Graph RAG
테디노트영상에서 GraphRAG 의 신! 정이태님이 하신 강의를 정리 해놓은 블로그이다.
source : https://www.youtube.com/watch?v=zHN2jDZHvI0&t=4837s
GraphRAG 트랜드 및 현주소
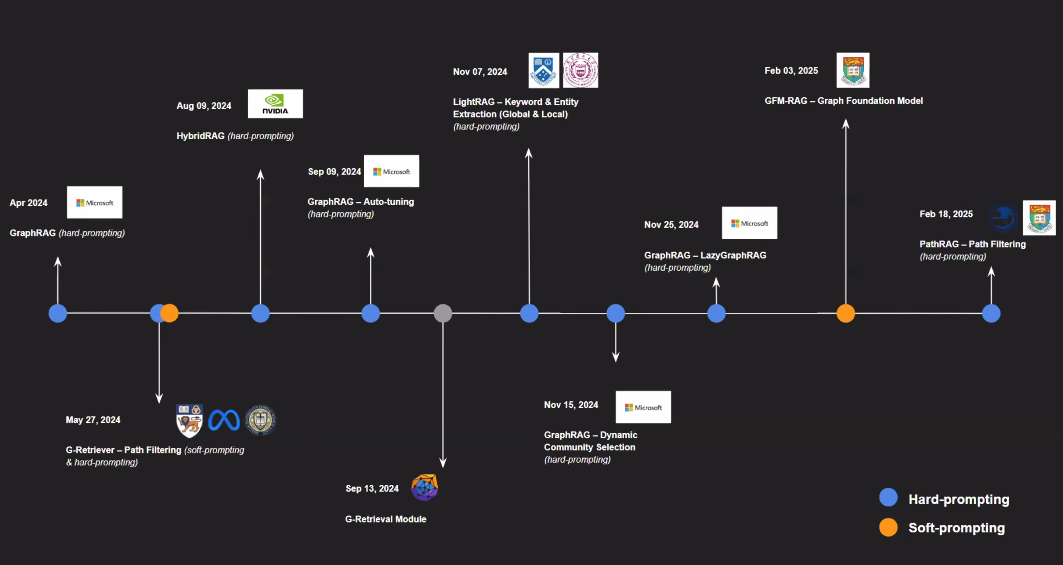
GraphRAG의 발전은 다양한 기업과 연구기관의 주도로 이루어지고 있으며, 주로 Hard-prompting과 Soft-prompting 방식으로 나뉘어 전개되고 있다. 아래는 발표된 기술들을 중심으로 시간 순으로 정리한 내용이다.
GraphRAG 연구 흐름
-
2024년 4월 – Microsoft
최초의 GraphRAG 구조가 발표되었으며, hard prompting 기반의 정형화된 방식으로 질의 응답을 처리한다. -
2024년 5월 27일 – Oxford, Meta, CMU
G-Retriever – Path Filtering이 발표되었으며, soft prompting과 hard prompting을 병행하여 사용자 질의에 맞는 경로를 필터링하는 방식 -
2024년 8월 9일 – NVIDIA
HybridRAG가 발표되었으며, 전통적인 RAG 구조와 그래프 기반 접근을 결합한 방식 -
2024년 9월 9일 – Microsoft
GraphRAG Auto-tuning 기술이 발표되었으며, hard prompting 기반의 프롬프트 최적화를 자동으로 수행 -
2024년 9월 13일 – G-Retrieval Module
그래프 기반 정보 검색을 위한 전용 모듈이 발표되었으며, 다양한 GraphRAG 구조와의 통합을 전제로 한다. -
2024년 11월 7일 – KAIST, 고려대학교 등
LightRAG이 발표되었으며, 글로벌 및 로컬 수준의 키워드 및 엔티티 추출 기능을 강화한 방식이다. -
2024년 11월 15일 – Microsoft
GraphRAG – Dynamic Community Selection 기술이 발표되었으며, 사용자 질의에 따라 관련 커뮤니티(서브그래프)를 동적으로 선택한다. -
2024년 11월 25일 – Microsoft
LazyGraphRAG이 발표되었으며, 필요 시점에만 관련 서브그래프를 로딩하는 지연 처리 방식이 적용된다. -
2025년 2월 3일 – 홍콩대학교
GFM-RAG (Graph Foundation Model)이 발표되었으며, 범용 그래프 기반의 프레임워크를 제안한다. -
2025년 2월 18일 – LlamaIndex 등
PathRAG – Path Filtering 기술이 발표되었으며, 불필요한 경로를 제거해 응답의 정확도와 품질을 높인다.
2024년 초반에는 GraphRAG의 기본 구조가 정립되었으며, 하드 프롬프트 기반의 정적 질의 응답 방식이 주류를 이루었다.
2024년 하반기부터는 커뮤니티 기반의 동적 선택, 프롬프트 자동 튜닝, 그래프 지연 로딩 등 고도화된 기술들이 발표되었다.
2025년에는 범용 그래프 모델(GFM-RAG), 경로 필터링 최적화(PathRAG) 등으로 방향이 확장되고 있으며, Soft-prompting 방식은 비중은 작지만, 사용자 맞춤형 응답과 적응성 측면에서 병행되는 흐름을 보이고 있다.
GraphRAG 구축 의사결정나무
1. Strategy (전략 수립)
Graph Strategy Planning 단계에서는 GraphRAG가 적용될 환경을 고려해야 한다.
이 환경은 클라우드 또는 온프레미스일 수 있으며, 사용 사례로는 사회, 법률, 이커머스, 제조, 통신 등의 다양한 산업군이 존재한다.
30개 이상의 실 사례 기반으로 전략을 수립하는 것이 바람직하다.
2. Data (데이터 단계)
Data Qualification
GraphRAG에서 사용할 메타데이터와 스키마가 존재해야 하며, 쿼리가 기존 RAG 파이프라인과 일관되게 구성되어야 한다.
이러한 데이터는 LLM 기반 또는 휴먼 라벨러에 의해 정제될 수 있다.
(Knowledge) Graph Build
지식 그래프 구축은 두 가지 방식으로 접근할 수 있다.
- Enterprise Ontology 기반 구축 방법
- 도메인 문서 기반 구축 방법
그 다음 단계로 스키마 정렬(Schema Matching) 및 관계 매핑을 수행한다.
엔티티 연결 및 관계 구성은 자체 구축 또는 사전 학습된 기반 모델을 활용할 수 있다.
그래프 구조는 동적(Dynamic) 혹은 정적(Static) 방식으로 결정되며, 표현 방식은 다음 중 선택한다:
- Adjacency matrix
- Edge list
- Linked-list
- Bitread
질의는 글로벌 쿼리 또는 로컬 쿼리로 구분된다.
Infrastructure (인프라 단계)
Data Management
그래프 데이터 레이아웃은 단일 레이아웃, 병렬 처리 또는 파티셔닝 방식으로 관리된다.
이때 계층 구조(Hierarchical), 정점(Vertex) 중심, 엣지(Edge) 중심 중 하나를 선택해야 한다.
Graph Database Backend
단일 노드 또는 분산 그래프 처리 방식 중 하나를 선택하며, 공유 메모리를 사용하는지도 결정해야 한다.
하드웨어 및 소프트웨어는 다음을 기준으로 선택한다.
- 관계형(Relational) 기반인지
- Open/Closed API인지
- SaaS 환경을 사용하는지
- 비용 고려 여부
Processing (처리 단계)
GraphRAG 처리 방식
GraphRAG는 다음 세 가지 항목을 기준으로 구성된다.
-
LLM 연동 여부
-
Prompting 방식:
- Soft Prompting은 이질적 그래프 스케줄링(Heterogeneous Graph Scheduling)에 활용된다.
- Hard Prompting은 CoT, IRCoT, 루팅 기반 의사결정에 활용된다.
-
RAG 품질 측면
- 기존 RAG 파이프라인과의 통합 여부
- 독립형인지 의존형인지 결정한다.
Deployment (배포 단계)
Graph CI/CD 및 유지보수
CI/CD 구성에는 평가 및 유지보수 체계가 포함된다.
주요 고려 항목은 다음과 같다.
- 쿼리 지연 시간
- 응답 관련성
- 그래프 구조 일관성
평가 지표는 멀티홉 질의(Multi-hop)와 공통 지식(Common knowledge) 기반으로 구성된다.
Document 에 있는 요소들을 Graph로 표현하는 방법
Document에 있는 표(table)와 문서(text)를 그래프로 표현하는 방식은 GraphRAG을 구축할 때 매우 중요한 초기 단계이자, 이후의 정보 검색 품질에 직결되는 구조 설계 단계다. 각각을 구조화 방식, 노드/엣지 생성 방식, 대표 예시로 나누어 구체적인 정리를 해보자.
1. 표(Table)를 그래프로 표현하는 방식
표는 기본적으로 행(row)과 열(column) 로 구성된 구조화된 데이터이므로, 이를 그래프로 표현하는 방식에는 몇 가지 패턴이 존재한다.
(1) 각 행을 노드로 표현하고 열을 속성으로 유지
- 방식: 각 행 = 하나의 노드, 각 열 = 속성(attribute)
- 예시:
| 이름 | 직업 | 국적 |
|------|----------|-------|
| John | 의사 | 미국 |
| Mary | 간호사 | 영국 |→ John 노드: {직업: 의사, 국적: 미국}
→ Mary 노드: {직업: 간호사, 국적: 영국}
- 장점: 그래프 형태가 단순하며, 필터링 쿼리에 유리함
- 단점: 값들 사이의 관계 정보(예: “John은 미국에 있다”)가 누락됨
(2) 각 셀(cell)을 개별 노드로 표현하고 행/열 구조를 엣지로 연결
-
방식: 셀 데이터 자체를 노드로 만들고, 행/열 구조를 연결 엣지로 표현
-
예시:
- 노드: "John", "의사", "미국"
- 엣지: ("John") —[has_job]→ ("의사")
("John") —[has_nationality]→ ("미국")
-
장점: 노드 간 관계가 명확하게 나타나 쿼리나 확장성에 유리함
-
단점: 노드 수가 많아지고 쿼리 복잡도가 증가할 수 있음
(3) 계층 구조로 테이블 스키마까지 그래프화
- 방식: "테이블" → "열" → "값" 구조로 계층적으로 표현
- 예시:
Table → Column(이름) → Value("John")
→ Column(직업) → Value("의사")- 장점: 메타데이터, 스키마 분석에 유리
- 단점: 검색 효율이 낮음, 실사용에는 과도한 계층
2. 문서(Document)를 그래프로 표현하는 방식
비정형 텍스트 문서의 경우에는 자연어 문장을 구조화하는 과정이 선행되며, 주로 정보 추출(NER, RE)과 요약 또는 chunking 이후 그래프화된다.
(1) 엔티티(개체)와 관계 추출 방식 (Knowledge Graph 패턴)
- 방식: 문장에서 개체(Entity)와 관계(Relation)를 추출하여 삼중항(triple)으로 구성
- 예시 문장: “John은 미국 출신의 의사이다.”
→ ("John", "국적", "미국")
("John", "직업", "의사") - 장점: 실제 검색, 질의 응답(QA)에 활용도가 높음
- 단점: NER/RE 정확도에 따라 성능 크게 달라짐
(2) 문단/문장 기반의 의미 연결 방식
- 방식: 문장을 chunking한 뒤, 유사도 기반으로 문단 간 semantic edge 생성
- 예시:
문장 A: "암은 세포가 비정상적으로 자라는 병이다."
문장 B: "비정상적인 세포 증식은 종양을 유발한다."
→ A —[semantic similarity]→ B- 장점: 긴 문서 내 문장 간 연결성이 반영되어 문맥 흐름 이해에 유리
- 단점: 엣지가 추론 기반이라 신뢰도 평가가 어려움
(3) 문서 구조 기반 노드 분해 (문단, 제목, 리스트 등)
- 방식: 문서 구조를 XML/Markdown처럼 파싱하고, 구조 요소를 노드화
- 예시:
- 문서 → 제목1 → 문단1 → 리스트 항목1, 항목2
- 각 구조 요소에 id 부여 후 참조 엣지 생성 - 장점: 문서 탐색성과 시각화에 유리
- 단점: 구조가 정보 의미보다는 표현에 가까워 검색과 QA 용도에는 부적합
표 & 문서 방식 정리
| 표현 대상 | 주요 방식 | 장점 | 단점 |
|---|---|---|---|
| 표 | 행을 노드로, 열은 속성 | 간단하고 쿼리에 적합 | 관계 추론이 어려움 |
| 셀을 노드로, 엣지로 관계 표현 | 관계 표현 명확, 확장성 높음 | 복잡도 증가, 노드 수 많음 | |
| 테이블 스키마까지 계층 구조화 | 메타데이터 활용 가능 | 검색 효율 낮음 | |
| 문서 | 개체/관계 추출 기반 Knowledge Graph | QA, 검색에 가장 효과적 | NER/RE 정확도 민감 |
| 문장 유사도 기반 연결 | 문맥 흐름 반영 가능 | 관계 신뢰도 낮음 | |
| 문서 구조 기반 분해 | 시각화, 탐색성 좋음 | 정보 기반 검색에 부적합 |
그래프를 조회하는 방식
그래프를 조회하는 방식은 GraphRAG 시스템의 핵심인 Graph Retrieval 단계에서 매우 중요하다.
이 단계에서 그래프 구조 안에 저장된 정보를 어떻게 "질문(Query)"에 맞게 효율적이고 정밀하게 꺼내올 수 있느냐가 전체 성능을 좌우한다.
1. 기반 기술에 따른 조회 방식
(1) 키워드 기반 조회 (Keyword Matching)
- 질의에서 핵심 단어를 뽑아 그래프 노드의 텍스트와 단순 일치 혹은 부분 일치로 검색
- 예시:
- "미국 국적의 의사" → "국적=미국", "직업=의사" 조건 노드를 필터링 - 장점: 구현 간단, 빠름
- 단점: 문맥 고려가 안 되며 의미 기반 질의에 취약
(2) 벡터 기반 조회 (Embedding-based Retrieval)
- 노드 텍스트, 속성, 또는 서브그래프를 벡터화하고, 질의와 임베딩 유사도 비교
- 일반적으로 FAISS나 HNSW, GDBMS의 native vector search 기능 사용
- 장점: 문맥 이해 가능, 의미 기반 검색 가능
- 단점: 엣지나 구조는 반영되지 않음 (순수 텍스트 기반)
(3) 그래프 구조 기반 탐색 (Graph Traversal / Pattern Matching)
- 엣지를 따라가며 트리형/경로형으로 질의 패턴을 매칭
- Cypher (Neo4j), Gremlin (TinkerPop) 등의 그래프 쿼리 언어 사용
- 예시:
MATCH (p:Person)-[:HAS_JOB]->(j:Job {name: '의사'})
WHERE p.nationality = '미국'
RETURN p- 장점: 관계 기반 질의에 강력
- 단점: 쿼리 설계가 어렵고 LLM과 결합할 때 파싱/변환 필요
(4) 하이브리드 검색 (Structure + Semantics)
- 구조적 쿼리(Cypher 등) + 의미 기반 임베딩 검색을 결합
- 예: 구조 쿼리로 후보를 좁힌 뒤, 벡터 유사도로 재정렬
- 장점: 정확도와 확장성 모두 확보 가능
- 단점: 구현 복잡도와 성능 튜닝 필요
2. 조회 단위에 따른 방식
(1) 노드 단위 조회
단일 노드 또는 특정 타입(예: 사람, 논문, 장소 등) 필터링
(2) 서브그래프 조회
질문에 관련된 노드 집합과 그 주변 관계(1-hop, 2-hop 등)를 함께 추출
GraphRAG에서 LLM에 제공되는 context chunk는 보통 이 방식
(3) 경로(Path) 기반 조회
두 노드 사이의 관계 흐름 추적
- 예: "A가 B에게 영향을 미쳤는가?" → A→...→B 경로 존재 여부 확인
3. GraphRAG에서 주로 사용되는 조회 전략
| 목적 | 방식 | 설명 |
|---|---|---|
| 관련 정보 추출 | vector search + k-hop traversal | 의미적으로 비슷한 노드를 먼저 찾고, 주변 서브그래프 함께 추출 |
| 구조적 질의 대응 | Cypher pattern matching | 엣지 방향, 관계 타입 기반 필터링 |
| 빠른 응답 속도 | embedding prefilter → GNN scoring | 필터링 후 GNN으로 중요 노드 선별 |
| LLM 연동용 | retrieved triples → prompt injection | 검색 결과를 LLM에게 텍스트형태로 제공 |
예시 흐름: LLM 기반 GraphRAG에서의 쿼리 예시
- 사용자의 자연어 질문:
"미국 출신이며 암 치료 경력이 있는 의사는 누구인가?"- 시스템 내부 처리 흐름:
-
Query → embedding 변환
-
유사 노드 벡터 검색
-
관련 엣지를 따라 1-hop/2-hop 서브그래프 수집
-
triple로 재구성:
("John", "국적", "미국") ("John", "전문분야", "암 치료")
- 이 triple들을 LLM에게 주어 최종 답변 생성
GraphRAG 및 Graph Retrieval 에서 발생하는 주요 문제와 해결 방식
1. 스키마 정합성 부족 문제
문서나 표에서 추출된 정보가 서로 다른 스키마 구조로 표현되어 연결이 어려워지는 문제가 발생한다.
예를 들어 동일한 보험 상품을 서로 다른 이름, 분류 체계로 기술한 경우가 대표적이다.
해결 방식
- 스키마 정합화(Schema Alignment) 및 Ontology 기반 통합 기법을 적용하여 다양한 도메인 간 개체 연결을 가능하게 한다.
- self-own model 또는 foundation model을 사용한 관계 자동 추출을 통해 관계표현 자동화를 수행한다.
2. 이질적(Heterogeneous) 그래프 구조로 인한 탐색 효율 저하
노드 타입이 다양하고 관계도 복잡하여 단순 쿼리 기반으로는 효율적인 탐색이 어렵다.
동일 노드라도 다른 타입 간 연결이 많아질 경우, 정확한 결과 도출이 힘들어진다.
해결 방식
- 노드 간 연결의 type-sensitive graph routing 또는 community-based clustering을 적용해 탐색 효율을 높인다.
- LightRAG 등에서는 keyword/entity 단위로 subgraph를 미리 구성하여 local 탐색 효율을 개선한다.
3. 그래프 내 불필요 경로 포함 (Noise Path)
RAG 시 불필요하거나 중복된 경로가 포함되면, LLM이 혼란을 겪고 정확도가 떨어진다.
해결 방식
- G-Retriever의 Path Filtering 기법을 활용하여 soft-prompting, hard-prompting 방식으로 유효 경로만 남긴다.
- GraphRAG-Routing에서는 IRGPT를 통해 의미적 유사성 기반으로 경로를 필터링한다.
4. Query에 따른 응답 일관성/정확도 저하
같은 질문이어도 LLM이 어느 subgraph를 선택하느냐에 따라 응답이 달라질 수 있다.
해결 방식
- Query에 따라 task를 분류하고 적절한 prompt pool을 연결하는 방식의 Prompt Routing 구조를 사용한다.
- Prompt의 세분화와 예제 선택기를 통해 soft-context control을 실현한다.
5. Prompt 설계 난이도
Hard-prompting은 설계 복잡도가 높고, Soft-prompting은 정밀 제어가 어렵다.
해결 방식
- Hybrid 방식의 GraphRAG(HybridRAG)를 도입하여 task에 따라 동적으로 prompting 방식을 조정한다.
- Auto-tuning 기법을 적용하여 적절한 prompt 구성을 자동으로 찾아내도록 한다.
6. 멀티홉 추론의 불안정성
다단계 reasoning이 필요한 질문에서 관련 경로를 제대로 찾지 못하는 문제가 있다.
해결 방식
- GraphRAG에서는 Multi-hop reasoning metric을 정의하여 평가 기준을 명확히 한다.
- Graph Routing 모듈을 강화하여 멀티홉 경로를 사전에 탐색하거나 embedding 기반 후보 필터링을 병행한다.
7. 그래프 평가의 객관성 부족
결과 품질을 정량적으로 평가하기 어렵고, 실 사용자 피드백과 괴리가 발생할 수 있다.
해결 방식
- Graph CI/CD 구조를 도입하여 응답 시간, 출력 품질, reasoning 성공률 등 다양한 지표 기반으로 주기적 평가와 개선을 반복한다.
- 사용자 query log 기반의 Offline Evaluation과 LLM 기반의 Auto-eval 시스템을 연동한다.
GraphRAG 성능 평가 방법 및 데이터셋 구성 전략
1. 평가 목표 정의
단순 응답 정확도뿐 아니라, 그래프 구조가 유의미한 추론에 기여했는가를 평가해야 한다.
주요 평가 항목은 다음과 같다:
- 정확도(Accuracy)
- 추론 경로 적합도(Path Relevance)
- 응답 일관성(Response Consistency)
- 멀티홉 추론 성공률(Multi-hop Reasoning Success)
- 쿼리 응답 시간(Query Latency)
2. 평가용 쿼리 데이터셋 만들기 (Query Set Design)
(1) Human Annotation 기반 생성
도메인 전문가가 직접 쿼리를 만들고, 정답/경로를 명시한다.
각 쿼리에 대해:
- Ground-truth 답변
- 필요 노드 및 경로 정보
- 기대 reasoning chain
(2) Log 기반 생성
- 실제 유저의 query log에서 자주 묻는 질문을 수집하여 평가 데이터로 활용한다.
- 자주 등장하는 질문을 클러스터링 후 대표 쿼리로 선정한다.
- 실제 유저 피드백이나 선택한 결과와 비교하여 평가 가능하다.
(3) Synthetic Generation + Auto-Labeling
LLM을 활용해 도메인 기반 쿼리를 생성하고, 같은 LLM으로 정답 후보 생성 및 필터링을 진행한다.
이후 human validation으로 보강한다.
3. 정답 생성 방식 (Ground Truth Creation)
단순 정답뿐 아니라 필요 경로(노드, 엣지)를 함께 저장해야 한다.
예시:
{
"query": "네이버페이가 제공하는 자동차 보험에는 어떤 법률이 적용되는가?",
"answer": "자동차 보험법 제35조가 적용된다.",
"expected_path": ["Customer -> Fintech -> Insurance -> Product -> Law"]
}4. 평가 메트릭 설계 (Evaluation Metrics)
| 항목 | 설명 |
|---|---|
| EM (Exact Match) | 답변이 GT와 완전히 일치하는가 |
| Path Recall / Precision | LLM이 추론에 사용한 그래프 경로가 GT 경로와 얼마나 겹치는가 |
| Query Latency | 쿼리 처리 시간 |
| Answer Diversity | 다양한 질문에 대해 얼마나 일관성 있게 답하는가 |
| Faithfulness | 그래프 기반 정보에 충실한 답인가 (LLM hallucination 방지 지표) |
5. 자동화 평가 구성 (Graph CI/CD 연계)
CI/CD 파이프라인에 주기적으로 위 평가 쿼리셋을 돌려서 점수화한다.
특정 변경(예: 그래프 필터링 방식 수정) 이후 전/후 성능 비교가 가능하다.
Auto-eval 파이프라인 예:
- 쿼리 입력
- GraphRAG 실행
- 추론 경로 및 응답 수집
- Ground-truth와 비교
- 정량화된 메트릭 저장 및 리포트 생성
6. 추천 평가 도구/프레임워크
- LangChain’s
QA Benchmarking Module - HuggingFace’s
datasets+evaluate라이브러리 - OpenLLM Leaderboard 기준 자체 측정 방식
- Microsoft G-Retriever 평가 방식 (Path Matching 기반)
GDBMS, 성능과 비용 그리고 데이터 사일로를 고려해서 선정하는 방식
GDBMS(Graph Database Management System)를 선정할 때는 단순 성능뿐 아니라 비용, 운영 생태계, 데이터 사일로 해소 여부 등 실무적으로 중요한 요소들을 함께 고려해야 한다.
1. 생태계(Ecosystem) – 운영 지속성과 도입 난이도 중심
고려 요소
- 커뮤니티 활성도: Stack Overflow, GitHub, Discord 등 활발한 사용자 커뮤니티가 있는가?
- 문서화 수준: 공식 문서, 튜토리얼, 샘플 코드가 잘 정리되어 있는가?
- 도구 호환성: Python, Java, REST API, GraphQL 등 다양한 언어 및 도구와의 호환성
- 클라우드 지원 여부: AWS, Azure, GCP 등에서의 Managed Service 존재 여부
예시 비교:
| GDBMS | 생태계 특성 |
|---|---|
| Neo4j | 가장 활발한 커뮤니티, 풍부한 예제, AuraDB로 클라우드 지원 |
| Amazon Neptune | AWS와 통합이 뛰어남, IAM/CloudWatch 지원 |
| TigerGraph | 산업 적용 중심, 성능은 좋지만 커뮤니티는 다소 작음 |
2. 성능(Performance) – 대규모 그래프 처리 효율
고려 요소:
- Query 처리 속도: 특히 multi-hop query, shortest path, pattern matching 성능
- 그래프 스케일 처리 능력: 수억 개 노드/엣지에 대한 분산 처리
- 병렬 처리: GPU 가속 또는 병렬 쿼리 실행 가능 여부
- Latency vs Throughput: 실시간 응답이 필요한지, 배치 처리 중심인지 구분
주요 시나리오 예:
- 실시간 추천 시스템 → Neo4j / RedisGraph
- 수천만 노드 분산 분석 → DGL + TigerGraph
- 지식 기반 문서 검색용 RAG → RDF 기반 Blazegraph or Neptune
3. 적합성(Fit for Use) – 도메인 특화 및 비용-구조 적합성
고려 요소:
- 도메인 적합성: RDF를 사용하는 표준 데이터인지, 관계중심인지, 동적 그래프인지
- Schema 유연성: 초기에 스키마 없이 시작할 수 있는지
- 운영비용: 라이선스 비용, 온프레미스 대비 클라우드 가격
- 데이터 사일로 해소 여부: 이기종 데이터 연결이 용이한가 (RDB, 문서, 메타데이터 등)
비용 및 적합성 관점 예시:
| GDBMS | 라이선스 / 비용 스키마 유연성 이기종 연결성 |
|---|---|
| Neo4j | 커뮤니티 무료 / 기업 유료 유연함 제한적 |
| ArangoDB | 무료 / 엔터프라이즈 유료 JSON 기반 유연함 문서+그래프 복합 |
| TerminusDB | 오픈소스 완전 무료 Git-like 관리 RDF & JSON 모두 지원 |
결론 : GDBMS 선택 전략
| 우선순위 | 상황 | 추천 |
|---|---|---|
| 생태계 | 빠른 개발, 도입 쉬움이 중요할 때 | Neo4j, ArangoDB |
| 성능 | 수억 노드 이상의 데이터 처리 필요 | TigerGraph, DGL 기반 |
| 적합성 | 표준 지식베이스 (RDF), 비용 민감 | Blazegraph, TerminusDB |
| 통합성 | 다른 DB나 메타데이터 통합 | ArangoDB, JanusGraph |
