건물 용도 정보는 도시 계획, 디지털 트윈, 그리고 정보에 기반한 정책 수립에 매우 중요한 요소이다.
기존 연구들은 주로 건물 용도를 광범위한 카테고리만 분류하는데 집중하였으며, 실제 용도에 대한 일반적인 통찰만을 제공했다.이 연구는 계층적 건물 카테고리 추출을 조사한다. 이는 광범위한 분류와 세부 분류를 모두 포함하면서 복합 용도 까지 고려하는 접근법이다.
1. INTRODUCTION
현대도시환경에서는 하나의 건물내에서 다양한 인간활동이 이루어지는 복합용도 건물이 증가하고 있다. 이는 지속가능한 발전목표- 지속가능한 도시와 커뮤니티 달성에 매우 중요한 요소이다.
기존 연구의 한계점
- 기존 연구들은 주고 광범위한 카테고리로만 분류하여 실제 용도에 대한 일반적인 통찰만을 제공
- 세부 기능과 복합 용도를 고려한 연구보족
- 세부 단일 모달리티 사용으로 인한 제한된 정확도
구체적 한계
- 단일 모달리티의 한계
- Srivastava et al.(2018)는 거리뷰 이미지만 사용하여 9가지 건물 기능을 예측했지만, 제한된 정확도와 낮은 평균 정확도를 보임 - 데이터 의존성 문제
- Liu et al.(2018)은 소셜 네트워크, 택시 궤적, POI 데이터를 사용햇지만, 특정 데이터가 부족한 건물에는 적용할 수 없는 한계.
건물 용도 분류의 중요성
세부 기능과 복합용도를 고려한 건물 용도 분류 연구가 매우부족하며, 복합 토지이용 시나리오와 관련된 복잡성 뉘앙스를 효과적으로 처리할 수 있는 연구가 필요한 상황.
- 도시 계획 및 설계
- 도시 디지털 트윈
- 인프라 개발
- 응급관리 및 정책 수립
- 스마트 성장, 압축 도시, 생태 도시, 자전거 친화 도시 등 도시 이론
등에 핵심적인 역할을 함.
따라서 이 논문은 연구 공백을 메워, 다중 모달리티 Transformer 기반 특징 융합 네트워크를 제안하여 계층적 건물 용도 분류를 실현한다.
연구 목표
- 계층적 분류 시스템 설계(세부 카테고리 포함)
- 다중 레이블 분류 데이터셋과 네트워크 설계로 다양한 데이터 소스 간 시너지 활용
- 도시 계획 및 개발을 위한 정보 기반 의사결정 개선
2. Dataset
데이터 수집 및 구축
17,946개 건물 샘플을 암스테르담 시 웹사이트의 비주거 기능 데이터를 기반으로 구축.
각 포인트 데이터를 가장 가까운 건물 풋프린트(아래그림)와 정렬하여 매칭하고, 주거 기능은 수동으로 부여. 여러용도가 혼재하는 건물은 복합용도(mixed-use)로 분류.

암스테르담 건물분포 시각화 풋프린트
OpenStreetMap 에서 가져왔으며, 건물 용도 분류모델을 학습하고 평가하는데 사용
계층적 분류 체계
2단게 트리구조
4단계 광범위 카테고리
- R(주거) : R1(단독주택), R2(연립주택), R3(공동주택), R4(호텔)
- B (상업서비스) : B1(소매), B2(기업), B3(음식점/바/카페), B4(사무실), B5(스포츠), B6(여가/유흥)
- A (공공관리서비스) : A1(커뮤니티 집회), A2(의료), A3(교육)
- I (산업) : 세부 분류 없음
R1, R2, R3는 상호 배타적이며, R4는 건축적 특성에 따라 R1, R2, R3 중 하나에 할당된다.

(a, d, g) : SVI (Street View Images)
(b, e, h) : Remote Sensing (RS)
(c, f, i) : Digital Surface Model (DSM)
데이터 분포및 분할
- 훈련용 80%, 검증용 10%, 테스트용 10%로 분할
- R4, B5, B6, A1, A2, A3은 각각 1,000개 미만의 적은 샘플 수를 가짐
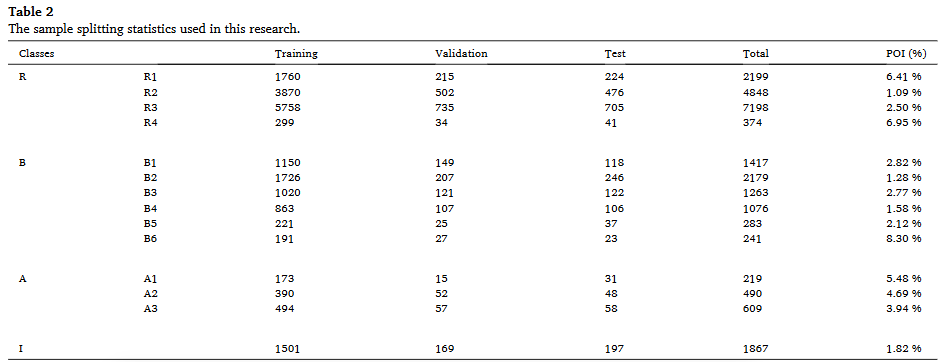
- Training (훈련), Validation (검증), Test (테스트): 모델 학습 및 평가를 위해 전체 데이터셋을 나눈 샘플 수. 일반적으로 훈련 데이터로 모델을 학습시키고, 검증 데이터로 학습 중 성능을 확인하며, 테스트 데이터로 최종 성능을 평가한다. 논문에 따르면, 샘플은 훈련 80%, 검증 10%, 테스트 10%로 분할한다.
- Total (총합): 각 클래스에 속하는 전체 샘플 수입니다.
- POI (%): 해당 클래스의 건물 샘플 중 POI(Point of Interest) 데이터가 있는 비율을 나타냅니다. POI 데이터는 특정 장소와 관련된 정보(예: 가게 이름, 종류)를 포함
다중 모달리티 데이터 소스
2022년 데이터로 통일하여 수집
| 데이터 유형 | 소스 | 제공 정보 | 해상도/규격 | 커버리지 |
|---|---|---|---|---|
| RS (Remote Sensing - 위성 이미지) | SuperView-1 | 건물 상부조감도 | 0.5m 공간해상도 | 100% |
| DSM (Digital Surface Model) | PDOK(네덜란드 공공 서비스) | 건물 높이 /3D구조 | 0.5m 공간해상도 | 100% |
| SVI (Street View Images) | Google Street View | 건물 정면 외관 | 640×640 → 224×224 리사이즈 | 73.1% |
| POI (Point of Interest) | OpenStreetMap(사람들이 직접 입력) | 기능/용도 텍스트 | 텍스트 데이터 | 2.8% |
3. METHOD
건물 용도 분류를 각 용도 카테고리의 존재여부를 판별하는 이진분류작업으로 접근한다. 복합 용도 건물을 고려하여 다중 레이블 다중 모달 분류 방법을 제안했다.
Modality Alignment(데이터정렬)
건물 풋프린트의 중심점을 기준으로 네가지모달리티 정렬
- SVI : 건물을 향한 가장 가까운 Street View 이미지 선택
- DSM/RS: 건물 중심점 기준으로 224x224 픽셀로 Cliping.
- POI : 가장 가까운 건물 중심점 풋프린트와 매칭
- Json 파일로 정렬 정보를 기록하여 검색 가능하게 관리
MMFF-Net 아키텍쳐
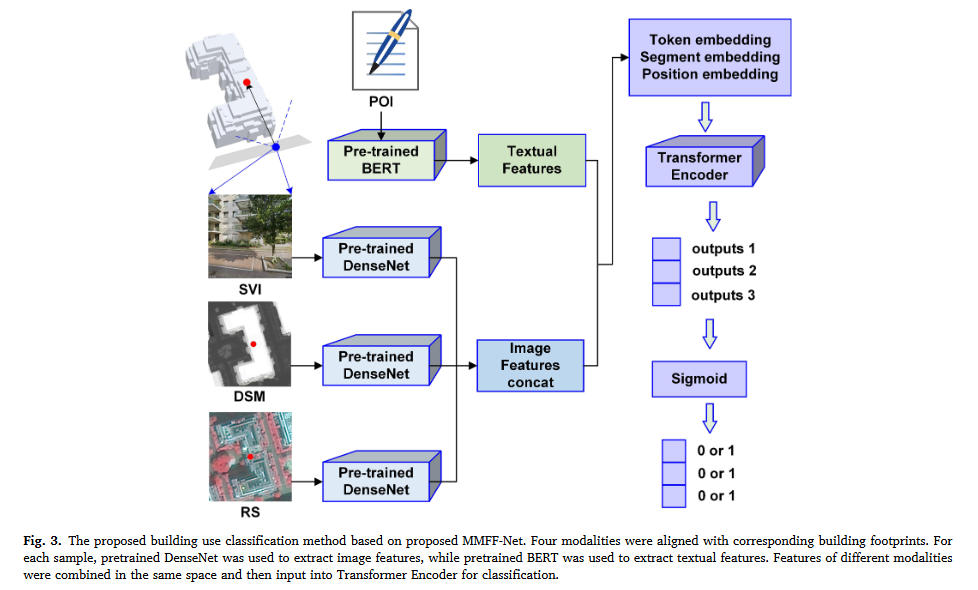
1. 입력데이터 수집
모델은 건물의 용도를 분류하기 위해 네가지 종류의 다른 소스에서 얻은 데이터를 입력으로 사용한다.(SVI, DSM, RS, POI)
2. 이미지 특징 추출
- 사전 훈련된 DenseNet 모델로 SVI, DSM, RS 이미지의 특징 추출
- DenseNet : 이미지의 시각적 계층 구조와 특징을 효과적으로 학습하는 컨볼루션 신경망.
- 전처리 : 224×224 RGB 형식으로 전처리
- DSM : 그레이스케일을 RGB로 변환(채널 3배 복제)- SVI : 640×640에서 224×224로 바이리니어 보간 리사이즈
- RS : 4밴드에서 false color combination으로 RGB 변환
2. 텍스트 특징 추출
- 사전 훈련된 BERT 네트워크로 POI 데이터의 의미 정보 추출
- WordPiece 알고리즘으로 토큰화하고 BERT 어휘에 매핑
- 패딩으로 고정길이 달성
3. 특징융합
- 추출된 이미지 특징과 텍스트 특징을 하나로 결합하여 통합된 특징 표현을 생성
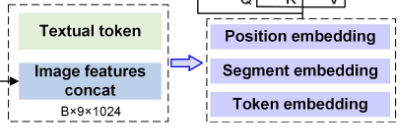
- 추출된 이미지 특징들은 먼저 연결(concatenate)된다.- 연결된 이미지 특징과 텍스트 특징은 토큰 임베딩 (token embedding), 세그먼트 임베딩 (Segment embedding), 위치 임베딩(Position embedding)과정을 거쳐 Transformer 모델의 입력 형식에 맞게 변환.
- Transformer Encoder로 융합된 특징에 대해 분류 수행
MMFF-Net 아키텍쳐 상세분석

1. 입력 데이터 전처리 단계
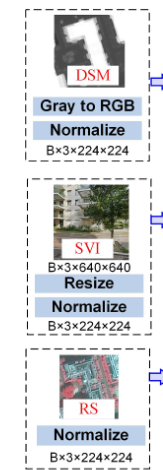
- DSM(Dgital Surface Modal)
- Gray to RGB 변환 : 단일 그레이스케일 채널을 3개 RGB 채널로 복제- 정규화 : Bx3x224x224 형태로 표준화
- 목적 : CNN이 처리할 수 있는 3채널 형태의 높이 정보 제공
- SVI (Street View Images)
- 크기 조정 : 원본 640x640 을 244x244 바이리니어 보간 리사이즈- 정규화 ImageNet 사전 훈련 모델에 맞는 평균/표준 편차로 정규화
- 목적 : 건물 정면 외관의 세부사항을 표준 입력 크기로 조정
- RS(Remote Sensing)
- 4밴드 -> RGB: False color combination 으로 다중 스펙트럴을 시각적 3채널로 변환- 밴드 선택 : Near -infrared, Red, Green 밴드를 RGBfh aovld
- 정규화 : Bx3x224x224 표준형태로 변환
2. DenseNet 기반 특징 추출
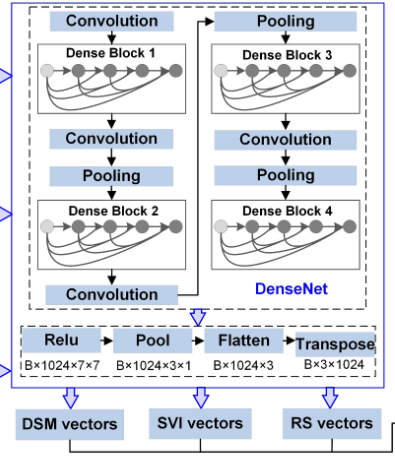
Dense Block 구조 분석
DenseNet의 핵심은 각 레이어가 이전 모든 레이어와 연결되는 Dense Connection이다.
- Dense Block 1~4의 계층적 처리
Dense Block 1: 저수준 특징(모서리, 텍스처) Dense Block 2: 중간수준 특징(형태, 패턴 Dense Block 3: 고수준 특징 (객체부분) Dense Block 4: 최고수준 특징(전체 객체) - 특징 추출 과정
- Convolution -> Pooling : 공간 해상도를 점진적으로 축소하면서 추상화- ReLU 활성화 함수 : 비선형성 추가
- 최종 벡터화 : B x 1024 x 7 x 7 -> Flatten -> Transpose -> B x 3 x 1024
모달리티 특징 벡터 생성
각 모달리티에서 1024차원 특징 벡터 3개씩 추출 :
- DSM vectors : 건물 높이와 3D 구조적 특성
- SVI vectors : 건물 외관과 건축적 디테일
- RS vectors : 건물 상부구조와 공간적 맥락
3. BERT 기반 텍스트 처리
POI 데이터 토큰화
WordPiece 토큰화 과정

원본 POI : "Commercial Building Office Sapce"
-> WordPiece : ["Com", "##mercial", "Building", "Office", "Space"]
-> Bert Vocabulary : [2543, 7891, 1248, 3456, 8901]
-> Padding: [2543, 7891, 1248, 3456, 8901, 0,0, ..., 0] (512길이)텍스트 특징 추출
- Bert Encoding : 각 토큰의 의미적 표현 학습
- Context Embedding : 전체 POI 텍스트의 맥락적 의미 파악
- 최종 출력 : 텍스트의 의미적 특징 벡터
4. 멀티모달 특징 융합
임베딩 통합 메커니즘
검색 결과의 Transformer 기반 encoder-decoder 모델 구조 :
3가지 임베딩 결합
최종 임베딩 = Token Embedding + Segment Embedding + Position EmbedingToken Embedding
- 이미지 특징 : Bx9x1024 (DSM 3개+SVI 3개+RS 3개)
- 텍스트 특징 : POI 토큰 임베딩
- 통합 : 모든 모달리티를 동일한 임베딩 공간에 매핑
Segment Embedding
- 모달리티 구분 : 각 특징이 어떤 모달리티에서 왔는지 구분
- 세그먼트 ID : DSM =0, SVI=1, RS=2, POI=3 등으로 할당
Position Embedding
- 순서정보 : 각 특징 토큰의 위치 정보 인코딩
- 공간적 관계 : 이미지 패치 간의 상대적 위치 학습
5. Transformer Encoder 심화분석
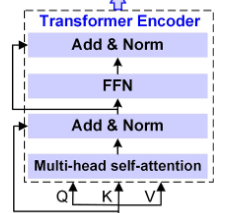
Multi-Head Self-Attention
검색 결과의 Adaptive Weight Learing 개념을 적용 :
- 12개 어텐션 헤드의 역할 분화
- Head 1-3 : 공간적 관계 학습(DSM <-> RS)- Head 4-6 : 시각-텍스트관계(SVI <-> POI)
- Head 7-9 : 전역적 맥락 (모든 모달리티 간)
- Head 10-12 : 계층적 분류 관계 (광범위 <-> 세부)
- Attention 계산과정
Q,K,V = Linear(융합된 특징)
Attention(Q,K,V) = Softmax(QK^T/√d_k)VFeed-Forward Network (FFN)
- 3,072개 파라미터의 역할
- 차원확장 : 768 -> 3,072 (4배확장)
- 비선형 변환 : GELU 활성화 함수로 복잡한 패턴 학습
- 차원축소 : 3,072 -> 768 (원래 차원으로 복원)
Add & Norm
- 검색 결과의 JSENet 구조를 참고하면 :
- Residual Connection: 입력 + 출력으로 그래디언트 소실 방지
- Layer Normalization: 각 레이어 출력을 정규화 하여 학습 안정화
6. 계층적 다중 레이블분류
17개 독립 분류기 구조
광범위 카테고리 (4개)
P(R) = σ(W_R × h + b_R) # 주거
P(B) = σ(W_B × h + b_B) # 상업
P(A) = σ(W_A × h + b_A) # 공공
P(I) = σ(W_I × h + b_I) # 산업세부 카테고리 (13개)
P(R1) = σ(W_R1 × h + b_R1) # 단독주택
P(R2) = σ(W_R2 × h + b_R2) # 연립주택
...
P(B6) = σ(W_B6 × h + b_B6) # 여가시설7. 핵심 혁신점
Adaptive Weight Learning
검색 결과의 AWLN(Adaptie Weight Learning Network) 개념을 적용:
w_n = Sigmoid(W_L(φ_w^2(φ_w^1(f_n))) + b_L)- 동적 가중치 : 각모달리티의 중요도를 동적으로 조절
- 상황적응 : 건물 유형에 따라 모달리티 중요도 자동 조정
Cross-Modal Attention Visualization
- 어텐션 맵 : 어떤 모달리티가 어떤 분류에 기여하는지 시각화
- 해석 가능성 : 모델의 의사결정 과정을 투명하게 공개
Transformer Encoder 구조
12개 레이어, 각 레이어당 12개 self-attention head(크기 768)
Feed Forward network 3,072개 파라미터
총 276,480개 파라미터
Transformer Encoder:
- 융합된 다중 모달리티 특징을 입력으로 받는다.
- 여러 층(Layer)으로 구성되며, 각 층은 Multi-head >- self-attention 메커니즘과 Feedforward Network (FFN)로 이루어져 있다.
- Add & Norm (잔차 연결과 레이어 정규화)은 학습 안정화 및 성능 향상을 돕는다.
- Self-attention 메커니즘은 다양한 모달리티의 특징들 간의 복잡한 상호작용 및 관계를 학습하는 핵심 역할을 한다.
- Transformer Encoder는 입력 특징을 더욱 풍부하고 문맥화된 표현으로 변환한다.출력 및 분류 (Output and Classification):
- Transformer Encoder의 최종 출력은 건물의 용도를 나타내는 융합된 표현.
- Sigmoid: 이 표현은 최종적으로 Sigmoid 활성화 함수를 통과한다. 각 출력 노드는 특정 건물 용도 카테고리의 존재 확률을 나타내며, 0과 1 사이의 값을 가진다.
- 네트워크는 건물의 광범위(broad) 용도와 상세(detailed) 용도를 동시에 예측한다. 각 카테고리별로 독립적인 이진 분류(binary classification)를 수행하므로, 한 건물에 여러 용도 라벨이 할당될 수 있어 혼합 사용 분류가 가능해짐.
논문에서는 4개의 광범위 카테고리와 13개의 상세 카테고리를 예측하므로 총 17개의 출력을 가진다.
분류및 예측
다중 레이블 분류
- 각 카테고리별 독립적인 이진 분류기 구성
- 광범위 카테고리와 세부 카테고리를 동시에 독립적으로 예측
- Sigmoid 분류기로 각 카테고리의 존재/부재 판별
평가지표
- MAF(Macoro Average F1) : 모든 카테고리의 평균 F1 점수

- WAF(Weighted Average F1) : 샘플수로 가중된 평균 F1 점수
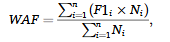
이 방법론의 핵심은 계층적 구조를 유지하면서 복합 용도를 고려한 동시 돌깁 예측과 네가지 서로 다른 모달리티의 효과적인 융합이다.
4. EXPERIMENT
4-1. 네가지 모달리티기반 건물 용도 분류 실험
실험 설정
- 손실함수 : Multilabel Soft Margin Loss
- 최적화 기법 : AdamW
- 훈련 설정 : 24 epochs, 배치 크기 16, 초기학습률 5e-5
- 분류 대상 : 4개 광범위 카테고리 + 13개 세부 카테고리 ( 총 17개 )
카테고리 성능 분석

- 광범위 카테고리 : R(주거), B(상업), A(공공관리서비스), I(산업)
세부 카테고리 : - 주거(R) 카테고리 - 전반적으로 우수한 성능
- R1, R2, R3: 98%, 97%, 92%로 매우 높은 정확도- R4 (호텔): 30%로 분류 난이도가 높음을 반영
- 상업서비스(B) 카테고리 - 광범위 카테고리보다 낮은 성능
- B1~B6: 55%, 74%, 38%, 42%, 21%, 19%
- 모든 세부 카테고리가 광범위 카테고리(86%)보다 낮아 B 카테고리 내 세부 분류의 어려움 시사 - 공공관리서비스(A) 카테고리 - 가장 큰 성능 격차
- A1, A2, A3: 6%, 23%, 27%
- 광범위 카테고리(49%)와 세부 카테고리 간 현저한 성능 차이
전체 성능 지표
- 세부 카테고리 (13개)
- MAF: 47.8%
- WAF: 77.0% - 광범위 카테고리 (4개)
- MAF: 80.5%
- WAF: 90.7% - 전체 카테고리 (17개)
- MAF: 55.5%
- WAF: 84.2% - 주요 발견사항
- 광범위 카테고리가 세부 카테고리보다 분류하기 용이함
- 주거 카테고리(R)에서 가장 높은 성능, 특히 건축적 특성이 뚜렷한 R1, R2, R3
- 공공관리서비스(A) 카테고리에서 가장 큰 분류 어려움
- 복합 용도 고려 시에도 전반적으로 양호한 성능 달성
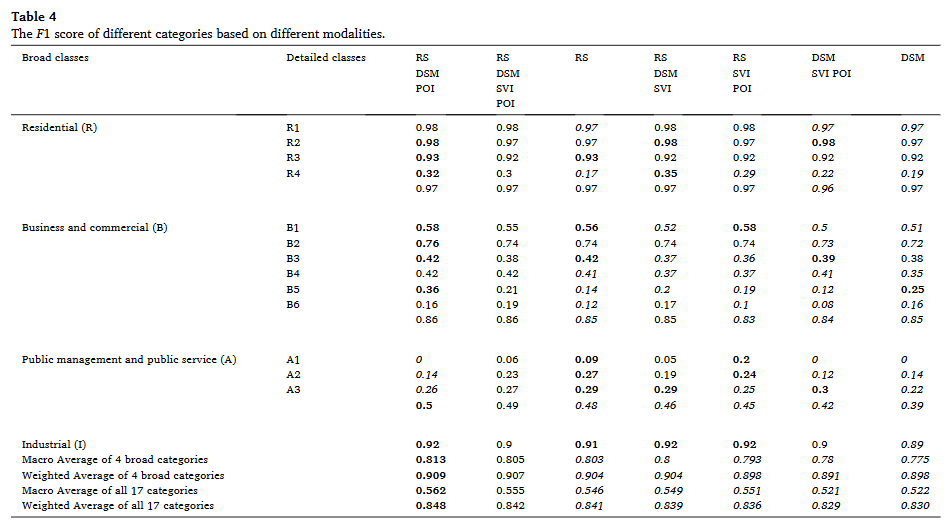
4-2. 서로 다른 모달리티의 기여도 분석
SVI 데이터 제외 효과
- 모든 성능지표가 향상 : MAF와 WAF 모두 0.2~0.8% 증가
- SVI 단독으로는 모델 훈련 불가능
- 결론 : SVI 데이터느 효과적인 정보보다 노이즈를 더 많이 제공
POI 데이터 제외 효과
- 성능 소폭 감소: MAF와 WAF가 0.3~0.6% 감소
- B 카테고리 세부 분류와 A 카테고리에서 정확도 향상에 기여
- POI 가용성이 2.8%로 제한적이지만 유용한 보완 정보 제공
DSM 데이터 제외 효과
- 중간 정도 성능 감소: MAF와 WAF가 0.4~1.2% 감소
- R2, R3, B3, B5 카테고리 분류에 중요한 역할
- DSM 단독 사용 시 상당한 성능 저하 발생
RS 데이터 제외 효과
- 가장 큰 성능 저하: MAF와 WAF가 1.3~3.4% 감소
- RS 단독 사용 시에도 상대적으로 양호한 성능 유지
- 모든 카테고리에서 포괄적이고 영향력 있는 정보 제공
단일 모달리티 성능 분석
| Modality | 성능수준 | 특징 |
|---|---|---|
| RS | 높음 | 광범위 카테고리에 더 많은 정보제공 |
| DSM | 낮음 | 제한적기능 정보만 제공 |
| SVI | 훈련 불가 | 단독으로는 효과적이지 않음 |
| POI | 평가 제외 | 데이터 가용성 부족 |
모달리티 중요도 순위
실험 결과에 따른 기여도 순서 :
1. RS(원격감지 이미지 ) - 핵심 정보원
2. DSM ( 디지털 표면 모델 ) - 보완적 구조정보
3. POI ( 관심지점 데이터 ) - 제한적이지만 유용한 의미 정보
4. SVI ( 거리뷰 이미지 ) - 노이즈 증가요소
- RS 데이터의 중심적 역할
- 계층적 건물 용도 분류의 핵심 요소- 다른 모달리티 없이도 합리적인 성능 유지 가능
- 모든 분류 카테고리에서 강건하고 정보가 풍부함
- DSM과 POI 의 보완적역할
- DSM은 대부분의 정보가 이미 RS에 포함되어 있어 제한적 기여- POI는 가용성이 낮지만 존재할 때 유의미한 향상 제공
- SVI의 역효과
- 노이즈가 유용한 정보보다 많아 오히려 성능 저하 유발- 거리뷰 이미지의 한계와 건물 용도 분류와의 연관성 부족
