Adaptive RAG
이번에는 RAG(Adaptive Retrieval-Augmented Generation)의 구현을 다룰 것이다.
Adaptive RAG는 쿼리 분석과 능동적/자기 수정 RAG를 결합하여 다양한 데이터 소스에서 정보를 검색하고 생성하는 전략이다.
LangGraph를 사용하여 웹 검색과 자기 수정 RAG 간의 라우팅을 구현해보도록 한다.
- Create Index: 인덱스 생성 및 문서 로드
- LLMs: LLM을 사용한 쿼리 라우팅 및 문서 평가
- Web Search Tool: 웹 검색 도구 설정
- Construct the Graph: 그래프 상태 및 흐름 정의
- Compile Graph: 그래프 컴파일 및 워크플로우 구축
- Use Graph: 그래프 실행 및 결과 확인
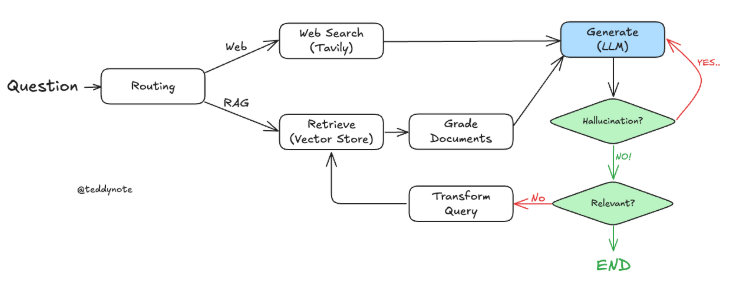
Adaptive RAG는 RAG의 전략으로, (1) 쿼리 분석과 (2) Self-Reflective RAG을 결합하는 것이다..
논문: Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity 에서는 쿼리 분석을 통해 다음과 같은 라우팅을 수행한다.
No RetrievalSingle-shot RAGIterative RAG
LangGraph를 사용하여 이를 구현.
이 구현에서는 다음과 같은 라우팅을 수행할 것이다.
- 웹 검색: 최신 이벤트와 관련된 질문에 사용
- 자기 수정 RAG: 인덱스와 관련된 질문에 사용
from dotenv import load_dotenv
load_dotenv()
True기본 PDF 기반 Retrieval Chain 생성
여기서는 PDF 문서를 기반으로 Retrieval Chain 을 생성. 가장 단순한 구조의 Retrieval Chain이다.
LangGraph 에서는 Retirever 와 Chain 을 따로 생성. 그래야 각 노드별로 세부 처리를 할 수 있다.
from rag.pdf import PDFRetrievalChain
# load pdf
pdf = PDFRetrievalChain(["docs/SPRI_AI_Brief_2023년12월호_F.pdf"]).create_chain()
# create retriever
pdf_retriever = pdf.retriever
# chain 생성
pdf_chain = pdf.chain['docs/SPRI_AI_Brief_2023년12월호_F.pdf']Query Routing & Document Evaluation
LLMs 단계에서 쿼리 라우팅과 문서평가를 수행한다. 이 과정은 Adaptive RAG 의 핵심으로서, 효율적인 정보 검색과 생성을 위해 필요하다.
- Query Routing: 사용자의 쿼리 분석하고 적절한 정보 소스로 라우팅한다. 이를 통해 쿼리의 목적에 맞는 최적의 검색 경로를 설정할 수 있다.
- Document Evaluation : 검색된 문서의 품질과 관련성을 평가하여 최종 생성에 사용될 문서를 선택한다. (LLMs의 성능을 극대화 하는데 필수적인 요소)
agent가 많아질수록 controllerbility가 떨어지기 때문에, 정형화된 아웃풋 출력을 반환하게 한다.
시스템 프롬프트에 어떠한 상황에따라서 아웃풋이 달라질지를 정의한다.
이 단계는 Adaptive RAG의 핵심 기능을 지원하며, 정확하고 신뢰할수 있는 제공을 목표로 한다.
from typing import Literal
from langchain_core.prompts import ChatPromptTemplate
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
MODEL_NAME = "gpt-4o-mini"
# 사용자 쿼리를 가장 관련성 높은 데이터 소스로 라우팅하는 데이터 모델
class RouteQuery(BaseModel):
"""Route a query to the most relevant data source"""
# 데이터소스 선택을 위한 리터럴 타입 필드
datasource: Literal["vectorstore", "web_search"] = Field(
...,
description = "Given a user question choose route it to web search or a vector database"
)
###
# LLM초기화 및 함수 호출을 통한 구조화된 출력 생성
llm = ChatOpenAI(model=MODEL_NAME, temperature=0.65)
structured_llm_router = llm.with_structured_output(RouteQuery)
###
# 시스템 메시지와 사용자 질문을 포함한 프롬프트 템플릿 생성
system = """You are an expert at routing a user question to a vectorstore or web search.
The vectorstore contains documents related to DEC 2023 AI Brief Report(SPRI) with Samsung Gause, Anthropic, etc.
Use the vectorstore for questions on these topics. Otherwise, use web-search."""
# Routing 을 위한 프롬프트 템플릿 생성
route_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}" )
]
)
# 프롬프트 템플릿을 사용하여 라우팅 함수 생성
question_router = route_prompt | structured_llm_router# 문서 검색이 필요한 질문
question_router.invoke(
{"question": "AI Brief 에서 삼성전자가 만든 생성형 AI 의 이름은?"}
)RouteQuery(datasource='vectorstore')# 웹 검색이 필요한 질문
result = question_router.invoke({"question": "판교에서 가장 맛있는 딤섬집 찾아줘"})
result.datasource
'web_search'Retrieval Grader(문서 관련성 평가)
기본 Agent는 검색된문서 전체를 평가하지만, AdaptiveRAG는 10개의 문서가 검색된다면, 각 문서 10개를 하나하나씩 관련성을 평가한다.
각각 문서를 관련이 있다면 yes, 없다면 no 로 평가하여 관련있는 문서만 선택할 수있다.
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# 문서 평가를 위한 데이터 모델 정의
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
# LLM 초기화 및 함수 호출을 통한 구조화된 출력 생성
llm = ChatOpenAI(model=MODEL_NAME, temperature=0)
structured_llm_grader = llm.with_structured_output(GradeDocuments)
# 시스템 메시지와 사용자 질문을 포함한 프롬프트 템플릿 생성
system = """You are a grader assessing relevance of a retrieved document to a user question. \n
If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n
It does not need to be a stringent test. The goal is to filter out erroneous retrievals. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question."""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Retrieved document: \n\n {document} \n\n User question: {question}"),
]
)
# 문서 검색결과 평가기 생성
retrieval_grader = grade_prompt | structured_llm_grader# 사용자 질문 설정
question = "삼성전자가 만든 생성형 AI 의 이름은?"
# 질문에 대한 관련 문서 검색
docs = pdf_retriever.invoke(question)# 검색된 문서의 내용 가져오기
retrieved_doc = docs[1].page_content
# 평가 결과 출력
print(retrieval_grader.invoke({"question": question, "document": retrieved_doc}))binary_score='yes'# 필터링 하는 코드 예시
filtered_docs = []
for doc in docs:
result = retrieval_grader.invoke(
{
"question": question,
"document": doc.page_content,
}
)
print(result)
if result.binary_score == "yes": # yes 일 경우 필터링에 추가
filtered_docs.append(doc)binary_score='yes'
binary_score='yes'
binary_score='yes'
binary_score='yes'
binary_score='no'
binary_score='no'
binary_score='yes'
binary_score='yes'
binary_score='no'
binary_score='no'filtered_docs[Document(id='f9e719d0-5f58-4d13-80dc-feacc7777c54', metadata={'source': 'docs/SPRI_AI_Brief_2023년12월호_F.pdf', 'file_path': 'docs/SPRI_AI_Brief_2023년12월호_F.pdf', 'page': 1, 'total_pages': 23, 'Author': 'dj', 'Creator': 'Hwp 2018 10.0.0.13462', 'Producer': 'Hancom PDF 1.3.0.542', 'CreationDate': "D:20231208132838+09'00'", 'ModDate': "D:20231208132838+09'00'", 'PDFVersion': '1.4'}, page_content='▹ 삼성전자, 자체 개발 생성 AI ‘삼성 가우스’ 공개 ···························································10\n▹ 구글, 앤스로픽에 20억 달러 투자로 생성 AI 협력 강화 ················································11\n▹ IDC, 2027년 AI 소프트웨어 매출 2,500억 달러 돌파 전망···········································12'),
Document(id='91a480cd-64aa-4786-b665-d552e23f74b1', metadata={'source': 'docs/SPRI_AI_Brief_2023년12월호_F.pdf', 'file_path': 'docs/SPRI_AI_Brief_2023년12월호_F.pdf', 'page': 12, 'total_pages': 23, 'Author': 'dj', 'Creator': 'Hwp 2018 10.0.0.13462', 'Producer': 'Hancom PDF 1.3.0.542', 'CreationDate': "D:20231208132838+09'00'", 'ModDate': "D:20231208132838+09'00'", 'PDFVersion': '1.4'}, page_content='SPRi AI Brief |\n2023-12월호\n삼성전자, 자체 개발 생성 AI ‘삼성 가우스’ 공개\nKEY Contents\nn 삼성전자가 온디바이스에서 작동 가능하며 언어, 코드, 이미지의 3개 모델로 구성된 자체 개발 생성\nAI 모델 ‘삼성 가우스’를 공개\nn 삼성전자는 삼성 가우스를 다양한 제품에 단계적으로 탑재할 계획으로, 온디바이스 작동이 가능한\n삼성 가우스는 외부로 사용자 정보가 유출될 위험이 없다는 장점을 보유\n£언어, 코드, 이미지의 3개 모델로 구성된 삼성 가우스, 온디바이스 작동 지원'),
Document(id='049ec52e-5c99-45e3-89fd-ef7acb333bf6', metadata={'source': 'docs/SPRI_AI_Brief_2023년12월호_F.pdf', 'file_path': 'docs/SPRI_AI_Brief_2023년12월호_F.pdf', 'page': 12, 'total_pages': 23, 'Author': 'dj', 'Creator': 'Hwp 2018 10.0.0.13462', 'Producer': 'Hancom PDF 1.3.0.542', 'CreationDate': "D:20231208132838+09'00'", 'ModDate': "D:20231208132838+09'00'", 'PDFVersion': '1.4'}, page_content='£언어, 코드, 이미지의 3개 모델로 구성된 삼성 가우스, 온디바이스 작동 지원\nn 삼성전자가 2023년 11월 8일 열린 ‘삼성 AI 포럼 2023’ 행사에서 자체 개발한 생성 AI 모델\n‘삼성 가우스’를 최초 공개\n∙ 정규분포 이론을 정립한 천재 수학자 가우스(Gauss)의 이름을 본뜬 삼성 가우스는 다양한 상황에\n최적화된 크기의 모델 선택이 가능\n∙ 삼성 가우스는 라이선스나 개인정보를 침해하지 않는 안전한 데이터를 통해 학습되었으며,\n온디바이스에서 작동하도록 설계되어 외부로 사용자의 정보가 유출되지 않는 장점을 보유'),
Document(id='0e88db09-170d-47c9-a3fa-4d1ed2fcbb49', metadata={'source': 'docs/SPRI_AI_Brief_2023년12월호_F.pdf', 'file_path': 'docs/SPRI_AI_Brief_2023년12월호_F.pdf', 'page': 12, 'total_pages': 23, 'Author': 'dj', 'Creator': 'Hwp 2018 10.0.0.13462', 'Producer': 'Hancom PDF 1.3.0.542', 'CreationDate': "D:20231208132838+09'00'", 'ModDate': "D:20231208132838+09'00'", 'PDFVersion': '1.4'}, page_content='어시스턴트를 적용한 구글 픽셀(Pixel)과 경쟁할 것으로 예상\n☞ 출처 : 삼성전자, ‘삼성 AI 포럼’서 자체 개발 생성형 AI ‘삼성 가우스’ 공개, 2023.11.08.\n삼성전자, ‘삼성 개발자 콘퍼런스 코리아 2023’ 개최, 2023.11.14.\nTechRepublic, Samsung Gauss: Samsung Research Reveals Generative AI, 2023.11.08.\n10'),
Document(id='cb5f1887-4e5b-4745-acb1-75182f53a5ca', metadata={'source': 'docs/SPRI_AI_Brief_2023년12월호_F.pdf', 'file_path': 'docs/SPRI_AI_Brief_2023년12월호_F.pdf', 'page': 12, 'total_pages': 23, 'Author': 'dj', 'Creator': 'Hwp 2018 10.0.0.13462', 'Producer': 'Hancom PDF 1.3.0.542', 'CreationDate': "D:20231208132838+09'00'", 'ModDate': "D:20231208132838+09'00'", 'PDFVersion': '1.4'}, page_content='처리를 지원\n∙ 코드 모델 기반의 AI 코딩 어시스턴트 ‘코드아이(code.i)’는 대화형 인터페이스로 서비스를 제공하며\n사내 소프트웨어 개발에 최적화\n∙ 이미지 모델은 창의적인 이미지를 생성하고 기존 이미지를 원하는 대로 바꿀 수 있도록 지원하며\n저해상도 이미지의 고해상도 전환도 지원\nn IT 전문지 테크리퍼블릭(TechRepublic)은 온디바이스 AI가 주요 기술 트렌드로 부상했다며,\n2024년부터 가우스를 탑재한 삼성 스마트폰이 메타의 라마(Llama)2를 탑재한 퀄컴 기기 및 구글'),
Document(id='57f090e4-a8b7-4128-a572-6ccc86462bd6', metadata={'source': 'docs/SPRI_AI_Brief_2023년12월호_F.pdf', 'file_path': 'docs/SPRI_AI_Brief_2023년12월호_F.pdf', 'page': 12, 'total_pages': 23, 'Author': 'dj', 'Creator': 'Hwp 2018 10.0.0.13462', 'Producer': 'Hancom PDF 1.3.0.542', 'CreationDate': "D:20231208132838+09'00'", 'ModDate': "D:20231208132838+09'00'", 'PDFVersion': '1.4'}, page_content='온디바이스에서 작동하도록 설계되어 외부로 사용자의 정보가 유출되지 않는 장점을 보유\n∙ 삼성전자는 삼성 가우스를 활용한 온디바이스 AI 기술도 소개했으며, 생성 AI 모델을 다양한 제품에\n단계적으로 탑재할 계획\nn 삼성 가우스는 △텍스트를 생성하는 언어모델 △코드를 생성하는 코드 모델 △이미지를 생성하는\n이미지 모델의 3개 모델로 구성\n∙ 언어 모델은 클라우드와 온디바이스 대상 다양한 모델로 구성되며, 메일 작성, 문서 요약, 번역 업무의\n처리를 지원')]답변 생성을 위한 RAG 체인 생성
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from yaml import safe_load
# 미리 만들어놓은 프롬프트 yaml파일 로드
with open("prompt/rag_withou_history.yaml", "r") as file:
prompt_config = safe_load(file)
prompt = PromptTemplate(
template=prompt_config.get("template", ""),
input_variables=prompt_config.get("input_variables", [])
)
# LLM 초기화
llm = ChatOpenAI(model_name=MODEL_NAME, temperature=0)
# 문서 포맷팅 함수
def format_docs(docs):
return "\n\n".join(
[
f'<document><content>{doc.page_content}</content><source>{doc.metadata["source"]}</source><page>{doc.metadata["page"]+1}</page></document>'
for doc in docs
]
)
# RAG 체인 생성
rag_chain = prompt | llm | StrOutputParser()# RAG 체인에 질문을 전달하여 답변 생성
generation = rag_chain.invoke({"context": format_docs(docs), "question": question})
print(generation)삼성전자가 만든 생성형 AI의 이름은 '삼성 가우스'입니다.
**Source**
- docs/SPRI_AI_Brief_2023년12월호_F.pdf (page 13)hallucination Checker 추가
# hallucination check를 위한 데이터 모델 정의
class GradeHallucination(BaseModel):
"""Binary score for hallucination present in generation answer."""
binary_score : str = Field(
description = "Answer is grounded in the facts, 'yes' or 'no'"
)
# 함수 호출을 통한 LLM 초기화
llm = ChatOpenAI(model = MODEL_NAME, temperature=0.65)
structured_llm_hallucination_grader = llm.with_structured_output(GradeHallucination)
# 프롬프트 설정
system = """You are a grader assessing whether and LLM generation is grounded in / supported by a set of retrieved facts. \n
Give a binary score 'yes' or 'no'. 'yes' means that the answer is grounded in / supported by the set of facts."""
# 프롬프트 템플릿 생성
hallucination_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Set of Facts \n\n {documents} \n\n LLMgeneration : {generation}")
]
)
# 환각 평가기 생성
hallucination_grader = hallucination_prompt | structured_llm_hallucination_grader생성한 hallucination_grader 를 사용하여 생성된 답변의 환각 여부를 평가한다.
# 평가기를 사용하여 생성된 답변의 환각 여부 평가
hallucination_grader.invoke({"documents" : format_docs(docs), "generation" : generation})GradeHallucination(binary_score='yes')class GradeAnswer(BaseModel):
"""Binary scoring to evaluate the appropriateness of answers to questinos"""
binary_score : str = Field(
description = "Indicate 'yes' or 'no' whether the answer solves the question"
)
# 함수 호출을 통한 LLM 초기화
llm = ChatOpenAI(model = MODEL_NAME, temperature=0.65)
structured_llm_answer_grader = llm.with_structured_output(GradeAnswer)
system= """you are a grader assessing whether an answer addresses / resolves a question \n
Give a binary score 'yes' or 'no'. 'Yes' means that the answer resolves the question"""
answer_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "User Question : {question} \n\n LLM generation : {generation}")
]
)
# 답변 평가기 생성
answer_grader = answer_prompt | structured_llm_answer_graderanswer_grader.invoke({"question": question, "generation": generation})GradeAnswer(binary_score='yes')쿼리 재작성 (Query Rewrite)
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# LLM 초기화
llm = ChatOpenAI(model = MODEL_NAME, temperature=0.65)
# Query Rewriter 프롬프트 정의
system ="""You a question re-writer that converts an input question to a better version that is optimized \n
for vectorstore retrieval. Look at the input and try to reason about the underlying semantic intent / meaning."""
# Query_write_promp
rewrite_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "User Question : {question}")
]
)
# Query Rewriter 생성
query_rewriter = rewrite_prompt | llm | StrOutputParser()생성한 query_rewriter 를 사용하여 쿼리를 재작성한다.
# 질문 재작성기에 질문을 전달하여 개선된 질문 생성
query_rewriter.invoke({"question": question})'삼성전자가 개발한 생성형 AI의 공식 명칭은 무엇인가요?'웹 검색 도구
웹 검색 도구는 Adaptive RAG의 중요한 구성 요소로, 최신 정보를 검색하는 데 사용된다. 이 도구는 사용자가 최신 이벤트와 관련된 질문에 대해 신속하고 정확한 답변을 얻을 수 있도록 지원한다.
- 설정: 웹 검색 도구를 설정하여 최신 정보를 검색할 수 있도록 준비
- 검색 수행: 사용자의 쿼리를 기반으로 웹에서 관련 정보를 검색
- 결과 분석: 검색된 결과를 분석하여 사용자의 질문에 가장 적합한 정보를 제공
from langchain_teddynote.tools.tavily import TavilySearch
# 웹 검색 도구 생성
web_search_tool = TavilySearch(max_results=3)웹 검색 도구를 실행하여 결과를 확인한다.
# 웹 검색 도구 호출
result = web_search_tool.search("ruah0807 아이디를가진 github 프로필 주소를 알려주세요")
print(result)[{'title': 'ruah0807 (Ruah Kim) - GitHub', 'url': 'https://github.com/ruah0807/', 'content': '개발이란 얼마나 멋진것인가 ! ruah0807 has 26 repositories available. Follow their code on GitHub.', 'score': 0.4977301, 'raw_content': "Navigation Menu\nSearch code, repositories, users, issues, pull requests...\n\n Provide feedback\n \nWe read every piece of feedback, and take your input very seriously.\n\n Saved searches\n \nUse saved searches to filter your results more quickly\n\n To see all available qualifiers, see our documentation.\n \n\n\n\n\n\n Ruah Kim\n \n\n ruah0807\n\n \n\nAchievements\nAchievements\nOrganizations\n\n Block or report ruah0807\n \n\n Prevent this user from interacting with your repositories and sending you notifications.\n Learn more about blocking users.\n \n\n You must be logged in to block users.\n \n\n Contact GitHub support about this user’s behavior.\n Learn more about reporting abuse.\n \nHi there, I'm Ruah Kim! 👋\nAbout Me :\nTech Stack:\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nContact 📞\n\n\n\n\n\n\n\n\n\n\n Pinned\n \n\n\n\n Loading\n\n\n\nFooter\nFooter navigation\n"}, {'title': '계정 및 프로필 설명서 - GitHub Docs', 'url': 'https://docs.github.com/ko/account-and-profile', 'content': '프로필 추가 정보 관리. GitHub 프로필에 README를 추가하여 다른 사용자에게 자신에 대해 알릴 수 있습니다. ... 웹 기반 작업을 수행할 때 메일 주소를 비공개로 유지하기로 선택한 경우 개인 메일 주소를 노출할 수도 있는 명령줄 푸시를 차단하도록 선택할 수도', 'score': 0.16210158, 'raw_content': '계정 및 프로필 설명서 \n개인 계정의 설정을 조정하고 프로필 페이지를 맞춤형으로 설정하고 받은 알림을 관리하여 GitHub를 가장 적합하게 만듭니다.\n여기에서 시작\nGitHub 사용자 이름 변경\nGitHub에서 계정의 사용자명을 변경할 수 있습니다.\n프로필 추가 정보 관리\nGitHub 프로필에 README를 추가하여 다른 사용자에게 자신에 대해 알릴 수 있습니다.\n알림 정보\n알림은 구독한 GitHub에서의 활동에 대한 업데이트를 제공합니다. 알림 받은 편지함을 사용하여 업데이트를 사용자 지정, 심사 및 관리할 수 있습니다.\n인기 사이트\n커밋 메일 주소 설정\nGitHub 및 컴퓨터에서 커밋을 작성하는 데 사용되는 이메일 주소를 설정할 수 있습니다.\n개인 리포지토리에 협력자 초대\n개인 리포지토리에 협력자가 되도록 사용자를 초대할 수 있습니다.\n알림 구성\n알림을 받을 GitHub의 작업 유형과 이러한 업데이트를 전달하는 방법을 선택합니다.\n새로운 기능\n가이드\n내 기여가 내 프로필에 표시되지 않는 이유는 무엇인가요?\n기여 그래프에서 기여가 누락될 수 있는 일반적인 이유를 알아봅니다.\n받은 편지함에서 알림 관리\n받은 편지함을 사용하여 메일 및 모바일에서 알림을 빠르게 심사하고 동기화합니다.\n개인 메일 주소를 노출하는 명령줄 푸시 차단\n웹 기반 작업을 수행할 때 메일 주소를 비공개로 유지하기로 선택한 경우 개인 메일 주소를 노출할 수도 있는 명령줄 푸시를 차단하도록 선택할 수도 있습니다.\n모든 계정 및 프로필 문서\nGitHub에서 개인 계정 설정 및 관리\nGitHub 프로필 설정 및 관리\nGitHub의 구독 및 알림 관리\n도움말 및 지원\xa0\n필요한 항목을 찾으셨나요?\n계속 도움이 필요하세요?\nLegal\n'}, {'title': 'GitHub 프로필 시작하기', 'url': 'https://mean71.github.io/github/GitHub_Profile/', 'content': 'GitHub 프로필 시작하기 1. github 프로필 생성. New repositorie 생성 Owner와 Repository name 을 자신의 GitHub_User_ID로 기입 "Add a README file" 옵션을 선택 (or 생성 후 그냥 readme.md 파일 작성)', 'score': 0.13675845, 'raw_content': None}]# 웹 검색 첫번째 결과 확인
print(result[0])
{'title': 'ruah0807 (Ruah Kim) - GitHub', 'url': 'https://github.com/ruah0807/', 'content': '개발이란 얼마나 멋진것인가 ! ruah0807 has 26 repositories available. Follow their code on GitHub.', 'score': 0.4977301, 'raw_content': "Navigation Menu\nSearch code, repositories, users, issues, pull requests...\n\n Provide feedback\n \nWe read every piece of feedback, and take your input very seriously.\n\n Saved searches\n \nUse saved searches to filter your results more quickly\n\n To see all available qualifiers, see our documentation.\n \n\n\n\n\n\n Ruah Kim\n \n\n ruah0807\n\n \n\nAchievements\nAchievements\nOrganizations\n\n Block or report ruah0807\n \n\n Prevent this user from interacting with your repositories and sending you notifications.\n Learn more about blocking users.\n \n\n You must be logged in to block users.\n \n\n Contact GitHub support about this user’s behavior.\n Learn more about reporting abuse.\n \nHi there, I'm Ruah Kim! 👋\nAbout Me :\nTech Stack:\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nContact 📞\n\n\n\n\n\n\n\n\n\n\n Pinned\n \n\n\n\n Loading\n\n\n\nFooter\nFooter navigation\n"}그래프 구성
그래프 상태 정의
from typing import List, TypedDict, Annotated
# 그래프 상태 정의
class GraphState(TypedDict):
"""
그래프 상태를 나타내는 데이터 모델
Attributes:
question: 사용자 질문
generation: 생성된 답변
documents: 검색된 문서
"""
question : Annotated[str, "The user question"]
generation : Annotated[str, "The LLM generation"]
documents : Annotated[List[str], "The retrieved documents"]
그래프 흐름 정의
그래프 흐름을 정의하여 Adaptive RAG 작동 방식을 명확히한다. 이 단계에서는 그래프의 상태와 전환을 설정하여 쿼리 처리의 효율성을 높인다.
- 상태 정의 : 그래프의 각 상태를 명확히 정의하여 쿼리의 진행 상황을 추적.
- 전환 설정 : 상태 간의 전환을 설정하여 쿼리가 적절한 경로를 따라 진행.
- 흐름 최적화 : 그래프의 흐름을 최적화하여 정보 검색과 생성의 정확성을 향상.
Node 정의
from langchain_core. documents import Document
# 문서 검색 노드
def retrieve(state):
print("\nRETRIEVE >>>")
question = state["question"]
# 문서 검색
documents = pdf_retriever.invoke(question)
return {"documents" : documents}
# 답변 생성노드
def generate(state):
print("\nGENERATE >>>")
# 질문과 문서 검색 결과 가져오기
question = state["questinon"]
documents = state["documents"]
# 답변생성
generation = rag_chain.invoke({"context" : format_docs(documents), "question" : question})
return {"generation" : generation}
# 문서 관련성 평가
def grade_documents(state):
print("\nGRADE DOCUMENTS >>>")
question = state["question"]
documents = state["documents"]
# 문서 관련성 평가
filtered_docs = []
for doc in documents:
score = retrieval_grader.invoke(
{
"question" : question,
"documents" : doc.page_content
}
)
if score.binary_score == "yes":
print("--- Document Relevant Grading : YES")
filtered_docs.append(doc)
else:
print("--- Document Relevant Grading : NO")
continue
return {"documents" : filtered_docs}
# 질문 재작성
def transform_query(state):
print("\nTRANSFORM QUERY >>>")
question = state["question"]
# 질문 재작
better_question = query_rewriter.invoke({"question": question})
return {"question" : better_question}
# 웹 검색 노드
def web_search(state):
print("\nWEB SEARCH >>>")
# 질문과 문서 검색 결과 가져오기
question = state["question"]
# 웹 검색
web_results = web_search_tool.invoke({"query": question})
web_results_docs = [
Document(
page_content = web_result["content"],
metadata = {"source": web_result["url"]}
)
for web_result in web_results
]
return {"documents" : web_results_docs}
추가 노드 정의
# 질문 라우팅 노드
def route_question(state):
print("\nROUTE QUESTION >>>")
# 질문 가져오기
question = state["question"]
# 질문 라우팅
source = question_router.invoke({"question": question})
# 질문 라우팅 결과에 따른 노드 라우팅
if source.datasource == "web_search":
print("\nROUTE QUESTION TO WEB SEARCH >>>")
return "web_search"
elif source.datasource == "vectorstore":
print("\nROUTE QUESTION TO VECTORSTORE >>>")
return "vectorstore"
# 문서 관련성 평가 노드
def decide_to_generate(state):
print("\nDECISION TO GENERATE >>>")
# 문서 검색 결과 가져오기
filtered_documents = state["documents"]
if not filtered_documents:
# 모든 문서가 관련성 없는 경우 질문 재작성
print(
"\nDECISION: ALL DOCUMENTS ARE NOT RELEVANT TO QUESTION, TRANSFORM QUERY >>>"
)
return "transform_query"
else:
# 관련성 있는 문서가 있는 경우 답변 생성
print("\nDECISION: GENERATE >>>")
return "generate"
def hallucination_check(state):
print("\nCHECK HALLUCINATIONS >>>")
# 질문과 문서 검색 결과 가져오기
question = state["question"]
documents = state["documents"]
generation = state["generation"]
# 환각 평가
score = hallucination_grader.invoke(
{"documents": documents, "generation": generation}
)
grade = score.binary_score
# Hallucination 여부 확인
if grade == "yes":
print("\nDECISION: GENERATION IS GROUNDED IN DOCUMENTS >>>")
# 답변의 관련성(Relevance) 평가
print("\nGRADE GENERATED ANSWER vs QUESTION >>>")
score = answer_grader.invoke({"question": question, "generation": generation})
grade = score.binary_score
# 관련성 평가 결과에 따른 처리
if grade == "yes":
print("\nDECISION: GENERATED ANSWER ADDRESSES QUESTION >>>")
return "relevant"
else:
print("\nDECISION: GENERATED ANSWER DOES NOT ADDRESS QUESTION >>>")
return "not relevant"
else:
print("\nDECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY >>>")
return "hallucination"각각의 노드마다 llm이 들어가기때문에, 지연시간이 오래 걸릴 수 있는 단점이 있다.
따라서, 요즘의 추새는 과정을 보여주는 UX 방식을 사용한다.
그래프 컴파일
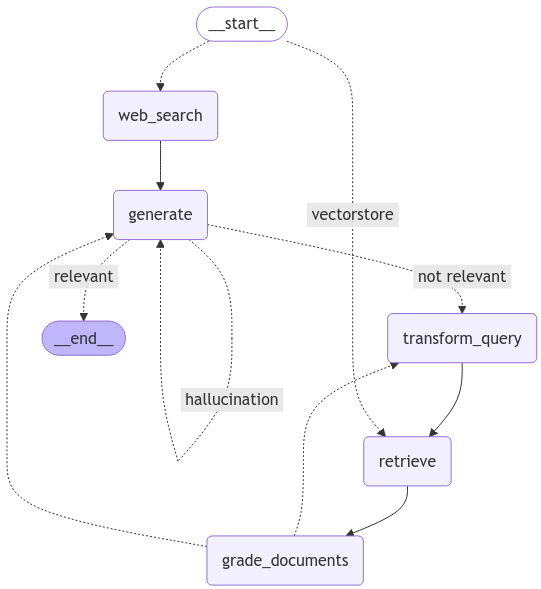
그래프 컴파일 단계에서는 Adaptive RAG의 워크플로우를 구축하고 실행 가능한 상태로 만든다. 이 과정은 그래프의 각 노드와 엣지를 연결하여 쿼리 처리의 전체 흐름을 정의한다.
- 노드 정의: 각 노드를 정의하여 그래프의 상태와 전환을 명확히 한다.
- 엣지 설정: 노드 간의 엣지를 설정하여 쿼리가 적절한 경로를 따라 진행되도록 한다.
- 워크플로우 구축: 그래프의 전체 흐름을 구축하여 정보 검색과 생성의 효율성을 극대화한다.
from langgraph.graph import END, StateGraph, START
from langgraph.checkpoint.memory import MemorySaver
# 그래프 상태 초기화
workflow = StateGraph(GraphState)
# 노드 정의
workflow.add_node("web_search", web_search) # 웹 검색
workflow.add_node("retrieve", retrieve) # 문서 검색
workflow.add_node("grade_documents", grade_documents) # 문서 평가
workflow.add_node("generate", generate) # 답변 생성
workflow.add_node("transform_query", transform_query) # 쿼리 변환
# 그래프 빌드
workflow.add_conditional_edges(
START,
route_question,
{
"web_search": "web_search", # 웹 검색으로 라우팅
"vectorstore": "retrieve", # 벡터스토어로 라우팅
},
)
workflow.add_edge("web_search", "generate") # 웹 검색 후 답변 생성
workflow.add_edge("retrieve", "grade_documents") # 문서 검색 후 평가
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query", # 쿼리 변환 필요
"generate": "generate", # 답변 생성 가능
},
)
workflow.add_edge("transform_query", "retrieve") # 쿼리 변환 후 문서 검색
workflow.add_conditional_edges(
"generate",
hallucination_check,
{
"hallucination": "generate", # Hallucination 발생 시 재생성
"relevant": END, # 답변의 관련성 여부 통과
"not relevant": "transform_query", # 답변의 관련성 여부 통과 실패 시 쿼리 변환
},
)
# 그래프 컴파일
app = workflow.compile(checkpointer=MemorySaver())from IPython.display import Image, display
# 그래프 시각화
img = Image(app.get_graph(xray=True).draw_mermaid_png())
with open("adaptive_rag_graph.png", "wb") as f:
f.write(img.data)
display(Image("adaptive_rag_graph.png"))