Agents
Publication Date : 2024-11-12
Authors : Julia Wiesinger, Patrick Marlow, and Vladimir Vuskovic
인간은 패턴을 인식하는 능력이 뛰어나지만, 더 정확한 결론을 내리기 위해 책, 검색, 계산기 등의 도구를 활용한다.
Generative AI 모델도 인간과 마찬가지로 도구들을 사용하여 인간처럼 작업을 하도록 훈련이 가능하다. 예를 들어, 데이터베이스 검색 도구를 사용하여 고객의 구매 이력을 확인하고 맞춤형 추천을 생성하거나, API 호출을 통해 이메일을 보내거나 금융 거래를 실행하는 작업을 수행 가능하다.
이를 위해서는 모델이 단순히 외부 도구에 접근하는 것뿐만 아니라, 계획을 세우고 스스로 작업을 실행할 수 있는 능력이 필요하다.
이러한 논리적 사고, 계획, 외부 정보 활용을 결합한 개념이 "에이전트(Agent)"이며, 이는 기존 Generative AI 모델을 뛰어넘는 프로그램을 의미한다.
이 글에서는 에이전트의 개념과 그와 관련된 다양한 요소들을 상세히 다룬 논문의 핵심 내용을 요약 및 정리한 리뷰를 작성할 것이다.
What is an Agent? (에이전트란?)
- 에이전트는 목표를 달성하기 위해 환경을 관찰하고, 도구를 사용하여 행동하는 응용 프로그램.
- 자율적이며, 사람의 개입 없이 목표 달성을 위한 계획을 세우고 실행할 수 있음.
- 특정한 AI 모델을 활용해 인지 아키텍처(Cognitive Architecture) 를 구성.
The Model (모델)
- 에이전트에서 Model은 중앙 의사 결정 시스템 역할을 한다.
- 하나 이상의 언어 모델 (LLM)을 활용할 수 있으며, 크기(small/large)와 유형(multi-modal, fine-tuned, etc.)에 따라 다양한 작업을 수행할 수 있다.
- ReAct, Chain-of-Thought(CoT), Tree-of-Thoughts(ToT) 같은 Cognitive Architecture(인지아키텍쳐)를 적용하여 논리적으로 사고하고 결정을 내릴 수 있음.
- 최적의 결과를 얻기 위해서는, 에이전트가 사용하는 도구(Tools)와 잘 연계된 모델을 선택하는 것이 중요.
모델 자체는 특정 에이전트 설정(도구 선택, 오케스트레이션 구조 등)에 대해 미리 학습되지 않는다. 그러나, 에이전트가 특정 도구를 사용하는 예제나 추론 과정을 추가로 학습시켜(finetuning or few-shot learning) 모델을 최적화 할 수 있다.
The Tools (도구)
- 기본 언어 모델만으로는 현실 세계와 상호작용할 수 없기 때문에 도구가 필요.
- 도구의 종류:
- Extensions (확장): API를 호출하여 외부 데이터를 활용.
- Functions (함수 호출): 모델이 특정 기능을 클라이언트 측에서 실행하도록 지시.
- Data Stores (데이터 저장소): 벡터 DB 등을 통해 외부 데이터 활용.
The Orchestration Layer (오케스트레이션 레이어) : 에이전트의 작동방식식
- 에이전트의 의사 결정 과정을 관리하는 반복적 실행 구조.
- 데이터를 수집 → 내부에서 추론 → 도구 사용 → 결과 생성.
- 단순한 계산부터 복잡한 체인 로직, 머신러닝 알고리즘 등을 포함할 수 있음.
Agents vs. Models (에이전트 vs. 모델)
| 특징 | 모델(LLM) | Agent |
|---|---|---|
| 지식 | 훈련된 데이터에 의존 | 외부 도구를 통해 확장 가능 |
| 추론 방식 | 단일 질의 응답(One-off inference) | 세션유지, 다중 단계 추론 가능 |
| 도구사용 | 불가능 | API 호출, 데이터 활용가능(RAG, Dataframe, etc.) |
| 논리적 실행 | 명시적 프롬프트 필요 | 자체적인 추론 및 행동 계획 |
Cognitive Architectures : How Agents Operate(인지 아키텍쳐 : 에이전트의 작동방식)
Orchestration Layer : 에이전트가 정보를 수집 -> 계획 -> 실행 -> 조정 하는 반복적인 과정을 거쳐 최적의 결과를 얻는 과정
- 기억(memory), 상태(state), 논리(reasoning), 계획(planning)을 유지하고 제어 하는 역할
- 프롬프트 엔지니어링(Prompt Engineering) 및 추론 기법을 활용하여 의사결정을 최적화
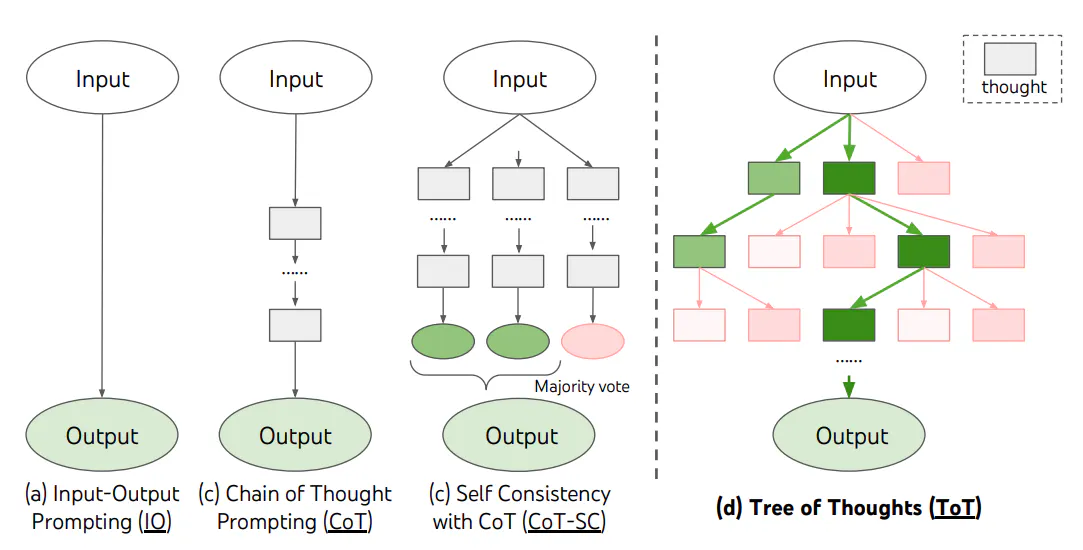
Reasoning Techniques : 대표적인 추론기법
ReAct (Reasoning + Acting)
- 모델이 논리적 사고(Reasoning) 후, 적절한 행동(Action)을 결정하는 프레임워크.
- 사용자의 요청에 따라 도구를 선택하여 최적의 결과를 도출.
- LLM의 신뢰성과 인간과의 상호작용성을 향상시킴.
Chain-of-Thought (CoT)
- 복잡한 문제를 해결하기 위해 중간 사고 과정(Intermediate Steps)을 포함한 추론 기법.
- Self-Consistency, Active-Prompt, Multimodal CoT 등의 변형 기법이 존재.
- 단순한 질의응답보다 논리적인 문제 해결에 적합.
Tree-of-Thoughts (ToT)
- 문제를 해결하기 위해 여러 개의 사고 체인(Thought Chains)을 확장하는 방식.
- 다양한 탐색 경로를 고려하여 최적의 결정을 내릴 수 있도록 설계됨.
- 전략적 탐색 및 장기적인 의사결정이 필요한 경우 유용.
Tools : Our Keys to the Outside World (도구 : 외부 세계와의 연결)

A는 Extension의 예, B는 Function의 예이다.
Extensions(확장기능)
- 언제 ? API 호출을 즉시 실행하고, 빠르게 응답을 받아야할때.(실시간 정보 조회 등)
- API호출을 통해 외부 데이터를 가져오는 방법
- 예 : 항공평조회 API, 날씨 데이터 API
- 실행 방식 :
- API 호출 예제를 이용해 에이전트를 학습. (예 : 비행 출발 및 도착하는 도시, 날짜, 시간 등)
- 필요한 인자 및 파라미터 학습
- 모델이 적절한 API를 자동 선택하여 호출
- 장점
- 에이전트가 API호출을 직접 실행하기 때문에 개발자가 신경쓸 부분이 적어짐.
- API 호출 방식이 동적으로 변경가능 : 에이전트가 특정 작업을 수행할 때, 적절한 API를 자동으로 선택 가능.
- API 호출을 자동으로 최적화 : API 요청 방식이나 파라미터를 에이전트가 직접 조정할 수 있음.
A는 Extension의 예, B는 Function의 예이다.
- 즉시 응답(실시간호출)이 필요한 작업에 적합 : 실시간 API 요청을 통해 즉각적인 결과 반환 가능.(날씨정보, 뉴스검색, 실시간 데이터) - 단점
- API 인증문제 발생가능성 : API 키를 에이전트 내부에서 처리해야 하므로, 보안 리스크가 존재.
- 일부 API는 에이전트가 직접 호출할 수 없음 (내부 시스템 API 등).
- 클라이언트가 API 호출을 직접 제어할 수 없음 : 개발자가 세밀하게 조정하기 어려움
- 확장성 문제 :
- 에이전트 내부에서 API를 실행하므로, API가 증가할수록 복잡성이 증가.
- 모든 API를 직접 실행하면, 네트워크 부담이 커질 수 있음.
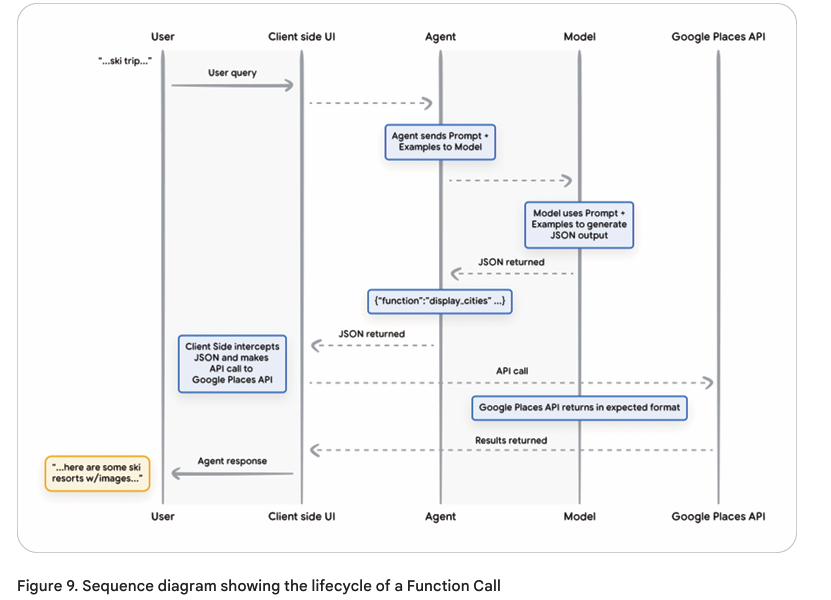
Functions Calling (함수 호출)
- 언제 ? : API 키를 보호하고, 클라이언트가 직접 API 호출을 제어해야 할 때(최근사용자의 구매내역 분석 등등)
- Agent가 API를 직접 호출하는 것이 아니라, 모델이 어떤 함수를 실행해야하는지 결정
- 클라이언트 측에서 실행되는 함수
- 보안 이슈를 해결하거나 추가적인 데이터 변환이 필요한 경우 유용
- 장점:
- 보안 강화 → API 키와 인증 정보를 보호 가능
- API 호출을 클라이언트에서 처리하므로, API 키를 에이전트가 직접 다룰 필요 없음.
- 내부 시스템 API도 안전하게 사용할 수 있음.
- API 호출 로직을 클라이언트에서 제어가능
- 클라이언트가 API 호출 방식을 직접 지정할 수 있어, 유연한 요청가능(batch 처리, 추가적인 데이터 변환 후 API 호출 가능)
- 실시간 호출이 필요 없는 작업에 적합 : 예약 실행(비동기 처리), 최근 구매내역 분석 등.
- API Mocking을 활용한 개발 가능
- API가 아직 완성되지 않은 상태에서도, 가짜 응답(Mock)을 사용해 개발 진행 가능.
- API 변경 시, 에이전트가 아닌 클라이언트에서만 수정하면 됨.
- 보안 강화 → API 키와 인증 정보를 보호 가능
- 단점 :
- API 호출을 직접 실행할 수 없음 : 에이전트는 "실행해야 한다" 는 신호만 보낼 뿐, API 호출을 직접 실행하지 않음. 따라서 API실행 로직 추가 구현
- 즉시 응답이 필요한 작업에는 적합하지 않음 : 실시간 요청에는 속도가 느려짐.
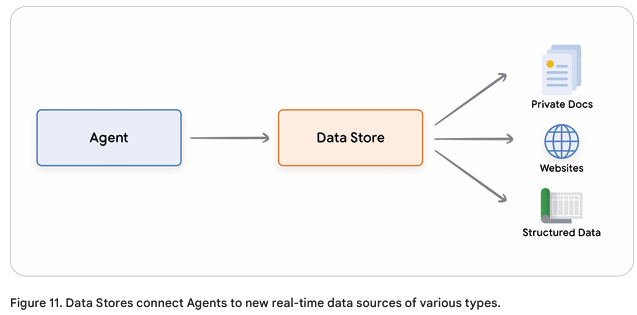
Data Stores(데이터 저장소)
- 언제? : 데이터를 저장하고 조회해야 할 때.
- Vector DB를 통해 외부 데이터 활용.
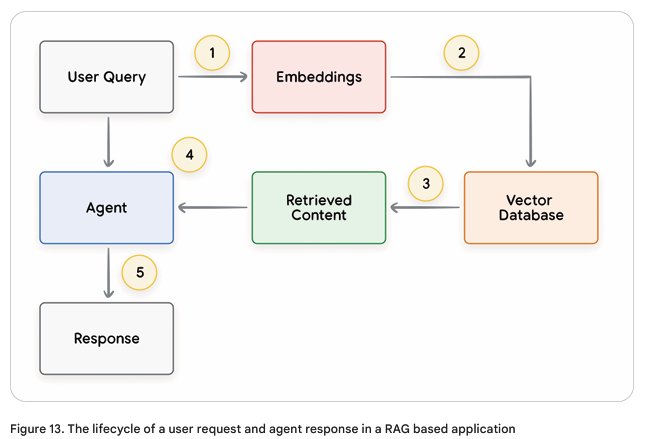
- Retrieval Augmented Generation(RAG) :
- Web content
- Structured Data : PDF, CSV, WordDocs, Spreadsheets, etc.
- Unstructured data : HTML, PDF, TXT, etc.

| Extension | Function Calling | Data Store | |
|---|---|---|---|
| Execution | Agent-Side Execution | Client-Side Execution | Agent-Side Execution |
| Use Cases | - 에이전트가 API endpoint와의 상호작용을 제어 - 사전에 구축된 기본확장 활용에 유용(예 : Vertex Search, Code Interpreter, etc.) - Multi-hop Planning 및 API 호출( 즉, 다음 에이전트 작업은 이전작업 / API 호출의 출력에 따라 달라짐.) | - 보안 또는 인증 제한으로 에이전트가 API를 직접 호출 불가한 경우 - Agent가 실시간으로 API를 호출하지 못하도록 하는 타이밍 제약 조건 또는 작업 순서 제약 조건(예 : batch, Human-in-the-loop 검토 등) - 인터넷에 노출되지 않거나 Google 시스템에 엑세스 할 수없는 API | 다음 데이터 유형 중 하나로 RAG 구현: - 사전 indexing 된 도메인 및 웾사이트 콘텐츠 - PDF,Word Docs, CSV, SpreadSheets 등과 같은 정형 데이터 - HTML, PDF, TXT 등과 같은 비정형 데이터터 |
Enhancing Model Performance with Targeted Learning (목표 학습을 통한 모델 성능 향상)
다음은 모델이 적절한 도구를 선택하도록 학습하는 3가지 방법이다.
- In-Context Learning
- Retrieval-Based In-Context Learning
- Fine-Tuning
In-Context Learning(문맥 내 학습)
- 몇 개의 예제만 주고 즉석에서 학습하는 방식
- 예제 1: "서울에서 도쿄까지 가장 저렴한 비행기" → 결과: 항공사 X, 가격 500달러
- 예제 2: "런던에서 파리까지 저렴한 비행기" → 결과: 항공사 Y, 가격 100유로 Retrieval-Based In-Context Learning(검색 기반 문맥 학습)
- 외부 데이터를 검색하여 적절한 예제 제공하는 방식
user_query : "Python에서 빠른 정렬을 구현하는 방법 알려줘"
retrieved_context : "퀵 정렬은 분할 정복 알고리즘으로 평균 시간복잡도 O(n log n)을 가짐."
agent_answer : "퀵 정렬은 분할 정복 알고리즘으로 평균 시간복잡도 O(n log n)을 가지기 때문에 빠른 정렬을 구현할 수 있습니다."Fine-Tuning (모델 미세 조정)
- 특정 도메인(의료, 법률, 금융 등)에 대한 대규모 데이터셋을 사용해 모델을 사전 학습.
- 이후 동일한 유형의 문제를 더 잘 해결하도록 조정된 모델을 제공.
이러한 각 접근 방식은 속도, 비용 및 대기시간 측면에서 고유한 장점과 단점을 제공한다. 그러나 이러한 기술을 Agent Framwork에 결합한다면 다양한 강점을 활용하고 약점을 최소화하여 보다 강력하고 적응력 있는 솔루션을 만들 수 있다.
의료 상담 데이터로 학습된 AI 챗봇이 더 정확한 진단 추천
Agent Quick Start with LangChain (LangChain을 활용한 에이전트 빠른 시작)
LangChain과 LangGraph 라이브러리를 사용하여 에이전트 구축.
SerpAPI (Google 검색) 및 Google Places API를 사용한 간단한 예제 제공.
from langgraph.prebuilt import create_react_agent
from langchain_core.tools import tool
from langchain_community.utilities import SerpAPIWrapper
from langchain_community.tools import GooglePlacesTool
os.environ["SERPAPI_API_KEY"] = "XXXXX"
os.environ["GPLACES_API_KEY"] = "XXXXX"
@tool
def search(query: str):
"""Use the SerpAPI to run a Google Search."""
search = SerpAPIWrapper()
return search.run(query)
@tool
def places(query: str):
"""Use the Google Places API to run a Google Places Query."""
places = GooglePlacesTool()
return places.run(query)
model = ChatVertexAI(model="gemini-1.5-flash-001")
tools = [search, places]
query = "Who did the Texas Longhorns play in football last week? What is the address of the other team's stadium?"
agent = create_react_agent(model, tools)
input = {"messages": [("human", query)]}
for s in agent.stream(input, stream_mode="values"):
message = s["messages"][-1]
if isinstance(message, tuple):
print(message)
else:
message.pretty_print()=============================== Human Message ================================
Who did the Texas Longhorns play in football last week? What is the address
of the other team's stadium?
================================= Ai Message =================================
Tool Calls: search
Args:
query: Texas Longhorns football schedule
================================ Tool Message ================================
Name: search
{...Results: "NCAA Division I Football, Georgia, Date..."}
================================= Ai Message =================================
The Texas Longhorns played the Georgia Bulldogs last week.
Tool Calls: places
Args:
query: Georgia Bulldogs stadium
================================ Tool Message ================================
Name: places
{...Sanford Stadium Address: 100 Sanford...}
================================= Ai Message =================================
The address of the Georgia Bulldogs stadium is 100 Sanford Dr, Athens, GA
30602, USA.Production Applications with Vertex AI Agents (Vertex AI 에이전트를 활용한 실무 적용)
Google의 Vertex AI 플랫폼을 활용하여 프로덕션 레벨의 AI 에이전트 구축 가능.
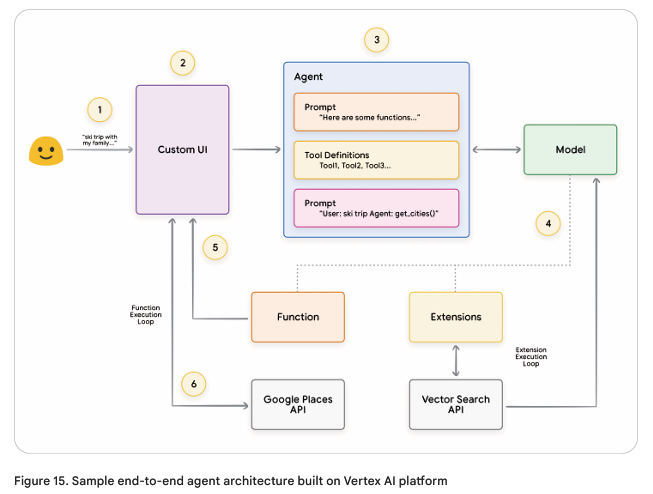
핵심 구성 요소:
- Vertex Agent Builder: 사용자 정의 에이전트 생성.
- Vertex Extensions: API 확장 기능.
- Vertex Function Calling: 클라이언트 측 함수 호출.
- Vertex Example Store: 예제 데이터 저장소.
Summary (요약)
에이전트(Agent) 는 단순한 언어 모델(LLM)보다 확장된 개념으로, 외부 도구와 상호작용하며 자율적으로 작업을 수행할 수 있다.
핵심 구성 요소:
- Agent의 역할 :
- 에이전트는 언어 모델(LLM)의 한계를 확장하여, 도구를 활용해 실시간 정보에 접근하고, 실제 행동을 수행하며, 복잡한 작업을 자동으로 계획하고 실행할 수 있다.
- 단순한 언어 모델과 달리, 여러 개의 LLM을 조합하여 최적의 도구를 선택하고 다양한 복잡한 작업이 수행가능하다.
- 오케스트레이션 레이어 & 인지 아키텍쳐쳐 :
- 에이전트의 핵심은 "오케스트레이션 레이어"로, 이를 통해 정보 처리, 계획, 의사결정 및 실행을 제어한다.
- ReAct, Chain-of-Thought(CoT), Tree-of-Thoughts(ToT) 같은 추론 기법을 활용하여, 내부적으로 논리를 구성하고 최적의 행동을 결정.
- Tools
- Extensions, Functions, Data Stores들은 외부와 상호작용하는 데 사용된다.
- Extensions (확장 기능) → 에이전트가 외부 API를 직접 호출하여 실시간 데이터 활용 가능.
- Functions (함수 호출) → API 실행을 클라이언트 측에서 처리하도록 분리하여 보안 및 확장성 확보.
- Data Stores (데이터 저장소) → 구조화된 데이터(예: DB) 및 비구조화된 데이터(예: PDF, 문서 등) 접근 가능, RAG(Retrieval-Augmented Generation) 방식 활용 가능.
- Extensions, Functions, Data Stores들은 외부와 상호작용하는 데 사용된다.
미래에는 복합적인 에이전트 체인을 활용하여 더욱 강력한 AI 시스템 구축 가능해질 것이다.
