최근 자연어 처리(NLP)와 검색 증강 생성(RAG) 시스템의 발전으로 LLM(대규모 언어 모델)의 정확한 평가가 필수적이라고 할수있다. 때문에, Ragas를 사용하여 RAG 파이프라인과 LLM 응답을 평가하는 시스템을 구현해보았다. RAGAS는 검색 증강생성 (RAG) 파이프라인의 성능을 평가하기 위한 오픈소스 프레임워크로, LLM의 응답을 다양한 측면에서 측정하는 여러 평가 지표를 제공한다.
RAGAS 주요 평가 지표
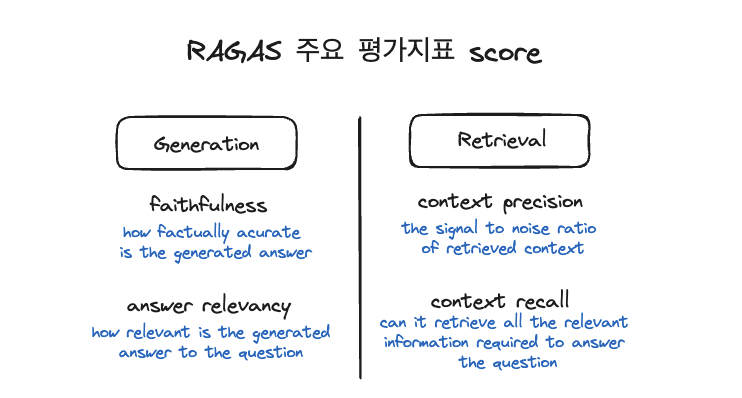
다음은 RAGAS에는 대표적인 평가지표가 4가지 있다고 할수있다. LLM이 생성한 응답과 검색된 문서의 연관성을 정량적으로 측정하는 데 사용된다.
생성 평가지표 (Generation Metrics)
- Faithfulness(충실성)
- 생성된 응답이 주어진 context와 얼마나 일치하는가를 평가.- 응답에 포함된 정보가 컨텍스트에서 추론될 수 있는 경우 높은 점수를 받는다.
- Answer Relevance(응답 관련성)
- 생성된 응답이 주어진 질문과 얼마나 관련성이 있는지를 측정.- 응답이 질문에 직접적으로 부합하고 불필요한 정보가 없는 경우 높은 점수를 받는다.
검색 평가지표 (Retrieval Metrics)
- Context Precision(컨텍스트 정밀도)
- 검색된 문서 중 실제로 질문에 관련된 문서의 비율을 평가.- 높은 정밀도는 검색된 문서들이 질문과 밀접하게 관련되어있음을 나타낸다.
- Context Recall(컨텍스트 재현률)
- 질문에 답변하는데 필요한 모든 관련 문서 중에서 실제로 검색된 문서의 비율을 측정- 높은 재현율은 필요한 정보가 대부분 검색되었음을 의미한다.
구현코드
기본설정
먼저 필요한 라이브러리를 설치하고 OPENAI API 키를 환경변수로 설정한다.
# init.py
import openai
from dotenv import load_dotenv
load_dotenv()
openai.api_key = os.environ.get("OPENAI_API_KEY")# evaluation/eval_ragas.py
from ragas import evaluate
from ragas.metrics import Faithfulness, AnswerRelevancy, ContextPrecision, ContextRecall, SemanticSimilarity
from ragas.llms import LangchainLLMWrapper
from ragas.embeddings import LangchainEmbeddingsWrapper
from langchain_openai import ChatOpenAI
from evaluation.data_samples import eval_dataset
from init import * # 환경변수 설정한 openai, embeddings model 임포트
# Langchain LLM 및 임베딩 래퍼 설정
evaluator_llm = LangchainLLMWrapper(ChatOpenAI(model="gpt-4o"))
evaluator_embeddings = LangchainEmbeddingsWrapper(embeddings)
# SemanticSimilarity를 평가하기 위해서 설정해준다.나는 임베딩 모델을 bge-m3로 따로 설정해두었기 때문에 다로 가져다가씀
Langchain 트레이싱 활성화
Langchain 트레이싱 기능을 활성화하면 대시보드에서 평가 및 로그 데이터를 시각적으로 확인이 가능하다.
# .env
LANGCHAIN_TRACING_V2=true
LANGCHAIN_ENDPOINT=https://api.smith.langchain.com
LANGCHAIN_API_KEY=lsv2_********************** # langchain api key
LANGCHAIN_PROJECT=ragastest # project name
# 미리 설정해둔 openai api 키
OPENAI_API_KEY= sk-*************위와 같이 환경변수를 설정한 후, LangChain의 추적데이터를 대시보드에서 확인할수있다. 실행한 평가의 각 지표와 세부 로그가 저장되며, 이를 통해 모델의 상세한 성능분석이 가능하다.
평가 데이터 셋 준비
단일 턴 챗봇 대화 데이터를 준비한다.
- 데이터는 사용자입력(user_input), 검색된문서,(retrieved_contexts), 생성된 응답(response), 기준 정답(reference)로 구성.
from ragas import SingleTurnSample, EvaluationDataset
samples = [
SingleTurnSample(
user_input="인공지능 모델의 성능을 평가하는 방법은 무엇인가요?",
retrieved_contexts=[
"인공지능 모델 평가에는 여러 메트릭이 사용됩니다. 정확도는 전체 예측 중 올바른 예측의 비율을 나타냅니다.",
"교차 검증은 데이터를 여러 폴드로 나누어 모델의 일반화 성능을 평가하는 방법입니다.",
"ROC 곡선은 다양한 임계값에서의 진양성률과 위양성률을 보여주는 그래프입니다."
],
response="인공지능 모델의 성능 평가는 주로 다음과 같은 지표들을 사용합니다: 정확도, 정밀도, 재현율, F1 점수, ROC/AUC",
reference="정확도, 정밀도, 재현율, F1 점수, ROC/AUC"
),
# ... 외의 예시들
]
eval_dataset = EvaluationDataset(samples=samples)평가 실행
RAGAS에서 제공하는 다양한 평가지표를 설정한 후 평가를 실행한다.
metrics = [
Faithfulness(llm=evaluator_llm),
AnswerRelevancy(llm=evaluator_llm),
ContextPrecision(llm=evaluator_llm),
ContextRecall(llm=evaluator_llm),
SemanticSimilarity(embeddings=evaluator_embeddings)
]
# 평가 실행
results = evaluate(
dataset=eval_dataset,
metrics=metrics
)
# 결과 출력
df = results.to_pandas()
print("\n평가 결과:")
print(df)
df.to_csv('evaluation_results.csv', index=False)
# 엑셀 저장 예시
import openpyxl # 엑셀 저장을 위해 필요한 import (pip install openpyxl)
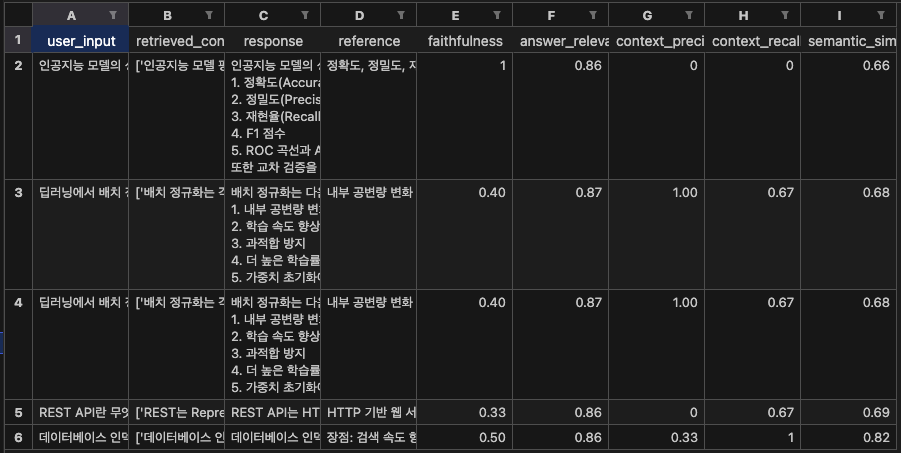
df.to_excel('evaluation_results.', index=False)평가 결과
EXCEL
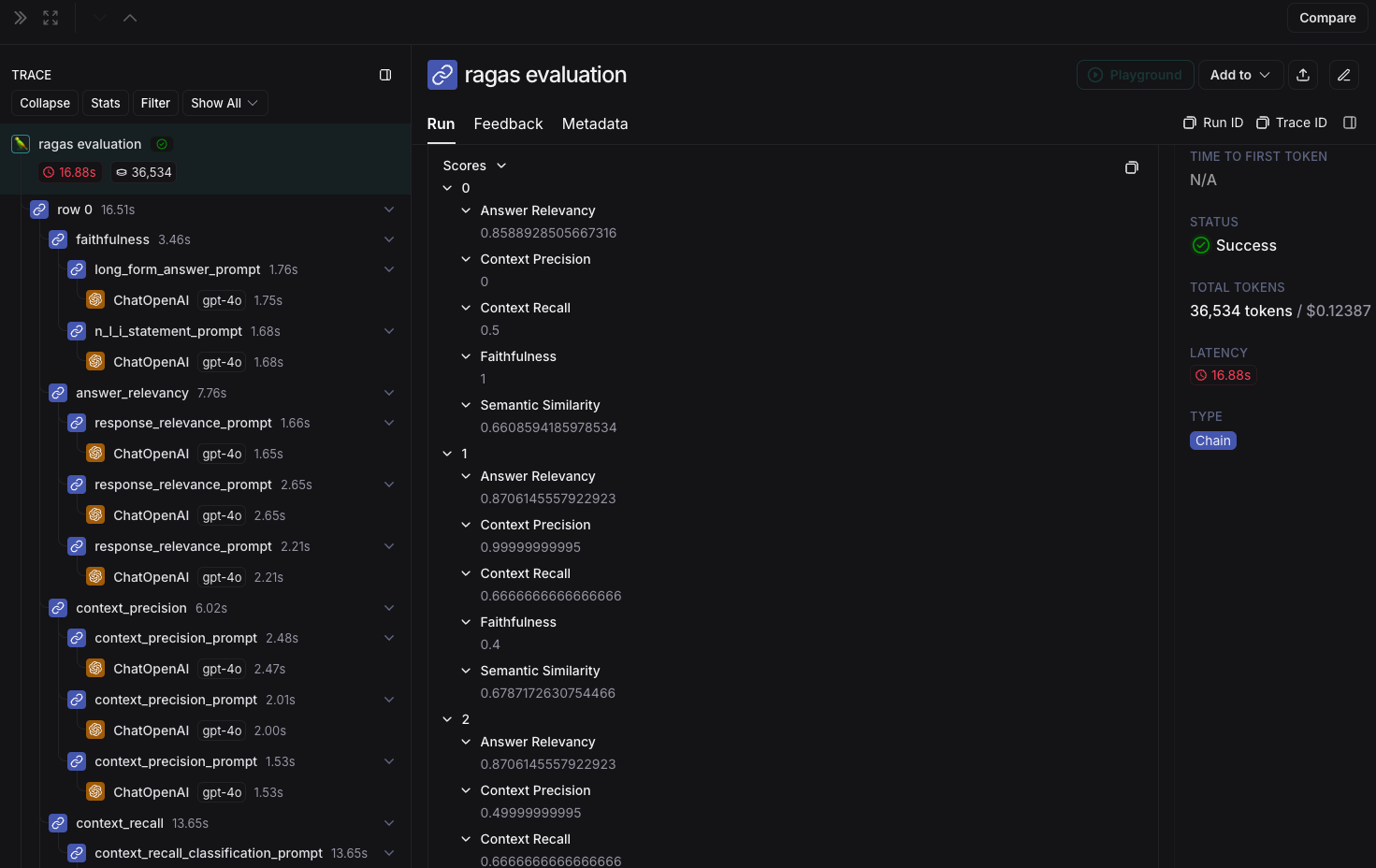
Langsmith dashboard
랭스미스는 전역으로 설정이 되어있기때문에 따로 임포트를 하지 않아도 langchain과 관련된 ai의 상세한 로그들을 데쉬보드를 통해 편하게 확인이 가능하다.
Ragas는 NLP 및 검색 시스템의 성능을 평가하는 데 유용한 도구이다.
이를 활용하여 챗봇 및 RAG 파이프라인의 성능을 정량적으로 측정하고, 개선 방향을 설정할 수 있다. 앞으로 더 많은 데이터셋과 다양한 시나리오를 테스트해볼 계획이다.
