DINO는 기존 DETR 계열 모델 대비 성능과 효율성을 향상시키는 세가지 핵심 기법을 도입했다.
1. Contrastive denoising traning : 대조적 방식의 디노이징 학습
2. Mixed query selection : 앵커 초기화를 위한 혼합 쿼리 선택 방법
3. Look forward twice scheme : 박스 예측을 위한 전방 참조 기법주요 성과
- COCO 데이터셋 : 12 epochs 에서 49.4 AP, 24epochs 에서 51.3 AP
- DN-DETR 대비 : +6.0 AP:, +2.7 AP 개선
- 최고 성능 : Objects 365 사전 훈련으로 63.3 AP 달성
- 효율성 : 기존 모델 대비 더 작은 모델 크기와 적은 사전 훈련 데이터로 더 나은 결과
DINO는 모델 크기와 데이터 크기 양방향에서 우수한 확장성을 보이며, Detection Transformer 분야의 새로운 기준을 제시한다.
1. Introduction
배경 및 문제점
- 전통적 객체 탐지 : 앵커 생성, NMS(Non-Maximnum Suppression)* 등 hand-crafted 컴포넌트 사용하여 좋은 성능달성
- DETR : Transformer 기반으로 hand-crafted 컴포넌트 제거했지만 학습 수렴이 느리고 쿼리 의미가 불분명
- 기존 개선 시도 : DAB-DETR (동적 앵커 박스), DN-DETR(디노이징 기법) 등이 제안되었으나 여전히 한계 존재
현재 문제점
- 성능 한계
- 최고 DETR 계열 모델도 COCO 에서 50 AP 미만
- 확장성 부족
- 대규모 백본과 데이터셋에서의 성능 연구 부족
DINO 핵심 개선사항
- Contrastive denoising traning : positive/negative 샘플을 동시에 사용하여 중복 출력 방지
- Mixed query selection : 인코더 출력에서 위치 쿼리 선택, 내용 쿼리는 학습 가능하게 유지
- Look forward twice : 나중 레이어의 박스 정보를 활용하여 이전 레이어 최적화
주요 성과
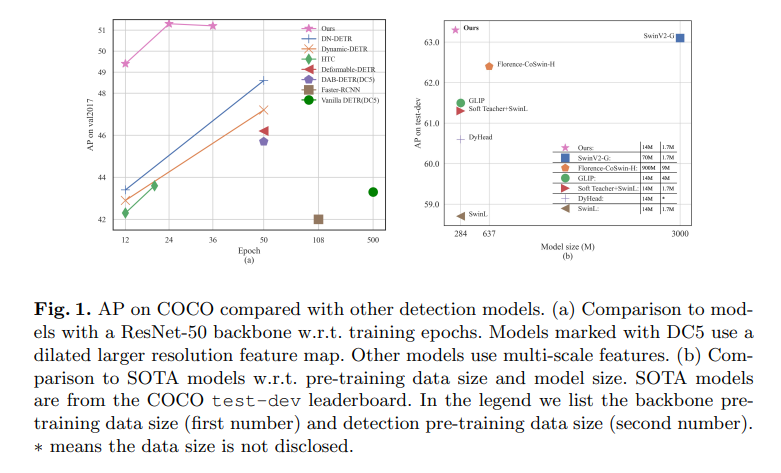
- ResNet-50: 12 epochs 49.4 AP, 24 epochs 51.3 AP (기존 최고 대비 +6.0 AP, +2.7 AP)
- SwinL* + Objects365: COCO 리더보드 1위 (val2017: 63.2 AP, test-dev: 63.3 AP)
- 효율성: SwinV2-G 대비 1/15 모델 크기, Florence 대비 1/60 사전훈련 데이터로 더 나은 성능
DINO는 최초로 end-to-end Transformer 탐지기가 COCO 리더보드에서 SOTA 달성하며, DETR 계열 모델의 성능과 확장성을 동시에 증명한 논문이다.
SwinL (Swin Transformer Large )
: Swin Transformer 의 Large 버전으로 , Computer Vision 분야에서 범용 백본(backbone)으로 사용되는 계층적 Vision Transformer.
NMS(Non-Maximum Suppression)
: 객체 탐지에서 중복된 검출결과를 제거하는 핵심적인 후처리 기법.
Related Work
2.1 Classical Object Detectors (전통적 객체 탐지기)
- Two-stage 모델 : RPN으로 후보 박스 제안 -> 두번째 단계에서 정제
- One-stage 모델 : YOLO v2/v3처럼 사전 정의된 앵커 기준으로 직접 오프셋 출력
- 현재 최고 성능 : HTC++, DyHead 등이 CoCo에서 Top 성능 달성
- 한계점 : 앵커 생성 방식에 의존하고 NMS등 hand-crafted 컴포넌트 필요로 end-to-end 최적화 불가
2.2 DETR and Its Variants(DETR및 변형모델들)
- DETR: 앵커 설계나 NMS 없는 TRansformer 기반 end-to-end 탐지기
- 주요문제 : 디코더 cross-attention으로 인한 느린 학습 수렴
개선 시도들
- Sun et al.: Encoder-only DETR (디코더 제거)
- Deformable DETR: 2D 앵커 포인트와 deformable attention
- DAB-DETR: 2D에서 4D 앵커 박스로 확장하여 쿼리 표현
- DN-DETR: Denoising training 방법으로 학습 속도 향상
DINO의 기반 : DAB-DETR + DN-DETR + deformable attention
2.3 Large-scale Pre-training(대규모 사전훈련)
- 현행 최고 성능 : 대규모 데이터로 사전 훈련된 큰 백본을 사용
- Swin V2 : 30억 파라미터 백본 + 7천만 개인 수집 이미지
- Florence : 9억 이미지 - 텍스트 쌍 백본 사전훈련 + 9백만 탐지 이미지
DINO의 차별점 : 공개 SwinL 백본 + Objects 365 데이터셋 (170만 주석이미지)만으로 SOTA 달성
DiNO는 기존 DETR 계열의 한계를 극복하고, 대규모 개인 데이터 없이도 공개 데이터만으로 치ㅗ고 성능을 달성한 혁신적인 모델이다.
3. DINO : DETR with Improved DeNoising Anchor Boxes
3.1 Preliminaries(기반기술들)
DAB-DETR의 기여
- 쿼리 분리 : DETR 의 쿼리를 positional query(위치)와 content query(내용)로 명확히 구분
- 4D 앵커 박스 : Positional query를 (x, y, w, h)형태의 명시적 앵커 박스로 표현
- 동적 정제 : 디코더 레이어별로 앵커 박스를 단계적으로 정제
DN-DETR의 기여
- 문제 식별 : DETR의 느린 수렴이 bipartite matching의 불안정성 때문임을 규명
- Denoising 학습 : 노이즈가 추가된 Ground Trouth를 디코더에 입력하여 원본 복원 학습
- 노이즈 제약 :
|∆x| < λw/2, |∆y| < λh/2, |∆w| < λw, |∆h| < λh - 보조 손실 : 기존 DETR손실에 DN 손실을 추가하여 학습 안정화
Deformable DETR의 기여
- Reference Point : Deformable attention 을 위한 참조점 개념 도입
- Query Selection : 인코더에서 특징과 참조박스를 선택하여 디코더 입력으로 직접 사용
- "Look Forward Once" : 디코더 레이어 간 Gradient detachment로 iterative 박스 정제
DINO의 통합 설계
DINO = DAB-DETR + DN-DETR + DEformable DETR 세가지 신규기법
┠─ DAB-DETR : 4D 동적 앵커 박스
┠─ DN-DETR : Denoising 학습 + 보조 손실
┠─ Deformable DTR: Query selection + "Look forward once"
┖─ DINO 신규기법 : (섹션 3.3, 3.4, 3.5에서 설명)핵심 아이디어
- 강력한 기반 : 기존 최고 기법들을 모두 결합한 storng baseline 구축
- 추가 혁신 : 이 기반 위에 3가지 새로운 방법을 도입하여 성능 대폭 향상
- 실용적 접근 : 각 기법의 장점을 살리면서 단점을 상호보완
DINO는 기존 DETR 계열 모델들의 핵심 아이디어를 효과적으로 통합한 것이다.
3.2 Model Overview
DINO 전체 아키텍쳐
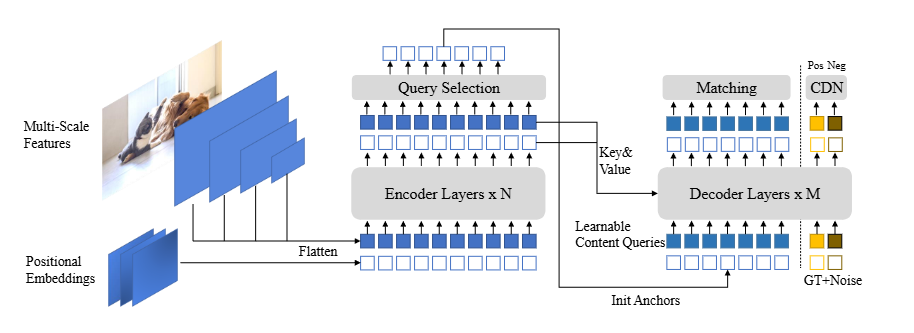
DINO는 DETR계열의 end-to-end 아키텍쳐로 다음 4개 주요 구성 요소로 이루어져있다 :
1. Backbone (ResNet, Swin Transformer 등)
2. Multi-layer Transformer Encoder
3. Multi-layer Transformer Decoder
4. Multiple Prediction Heads
데이터 처리 파이프라인
입력 이미지 -> Backbones를 사용하여 Multi-scale Feature 추출
↓
Transformer Encoder (positional embedding과 함께)
↓
Mixed Query Selection(새로운 앵커 초기화 전략)
↓
Transformer Decoder (deformable attention 사용)
↓
최종 출력 (refined anchor boxes + 분류 결과)핵심기법들
- Mixed Query Selection(section 3.4)
- Positional queries : 앵커로 초기화
- Content queries : 학습 가능한 상태로 유지
- Contrastive Denoising Training(Section 3.3)
- 기존 DN-DETR의 DN branch 확장
- Hard negative samples를 고려한 새로운 대조적 디노이징 접근법
- Look forward Twice(Section 3.5)
- 나중 레이어의 Refined box 정보를 활용
- 인접한 초기 레이어의 파라미터 최적화에 gradient 전달
주요 특징
- Deformable Attention: 인코더 출력 특징과 쿼리를 layer-by-layer로 결합
- Layer-wise 정제 : 앵커박스와 content feature 를 단계적으로 개선
- DN Branch : DN-DETR 처럼 추가적인 Denoising 학습 브랜치 보유
3.3 Contrastive DeNoising Training
- 기존 DN-DETR의 한계 : GT박스(Ground Trouth Box) 근처 앵커 예측은 잘하지만 , 객체가 없는 앵커에 대해 "no object"에측 능력 부족
- 혼란(Confusion) 문제 : 하나의 객체 주변에 여러 앵커가 있을때 모델이 어떤 앵커를 선택할지 결정하기 어려움
CDN(Contrastive DeNoising) 구현방법
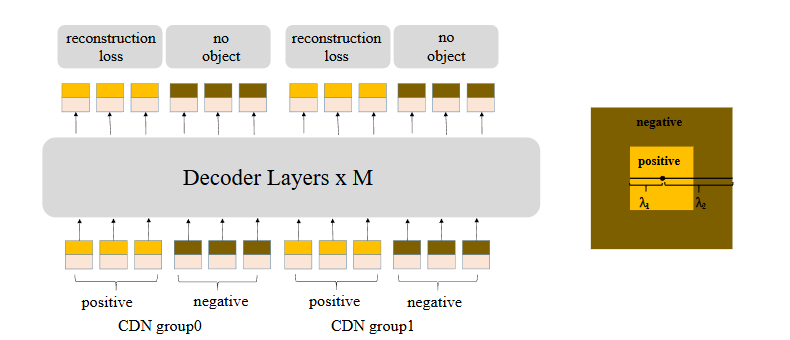
CDN 쿼리 생성 :
┠─ Positive Queries (내부 노란색 사각형) : 노이즈 < λ₁ → GT 박스 복원
┠─ Negative queries (외부 갈색 사각형 ) : λ₁ < 노이즈 < λ₂ → "no object" 예측
┗─ 각 CDN group : n개 GT 박스 당 2n개 쿼리 (positive + negative)손실 함수
- 박스 회귀 : L1 loss + GIOU loss
- 분류 : Focal loss(positive/negative 모두)
CDN의 효과
- 중족 예측 억제
- 기존 DN : 같은 객체에 대해 3개 이상 중복 예측 발생
- CDN : 앵커 간 미세한 차이를 구분하여 중복 에측 방지
- 고품질 앵커 선택
- 원거리 부적절한 앵커 거부 능력 향상
- GT 박스에 더 가까운 앵커 선택
성능평가 : ATD(k) Metric
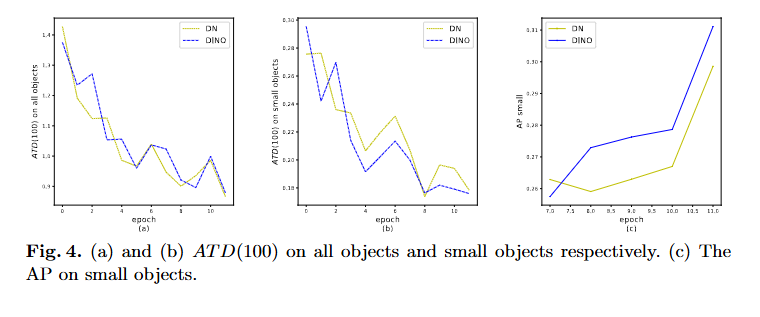
ATD(k)정의 :
ATD(k) = 1/k x Σ{topK({||b₀-a₀||₁, ||b₁-a₁||₁, ..., ||bₙ₋₁-aₙ₋₁||₁}, k)}실험 결과:
- (a) 전체 객체 ATD(100) : DN과 DINO 모두 유사한 성능, 12epoch 후 수렴
- (b) 소형 객체 ATD(100) : DINO가 DN 대비 더 나은 앵커 선택
- (c) 소형 객체 AP : CDN이 DN 대비 +1.3AP 개선(12epoch, ResNet-50)
핵심 의의
- Hard Negative Mining : GT box 에 가까운 hard negative 샘플을 활용한 대조학습
- 소형 객체 특화 : 특히 작은 객체 탐지에서 뛰어난 성능 향상
- 안정적 학습 : 혼란 문제 해결로 더 안정적이고 정확한 앵커 선택
CDN은 기존 DN-DETR의 디노이징 개념을 확장하여 positive/negative 대조학습을 통해 모델의 판별 능력을 크게 향상시킨 기법이다.
3.4 Mixed Query Selection요약
기존 방법들의 한계
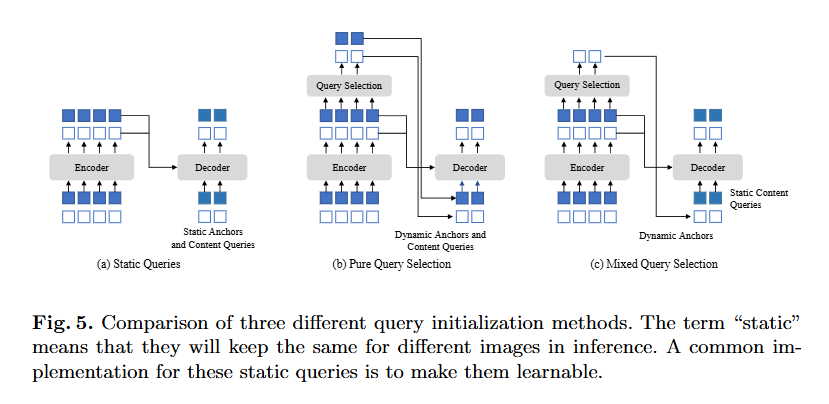
(a) Static Queries
- 사용모델 : DETR, DN-DETR
- Positional queries : 학습 데이터에서 직접 학습한 고정 앵커
- Content queiries : 모든 0벡터로 설정
- 한계 : 개별 이미지의 인코더 특징을 전혀 활용하지 않음
(b) Pure Query Selection
- 사용모델 : Deformable DETR("two-stage")
- Top-K 선택 : 마지막 인코더 레이어에서 상위 top-k 특징 선택
- Linear Transform : 선택된 특징을 positional + content 쿼리 모두로 변환
- 보조 탐지 헤드 : 예측 박스로 reference box 초기화
- 문제점 : 선택된 특징이 모호하고 오해의 소지가 있음.
- 하나의 특징에 여러 객체 포함 가능- 객체의 일부분만 포함할 수 있음
(c) Mixed Query Selection(DINO 제안)
핵심 아이디어 : 선택적 초기화
DINO의 Mixed Query Selection: ┠─ Positional queries : Top-K 선택된 특징의 위치 정보만 활용 ┗─ Content queries : 기존처럼 학습 가능한 정적 파라미터 유지
DINO의 장점
- 위치 정보 개선
- Top-K 선택된 특징으로 앵커박스(positional queries)초기화
- 개별 이미지에 특화된 더 나은 위치 정보제공
- Content 쿼리 안정성
- Content queries 를 학습 가능한 상태로 유지
- 예비적이고 미완성된 특징으로 인한 오해방지
- 효과적인 특징 풀링
- 더 나은 위치정보를 사용하여 인코더에서 포괄적인 content 특징 추출
- 첫번째 디코더 레이어가 spatial prior*에 집중하도록 유도
spatial prior : Computer vision과 딥러닝에서 공간적 관계나 구조에대한 사전 지식을 의미.
핵심 철학
Deformable DETR & DINO :
- Deformable DETR : 모든 쿼리를 선택된 특징으로 초기화 -> 과도한 의존성
- DINO : 위치만 초기화 , 내용은 학습 -> 균형잡힌 접근법
Mixed Query Selection 의 실제 효과
- Static 보다 향상된 위치인식
- Pure 보다 안정적인 content 학습
- 최적의 초기화 전략으로 성능 향상
Mixed Query Selection은 위치 정보의 장점은 취하되 content 정보의 모호성은 피하는 균형잡힌 쿼리 초기화 전략이다.
[ Mixed Query Selection(DINO) Example ]
- Positional : 인코더가 "사람이 있을것 같은 위치"를 제안
- Content : 학습 가능한 파라미터로 "사람의 특징"을 점진적으로 학습
장점 : 위치는 이미지 특화, 내용은 안정적 학습
[ 실제 동작 과정 ]
- 학습 초기
Query 1 (사람탐지용)
- Position : (100, 50, 40, 120) <- 인코더가 제안한 좋은 위치
- content : [0.1, -0.3, 0.7, ...] <- 학습중인 "사람"특징 벡터- 학습완료 후
Query 1 (사람 탐지 전문):
- Position : 동적으로 이미지마다 최적 위치 선택
- Content : [0.8, -0.1, 0.9, ...] <- "사람"을 잘 표현하는 학습된 특징3.5 Look Forward Twice
DINO 는 박스 예측을 위한 새로운 방법으로 "Look Forward Twice" 를 제안합니다. 이는 기존 Deformable DETR의 "Look Forward Once"방식을 개선한 것이다.

Figure 6(a) Look Forward Once
기존 방식의 한계 | formable DETR의 접근법 :
- Gradient detachment : 학습 안정화를 위해 gradient back propagation 차단
- 단일 레이어 최적화 : Layer i의 파라미터는 bi의 auxiliary loss에 의해서만 업데이트
- 제한적 정보 활용 : 나중 레이어의 개선된 정보를 활요하지 못함
Figure 6(b) - Look Forward Twice
DINO의 개선 방법(Look Forward Twice) :
동작원리
Look Forward Twice :
├─ Layer i 파라미터 <- Layer i 손실 + Layer (i+1) 손실 영향
├─ 각 predicted offset Δbi가 두 번 사용:
│ ├── b'i 업데이트용
│ └── b(pred)i+1 업데이트용예측 박스 정확도의 결정 요소
두가지 핵심요소 :
1. 초기 박스 품질 : bi-1의 품질
2. 예측 오프셋 : Δbi의 정확성
Look Forward Once vs Look Forward Twice:
- Look Forward Once: 오프셋(Δbi)만 최적화 (gradient detachment로 인해)
- Look Forward Twice: 초기 박스(bi-1)와 오프셋(Δbi) 모두 개선
핵심 개선 사항 :
- 정보 활용 극대화
- 나중 레이어의 refined box information 활용
- 양방향 정보 흐름으로 더 정확한 박스 예측
- 학습 안정성 유지
- Deformable DETR 과 동일한 Update 함수 사용
- 점진적 개선 방식으로 안정성 보장
