Knowledge Graph 개념 정리
1. 데이터 모델링의 문제점
애플리케이션을 설계할 때 처음 모델링한 데이터는 최종 모델과 거의 비슷하지 않은 경우가 많다. 일반적으로 데이터를 더 잘 이해하고 비즈니스 요구사항이 변화함에 따라 모델도 변경된다.
관계를 처리하도록 설계되지 않은 데이터베이스를 사용하면 애플리케이션 구축과 변화에 대응하는 것이 복잡해 진다. 이것은 "data model problem"라고 불리는 현상을 야기한다.
물리적 모델(데이터를 실제로 저장하는 방식)이 개념적 모델(우리가 자연스럽게 데이터를 생각하고 표현하는 방식) 과 잘 맞지 않는 문제
예를 들어, 관계형 데이터베이스에서는 모든 관계를 외래 키와 JOIN테이블을 사용하여 모델링해야한다. 아이러니 하게도 '관계형' 데이터베이스라는 이름에도 불구하고 실제로는 관계 자체를 직접 저장하지 않는다.
이러한 개념적 모델과 물리적 모델 간의 차이로 인해 데이터 사용이 더어려워진다. 관계와 비즈니스 규칙이 개발자가 작성한 SQL query와 코드 속에 묻혀 버리기 때문이다. 지식 그래프와 그래프 데이터 베이스는 관계와 비즈니스 규칙을 물리적 모델 자체에 명시적으로 포함함으로써 이 문제를 해결한다. 그래프 데이터 베이스에서는 관계가 데이터 구조 자체에 존재한다.
2. Knowledge Graph?
- 상호 연관된 데이터 Entity와 그들 간의 의미적 관계를 조직화하는 설계 패턴
- 데이터를 분석하고 인사이트(지식)를 도축하는데 사용됨.
- 다양한 기업사용 사례를 지원하는 데이터 계층이라 말할 수 있음
- 모든 유형의 데이터저장소와 통합 가능.
- 조직이 고도로 연결된 데이터를 관리할 수 있는 방법이 필요할 때 활용
관계형 데이터베이스도 나름의 용도가 있지만, 관계가 중요한 사용 사례에는 지식 그래프가 훨씬 더 적합하며 관계에 최적화된 유연한 데이터 구조를 가지고 있다.
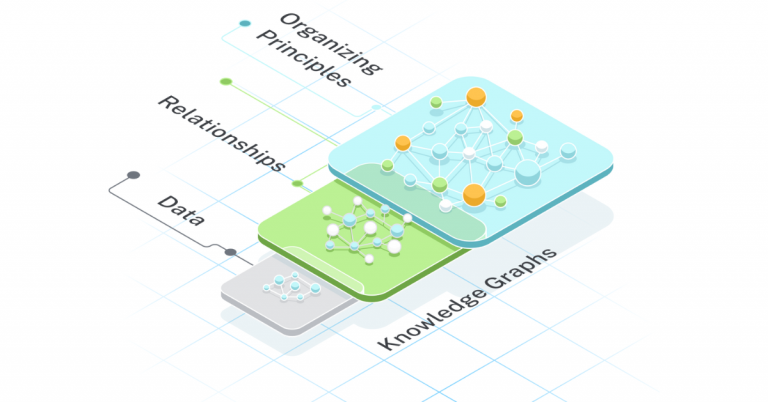
지식 그래프의 주요 구성요소 :
- 노드(NODES) : 데이터 엔티티를 나타냄
- 관계(Relationships) : 노드간의 연결
- 조직원칙(Organizing Principles) : 데이터를 개념적으로 범주, 계층 구조 또는 사용 사례에 중요한 다른 원칙으로 조직화하는 방식
지식 그래프는 관계를 데이터의 핵심 구성요소로 취급하므로써 데이터 모델링 문제를 해결한다. 관계는 JOIN을 재구성하는 대신 그래프 데이터베이스에 기본적으로 저장한다.
Step 1. Define the Knowledge Graph UseCase
지식 그레프 구축의 첫번째 단계는 명확한 목적과 사용 사례를 정의하는 것이다.
명확한 문제 정의의 중요성
구현을 시작하기 전에 지식 그래프가 해결할 문제를 명확하게 정의해야한다. 지식그래프는 관계형 모델에서는 복잡한 쿼리와 잦은 변경이 필요한 복잡한 데이터를 효과적으로 구성하고 조회하는데 탁월하다.
일반적인 지식 그래프 사용 사례
- recommendation engines : 추천 엔진
- fraud detection systems : 부정 거래 탐지 시스템
- supply chian tracking : 공급망 추적
- GraphRAG : 기업검색을위한 그래프 RAG
- master data management : 마스터 데이터 관리
점진적 접근 방식의 필요성
전체 도메인을 한번에 모델링하려 하지 말고, 집중된 시작점을 선택하자.
- 고객 데이터 통합 시스템을 구축할 경우 :
- 거래 내역, 장치 ID, 소셜 연결 등으로 확장하기 전에 기본적인 고객 식별자(이메일, 전화번호, 주소)와 그 관계부터 모델링
점진적 접근은 모델을 확장하기 전에 관리 가능한 범위 내에서 접근 방식을 검증 할 수 있게 해준다.

실제 적용 사례
-
NASA의 "Lessons Learned Database"
- 수십년 간의 프로젝트 데이터를 지식 그래프로 연결
- 엔지니어들이 트렌드를 파악하고 과거 실수를 반복하지 않도록 도움
- 화성 미션에서 200만 달러 이상의 비용 절감
-
Cisco의 메타데이터 기반 지식 그래프
- 2,000만 개의 내부 문서를 쉽게 검색할 수 있도록 구성
- 정확하고 맥락이 풍부한 콘텐츠 추천 제공
- 검색 시간을 절반으로 줄이고 연간 400만 작업 시간 이상 절약
-
Novartis의 생물학적 지식 그래프
- 유전자, 질병, 화합물 간의 관계를 시각화
- 표현형, 역사적, 의학 연구 데이터 통합
- 생물학적 시스템에서 숨겨진 관계를 식별하여 약물 개발 프로세스 가속화
Step 2 : Triple store vs. Property Graph
데이터베이스 관리 시스템(DBMS: DataBase Management system)은 시간이 지남에 따라 지식 그래프를 모델링, 쿼리 및 확장하는 방법을 결정한다. 효과적인 DBMS를 선택하면 비즈니스 요구에 맞게 사용 사례를 해결하고 확장할 수 있다.
그 주요 선택지로는 Triple Store(트리플스토어)와 Property Graph(속성그래프)가 있다.
RDF(Triple Store) - RDF 트리플스토어
RDF(Resource Description Framwork) 데이터 베이스는 '트리플스토어'라고도 하며, 데이터를 주어-술어-목적어 트리플 형태로 구조화한다.
- 원래 시맨틱 웹을 위해 설계
- 장점 : Ontology Management 및 Metadata 표현에 유용
- 한계 : 강성 구조로 인해 고도로 연결된 데이터를 모델링하는데 어려움
제한 사항
새 관계와 관계의 속성을 추가하는 경우:
- 트리플 스토어는 모든 데이터를 3개 단위 (트리플)로 구성한다.
- 새 관계를 추가하면 새로운 트리플(세가지 엔티티로 구성된 단위)이 생성된다.
- 각 관계의 속성도 또 다른 트리플로 표현된다.
해당 과정을 "구체화(Reification)"이라고 한다.
고도로 연결된 데이터셋을 다룰때 트리플 스토어는 빠르게 복잡해진다.
- 데이터셋이 많은 트리플로 폭발적으로 증가
- 불필요한 복잡성과 중복성 발생
Property Graph (속성 그래프)
Property Graph는 데이터를 Nodes(엔티티), Edges(관계), properties(노드나 관계에 대한 추가 정보)로 표현된다.
- 구조 : 규정된 데이터 구조 없이 엔티티 네트워크로 데이터를 표현
- 유연성 : 데이터 모델은 사용자가 선택한 형태를 취함.
- 데이터 모델의 한 부분은 엔티티 간 여러 관계가 있을 수 있음
- 다른 부분은 하나의 관계만 있거나 전혀 없을 수도 있음.
- 관게 저장 : 테이블을 조인하는 코드가 아닌 데이터베이스 자체에 존재
- 확장성 : 데이터 모델을 복잡하게 하지 않고 언제든지 새로운 관계나 데이터 셋을 추가할 수있음.
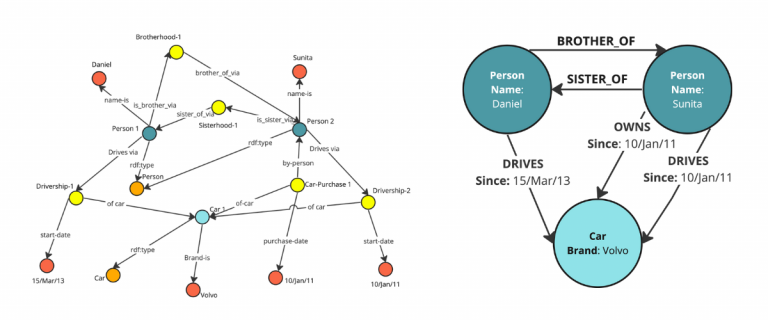
triple store VS property graph
Step 3. Model the Knowledge graph
그래프 데이터 모델링은 데이터를 노드와 관계로 표현하는 방법에 관한 것이다. 그래프 구조를 설계할 때는 도메인을 가장 효과적으로 표현할 수 있는 방법을 고안하게 된다.
Create a Graph Data Model
그래프 데이터 모델을 개발하는 과정 :
1. 도메인 분석 및 질문 정의
- 애플리케이션이 답해야할 특정 질문 정의
2. 주요 엔티티(node) 식별
- 데이터셋의 주요 객체( 고객, 제품, 거래등)를 나타내는 노드를 결정
- 각 노드에는 목적, 역할, 유형을 정의하는 하나 이상의 레이블이 있음.
3. 관계 정의
- 노드 간의 연결을 정의
- 예 : 구매한(purchased), 팔로우한다(follows), 주문했다(place order), 소속된다(belopngs to) 등
- 이 관계들은 노드들이 어떻게 상효작용하는지 나타냄
4. 속성 추가
- 노드와 관계에 대한 더 자세한 정보를 제공하는 속성을 추가
- 예: 'Person' 노드는 'first_name'과 'last_name'속성을 가질 수 있다.
- 예 : 'PLACED_ORDER'관게는 'purchase_date'와 같은 속성을 가질 수 있다.
Apply an Organizing Principle
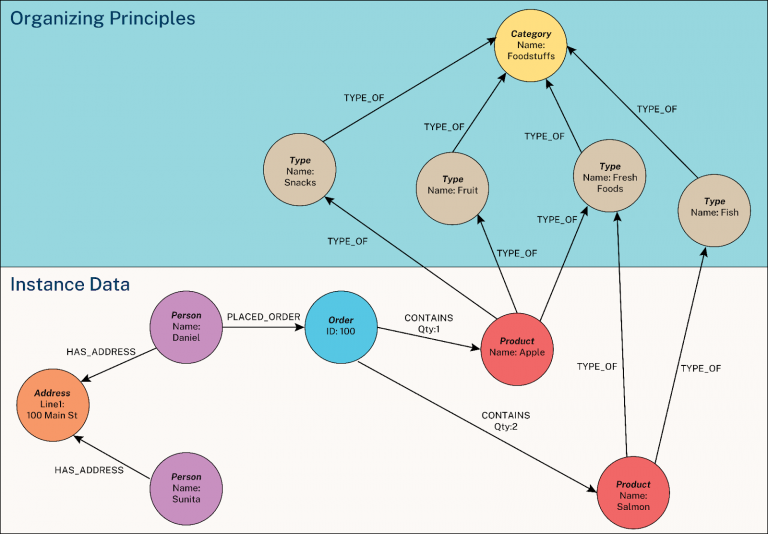
조직 원리는 주요 비즈니스 개념이나 규칙을 그래프에 직접 포함시켜 지식 그래프의 프레임워크를 구축한다. 이는 지식 그래프가 통찰력을 제공할 수 있도록 데이터를 구성하는 유연하고 개념적인 구조이다.
- 간단한 조직 원리
- 제품 분류법 (Taxonomy) : 아이템을 범주(예: 간식, 과일, 신선식품, 생선)나 계층 (예: 사과 -> 과일 -> 음식)으로 그룹화하는 방식
- 복잡한 조직 원리
- Ontology : 데이터를 의미적 네트워크에 체계적으로 매핑하는 방식
- 데이터의 구성, 분류, 해석방법을 표준화하여 애플리케이션과 시스템 전반에 걸쳐 일관성을 보장.
- 강력하지만 설계와 구현에 상당한 노력이 필요
대부분 간단한 조직원리를 사용하고, 정말 필요할때만 Ontology를 활용한다.
Step 4. Prepare Data for Ingestion
데이터 구조를 모델링 한 후, 지식 그래프를 채울 데이터를 준비해야한다.
데이터 수집
사용 사례와 관련된 데이터셋을 식별하는 것부터 시작한다.
-
구조화된 데이터: 테이블이나 스프레드시트와 같이 명확한 구조를 가진 데이터
-
반구조화된 데이터: JSON 또는 XML 파일과 같이 일부 구조를 가진 데이터
-
비구조화된 데이터: 텍스트 문서, 이메일, 로그와 같이 구조가 없는 데이터
데이터 정리
원시 데이터에는 불일치, 오류, 누락된 값이 포함될 수 있다. 지식 그래프에 데이터를 로드하기 전에 데이터를 정리해야 한다.
주요 데이터 준비 작업 :
1. 형식 표준화
모든 데이터셋에서 날짜, 숫자 값, 텍스트 필드가 일관되게 표현되는지 확인
예: 날짜 형식을 모두 'YYYY-MM-DD'로 통일
2. 중복 제거
동일한 고객이나 제품에 대한 여러 항목과 같은 중복 레코드를 식별하고 병합
그래프 데이터 모델은 지식 그래프를 생성하기 전에 이 "엔티티 해상도(entity resolution)" 단계를 효율적으로 수행하는 데 도움이 됨
3. 누락된 값 처리
불완전한 데이터를 어떻게 처리할지 결정:
- 값을 추정(imputing)하여 채우기
- 불완전한 레코드 제거
- 수동 수정을 위해 플래그 지정
4. 오류 수정
잘못된 철자, 유효하지 않은 ID 또는 기타 불일치와 같은 부정확성을 식별하고 수정
이러한 데이터 준비 과정을 통해 지식 그래프에 더 정확하고 일관된 데이터를 로드할 수 있게 된다.
Step 5. Ingest Data Into the Knowledge Graph
그래프 데이터 모델을 정의하고, 데이터를 준비했다면, 이제 데이터를 그래프 데이터베이스 인스턴스에 수집할 차례이다.
Neo4J를 예로 설명할 예정이다.
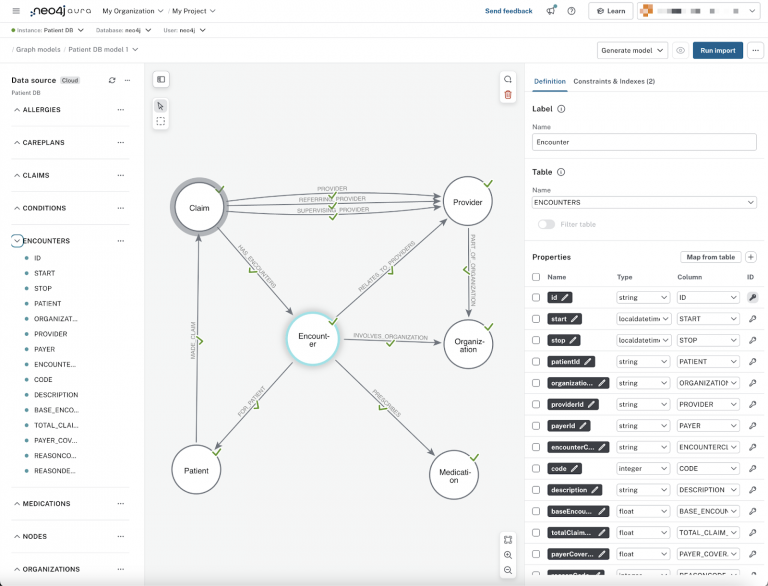
1. 데이터 소스 연결
- "데이터 서비스" 메뉴에서 "가져오기"를 선택
- 첫 번째 데이터 소스를 연결
- CSV 파일을 데이터 가져오기 서비스에 업로드하거나 드래그
2. 데이터 매핑
- 데이터 소스의 요소를 그래프의 노드, 속성, 관계에 매핑
- 이 과정은 반복적일 수 있지만, 그래프 데이터 모델에 있는 각 요소(노드 및 관계)를 데이터셋에 매핑.
- 각 요소가 정의되면 Aura Workspace는 녹색 체크 표시를 통해 노드나 관계의 필드가 채워졌음을 표시.
3. 점진적인 접근 방식
- 데이터 수집 시 작은 샘플로 시작하여 그래프 구조와 데이터 매핑을 검증
- 검증이 완료되면 전체 데이터셋을 수집하도록 규모를 확장
4. 유효성 검증
- 모든 관련 데이터셋이 올바르게 수집되었는지 확인
- 그래프의 노드, 관계, 속성, 조직 원리가 그래프 데이터 모델에 올바르게 매핑되었는지 확인
성공적으로 데이터를 수집하고 검증했다면, 지식 그래프가 완성된것이다.
Step 6. Test the KG
지식 그래프를 구축하는 것은 중요한 이정표이지만, 사용 사례에서 필요한 질문에 답할 수 있는지 확인하기 전까지는 과정이 완료되지 않는다.
지식 그래프를 테스트하면 개선이 필요한 영역을 식별하고 그에 따라 최적화할 수 있다. 이런 반복적인 과정을 통해 지식 그래프가 사용 사례를 지원하고 효율적으로 작동하는지 확인할 수 있다.
간단한 쿼리 Test
지식 그래프가 비즈니스 질문에 답할 수 있는지 확인하기 위해 쿼리를 실행한다. 이러한 쿼리는 그래프가 실행 가능한 인사이트를 제공하고 1단계에서 정의한 목표를 충족하는지 검증해야한다.
예를 들어, 전자 상거래 지식그래프에서는 다음과 같은 간단한 쿼리로 시작할 수 있다 :
- 특정 고객이 구매한 제품은 무엇인가?
- 어떤 제품 카테고리가 가장 높은 판매량을 보이는가?
- 특정 기간 동안 제품 카테고리별 총 판매액은 얼마인가?
고급 쿼리 테스트
이 후, 더 고급쿼리로 나아갈 수 있다.
- 함께 자주 구매되는 제품은 무엇인가?
- 유사한 구매이력을 가진 다른 고객을 기반으로 특정 고객에게 어떤 제품을 추천해야 하는가?
- 어떤 제품 조합이 반복 구매를 유도하고 판매 증가를 위해 번들로 제공될 수 있는가?
지식 그래프 최적화
지식 그래프가 의미 있거나 예상된 결과를 제공하지 않는 경우, 기초를 다시 검토해야 할 수도 있다.
1. 지식그래프 모델 검토 (Back to Step 3)
- 모델이 도메인을 정확히 표현하는지 평가
- 노드, 관계, 속성 또는 조직 원리를 정의하는 더 나은 방법이 있는지 확인
2. 누락된 데이터 식별(Back to Step 4)
- 데이터 준비나 수집 중에 제외된 데이터셋이 있는지 확인
- 더 나은 인사이트를 제공하기 위해 지식 그래프에 추가 데이터셋이 필요한지 판단
3. 데이터 검증 (Back to Step 5.)
- 노드, 관계, 속성이 수집 과정에서 올바르게 변환되고 도메인을 정확하게 표현하는지 확인
- 예 : "고객"이 올바른 "주문"과 연결되어있는지, "제품" 노드에 관련된 모든 속성이 완전히 포함되어 있는지 확인
이러한 테스트와 최적화 과정을 통해 지식 그래프의 실용성과 효율성을 보장한다.
Step 7. Maintain and Evolve Your KG
지식 그래프는 고정된 것이 아니라, 새로운 데이터와 비즈니스 요구에 맞춰 조정할 수 있다. 시간이 흐름에 따라 지식 그래프는 불가피한 변화에 적응하며 발전한다.
지식 그래프 발전시키기
도메인이 변화함에 따라 지식 그래프도 함께 조정해야한다.
1. 새로운 데이터 소스 추가
- 고객 리뷰와 같은 데이터셋을 통합하여 인사이트 향상
- 다양한 출처의 데이터를 통합해 더 풍부한 지식 그래프 구축
2. 사용 사례 확장
- 새로운 비즈니스 요구를 지원하도록 그래프 확장
- 예 : 전자상거래 그래프에 공급업체 네트워크 통합
3. 모델 개선
- 이해가 깊어짐에 따라 관계와 개념의 구조를 지속적으로 개선
- 더 나은 쿼리 성능과 인사이트를 위한 데이터 모델 최적화
미래를 위한 계획
지식 그래프는 비즈니스와 함께 성장해야한다. 다음과 같은 모범 사례를 적용하여 확장성과 효율성을 유지할 수 있다.
1. 업데이트 자동화
- 도구를 사용하여 데이터 수집, 검증, 업데이트 과정 간소화
- 자동화된 파이프라인으로 지속적인 데이터 통합 가능
2. 쿼리 성능 모니터링
- 복잡성이 증가함에 따라 쿼리 실행을 정기적으로 평가하고 최적화
- 성능 병목 현상 식별 및 해결
3. 확장성 계획
- 더 큰 데이터셋과 발전하는 비즈니스 요구를 지원할 수 있는 인프라 확보
- 성장에 따른 리소스 요구사항 예측 및 계획
지식 그래프를 꾸준히 유지관리하면 비즈니스가 성장함에 따라 정확한 인사이트를 계속 제공할 수 있다.
Conclusion
전통적인 데이터베이스는 풍부한 관계를 단순한 구조로 평면화하지만, 지식 그래프는 우리가 자연스럽게 생각하는 방식으로 데이터를 표현할 수 있게 해준다. (엔티티의 네트워크로서)
NASA와 Cisco 같은 조직들은 지식 그래프를 활용하여 고도로 연결된 데이터에서 인사이트를 도출한다. 이러한 인사이트는 전통적인 관계형 시스템에서는 발견하기 어려운 것들이다. 지식 그래프의 일반적인 사용 사례로는 추천 엔진 구축, 부정 거래 탐지 시스템 개발, 기업 검색을 위한 GraphRAG 사용 등이 있다.
시작하는 경우, 특정 사용 사례에 집중하고, 개념증명을 위해 위에서 설명한 단계를 따르는 것이 좋다.
이 후, 요구사항과 데이터셋이 변화함에따라 그래프가 발전하도록 한다. 첫번째 구현은 완벽할 필요가 없다(유용하기만하면됨). 경험이 쌓이고 지식 그래프가 성숙해짐에따라 연결된 데이터에서 계속해서 새로운 인사이트를 발견하게 된다.
Neo4j의 지식그래프 개념 증명 구축 개발안내서 : "The Developer's Guide : How to Build a Knowledge Grap(Northwind 데이터셋을 사용한 지식 그래프 구현의 상세한 과정)"
