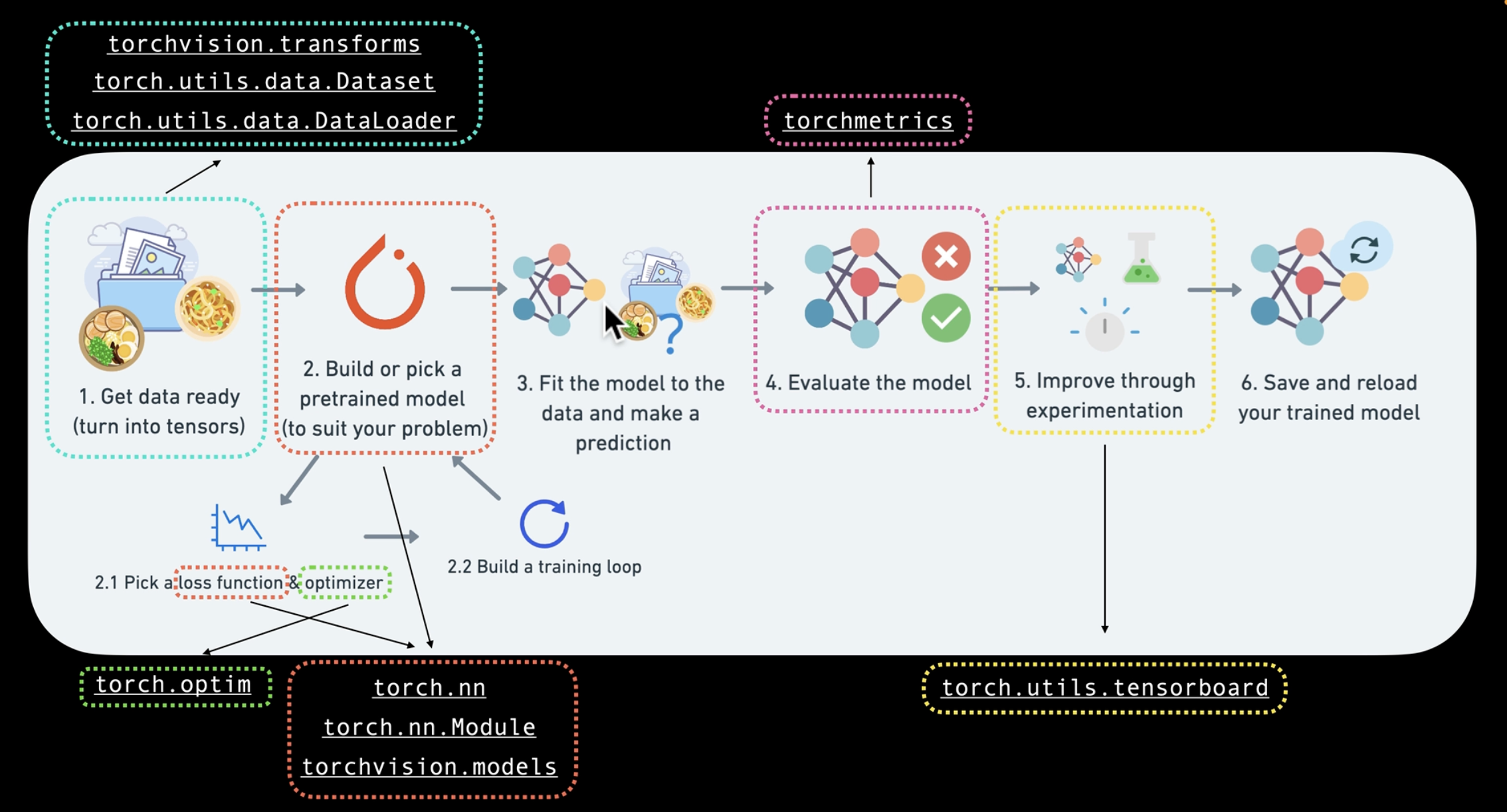
PyTorch Workflow
Let's explore an example PyTorch end-to-end workflow
Resources :
- Ground truth notebook : https://github.com/mrdbourke/pytorch-deep-learning/blob/main/01_pytorch_workflow.ipynb
- Book version of notebook : https://www.learnpytorch.io/01_pytorch_workflow/
- Ask a Question : https://github.com/mrdbourke/pytorch-deep-learning/discussions
What were covering
- 'data(prepare and load)',
- 'build model',
- 'fitting the model to data(training)',
- 'making predictions and evaluting a model (inference)',
- 'saving and loading a model',
- 'putting it all together'
Preparing loading data
머신러닝에서의 데이터는 거의 모든것이 될 수있다.
- excel spreadsheet
- images of any kind
- videos (YouTube has lots of data)
- audio like songs or podcasts
- DNA
- Text
Machine learning is a game of two parts :
- 데이터를 숫자 표현으로 변환
- 해당 숫자 표현으로 패턴을 학습하는 모델을 구축
- Linear Regression(선형 회귀)
- 선형 회귀는 가장 단순한 지도 학습(Supervised Learning) 알고리즘 중 하나이다.
- 주어진 데이터를 기반으로 독립 변수 X 와 종속 변수 y 사이의 선형 관계를 찾는 모델

import torch
# 1. 가중치와 편향 설정
weight = 0.7 # b
bias = 0.3 # a
# 2. 데이터 생성 (입력값 X)
start = 0
end = 1
step = 0.02
X = torch.arange(start, end, step).unsqueeze(dim=1)
y= weight * X + bias
# 3. 출력값 Y 계산
y = weight * X + bias # 선형 회귀 공식 적용
# 4. 데이터 확인
print("X:", X[:10]) # X의 처음 10개 값
print("y:", y[:10]) # y의 처음 10개 값
print("X 길이:", len(X))
print("y 길이:", len(y))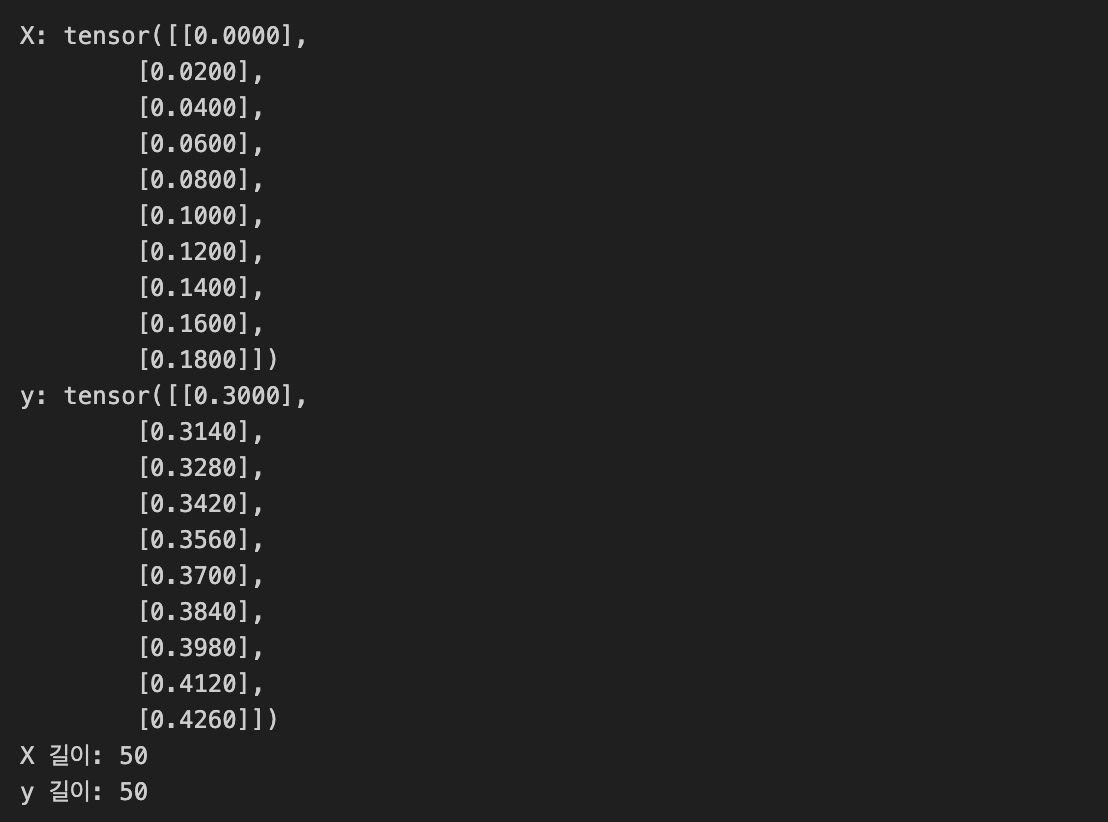
1. Data 세트 분할 : Training Data & Test Data
데이터를 훈련 세트와 테스트 세트로 분할하는 것은 가장 중요한 개념 중 하나이다.
Three datasets : 데이터를 세 가지 데이터 세트로 분할
- Training set : 모델을 학습하는 데 사용되는 데이터 (60-80%)
- Validation set : 모델을 평가하는 데 사용되는 데이터 (10-20%)
- Test set : 모델을 평가하는 데 사용되는 데이터 (10-20%)
# Create a train/test split
train_split = int(0.8 * len(X))
X_train, y_train = X[:train_split], y[:train_split] # 훈련 세트로 분할
X_test, y_test = X[train_split:], y[train_split:] # 테스트 세트로 분할
len(X_train), len(y_train), len(X_test), len(y_test) # 훈련 세트와 테스트 세트의 길이 출력
Visualize
데이터를 어떻게 하면 더 잘 시각화할 수있을까?
Visualize !
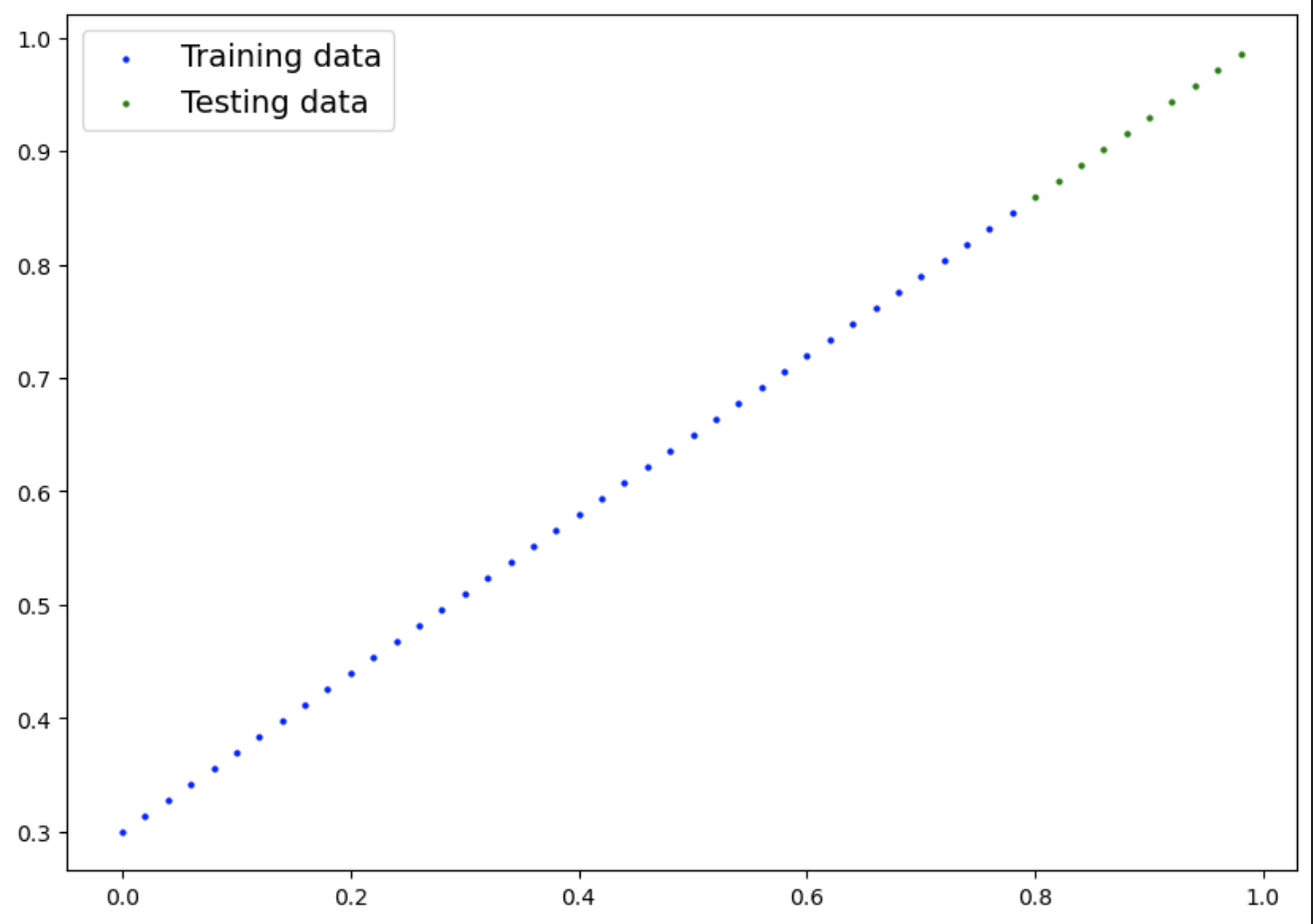
import matplotlib.pyplot as plt
def plot_predictions(train_data=X_train,
train_labels = y_train,
test_data = X_test,
test_labels = y_test,
predictions = None):
"데이터를 테스트하고 예측하고, 비교"
plt.figure(figsize=(10,7))
# plot training data in blue
plt.scatter(train_data, train_labels, c="b", s = 4, label="Training data")
# plot test data in green
plt.scatter(test_data, test_labels, c="g", s = 4, label="Testing data")
# Are there predictions?
if predictions is not None:
# plot the predictions in red if they exist
plt.scatter(test_data, predictions, c="r", s = 4, label="Predictions")
# Show the legend
plt.legend(prop={"size": 14})
plot_predictions()
2. Building a model
My first PyTorch model !
OOP(객체 지향 프로그래밍) : Object-Oriented Programming in Python
following resource from Real Python : https://realpython.com/python3-object-oriented-programming/
What my model does :
- 무작위 값(무게와 편향)으로 시작한다.
- 훈련 데이터를 살펴보고 무작위 값을 조정하여 이상적인 값(데이터를 생성할 때 사용한 가중치 및 편향 값)을 더 잘 표현하거나 더 가깝게 만든다.
How does it do so? :
- Gradient descent 경사하강법
- Backpropagation 역전파
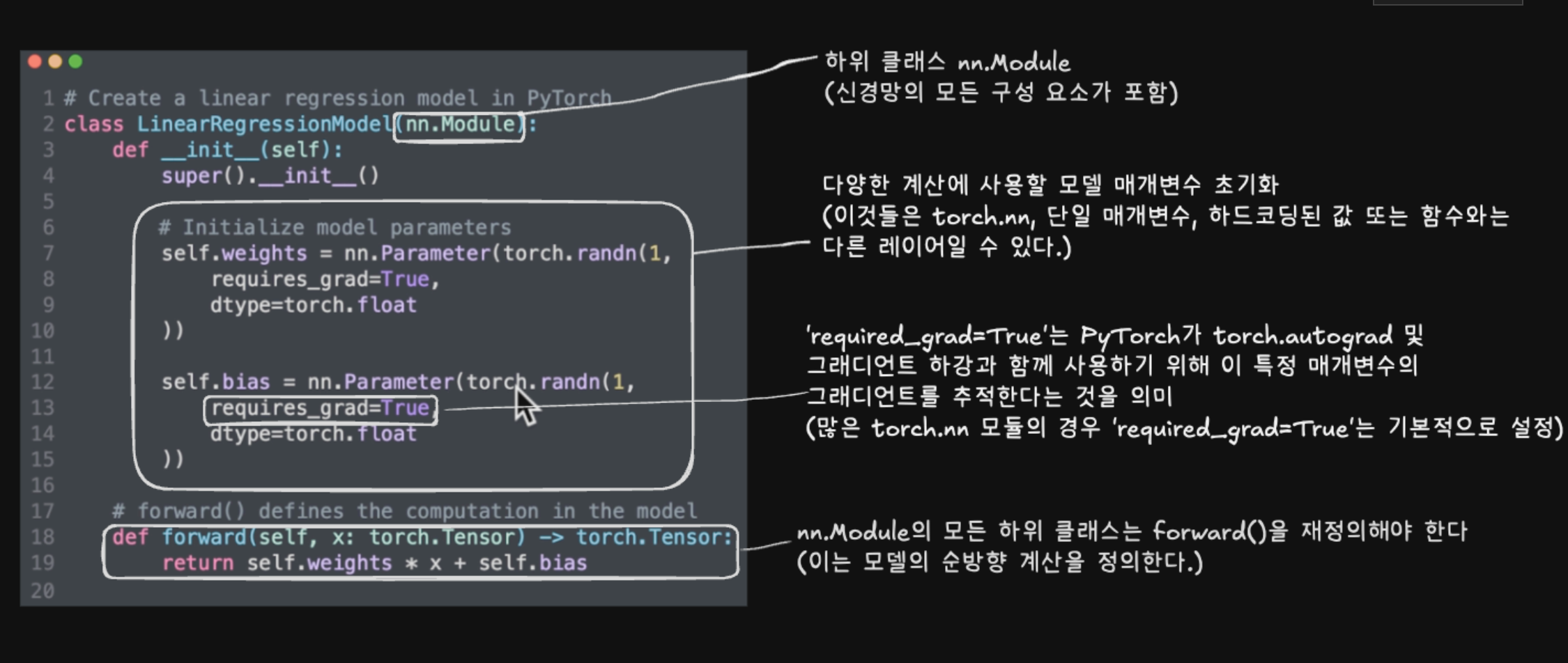
from torch import nn
# Create linear regression model class
class LinearRegressionModel(nn.Module): # PyTorch의 거의 모든 것은 nn 모듈에서 상속되므로 nn.Module을 상속해야 한다.
def __init__(self):
super().__init__()
self.weights = nn.Parameter(torch.randn(1,
requires_grad=True,
dtype=torch.float))
self.bias = nn.Parameter(torch.randn(1,
requires_grad=True,
dtype=torch.float))
# Forward method to define the computation in the model : 모델에서 메소드를 정의하는 방법
def forward(self, x: torch.Tensor) -> torch.Tensor: # <- "x"는 입력 데이터를 나타내는 텐서
return self.weights * x + self.bias # 선형회귀 공식 적용
PyTorch model building essentials
- torch.nn : 그래프 계산을 위한 모든 것을 포함한다.(뉴럴 네트워크)
- torch.nn.Parameter : 모델이 학습하려고 시도해야 할 매개변수는 무엇이며, 종종
torch.nn의 PyTorch 레이어가 이를 설정한다. - torch.nn.Module : 모든 신경망 모듈의 기본 클래스를 하위 클래스로 분류할 경우
forward()을 써야한다. - torch.optim : PyTorch의 옵티마이저들이 있는 곳, 경사 하강에 도움이 된다.
- def forward() : 모든
nn.Module하위 클래스는forward()를 덮어쓰도록 요구. 이 메서드는 forward 계산에서 발생하는 일을 정의합니다
Checking the contents of the PyTorch model
model.parameters()를 사용하여 모델 매개변수 또는 모델 내부의 내용을 확인할 수 있다.
# Create a random seed
torch.manual_seed(42) # 랜덤 시드 고정
# Create an instance of the model (this is a subclass of nn.Module)
model_0 = LinearRegressionModel()
# 모델의 내부 매개변수를 확인
list(model_0.parameters())
# 매개변수 이름과 값을 딕셔너리 형태로 확인
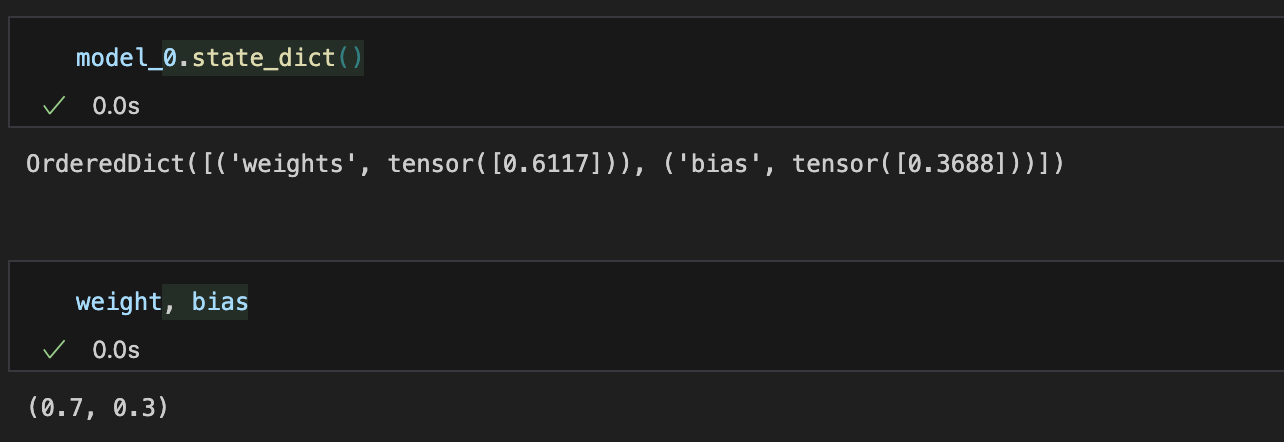
model_0.state_dict()
- 초기 가중치와 편향은 랜덤 값으로 설정된다.
랜덤 초기화의 이유
- 머신러닝 모델은 초기에는 랜덤한 가중치와 편향으로 시작.
- 학습 데이터를 통해 이 값을 점차 최적화하여 데이터의 패턴을 학습.
- 딥러닝의 핵심:
1. 임의의 값으로 시작.
2. 학습 과정을 통해 이상적인 값에 점진적으로 근접.
랜덤 시드의 중요성 : manual_seed()q
- 동일한 환경에서 재현 가능한 결과를 보장.
- 랜덤 시드를 설정하지 않으면, 같은 코드를 실행하더라도 다른 결과가 나올 수 있음.
랜덤 시드 설정 전후 비교
- 랜덤 시드 설정 전:
- 실행할 때마다 다른 초기 값이 생성. - 랜덤 시드 설정 후:
- 항상 동일한 초기 값이 생성.
PyTorch 에서 모델 초기화와 추론 모드(inference mode)
1. PyTorch 모델의 초기화
- 딥러닝의 전제
초기에는 임의의 값(가중치와 편향)으로 시작.
데이터를 기반으로 점진적으로 이상적인 값으로 수렴.
모델 초기 상태 예측
- 모델이 무작위 값으로 초기화되었기 때문에, 예측 결과도 무작위일 가능성이 높음.
- 모델의 성능을 향상시키기 위해 훈련 데이터를 활용하여 매개변수를 조정.
모델 초기 상태에서 예측하기
torch.no_grad()또는torch.inference_mode()를 사용하여 예측을 수행:
# Make predictions with the model
with torch.inference_mode():
y_preds = model_0(X_test)
# torch.no _grad(),으로 비슷한 작업을 수행할 수도 있지만, inference_mode()을 선호한다.
with torch.no_grad():
y_preds = model_0(X_test)
y_preds
Visualize with prediction
plot_predictions(predictions=y_preds)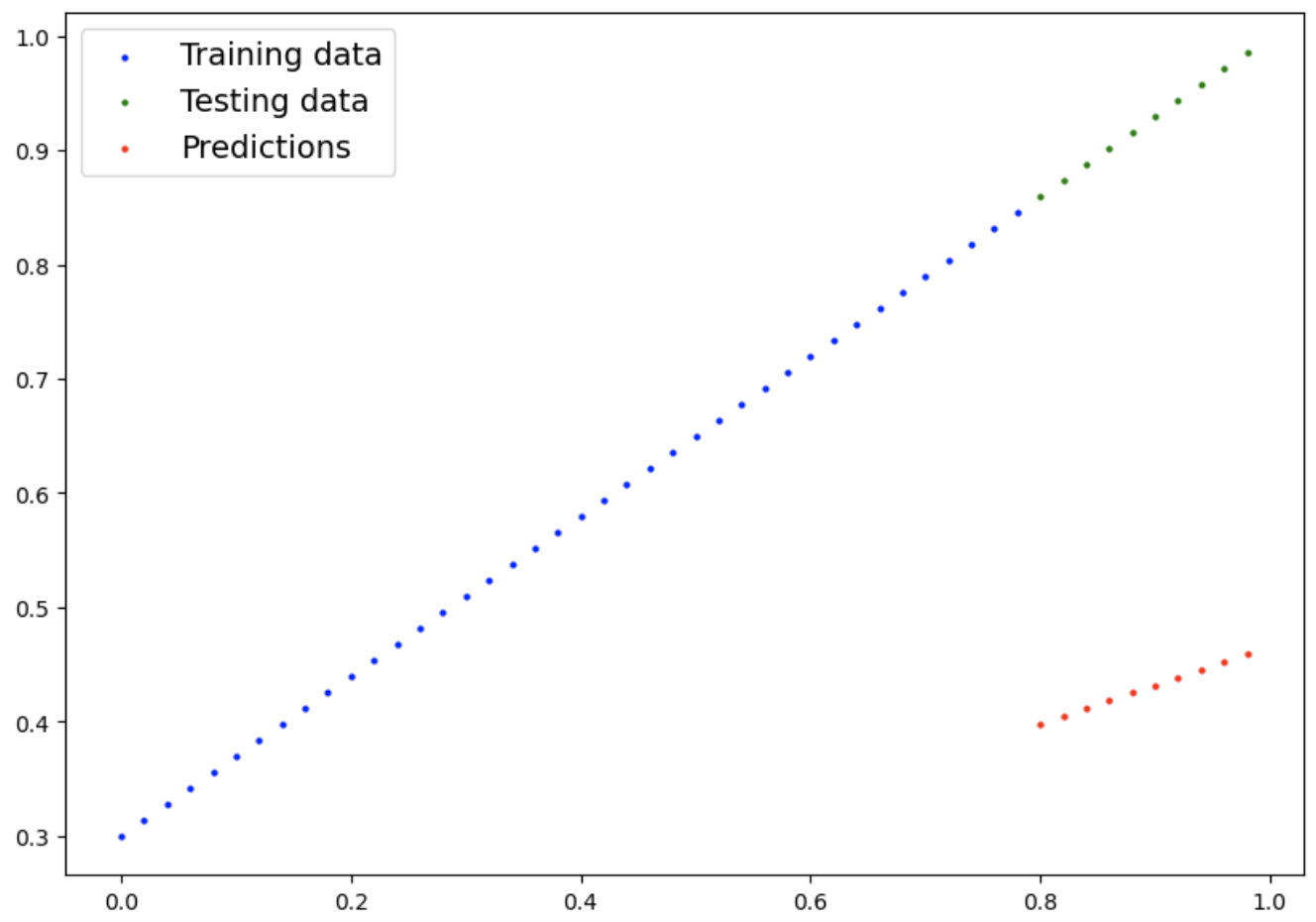
2. Inference Mode
추론 모드란?
- 컨텍스트 관리자로, 모델이 추론(예측)할 때 사용.
- 모델의 매개변수(가중치와 편향)를 업데이트하거나 기울기(gradient) 를 추적하지 않음.
- 메모리 사용량을 줄이고 실행 속도를 높임.
왜 추론 모드를 사용하는가?
- 기울기 추적 비활성화
- 모델의 매개변수를 업데이트하지 않으므로, 기울기 계산 및 추적 불필요.
- 메모리와 계산 자원을 절약. - 속도 향상
- 특히 대규모 데이터 세트에서 예측 성능이 크게 향상. - 메모리 최적화
- 필요하지 않은 데이터를 저장하지 않음.
3. Train model
훈련의 전체 개념은 모델이 어떤 알 수 없는 매개변수(이들은 무작위일 수 있음)에서 어떤 알 수 있는 매개변수로 이동하는 것이다. 데이터의 잘못된 표현에서 좋은 표현으로 이어지는 다른 최악의 상황에서도 마찬가지이다.
Loss Function(손실함수) & Optimizer(최적화
모델 예측이 얼마나 부실하거나 얼마나 잘못된지 측정하는 한 가지 방법은 loss function(손실 함수)를 사용하는 것이다.
- Note : 손실 함수는 다양한 영역에서 비용 함수 또는 기준이라고도 할 수 있다. 우리의 경우 손실 함수라고 부른다.
Thins we need to train:
- Loss function : 모델의 예측이 이상적인 출력에 얼마나 잘못된지를 측정하는 함수로, 낮을수록 좋다.
- Optimizer : 모델의 손실을 고려하고, 모델의 매개변수(우리 경우에는 가중치와 편향)를 조정하여 손실 함수를 개선한다.
PyTorch에 특정하게, 우리는 다음을 필요로 한다:
- A training loop
- A testing loop
손실함수 L1 Loss (Mean Absolute Error)
nn.L1Loss()- 두 값 간의 절대적 차이의 평균을 계산.
- 회귀 문제에서 자주 사용.
최적화 SGD (Stochastic Gradient Descent)
torch.optim.SGD()- 확률적 경사 하강법.
- 무작위로 매개변수를 조정하여 손실을 줄임.
# Setup a loss function
loss_fn = nn.L1Loss()
# Set up an optimizer(stochastic gradient descent)
optimizer = torch.optim.SGD(params = model_0.parameters(),
lr = 0.01) # lr = learning rate(학습률) = 설정할 수 있는 가장 중요한 하이퍼파라미터Learning Rate
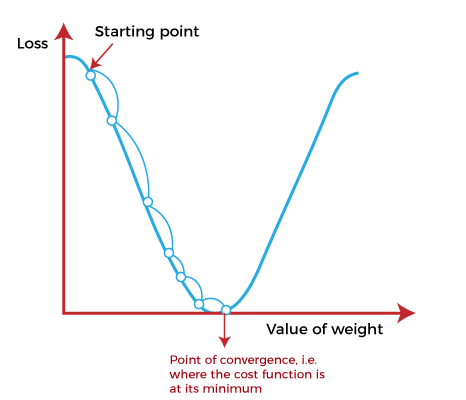
- 학습률: 매개변수 업데이트의 크기를 조정하는 하이퍼파라미터.
- 큰 학습률 → 빠르게 업데이트(과도한 움직임 가능).
- 작은 학습률 → 천천히 업데이트(수렴이 느림).
학습률 스케줄링
- 학습 초기에 큰 스텝으로 시작하고, 이후 점차 줄여 더 세밀하게 업데이트.
- 비유: 소파 뒤에서 동전을 찾는 과정처럼, 동전에 가까워질수록 보폭을 줄임.
PyTorch의 훈련 루프는 머신 러닝 모델의 성능을 점진적으로 개선하는 핵심 과정이며, 손실 함수와 최적화를 활용하여 모델의 매개변수를 조정한다. 경사 하강법과 학습률 스케줄링을 통해 더 나은 결과를 도출한다.
PyTorch에서 훈련 루프 구축
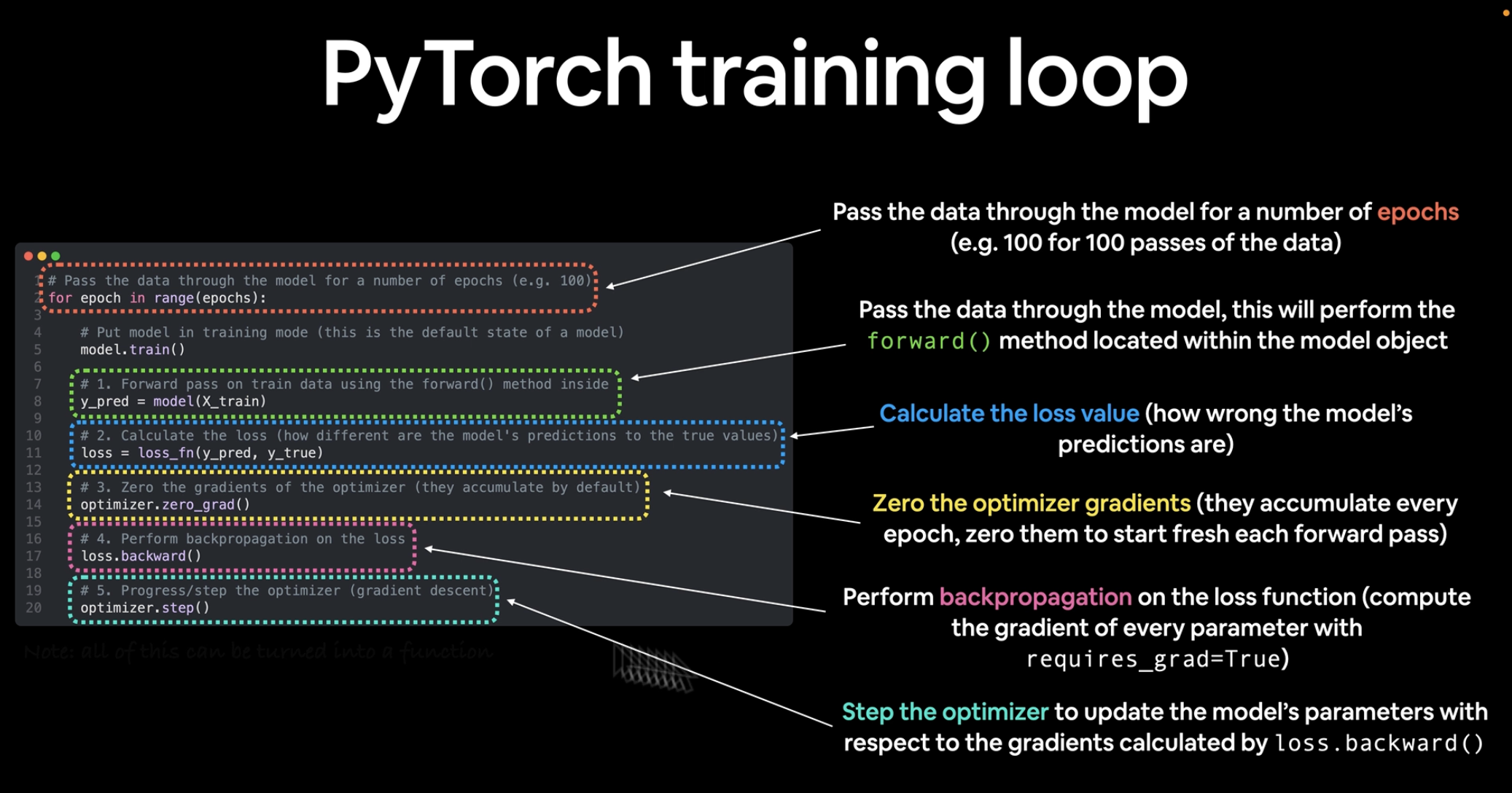
훈련 루프에 필요한 5단계
0. training loop : 데이터를 반복문으로 처리
1. forward pass : 데이터를 모델의 forward() 함수를 통해 전달하여 예측을 수행하는 전방 전달 과정 - 전방 전파라고도 함
- 입력 → 출력으로 데이터가 이동하는 과정.
2. calculate loss(손실함수 계산) : 전방 전달 예측과 실제 라벨을 비교
- 손실 함수로 예측 값과 실제 값 간의 차이를 계산.
- 목표: 손실 값을 줄이는 방향으로 매개변수 조정.
3. optimizer zero grad(최적화 함수 초기화) : 매 에포마다 누적되므로, 각 전방 전달마다 새로 시작하도록 0으로 설정.
- 초기화를 하지 않으면 그래디언트가 누적되어 잘못된 업데이트가 발생한다.
4. loss backward(손실 역전파) : 손실에 대한 모델의 각 매개변수에 대한 기울기를 계산하기 위해 네트워크를 역방향으로 이동(역전파(backpropagation))
- 손실 값을 기준으로 각 매개변수(가중치, 편향)의 그래디언트를 계산.
- 기술 용어: 경사 하강법(Gradient Descent)을 위한 그래디언트 계산.
5. optimizer step(최적화 함수 단계) : 최적화 함수를 사용하여 손실을 개선하려고 모델의 매개변수를 조정(경사 하강(gradient descent))
# epochs : 데이터를 반복하는 것 (이것은 우리가 직접 설정했기 때문에 하이퍼파라미터라고 한다.)
epochs = 1
# 0. 데이터를 반복문으로 처리
# 데이터를 모델을 통해 일정 횟수(예: 100회의 데이터 통과)의 에포크를 수행
for epoch in range(epochs):
# 모델을 훈련 모드로 설정
model_0.train()# PyTorch의 훈련 모드는 모든 기울기를 필요로 하는 매개변수를 훈련으로 설정.
# 1. forward pass
# 모델의 `forward()` 메서드를 수행하여 데이터를 모델을 통해 전달.
y_preds = model_0(X_test)
# 2. Calculate the loss
# 모델의 예측이 얼마나 잘못되었는지에 대한 손실 값을 계산.
loss= loss_fn(y_preds, y_test)
print(f"Loss: {loss}") # 손실 값 출력
# 3. optimizer zero grad (최적화 함수 초기화) : 매 에포마다 누적되므로, 각 전방 전달마다 새로 시작하도록 0으로 설정.
optimizer.zero_grad()
# 4. loss backward
# 손실 함수에 대한 역전파를 수행합니다( `requires_grad=True`인 모든 매개변수의 기울기를 계산합니다)
loss.backward()
# 5. optimizer step
# `loss.backward()`로 계산된 기울기에 따라 모델의 매개변수를 업데이트하는 최적화 함수를 단계를 진행
optimizer.step() # 루프를 통해 최적화가 누적되므로 다음 루프 반복을 위해 3단계에서 이를 초기화.
model_0.eval() # 기울기 추적 종료.
# 모델의 매개변수 출력
print(model_0.state_dict())

- 위 에폭을 여러번 실행하다보면 Loss는 계속 줄어들고 가중치와 편향 값이 올라가는 것을 볼수있다.
# 새로운 예측 생성
with torch.inference_mode():
y_preds_new = model_0(X_test)
# 새로운 예측 시각화
plot_predictions(predictions=y_preds_new)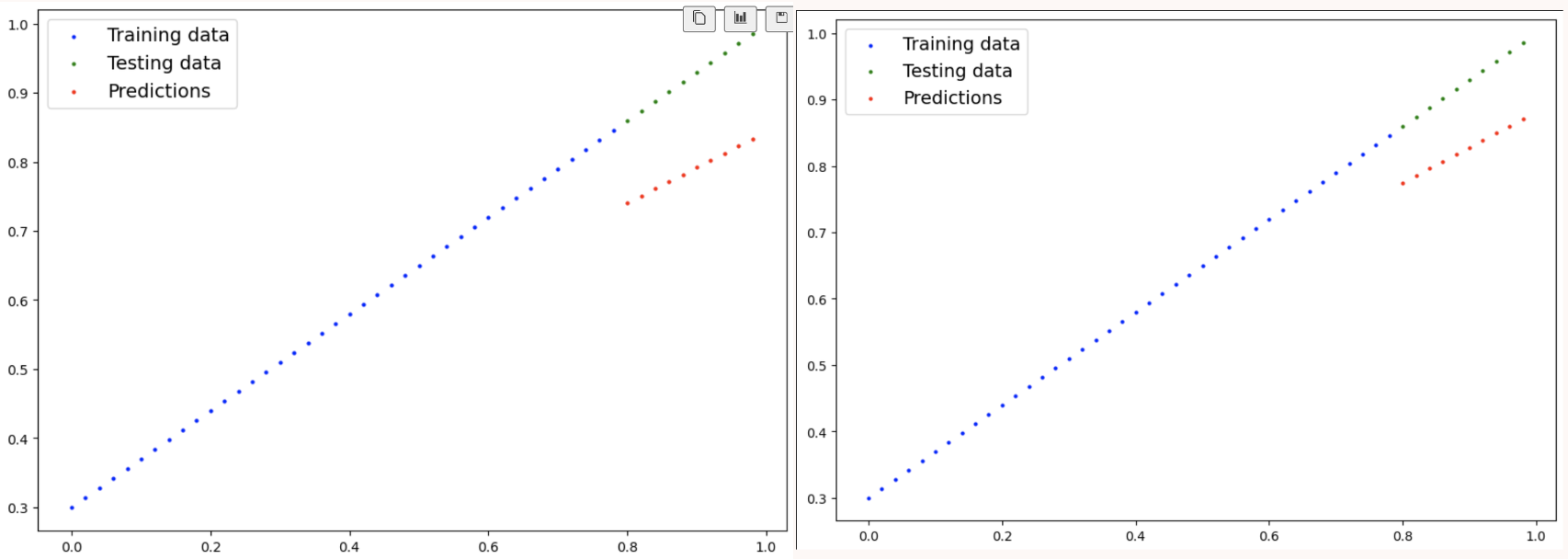
- 예측을 다시 시각화 해보면 맨 처음과 달리 점점 testing data와 값이 비슷해지는 것을 눈으로 확인 가능하다.
Testing Loop + Inference Mode

- 더 빠른 성능을 위해 추론 모드를 추가하는 것이 좋다.
torch.manual_seed(42) # 랜덤시드 설정(재현성을 위해)
# epochs : 데이터를 반복하는 것 (이것은 우리가 직접 설정했기 때문에 하이퍼파라미터라고 한다.)
epochs = 200
# Track different values
# 모델 진행 상황을 추적하는 데 도움이 되는 유용한 값을 저장하는 빈 리스트를 생성
epoch_count = []
loss_values = []
test_loss_values = []
# 0. 데이터를 반복문으로 처리
# 데이터를 모델을 통해 일정 횟수(예: 100회의 데이터 통과)의 에포크를 수행
for epoch in range(epochs):
# 모델을 훈련 모드로 설정
model_0.train()# PyTorch의 훈련 모드는 모든 기울기를 필요로 하는 매개변수를 훈련으로 설정.
# 1. forward pass
# 모델의 `forward()` 메서드를 수행하여 데이터를 모델을 통해 전달.
y_preds = model_0(X_test)
# 2. Calculate the loss
# 모델의 예측이 얼마나 잘못되었는지에 대한 손실 값을 계산.
loss= loss_fn(y_preds, y_test)
# 3. optimizer zero grad (최적화 함수 초기화) : 매 에포마다 누적되므로, 각 전방 전달마다 새로 시작하도록 0으로 설정.
optimizer.zero_grad()
# 4. loss backward
# 손실 함수에 대한 역전파를 수행합니다( `requires_grad=True`인 모든 매개변수의 기울기를 계산합니다)
loss.backward()
# 5. optimizer step
# `loss.backward()`로 계산된 기울기에 따라 모델의 매개변수를 업데이트하는 최적화 함수를 단계를 진행
optimizer.step() # 루프를 통해 최적화가 누적되므로 다음 루프 반복을 위해 3단계에서 이를 초기화.
# 모델을 평가 모드로 설정
# 훈련이 아닌 평가를 원한다고 모델에게 알려준다. (훈련에 사용되지만 평가에는 사용되지 않는 기능을 비활성화)
model_0.eval()
# 더 빠른 성능을 위한 추론 : `torch.inference_mode()` 컨텍스트 관리자를 활성화하여 경사 추적과 같은 기능을 비활성화(추론에는 경사 추적이 필요하지 않다.)
with torch.inference_mode():
# 1. forward 전달
# 모델을 통해 테스트 데이터를 전달합니다(이는 모델의 구현된 `forward()` 메서드를 호출합니다)
test_pred = model_0(X_test)
# 2. 손실 계산
# 테스트 손실 값 계산(모델의 예측이 테스트 데이터셋에서 얼마나 잘못되었는지, 낮을수록 더 좋음)
test_loss = loss_fn(test_pred, y_test)
# 3. 10번째 epoch마다 상태 출력
# 훈련/테스트 중 모델의 진행 상황을 ~10 에포크마다 출력 (참고: 여기에 출력되는 것은 특정 문제에 맞게 조정할 수 있다.)
if epoch % 10 == 0:
epoch_count.append(epoch)
loss_values.append(loss)
test_loss_values.append(test_loss)
print(f"Epoch : {epoch} | Loss : {loss} | Test loss : {test_loss}")
# 모델의 매개변수 출력
print(model_0.state_dict())
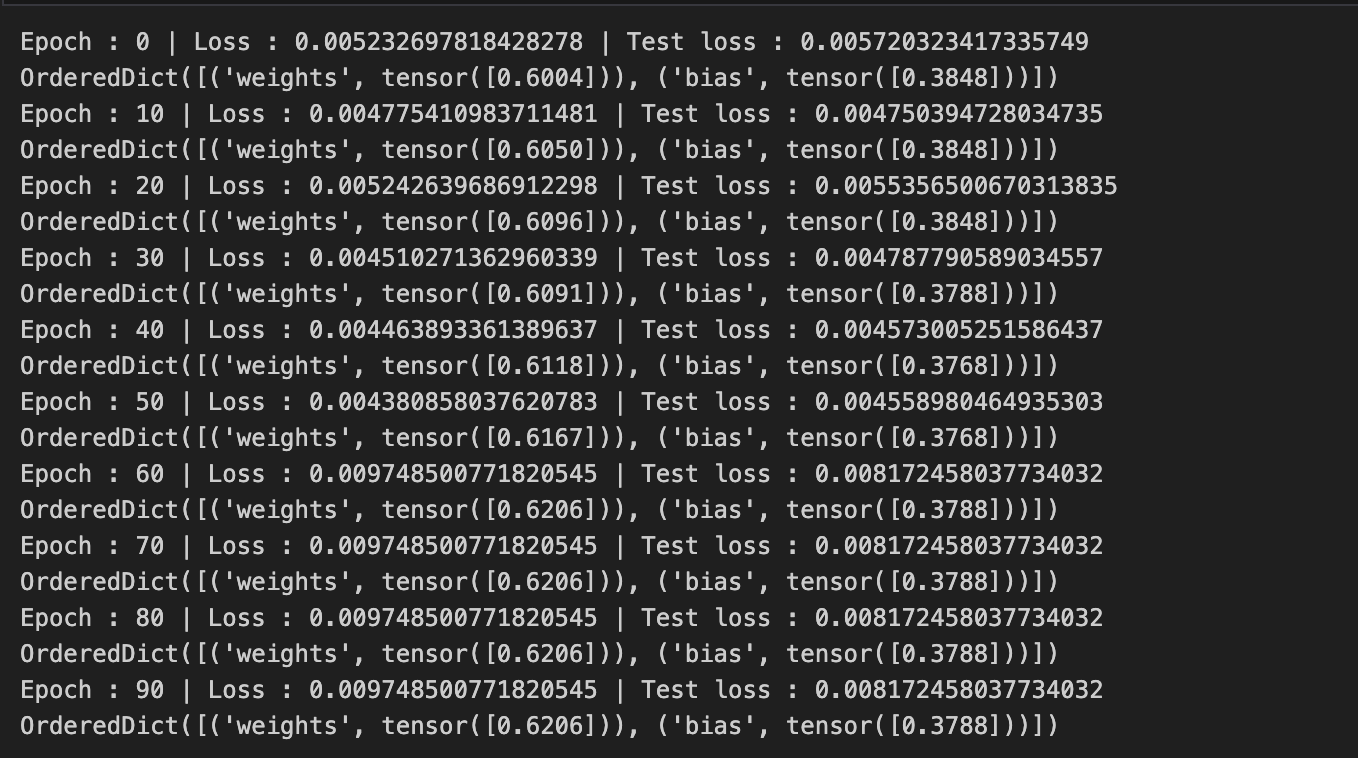
- 결과에 따르면 가중치와 편향은 각각 처음 설정한 0.7과 0.3에 가까워진것을 확인할수있다.
# 시각화
plot_predictions(predictions=test_pred)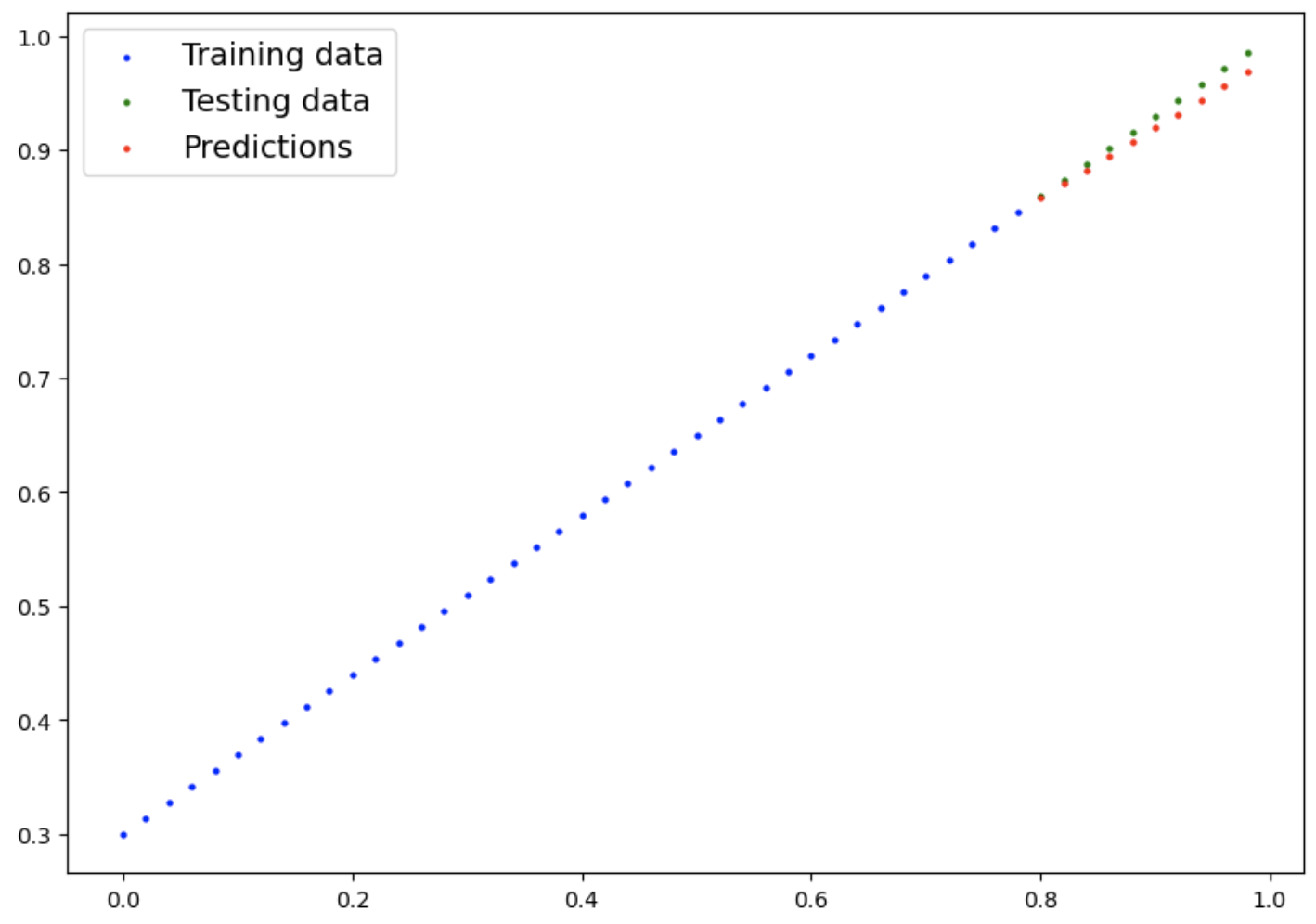
Inference Mode
- 평가 후 torch.inference_mode()와 함께 추론 모드로 실행하는 이유는 다음과 같은 효율성과 성능 최적화 때문이다.
1. 경사 추적 비활성화
torch.inference_mode()는 기울기 추적을 비활성화하여 아래의 이점을 제공:
- 메모리 절약: 경사 추적을 하지 않기 때문에 메모리 사용량 감소
- 속도 향상: 역전파와 같은 추가 계산이 필요 없으므로 예측 속도가 빨라진다.
훈련 단계에서는 역전파(backpropagation)를 위해 기울기 추적이 필수적이지만, 평가 및 추론 단계에서는 모델의 성능을 측정하는 것이 목적이므로 기울기 추적이 필요 없다.
2. 계산 그래프 구성 방지
훈련 시에는 PyTorch가 내부적으로 계산 그래프(Computation Graph) 를 구성하여 역전파를 수행할 수 있도록 설정한다. 하지만 추론 시에는 이 그래프가 필요하지 않으므로 torch.inference_mode()를 통해 이를 방지:
- 계산 그래프를 생성하지 않아 메모리와 시간 절약.
- 추론과 같은 읽기 전용 작업에 적합
3. 성능 최적화
torch.inference_mode()는 추론 및 평가 작업을 위해 추론 전용 모드를 제공:
- torch.no_grad()보다 더 빠르고 메모리 효율적.
- PyTorch 1.9 이후에 도입된 기능으로, 읽기 전용 작업의 최적화를 목표로 설계되었다.
4. 왜 평가 후에 사용하는가?
- 평가 모드(
model.eval()) 는 드롭아웃(dropout), 배치 정규화(batch normalization) 등의 레이어를 비활성화하여 모델이 평가에 적합한 상태로 동작하도록 설정. - 추론 모드(
torch.inference_mode()) 는 모델의 매개변수 업데이트를 필요로 하지 않는 순방향 전달(forward pass) 에 최적화된 상태로 실행.
결론적으로, model.eval()과 torch.inference_mode()는 목적이 다르다:
• model.eval(): 평가 모드로 전환 (모델의 상태 설정)
• torch.inference_mode(): 추론 전용 모드로 전환 (경사 추적 및 계산 그래프 비활성화)
이 두 가지를 조합함으로써 모델의 정확한 평가와 추론 작업의 효율성을 동시에 얻을 수 있다.
손실 곡선 그리기 (plot the loss curves)
# plot the loss curves
plt.plot(epoch_count, np.array(torch.tensor(loss_values).numpy()), label="Train loss")
plt.plot(epoch_count, np.array(torch.tensor(test_loss_values).numpy()), label="Test loss")
plt.title("Training and test loss culves")
plt.ylabel("Loss")
plt.xlabel("Epochs")
plt.legend()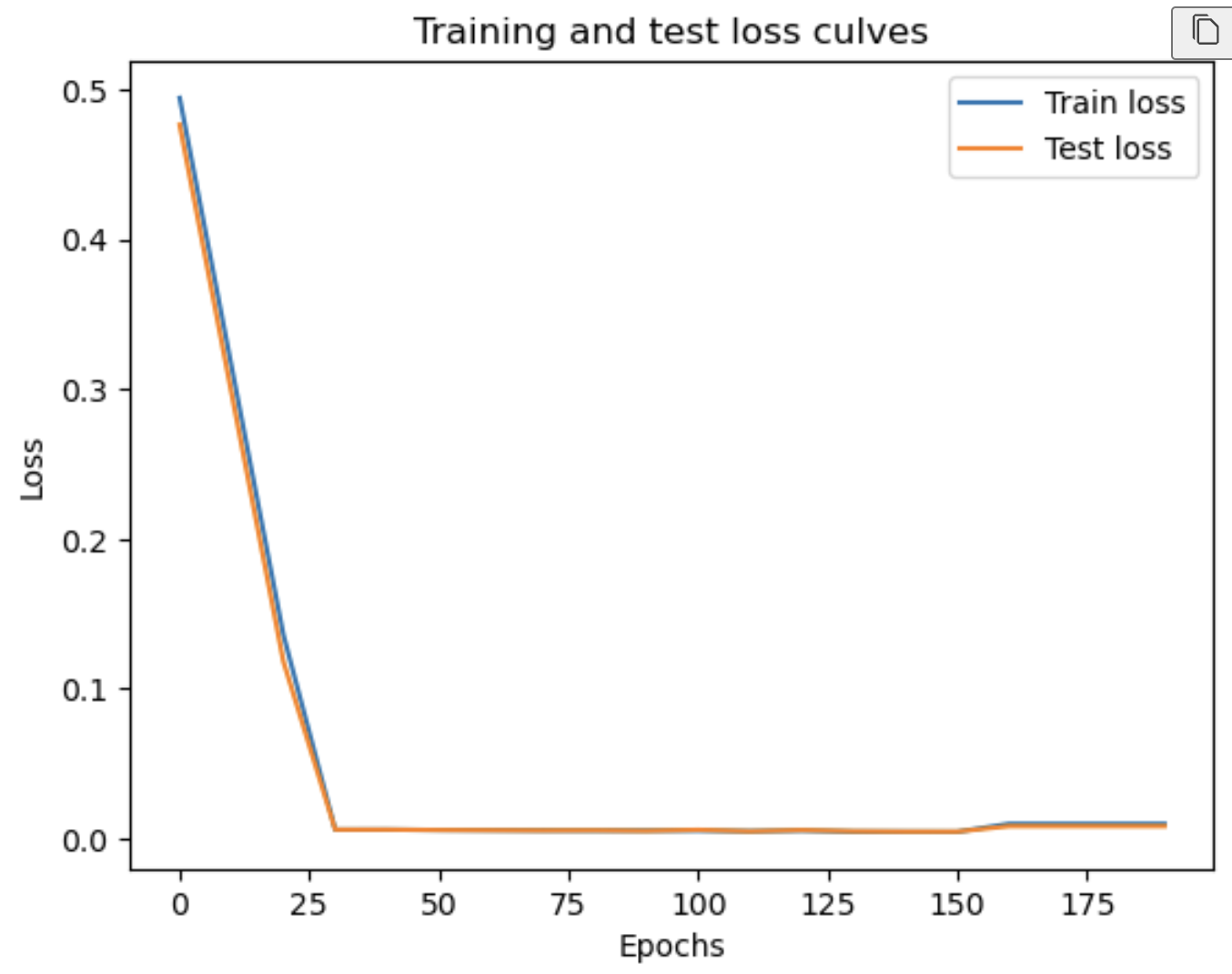
Save the Model in PyTorch
PyTorch에서 모델을 저장하고 로드하는 데 사용하는 세 가지 주요 메서드가 있다.
torch.save()- Python의 pickle 형식으로 PyTorch 객체를 저장torch.load()- 저장된 PyTorch 객체를 로드torch.nn.Module.load_state_dict()- 이 메서드를 사용하여 모델의 저장된 상태 사전을 로드.
# Saving our PyTorch model
from pathlib import Path
# 1. Create models directory
MODEL_PATH = Path("models")
MODEL_PATH.mkdir(parents=True, exist_ok=True)
# 2. Create model save path
MODEL_NAME = "01_pytorch_workflow_model_0.pth"
MODEL_SAVE_PATH = MODEL_PATH / MODEL_NAME
print(f" Saving model to : {MODEL_SAVE_PATH}")
torch.save(obj=model_0.state_dict(),
f=MODEL_SAVE_PATH)
# 3. Saving the model state dict
print((model_0.state_dict)) 
- 위 코드를 실행하면 위와같은 프린트가 될것이고, "model/01_pytorch_workflow_model_0.pth"파일이 생성되어 모델이 저장될 것이다.
Load Model in PyTorch
모델의 state_dict()를 저장했기 때문에, 모델 클래스의 새로운 인스턴스를 생성하고 저장된 state_dict() 정보를 로드한다.
# 저장된 state_dict()를 로드하려면 모델 클래스의 새 인스턴스를 생성해야 합니다.
loaded_model_0 = LinearRegressionModel()
# 저장된 model_0의 state_dict를 로드합니다 (이렇게 하면 새로운 인스턴스가 업데이트된 매개변수로 업데이트됩니다)
loaded_model_0.load_state_dict(torch.load(f=MODEL_SAVE_PATH))
