; i < sales[cur].length; i++) {
const income = sales[cur][i] < 10 ? 0 : sales[cur][i] * 0.1 >> 0;
sales[parent] ? sales[parent].push(income) : sales[parent] = [ income ];
sales[cur][i] -= income;
}
}
continue;
}
stack.push([cur, parent]);
visit[cur] = true;
for(const next of tree[cur]) {
if(!visit[next]) {
stack.push([next, cur]);
}
}
}
const answer = enroll.map(name => sales[name] ? sales[name].reduce((a, b) => a+b) : 0);
return answer;
}출처
