Paper Review | Time-LLM : Time Series Forecasting by Reprogramming Large Language Models
시간 시계열 예측(Time Series Forecasting, TSF)은 다양한 현실 세계의 동적 시스템에서 중요한 역할을 한다. 그러나, NLP나 컴퓨터 비전(CV)분야에서는 하나의 대형모델이 여러 작업을 수행할 수 잇는 반면, 시계열 예측 모델은 특정 작업과 응용 사례에 맞춰 개별적으로 설계되어야하는 한계가 있다.
- 시계열 도메인에서는 데이터 부족으로 인해 발전이 제한
- 시계열 데이터와 자연어 간의 모달리티 정렬(alignment)문제
해당 논문에서는 TIME-LLM이라는 LLM Reprogramming Framework를 제안.
LLM의 백본 모델을 변경하지 않고 시계열 예측에 활용하는 방법 제안 :
- 시계열 데이터를 텍스트 프로토 타입(text prototype) 형태로 변환하여, 동결된(frozen) LLM에 입력하여 두개의 모달리티를 정렬.
- Prompt-as-Prefix(PaP) 기법을 도입 : 입력 컨텍스트를 풍부하게하고 변환된 입력 패치의 처리를 유도하여 LLM의 시계열 데이터 추론 능력을 향상.
Source : TIME-LLM Github
Introduction
1. 시계열 예측의 중요성 및 기존 모델의 한계
시계열 예측(Time Seriese Forecasting, TSF)은 수요예측, 재고 최적화, 에너지 부하 예측, 기후 모델링 등 다양한 산업에서 필수적인 역할을한다.
그러나 각각의 TSF작업은 특정 도메인 전문지식과 맞춤형 모델 설계가 필요하여 일반화가 어렵다.
반면, GPT-3, GPT-4, LLaMA 같은 대형 언어 모델(LLM)은 다양한 NLP 작업을 Few-shot 또는 Zero-shot 방식으로 수행할 수 있음.
2. LLM을 활용한 시계열 예측의 가능성
LLM이 시계열 예측을 발전시킬 수 있는 주요 요소 :
1. 일반화 가능성(Generalizability):
- LLM은 Few-shot 및 Zero-shot 학습이 가능 -> 새로운 도메인에 대해 재학습 없이 활용될 가능성.
- 기존 TSF 모델은 특정 도메인에 맞춰져 있어 범용성이 부족
2. 데이터 효율성 (Data Efficiency)
- LLM은 사전 학습된 지식(Pre-trained knowledge)을 활용하여 적은 데이터로도 학습 가능
- 반면, 기본 TSF모델은 대량의 도메인별 데이터를 필요로 함
3. 추론 능력(Reasoning Capability)
- LLM은 복잡한 패턴을 인식하고 논리적으로 추론가능
- TSF 모델은 통계적 접근이 주를 이루며, 고차원 개념을 학습하기 어려움.
4. 멀티모달 학습(Multimodal Knowledge)
- LLM은 텍스트 뿐 아니라 이미지, 음성 등 다양한 데이터 모달리티를 학습가능
- 이러한 특성을 활용하면, 시계열 데이터와 다른 데이터 유형을 함께 결합하여 더 정확한 예척이 가능할 수 있음
5. 최적화 용이성(Easy Optimization)
- LLM은 대규모 학습니 완료된 상태에서 특정작업에 바로 적용가능하고, 하이퍼 파라미터 튜닝을 수행해야함.
3. LLM을 시계열 예측에 활용하는 과제
모달리티 정렬문제(Modality Alignment)
- LLM은 이산적(Discrete)토큰을 기반으로 작동하지만, 시계열 데이터는 연속적(Continuous) 형태를 가짐
- 즉, 시계열 데이터를 LLM이 이해할 수 잇도록 변환하는 과정이 필요.
사전 학습 부족(Lack of Pre-trained Knowledge)
- LLM은 시계열 데이터에 대해 직접적인 학습을 한적이 없음.
- 따라서, LLM이 기존의 학습된 패턴을 활용하여 시계열 데이터를 해석하고 예측하는 방법을 연구해야함.
4. TIME-LLM
Time-LLM : LLM을 시계열 예측에 적용하는 새로운 재프로그램(Reprogramming) v프래임워크
핵심 개념
1. 입력 변환 (Reprogramming Input Time Series)
- 시계열 데이터를 LLM이 이해할 수 있도록 텍스트 프로토 타입(Text Prototype) 형태로 변환
2. Prompt-as-Prefix(PaP)기법
- 단순한 입력 변환을 넘어, LLM이 시계열 데이터를 잘 이해할 수 있도록 도메인 지식 및 작업 지침을 포함한 프롬프트 제공.
5. 연구 기여점
LLM을 변경하지 않고 Reprogramming 시계열 예측에 적용하는 새로운 개념을 제안하여, 시계열 예측을 언어 처리와 유사한 문제로 변환하여 해결 가능한 TIME-LLM 프레임워크 개발하였으며,
Few-shot 및 Zero-shot 시나리오에서도 기존 모델을 초월하는 성능을 보였다. 게다가, 동시에 모델 재사용성이 뛰어나고, 최적화비용이 낮다.
Related Work
TSF모델의 발전과정과 LLM을 활용한 새로운 접근법, 그리고 기존 연구의 세가지 주요방향
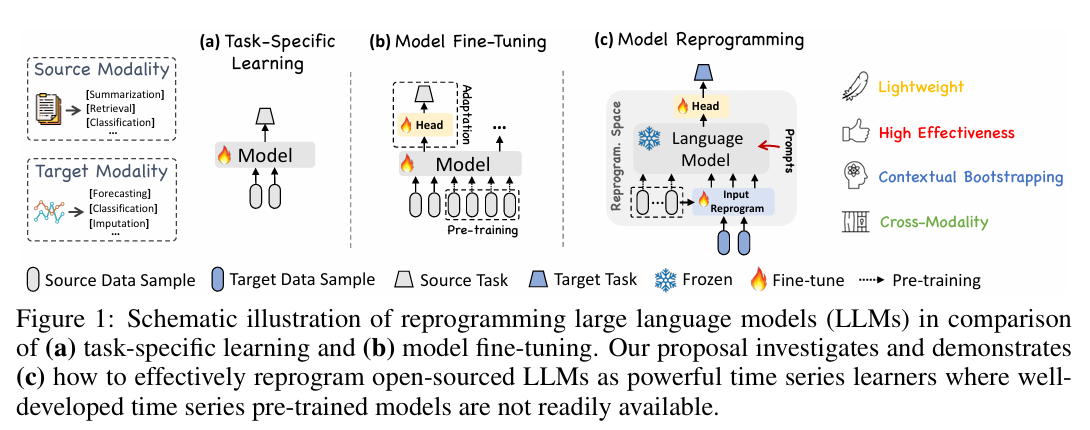
그림 1. LLM을 활용한 시계열 예측 모델의 다양한 접근 방식을 비교
1. Task-Specific Learning(작업특화학습)
대부분의 전통적인 시계열 예측 모델은 특정작업(예 : 교통량 예측, 기후 모델링 등)과 특정 도메인에 맞춰 정용 모델로 설계.
이러한 모델들은 소규모 데이터셋에서 최적화되며, End-to-end 방식으로 훈련.(그림1의 (a)참고)
대표적인 전통적 시계열 예측 모델:
- ARIMA: 단변량 시계열 예측(Univariate TSF)에 특화
- LSTM : 시퀀스모델링(Sequence Modeling)에 활용
- Temporal Convalutional Networks : 장기 시계열 의존성(Long-term dependencies)처리 가능
- Transformers : 최근 트랜스포머 기반 모델로 등장하여 시계열 데이터를 효과적으로 모델링
문제점 : 특정 도메인에 최적화되었기 때문에 범용성이 부족하며, 다양한 종류의 시계열 데이터를 처리하는 능력이 제한된다.
2. In-Modality Adaptation(도메인 내 적용)
NLP 및 CV에서는 사전 학습된 대형 모델을 다양한 하위 작업에 미세조정(fine-tuning)하여 활용하는 방식이 널리 사용.
이러한 성공을 바탕으로 TSPTMs (TimeSeries Pretrained Models, 시계열 사전학습모델)이 연구되기 시작.
TSPTMs의 주요 전략 :
- Supervised Pre-traning
- Self-Supervised Learning
- 활용방식
- 먼저 일반적인 시계열 패턴을 학습 후, 특정 도메인에서 미세조정(fine-tuning)을 수행.
문제점 : TSPTMs는 NLP/CV 분야의 사전 학습 모델과 유사한 구조를 따르지만, 데이터부족 문제로 인해 여전히 작은 규모에서만 활용.
3. Cross-Modality Adaptation(교차도메인 적응)
기존의 NLP 및 CV모델을 시계열 데이터로 전이(Transfer Learing)
하는 연구가 진행
대표적인 연구:
- Voice2Series (Yang et al., 2021) : 음성 인식 모델(Acoustic Model, AM)을 시계열 분류(Time Series Classification)에 적용.
- LLM4TS (Chang et al., 2023) : LLM을 시계열 예측에 적용하기 위해 두 단계로 미세 조정(Fine-tuning)하는 방법을 제안.
1. 시계열 데이터에 대한 지도 학습
2. 특정 작업(Task-specific) 미세 조정 - Zhou et al. (2023a) : LLM의 자기 주의(Self-attention) 및 피드포워드(FNN) 레이어를 변경하지 않고 시계열 분석에 활용하는 연구를 진행.
TIME-LLM과 기존 연구의 차별점
기존 연구들은 대부분 LLM을 시계열 예측에 적용하기 위해 미세조정(Fine-tuning)하거나 입력 데이터 자체를 변경하는 방식을 사용.
TIME-LLM은 이러한 방식과 달리:
- LLM의 백본 모델을 수정하지 않고 그대로 유지
- 시계열 데이터를 자연어와 정렬하기 위해 Reprogramming하는 접근법을 사용(그림1.(c)참고)
- 이를 통해 LLM의 본래 학습된 지식을 활용하여 시계열 예측이 가능하도록 함.
METHODOLOGY 방법론
모델의 구조는 크게 입력변환(Input Transformation), LLM 적용(Pre-trained LLM), 출력변환(Output Projection)으로 구성된다.
Figure 2 : time-llm 모델 구조 설명
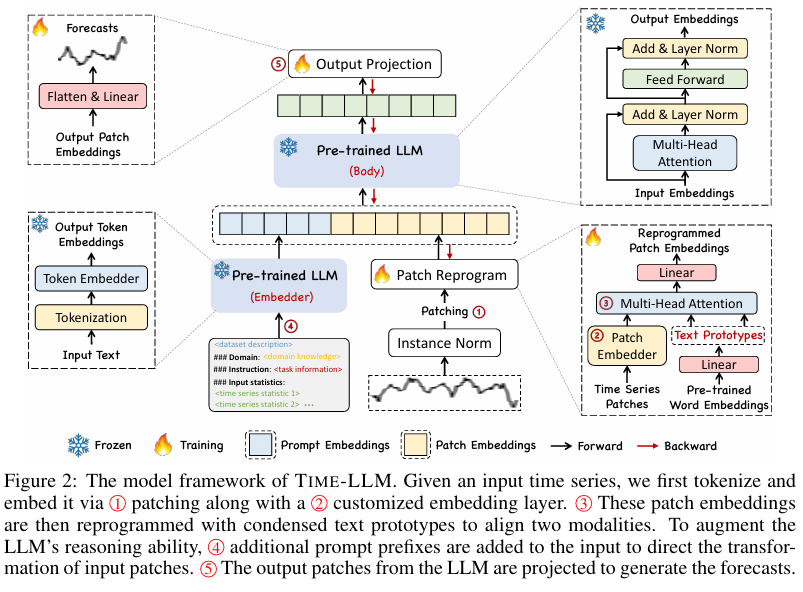
해당 그림은 Time-LLM(Time Series Forecasting using LLM Reprogramming)의 전체적인 모델 프레임워크를 시각적으로 설명. 기존 LLM을 수정하지않고, 시계열 데이터를 자연어 형태로 변환하여 예측하는 방법 제안.
흐름 및 주요 단계 :
-
Patching (패치변환)
- 입력 시계열 데이터는 Patch 단위로 분할.
- Instance Normalization(인스턴스 정규화)를 통해 데이터의 분포를 조정.
- 이후 Patch Embedder를 사용하여 패치를 특정 차원의 벡터로 변환.
-
Patch Embedding(임베딩 변환)
- 패치 데이터를 사용자지정(customized) 임베딩 레이어를 통해 벡터화.
- 이 과정에서 Text Prototypes을 활용하여 시계열 데이터를 자연어 표현과 정렬(Alignment).
-
Patch Reprogram(패치 재프로그램)
- 기존 LLM이 자연어를 처리하는 방식에 맞춰 패치 데이터를 재구성.
- 다중 헤드 어텐션(Multi-Head Attention)과 선형 변환(Linear)을 적용하여, 시계열 데이터를 LLM이 처리할 수 있는 입력 데이터로 변환
-
Prompt-as-Prefix(PaP, 프롬프트 추가)
- LLM이 시계열 데이터를 더 잘 이해할 수 있도록 prompt 추가.
- 프롬프트 구성 :
1. 도메인 지식(domain knowledge) - 해당 데이터의 의미 및 특성 설명- 작업 지시(Task Introduction) - 예측해야할 타임 스텝과 작업 방향을 지정
- 입력통계(Input Statistics) - 최소값, 최대값, 중간값, 추제 정보 제공
-
Output Projection(출력 투영)
- LLM이 생성한 출력을 다시 시계열 데이터 형태로 변환.
- 예측된 결과를 선형변환(Linear Projection) 및 Flatten 과정을 통해 최종 예측값을 도출.
🔥 (불꽃 아이콘) → 학습 과정에서 업데이트되는 가중치 (출력 투영 과정).
❄️ (눈꽃 아이콘) → LLM은 동결된 상태(Frozen) 로 유지되며 변경되지 않음.
파란색 박스 → LLM에서 처리하는 주요 과정 (임베딩, 본체, 출력 등).
노란색 박스 → 패치 변환과 재프로그램 과정 (Patch Reprogram).TIME-LLM은 기존의 Fine-tuning 방식보다 더 범용적이고 효율적인 시계열 예측 방법을 제공한다.
해당 그림은 전체적인 구조 및 데이터 흐름을 한눈에 이해할 수 있도록 정리한 개념도이며, 핵심기법인 Patch Reprogramming과 Prompt-as-Prefix기법을 강조한다.
3.1 모델의 구조(Model Structure)
Input Transformation : 입력변환
1. 시계열 데이터 정규화(Normalization)
- 각 입력 채널 𝑋(𝑖)를 개별적으로 평균 0, 표준편차 1로 정규화하여 시계열 분포 변화를 완화.
- Reversible Instance Normalization(RevIN)을 사용하여 시계열 데이터의 변화에도 적응하도록 함.
2. 패치변환(Patching)
- 시계열 데이터를 고정 길이의 패치 (Patch)단위로 분할
- 연속적인 패치를 구성하여 모델이 로컬 시계열 패턴을 효과적으로 학습하도록 유도
- 패치 수는 다음과 같이 계산된다.
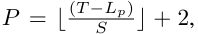
- Lp : 패치 길이
- 𝑆 : 슬라이딩 윈도우 크기
3. 패치 임베딩 (Patch Embedding)
- 분할된 패치를 선형 레이어를 통해 임베딩 벡터로 변환.
- 임베딩 된 패치 데이터를 LLM이 처리할 수 있는 형식으로 변환.
Patch Reprogramming 패치 재프로그래밍
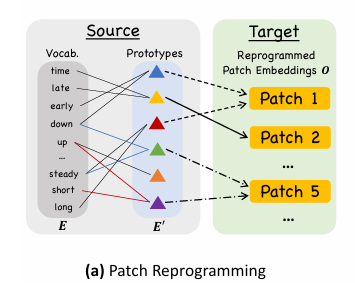
- LLM이 이해할 수 있도록 시계열 데이터를 자연어 형태로 변환
- Text Prototypes을 사용하여 패치 정보 요약.
- Multi-head Cross-Attention을 적용하여 시계열 데이터를 자연어 표현과 정렬(Alignment).
결과적으로, 시계열 데이터는 Text Prototypes를 통해 LLM의 자연어 처리 능력과 정렬됨.
Prompting : 프롬프트 기법
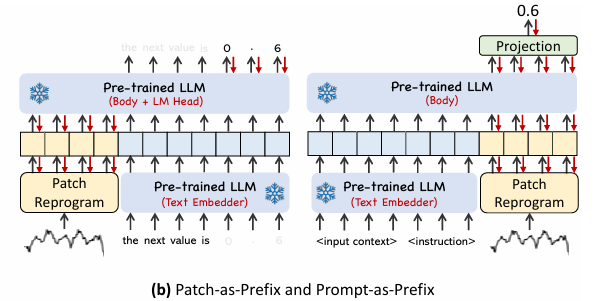
Figure3-2. Patch-as-Prefix VS. Prompt-as-Prefix 두가지 방법비교.
LLM의 예측 성능을 향상시키기 위해 Prompt-as-Prefix(PaP)기법 도입.
1. Patch-as-Prefix
시계열 데이터를 패치 단위로 변환 후, 이를 LLM에 직접 입력하여 다음 값을 예측하도록 학습.
예측값은 숫자(0.6)과 같은 형태로 직접 생성.
- 문제점
1. LLM은 숫자 처리 성능이 낮아 정밀도가 떨어짐.- 토큰화 방식이 다르기 때문에 숫자 출력을 일관되게 변환하기 어려움.
- 해서, 장기 예측이 어려움.
2. Prompt-as-Prefix(PaP)
LLM이 시계열 데이터를 더 효과적으로 학습할 수 있도록 프롬프트 추가
-
패치 변환 후, 추가적인 프롬프트를 입력하여 LLM이 시계열 데이터를 더 효과적으로 학습할 수 있도록 유도
-
출력은 자연어 기반으로 생성된 후, 최종적으로 Projection Layer(출력변환 레이어)를 통해 시계열 예측값으로 변환됨.
프롬프트 구성요소
-
Dataset Context : 데이터의 의미와 특성 제공
- 예 ) "이 데이터는 전력 소비량을 나타내며, 특정 시점에서 급증할 가능성이 있음."
-
Task Instruction : LLM이 수행해야할 예측 작업 정의 - 예측할 타임 스템과 예측 방식 설명
- 예 ) "다음 24시간 동안의 전력 소비량을 예측하시오"
-
Input Statistics : 입력 데이터의 통계 정보 제공
- 예 ) 최소, 최대, 중간값, 변화 추세(upward/downward) 등.
장 점
-
LLM의 논리적 추론 능력 활용 가능
- 숫자 자체를 예측하는 대신 데이터 패턴을 자연어로 이해하고 분석 가능. -
출력의 일관성 향상
- LLM이 수치를 직접 생성하는 것이 아니라, 최적의 변환과정을 거쳐 일관된 예측값을 생성
-
Few-shot, Zero-shot 학습에서 강력한 성능
- LLM이 이미 학습한 다양한 도메인 정보를 활용할 수 있으므로, 데이터가 부족한 환경에서도 성능이 뛰어남.

Figure 4. 프롬프트의 구조
1. [BEGIN DATA]
- 프롬프트가 포함하는 정보의 시작을 알리는 태그.
- 이후 시계열데이터와 관련된 설명 및 통계정보가 포함.
2. 프롬프트 주요 내용
- [Domain] 도메인 설명
- 해당 데이터가 의미하는 바를 설명하여 LLM이 데이터를 이해할 수 있도록 도움.
- 해당 예제에서는 전력 소비량(Electricity consumption)이 정오(Noon) 시간대에 최고치(Peak)에 도달한다는 정보 제공.
- 도메인 지식이 포함됨으로써 LLM이 시계열 데이터의 패턴을 추론하는데 도움이 됨.
- [Instruction] 작업지시
- LLM이 수행해야할 예측 작업을 설명
- 해당그림 :
```py
"이전 <T> 스탭(시간)의 데이터를 보고, 다음 <H> 스텝을 에측하라"
- 여기서 `<H>`와 `<T>`는 특정한 숫자로 대체될 변수(Task-specific configurations).
```
- `[Statistics]` 입력 데이터 통계
- 시계열 데이터의 수치적 특징을 제공하여 모델이 패턴을 쉽게 인식할 수 있도록 함.
- 제공되는 주요 통계 정보 :
1. `<min_val>` 최소값
2. `<max_val>` 최대값
3. `<median_val>` 중앙값
4. `<upward> or<downward>`전체적인 추세
5. `<lag_val>` 가장 중요한 상위 5개의 지연값[END DATA]종료 테그
PaP 기법을 활용하면, LLM이 더 효과적으로 시계열 패턴을 분석하고 예측 가능
Output Projection : 출력 반환
- LLM에서 생성된 출력을 다시 시계열 데이터 형태로 변환
- 출력투영 레이어(Projection Layer) 를 사용하여 예측값을 생성.
- LLM의 자연어 출력을 정량적 예측값으로 변환하는 역할.
MAIN RESULTS
TIME-LLM은 다양한 벤치마크와 실험 설정에서 최신 SOTA 시계열 예측 모델을 뛰어 넘는 성능을 기록했다. 특히 Few-shot 및 Zero-shot 학습 시나리오에서도 우수한 성능을 보였다.
Baselines : 비교모델 및 실험 설정
- 비교모델
- Transformer 기반 시계열 예측 모델; PatchTST(2023), ESTformer(2022), FEDformer(2022), Autoformer(2021), Informer(2021), Reformer(2020)
- 최근 경쟁모델 : GPT4TS(2023a), LLM Time(2023), DLinear(2023), TimesNet(2023), LightTS(2022a)
- 단기 예측 에서는 N-HiTS (2023b), N-BEATS(2020)와 비교. - 백본 모델 : Llama-7B
- 평가방법 : 실험설정을 통일하여 Wu et al. 2023의 실험 구성을 따름.
4.1 Long-term Forecasting : 장기 시계열 예측 성능
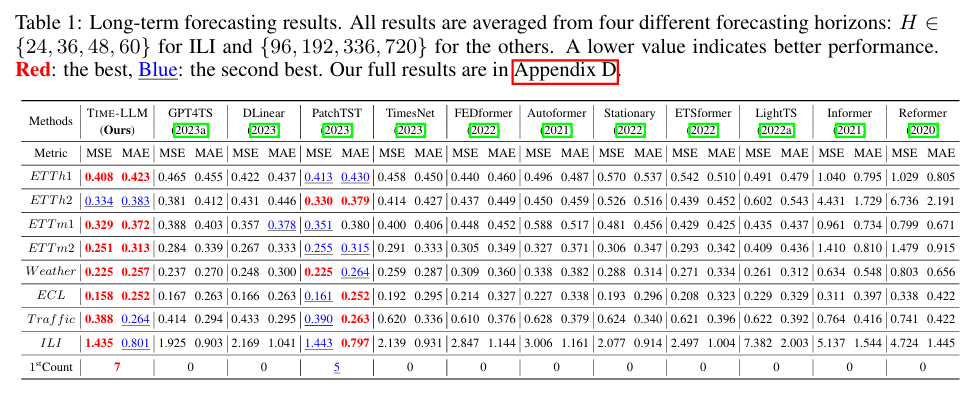
- 8개 벤치마크 데이터셋에서 평가(ETT, Weather, ECL, Traffic, ILI 등)
- TIME-LLM이 대부분의 모델보다 낮은 MSE, MAE 기록
- GPT4TS 대비 12%, TimesNet 대비 20%, PatchTST 대비 1.4% 성능 향상
4.2 Short-term Forecasting : 단기 예측
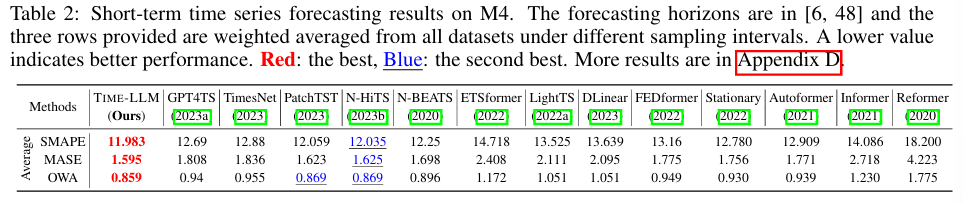
- M4 벤치마크 데이터셋에서 평가
- GPT4TS 대비 8.7% 성능 향상, N-HiTS와도 경쟁가능
4.3 Few-shot Forecasting : 소량 데이터 예측
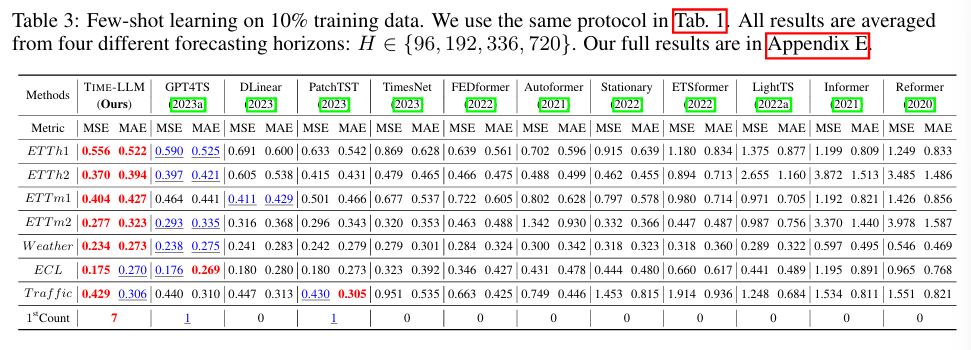
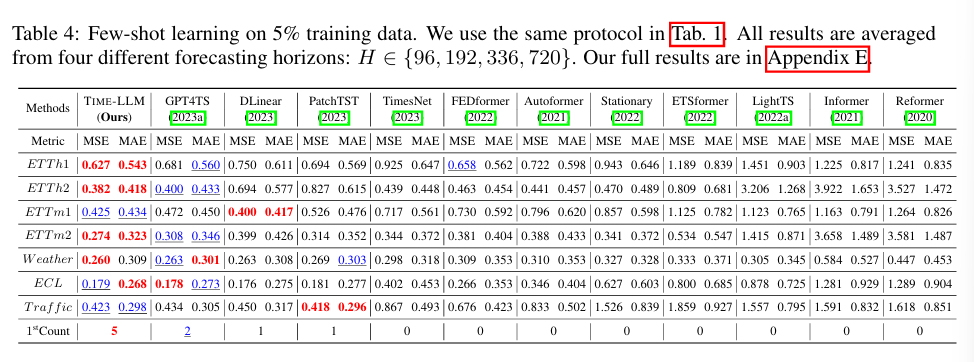
- Table3 & Table4에서 간단하게 10% 및 5% 데이터만 사용한 예측 실험
- GPT4TS 대비 평균 5% MSE 감소, PatchTST, DLinear, TimesNet 대비 8~33% 성능 향상
4.4 Zero-shot Forecasting : 도메인 적응력 테스트
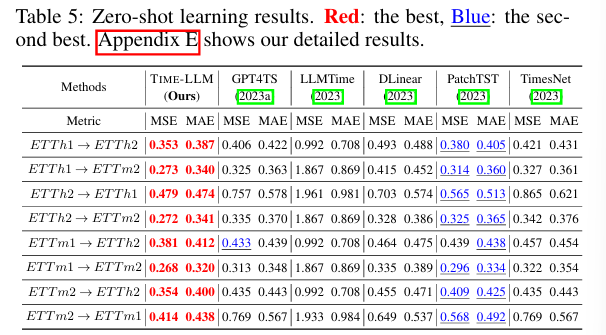
- 처음보는 데이터셋에서 모델 성능 평가
- MSE 기준 14.2% 개선, GPT4TS 대비 22% 성능 향상
- 비슷한 크기의 LLMTime(7b) 대비 7% 성능 향상
4.5 Model Analysis : 모델 분석
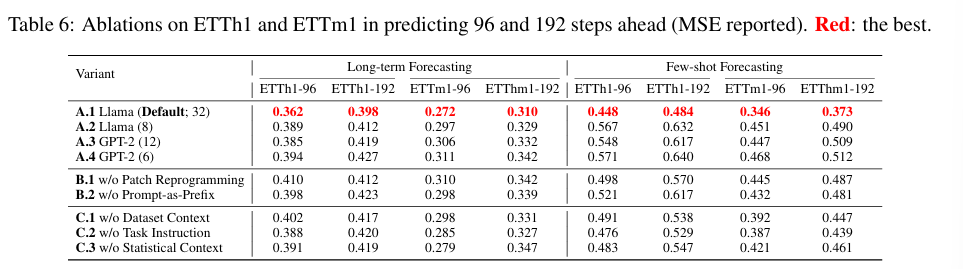

- Llama-7B가 소형모델보다 14.5% 성능 우위
- Patch Reprogramming & Prompt-as-Prefix 제거 시 9~19% 성능 저하.
- 6.6M 파라미터만 학습, 전체 Llama-7B의 0.2% 수준으로 경량화.
Figure 5. A Showcase of Patch Reprogramming
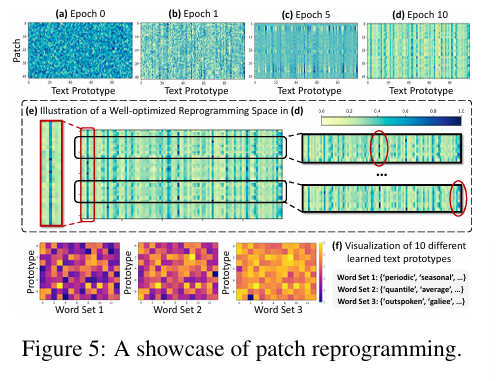
- TIME-LLM의 패치 재프로그래밍(Patch Reprogramming) 과정을 시각적으로 보여준다.
- (a)~(b) 학습 진행 단계(Epoch 0 -> 10)
- (a) Epoch 0 : 무작위 초기화된 패치 임배딩(Random Initialization)- (b) Epoch 1 : 초기 학습이 진행되며 패턴이 일부 형성
- (c) Epoch 5 : 더욱 구조화된 패턴이 나타남
- (d) Epoch 10 : 최적화된 패치 임베딩으로 정렬
- 결론 : 학습이 진행될 수록 패치들이 최적화되며, 특정한 패턴을 따르게됨.
- (e) 최적화된 패치 재프로그램 공간
- 입력 시계열 데이터 패치(행) -> 특정한 텍스트 프로토타입(열)과 매핑- 일부 프로토타입(열)이 특정한 패치(행)에만 강하게 반응.
- 즉, 일부 중요한 텍스트 프로토타입만이 특정 패치에 높은 연관성을 가지며 활성화됨.
- 결론 : 텍스트 프로토 타입이 단순한 변환이 아니라 시계열 데이터의 특정 패턴을 요악하는 역할을 수행.
- (f) 학습된 텍스트 프로토 타입 시각화
- Word Set 1 :('periodic', 'seasonal', ...)-> 주기적, 계절적 패턴 표현- Word Set 2:
('quantile', 'average', ...)→ 통계적 요약값을 표현.
- Word Set 3:('outspoken', 'galilee', ...)→ 추가적인 의미적 연관성을 가지는 프로토타입.- 각 텍스트 프로토타입은 특정한 시계열 특성을 반영하며, 데이터의 의미적 요약을 돕는다.
- Word Set 2:
최종 해석
- Patch Reprograming 은 단순한 데이터 변환이 아니라, 시계열 데이터를 이해하는 방식으로 동작.
- 학습이 진행됨에 따라 특정 패치가 특정한 텍스트 프로토 타입과 강하게 매칭되며 최적화됨.
- 이는 LLM이 시계열 데이터를 해석할 수 있도록 돕는 중요한 과정으로, 자연어 모델이 시계열 데이터를 효과적으로 처리할 수 잇도록 유도.
Time LLM은 Text Prototypes를 활용하여 시계열 데이터의 패턴을 학습하며, 이를 통해 기존 모델보다 더 강력한 일반화 성능을 갖게 된다.
CONCLUSION
TIME-LLMdms 기존의 LLM을 수정하지 않고도 시계열 예측에 적용할 수 잇는 강력한 프레임워크임을 입증
- Patch Reprogramming을 통해 시계열 데이터를 LLM이 이해할 수 있는 텍스트 프로토타입으로 변환
- Prompt-as-Prefix 기법을 사용하여 LLM의 논리적 추론 능력을 강화, 기존의 전문 시계열 모델보다 더 높은 성능 기록
- 이를 통해 시계열 예측을 자연어처리(NLP)문제처럼 다룰 수 있으며, LLM을 활용한 새로운 접근 방식이 가능함을 시사.
향후 연구방향
- 최적의 Reprogramming 기법 연구
- 현재보다 더 정교한 데이터 변환 방식 탐색 - LLM의 지속적인 사전학습(Pre-training)연구
- LLM이 시계열 데이터를 더 잘 이해할 수 있도록 특정한 도메인 지식을 추가학습 - 멀티모달(Multimodal) 모델로 확장
- 시계열 데이터 뿐만 아니라 자연어, 이미지, 음성 등과 결합하여 종합적인 분석 모델 구축 - LLM을 활용한 다양한 시계열 분석 적용
- 예측 뿐만 아니라 이상탐지, 분류, 시계열 데이터 생성 등 다양한 활용 가능성 탐색.
: TIME-LLM은 Fine-tuning 없이도 LLM을 시계열 예측에 적용할 수 있는 강력한 방법론을 제시하며, 향후 더욱 정교한 재프로그램 방식과 멀티모달 확장을 통해 더 넓은 분석 능력을 갖춘 모델로 발전할 가능성이 크다.
