Paper Review | GNN-RAG : Graph Neural Network Retrieval for LLM Reasoning
GNN-RAG : Graph Neural Retrieval for Large Language Model Reasoning
Costas Mavromatis / Univiersity of Minnesota
George Karypis / University of Minnesota
Abstract
Background
- 지식 그래프(Knowledge Graph, KG)는 head(머리), relation(관계), tail(꼬리) 형태의 삼중(triplet) 데이터를 활용하여 사실(factual knowledge)을 저장하는 구조이다.
- KG 기반 질의응답(KGQA)는 KG를 활용하여 자연어 질문에 답하는 과정이다.
- 대형 언어 모델(LLMs)은 자연어 처리(NLP)에서 강력한 질의응답 성능을 보이며, 반면 그래프 신경망(GNNs)은 KG에 저장된 복잡한 그래프 정보를 효과적으로 처리하는 강점을 가진다.
Objective(연구목표)
- 본 연구에서는 GNN-RAG 라는 새로운 방법론을 제안한다.
- LLM의 자연어 이해 능력과 GNN의 그래프 기반 추론 능력을 결합하여 RAG(Retrieval-Augmented Generation) 방식으로 질의응답 성능을 개선한다.
Introduction
1. 배경 및 문제 정의 (Background & Problem Statement)
-
LLM의 한계 :
- 새로운 지식 (in-domain knowledge)에 대한 적응력이 부족(사전 학습된 지식만 사용)
- hallucination 문제 : 존재하지 않는 정보를 생성하는 오류
- 사전학습 비용이 매우 높고, 업데이트가 어려움.
-
지식 그래프(KnowledgeGraph, KG)의 역할
- KG는 구조화된 데이터베이스로, head, relation,tail 형태의 삼중(triplet) 데이터를 저장.
- 예 : Jamaica(head) -> language_spoken(relation) -> English(tail)
- KG의 특징
- 새로운 정보 추가/삭제가 가능 -> 최신 정보 반영 가능
- 다중홉(multi-hop)관계를 저장하여 복잡한 지식 표현가능
- 지식이 명확하고 오류가 적음 -> KG 기반 질의 KGQA에 유용
- KG는 구조화된 데이터베이스로, head, relation,tail 형태의 삼중(triplet) 데이터를 저장.
multi-hop 이란?
-
다중홉(multi-hop)관계는 하나의 엔티티가 여러 개의 다른 엔티티와 연결되어 있는 경우
-
여러 개의 관계(relation)를 거쳐야만 정답에 도달할 수 있는 질의응답 방식
📌 1-Hop (단일 홉) 질의 예시:
질문: "자메이카에서 사용되는 언어는?"
지식 그래프 정보: <Jamaica → language_spoken → English>정답: "English"
✔ 단일 관계(1-hop)만 거치면 답을 찾을 수 있음.
📌 Multi-Hop (다중 홉) 질의 예시:
질문: "자메이카에서 사용되는 언어를 공용어로 지정한 군주는 누구인가?"
필요한 지식 그래프 정보:
1. <Jamaica → language_spoken → English> 2. <Jamaica → governed_by → Queen Elizabeth II>정답: "Queen Elizabeth II"
✔ 두 개 이상의 관계(2-hop 이상)를 거쳐야 답을 찾을 수 있음.
2. 기존 RAG의 문제점
RAG는 LLM이 신뢰할 수 있는 외부지식을 검색 후 활용하여 Hallucination 문제를 완화하는 방법이다. 하지만 RAG 성능은 검색된 KG 정보의 품질에 의해 결정된다.
- 기존 LLM 기반 검색(LLM-based Retrieval)의 한계
- 기존 RAG는 LLM을 이용해 KG에서 정보를 검색하지만, 다음과 같은 문제가 있다.
- KG 내 복잡한 그래프 구조를 처리하기 어려움 -> 다중 홈 질문에서 성능 저하
- GPT-4 같은 대형 모델에 의존해야 정확한 검색 가능 -> 비용 증가
- 불필요한 정보 검색 가능성 -> LLM이 부정확한 정보를 기반으로 답변 생성
- 기존 RAG는 LLM을 이용해 KG에서 정보를 검색하지만, 다음과 같은 문제가 있다.
3. GNN-RAG 제안 (Proposed Approach : GNN-RAG)
GNN-RAG는 LLM의 자연어 이해력과 GNN의 그래프 처리 능력을 결합하여 기존 RAG의 한계를 극복하는 방식이다.
- GNN-RAG의 주요 작동 원리
- GNN이 KG 내 밀집된 서브그래프(dense subgraph)를 탐색하여 정답 후보를 검색.
- 질문과 정답 후보를 연결하는 최단 경로(shortest paths)를 추출하여 KG의 추론 경로를 생성.
- 추출된 경로를 자연어로 변환(textualization)한 후, LLM에 입력으로 제공하여 최종 답 생성.
- LLM 기반 검색(기존 RAG)과 GNN 검색을 결합하여 성능을 더욱 향상.
- GNN-RAG의 장점
- GNN을 활용한 검색이 LLM기반 검색보다 다중 홉 질의에서 효과적
- GNN-RAG는 GPT-4와 동등한 성능을 7B 크기의 경량 LLM으로 구현 가능 → 비용 절감.
- 복잡한 KGQA(다중 홉 & 다중 엔터티 질문)에서 기존보다 8.9–15.5% 성능 향상.
4. 논문의 주요 기여 (Contributions)
- Framework :
- GNN을 RAG기반 KGQA의 검색기로 재활용하여 LLM의 추론능력을 강화
- 검색 강화기법 (RA, Retrieval Augmentation)을 활용하여 성능 향상
- Effectiveness& Faithfulness:
- WebQSP, CWQ 데이터셋에서 기존 방법 대비 최고 성능
- LLM이 Multi-Hop 정보를 신뢰성 있게 검색하도록 지원하여 환각 문제 감소.
- Efficiency:
- 추가적인 LLM 호출 없이도 KGQA 성능 향상 (RAG 시스템 대비 비용 절감)
- GPT-4 성능을 7B LLM으로 구현가능 -> 비용 및 연산량 절감
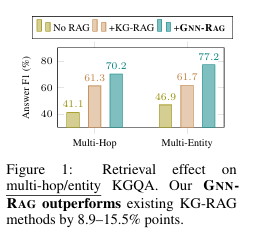
- 해당 그래프는 multi-hop 및 다중 Multi-Entity 질의응답(KGQA)에서 retrieval 방식에 따른 성능 차이를 보여준다.
Related Work (관련연구)
KGQA(Knowledge Graph Question Answering) Mothodology
KGQA(지식 그래프 질의 응답)은 크게 Sementic Parsing(SP) 와 Information Retrieval(IR) 방법 두가지 방법으로 분류된다.
-
Semantic Parsing(SP) 방법
-
주어진 질문을 SPARQL 쿼리 또는 논리적 질의 (logical from query)로 변환 후, KG에서 실행하여 정답을 추출하는 방식
-
단점 :
- 정확한 논리적 질의 데이터를 필요로 함 -> 학습 데이터 구축이 어렵고 비용이 큼
- Syntax error 또는 semantic error 발생 가능 -> 쿼리가 실행되지 않을 수 있음.
-
-
Information Retrieval(IR) 방법
-
약한 지도 학습(Weakly Supervised Learning) 기반 KGQA 방법
-
학습시 정확한 논리적 질의가 필요하지 않으며 질문-정답 쌍(question-answer pairs)을 활용하여 학습 가능
-
주어진 질문을 기반으로 KG에서 관련 subGraph를 검색한 후 이를 입력으로 사용
-
단점 :
- KG에서 불필요한 정보를 검색할 가능성이 있음. -> 검색된 데이터가 많아도 정답과 무관할 수 있음.
- multi-hop 질문에서 정확한 서브 그래프를 찾기가 어려움.
-
따라서, 논문에서는 GNN-RAG가 SP와 IR 방식의 장점을 결합하여 보다 효율적인 KGQA를 수행하도록 제안.
Graph-augmented LMs (그래프 기반 LLM 보강 방법론)
-
GNN을 활용한 잠재적 그래프 정보 추가 방법 (Latent Graph-Augmented LMs)
-
GNN을 활용하여 KG에서 잠재적(latent) 그래프 정보를 추출한 후, 이를 LLM의 내부 지식으로 보강하는 방식.
-
단점 :
- 자연어(Language)와 그래프(Graph) 간의 모달리티 불일치(Modality Mismatch) 발생
- LLM이 텍스트 기반이므로, 그래프 구조를 학습하는 과정에서 성능 저하 가능
-
-
그래프 정보를 자연어로 변환하여 입력에 추가하는 방법 (Verbalized Graph-Augmented LMs)
- 그래프에서 추출된 정보를 자연어 형태로 변환한 후, 이를 LLM 입력으로 제공하는 방식
- 예: "Knowledge: Jamaica → language_spoken → English" 를 LLM의 컨텍스트에 포함- 단점: - 대규모 그래프에서는 불필요한 정보(Noise)가 포함될 가능성 - LLM의 추론 과정에 방해가 될 수 있음GNN-RAG는 두 가지 방법의 단점을 보완하기 위해 GNN을 정보 검색 단계에 활용하고, LLM이 RAG 방식으로 KGQA를 수행하도록 설계됨.
Problem statement & Background(문제 정의 및 배경)
What is KGQA?
- KGQA는 지식 그래프(KG)를 기반으로 자연어 질문에 대한 답을 찾는 작업이다.
- KG는 (엔터티1, 관계, 엔터티2) 형식으로 정보가 저장된 그래프 이다. 예 :
<Jamaica → language_spoken → English> - 목표 : 주어진 질문에 맞는 엔터티들을 KG에서 찾아내는 것
KGQA : Retrieval & Reasoning (검색 & 추론)
검색과 추론의 두 단계로 나눠서 작업을 진행
-
검색 (Retrieval)
- KG에는 수백만 개의 사실(facts)과 노드(nodes)가 있기 때문에, 전체 그래프를 검색하는 것은 너무 시간이 오래 걸린다.
- 그래서, 질문에 관련된 작은 서브그래프(질문에 필요한 정보만 포함된 부분 그래프)를 먼저 검색한다.
-
추론(Reasoning) : GNN + LLM
- 검색된 서브그래프와 질문을 기반으로, 답을 추론하는 모델이 필요하다.
- 이 추론 모델로 GNN(Graph Neural Networks)과 LLM(Large Language Models)이 사용된다.
GNN(Graph Neural Networks) 사용법
- KG 내에서의 노드관계를 기반으로 정보를 처리하는 방식이다.
- 각 노드를 정답인지 아닌지 분류한다.
- GNN의 역할은 주어진 질문에 대해 관련된 노드와 관계를 찾고, 이를 바탕으로 답을 예측하는 것이다.
- GNN이 하는 일:
- GNN은 이웃 노드들에서 정보를 가져와 노드표현을 업데이트한다.
- 이 과정에서 질문과 관련도니 중요한 관계를 계산한다.
- GNN이 하는 일:
LLM(Large Language Models) 사용법
- LLM은 주어진 지식 그래프를 자연어로 변환하여 질문에 대한답을 생성하는 방식이다.
- LLM이 사용하는 방식 (RAG):
- 먼저 지식 그래프에서 필요한 정보를 추출하고, 이를 자연어로 바꿔서 LLM에 입력합니다.
- LLM은 그 정보를 바탕으로 질문에 대한 답을 생성합니다.
GNN, LLM 기반 검색 방식 비교

LLM 기반 검색 (RoG)
- RoG는 LLM을 훈련하여 질의에 적합한 경로(relationship paths)를 추출하도록 하는 방식이다.
- 질문 + 정답 쌍을 기반으로, LLM이 최단 경로를 예측하여 검색할 수 있게 훈련시킨다.
- 예:
"Which language do Jamaican people speak?"라는 질문에 대해, LLM은<official_language>, <language_spoken>관계를 찾아낼 수 있습니다.
- 예:
| 방법 | 검색 방식 | 추론 방식 | 강점 | 약점 |
|---|---|---|---|---|
| GNN-based KGQA | GNN이 서브그래프 검색 | GNN이 답 생성 | 다중 홉 질의에 강함 | 자연어 이해가 부족 |
| ToG (LLM-based KGQA) | LLM이 관계를 하나씩 검색 | LLM이 답 생성 | 자연어 이해가 뛰어남 | KG 구조 활용이 부족 |
| RoG (LLM-based KGQA) | LLM이 관계 경로를 예측하여 검색 | LLM이 답 생성 | 유연한 검색 가능 | 환각(Hallucination) 문제 발생 가능 |
| GNN-RAG (논문 기법) | GNN이 검색, LLM이 답 생성 | LLM이 RAG로 최적화 | GNN과 LLM의 장점 결합 | - |
GNN-RAG 방법론
GNN-RAG는 LLM의 자연어 인해 능력과 GNN의 논리적 추론 능력을 결합한 새로운 RAG 방식이다.
GNN이 KG(지식 그래프)에서 관련 정보를 검색하고, LLM이 이를 활용해 답을 생성한다.
-> GNN은 KG 구조적 정보를 활용하고, LLM은 자연어 이해와 답변 생성을 담당하는 방식
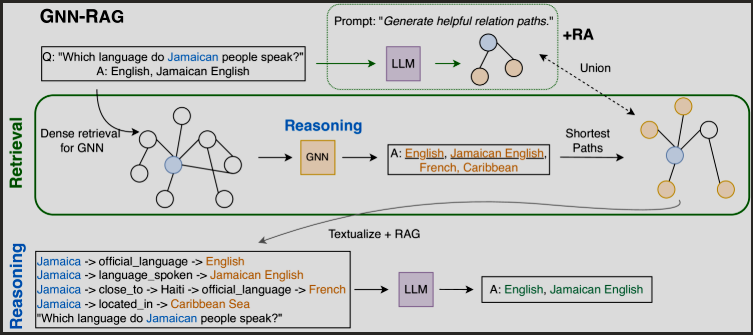
Figure 3. 해당 그림은 GNN-RAG방식을 시각적으로 설명한것.
- GNN과 LLM을 결합하여 질의 응답 (KGQA, Knowledge Graph Question Answering)을 수행하는 과정.
- Retrieval 단계 :
- 목표: 질문(question)과 관련된 정보를 KG에서 검색하여 정답 후보를 찾는 과정
- GNN이 밀집된 서브그래프(Dense Retrieval)를 검색하여 관련 노드를 찾음
-
Retrieval Augmentation(RA, 검색 강화) 단계 - 1번과 동시에 검색이 이루어짐짐
-
GNN이 놓칠수 잇는 추가적인 정보를 보완하기 위해 LLM기반 검색을 함께 사용.
-
LLM이 "Generate helpful relation paths" 라는 프롬프트를 통해 추가적인 관계 경로를 생성.
-
이 과정에서 GNN과 LLM이 찾은 관계 경로를 Union(결합)하여 최적의 reasoning paths를 도출한다.
-
-
Reasoning(추론) 단계 :
- 목표: 정답 후보를 더욱 정교하게 필터링하고, 질문과 정답 사이의 논리적인 경로(reasoning paths)를 생성.
- GNN이 검색한 노드들 간의 관계를 기반으로 최단 경로(shortest paths)를 추출
- 예 : "Jamaica"에서 "English"까지 가는 경로를 탐색하여 관련성이 높은 관계를 연결:
Jamaica → official_language → English Jamaica → language_spoken → Jamaican English Jamaica → close_to → Haiti → official_language → French Jamaica → located_in → Caribbean Sea - 이러한 관계를 분석하여 어떠한 답이 가장 타당한지를 평가한다.
-
LLM을 통한 최종 답변 생성(Textualize + RAG)
- GNN이 생성한 Reasoning Paths 를 LLM이 자연어로 변환한 후, 최종 정답을 생성
4-1. GNN(Graph Neural Networks)
-
GNN은 복잡한 그래프 정보를 분석하여 multi-hop 질의 에서도 정확한 정보를 검색 할 수 있다는 강점이 잇다.
-
다른 KGQA 방법(embedding기반 방법) 보다 다양한 경로를 탐색하여 정답을 찾을 확률이 놓다.
-
GNN이 하는 일
- GNN은 그래프 구조를 활용하여 각 노드의 중요도를 계산
- 최종적으로 높은 확률의 노드(정답 후보)를 선택하고, 질문과 연결된 reasoning paths를 생성
- 이 경로는 LLM의 RAG입력으로 사용
-
따라서, GNN은 KG에서 정확한 정보를 검색하는 역할을 한다.
4-2. LLM(Large Language Model)
-
GNN-RAG 에서 GNN이 생성한 reasoning paths를 LLM에게 전달하여 답변을 생성
-
LLM이 사용하는 입력 프롬프트 예시 :
prompt = f""" Based on the reasoning paths, please answer the given question. Reasoning Paths : {reasoning_paths} Question : {question} """ -
Reasoning paths 예시 :
Jamaica → offical_language → English Jamaica → language_spoken → Jamaican English -
GNN이 생성한 reasoning paths를 LLM이 해석하고, 이를 바탕으로 최종 답변을 생성하는 방식이다.
4-3. Retrieval Analysis (검색 분석)
-
GNN과 LLM기반 검색(RoG)을 비교하여 어떤 방식이 더 효과적인지 분석
-
GNN은 다중 홉 질문에 강하지만, 단순한 질문 (1-hop)에서는 성능이 떨어질 수 있음.
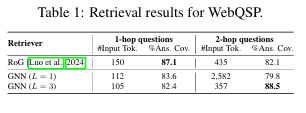
-
실험 결과:
- GNN (L=3, 깊은 모델) → 다중 홉 정보 검색에 유리.
- GNN (L=1, 얕은 모델) → 1-hop 질문에서는 성능이 상대적으로 낮음.
- RoG (LLM 기반 검색) → 1-hop 질문에서는 더 정확한 검색을 수행하지만, 다중 홉 질문에서는 성능이 떨어짐.
-
결론: GNN은 복잡한 질문에서는 우수하지만, 단순한 질문에서는 LLM 기반 검색이 더 효과적일 수 있음
4-4. Retrieval Augmentation, RA (검색 강화)
-
GNN과 LLM 기반 검색을 결합하여 더 나은 성능을 내는 방법.
-
GNN이 다중 홉 검색을 담당하고, LLM(RoG)이 단순한 질문에 대한 검색을 보완하도록 설계
-
실험에서 GNN-RAG + RA 방식이 가장 높은 성능을 보임
- GNN이 생성한 reasoning paths와 RoG(LLM 기반 검색)가 생성한 reasoning paths를 합침(UNION)
- 이 데이터를 LLM에 입력하여 최종 답변을 생성.
-
결과적으로 GNN과 LLM의 장점을 모두 활용하는 최적의 검색방식이라고 할수 있다.
Experimental Setup (실험 설정)
5-1. KGQA DataSets
- WebQuestionsSP (WebQSP)
- 총 4,737개의 자연어 질문 포함
- 최대 2-hop 추론이 필요한 질문들
- freebase 지식 그래프 기반 서브 set 사용
- Complex WebQuestions (CWQ)
- 총 34,699개의 복잡한 질문 포함
- 최대 4-hop 추론이 필요한 복잡한 질의
- 더 깊은 추론을 요구하는 KGQA 실험에 적합
5-2. Implementation & Evaluation
-
서브 그래프 검색 방식
- 연결된 엔티티와 PageRank 알고리즘을 사용하여 밀집된 그래프 정보 추출
- ReaRev(Mavromatis & Karypis, 2022)를 GNN-RAG의 기본 모델로 사용
- ReaRev : 깊은 KG 추론(Deep KG Reasoning)을 위한 GNN Model.
-
사용된 GNN 및 LM 조합
- ReaRev + SBERT (GNN과 사전 훈련된 SBERT 활용)
- ReaRev + LMSR (질문-관계 매칭을 위한 LM 적용)
-
LLM 기반 RAG 최적화
- RoG 를 활용하여 RAG 기반 프롬프트 튜닝 적용
- Section 4.2 에서 설명한 방법을 따름.
-
성능평가지표 (Evaluation Metrics)
-
Hit : 생성된 답변 중 정답이 포함되었는지 여부 측정 (LLM평가 시 사용)
-
H@1 (Hits@1): 첫번재 예측 답변이 정답인지 측정하는 Accuracy 평가.,
-
F1-score :
- 정답을 얼마나 많이 찾았는지(Recall)와 불필요한 답을 얼마나 줄였는지 (precision)를 모두 반영하는 점수
- LLM 및 KGQA 시스템의 성능을 종합적으로 평가하는 데 사용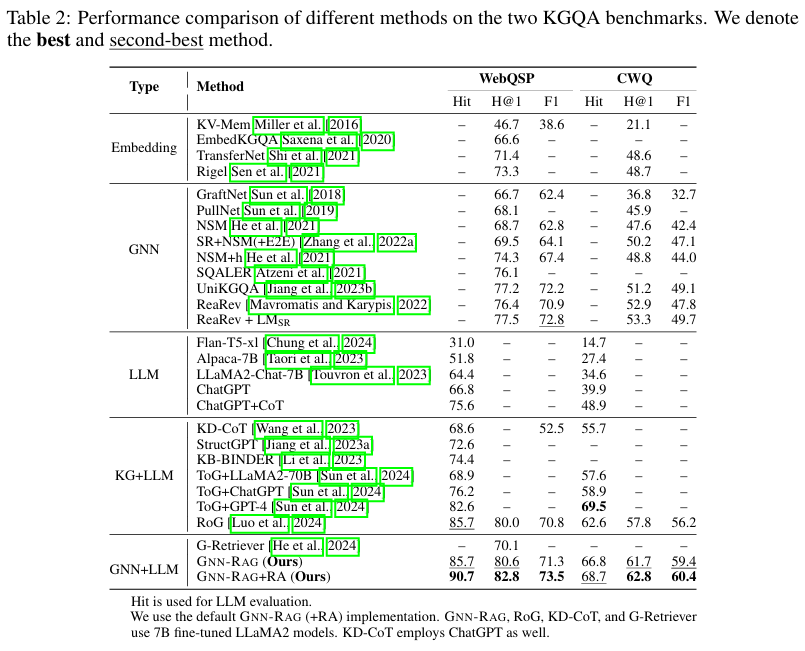
Table 2. KGQA 벤치마크 성능비교 (Performance Comparison on WebQSP & CWQ)
-
GNN-RAG + RA 가 WebQSP와 CWQ 모두에서 최고 성능을 기록
-
GNN-RAG는 기존의 LLM 기반 검색 방식보다 높은 F1-score를 달성
-
특히 WebQSP에서는 RoG보다 3.5% 높은 F1-score를 기록
-

Table 3: Multi-Hop & Multi-Entity 질문 성능 분석
- Multi-hop : 정답을 찾기위해 여러개의 관계(Edge)를 거쳐야하는 질문
- Multi-Entity : 하나의 질문에 대해 여러 개의 정답 엔터티가 포함되는 질문
- GNN-RAG는 Multi-Hop과 Multi-Entity 질문에서 우수한 성능을 보임
- GNN-RAG + RA는 모든 유형에서 최고 성능을 기록, 특히 Multi-Entity 질문에서 큰 개선
- RoG 보다 6~8% 높은 F1-score를 보이며 KGQA 성능이 향상됨
Result
6-1. 주요 결과
-
Table 2에서 다양한 KGQA 방법들의 성능 비교
-
GNN-RAG가 전반적으로 가장 높은 성능 기록 -> 최신 (SOTA) 결과 달성
-
GNN을 활용한 검색이 LLM기반 검색보다 추론 능력을 크게 향상시킴 (GNN+LLM vs KG+LLM)
-
GNN-RAG + RA vs. 기존 방법성능 비교
- RoG 보다 Hit 기준 5.0~6.1% 높은성능
- ToG+GPT-4와 비슷한 성능을 내면서도, 7B LLM과 훨씬 적은 LLM 호출(비용 절감)로 실행 가능
- ToG+GPT-4 실행 비용 추정: $800 이상
- GNN-RAG는 단일 24GB GPU에서도 실행 가능
-
ToG+ChatGPT 대비 최대 14.5% 높은 Hit 성능
-
최고 성능을 기록한 GNN 대비 Hits@1에서 5.39.5%, F1에서 0.710.7% 성능 향상
GNN-RAG는 복잡한 그래프 검색이 중요한 KGQA에서 매우 효과적
LLM의 추론 능력을 GNN을 통해 보완하면 성능이 대폭 향상됨
6-2. 검색 증강(Retrieval Augmentation) 분석
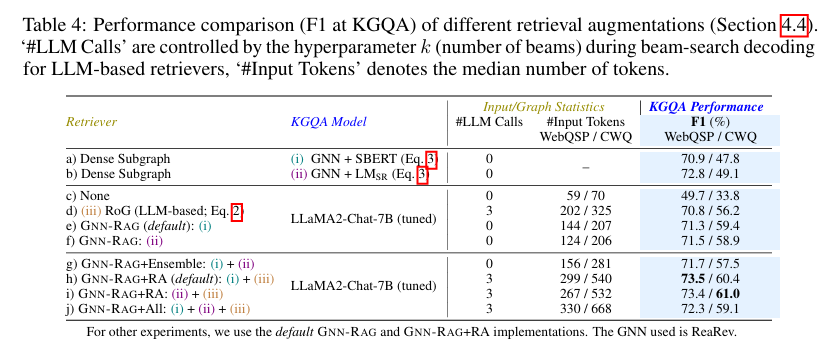
-
다양한 검색 증강 기법을 비교.
- 주요 평가 지표 : F1-score -> KG에서 정보를 얼마나 잘 검색했는지를 평가
-
주요 결론 :
- GNN-RAG+RA가 가장 효과적인 검색 증강 방식 (F1-score 최고 기록)
- 모든 검색 방식을 합치는 것은 오히려 성능 저하를 초래할 수도 있음
- GNN 기반 검색이 LLM 기반 검색보다 효율적이며, 복잡한 질문에서 더 강력함 🚀
6-3. 검색 방식에 따른 LLM 성능 비교
다양한 LLM(ChatGPT, Alpaca-7B, LLaMA2-Chat 등)을 활용한 검색 성능 비교
평가지표 : Hit(%)
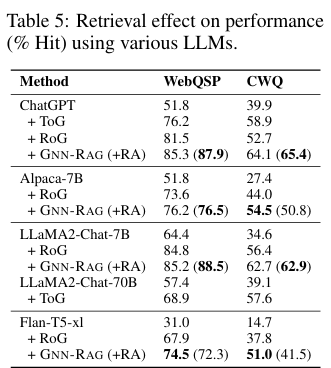
- 주요 결론 :
- GNN-RAG + RA 는 대부분의 LLM에서 Hit성능을 크게 향상시킴
- 특히 성능이 낮은 LLM(Alpacha-7b, FlanT5-xl)에서 개선효과가 더 두드러짐
- RoG 대비 최대 13.2%, ToG 대비 최대 6.5% 성능 향상
- GNN-RAG 는 7b Llama2 모델에서도 Llama2-Chat-70B + ToG 보다 높은 성능 기록
GNN-RAG는 다양한 LLM과 결합할 수 있으며, 추가 훈련 없이 KGQA 성능을 향상 가능
6-4. 사례연구 (Case Studies)
Figure 4. GNN-RAG가 LLM의 신뢰성(Faithfulness)을 어떻게 향상시키는지 보여주는 사례

-
GNN-RAG vs. KG-RAG :
-
질문 1: "In which state did fictional character Gilfoyle live?"
- RoG: Gilfoyle → fictional_universe.fictional_setting.characters_that_have_lived_here → Toronto → LLM이 "Toronto"라고 답변 (오답)
- GNN-RAG: 추가적인 reasoning paths를 검색하여 "Ontario"를 찾아내어 정답을 도출
-
질문 2: "Who was the real Erin Brockovich featured in Michael Renault Mageau movie?"
- RoG: "Actor"를 정답으로 예측했지만, 질문에서 기대하는 정답이 아님 (오답)
- GNN-RAG: Erin Brockovich가 실제로 영화에서 어떤 역할을 했는지 추론하여 "Consultant"를 정답으로 도출
-
결론 : GNN-RAG는 더 깊은 reasoning paths를 활용하여 LLM이 정확한 정보를 사용하도록 도와줌
Figure 5. 검색 증강(RA)이 GNN-RAG 성능을 개선하는 사례
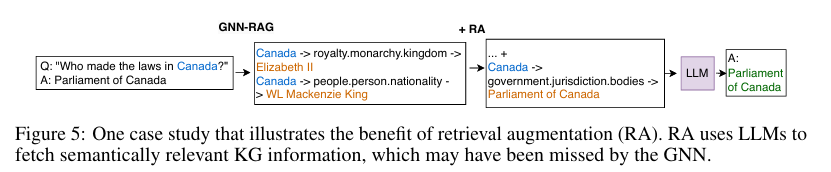
-
질문: "Who made the laws in Canada?"
- GNN-RAG 단독으로는 "Parliament of Canada"를 찾지 못함
- RA(Retrieval Augmentation): LLM이 "jurisdiction.bodies" 정보를 찾아내 최종적으로 정답을 생성할 수 있음
-
결론: RA를 사용하면 GNN이 놓칠 수 있는 의미적으로 중요한 KG 정보를 LLM이 보완할 수 있음
7. Conclusion
논문에서는 GNN-RAG를 KGQA(Knowledge Graph Question Answering)를 위한 새로운 RAG 방식으로 제안했으며, 주요기여는 다음과 같다.
Framework
- GNN을 KGQA의 검색(Retrieval) 단계에 활용하여, LLM의 추론(Reasoning) 능력을 보완하는 새로운 방법 제안.
- 검색분석 (Retrieval Analysis)를 통해 최적의 검색증강 (Retrieval Augmentation) 기법 설계
Effectiveness & Faithfulness
- GNN-RAG는 최신(KGQA) 벤치마크(WebQSP & CWQ)에서 최고 성능(SOTA)을 기록
- Multi-hop 정보를 효과적으로 검색하여, 복잡한 질문에서도 신뢰성 높은 high-faithfulness LLM 추론을 지원
Efficiency
- 기존의 RAG 기반 KGQA 시스템과 달리, 추가적인 LLM 호출 없이도 KGQA 성능을 개선 가능
- 7B 파라미터 크기의 LLM을 활용하면서도 GPT-4 성능을 뛰어넘거나 유사한 성능을 달성
